Marketing & Growth Priorities for 2026: Strategy Signals From 1,000 Businesses via @sejournal, @hethr_campbell
Compare your 2026 plan to what top teams are actually doing.
In this on-demand webinar, they examined how high-performing teams are prioritizing marketing heading into 2026, the tradeoffs businesses are making between growth, efficiency, and focus, and whether companies are truly prepared to use AI to drive growth in 2026.
See how businesses like yours planned for 2026.
Survey Results Are In. Your Competitors Are Making Pivots.
Jeff Hirz, EVP of Business Development at OuterBox, shared early findings from “2025 Performance Insights From 1,000 Businesses Planning for 2026,” including:
How companies performed in 2025 & what they’ll do differently.
Peer Data & Practical Takeaways To Refine Your 2026 Growth & Marketing Priorities
In this on-demand webinar, we unpack fresh market pulse data from nearly 1,000 businesses like yours.
You’ll Learn:
Where confidence is rising & what you need to focus on A clear view of how businesses feel heading into 2026 and what’s driving optimism or restraint.
Which marketing & operational activities are getting funded first How marketing, sales, and efficiency initiatives are being prioritized for sustainable growth.
How AI planning really looks for businesses like yours What “moderately ready” means in practice and what most teams still haven’t figured out.
Watch the on-demand webinar and learn what business data really says about growth, efficiency, and AI planning for 2026.
Google To Test Search Changes In EU After DMA Charges, Per Report via @sejournal, @MattGSouthern
Google is preparing to test changes to how search results appear in Europe that would give competing vertical search services more visibility, Reuters reported, citing a person with direct knowledge of the plans.
The test would show results from top-ranked rival services by default alongside Google’s own results for queries related to hotels, flights, and restaurants.
With this test, Google is aiming to avoid a fine under the EU’s Digital Markets Act. The European Commission sent preliminary findings in March, alleging Google Search treats Alphabet’s own services more favorably than rivals under the DMA. Penalties can reach up to 10% of a company’s global annual revenue.
Google has proposed multiple rounds of changes since it first faced DMA charges last year. Those proposals were rejected. Now, Google is moving past proposals to actual testing.
Google has already run smaller-scale experiments with stripped-down search results, removing maps and hotel listings in favor of basic blue links. Businesses criticized those tests after reporting up to 30% drops in free direct booking clicks.
Why This Matters
The DMA case is one of several regulatory and antitrust actions pressuring Google to change how search results work. Each one could change which results appear and how much visibility third-party sites get.
Travel, hospitality, and local business verticals would feel the effects first. Rival services could pull clicks from Google’s integrated results toward other booking platforms and aggregators.
The EU-specific nature of this test matters too. Google has made DMA-specific search changes in European markets that don’t exist elsewhere. EU search results already look different from what you see in other regions, and this test would widen that gap further.
Google has accumulated €9.71 billion ($11.5 billion) in EU antitrust fines since 2017 across various cases. The DMA gives the Commission a separate enforcement tool with penalties that could add billions more.
Looking Ahead
Reuters said the changes would be rolled out across Europe soon. No specific dates were given.
Between the U.S. antitrust remedies and the EU’s DMA enforcement, the rules governing what appears on a Google search results page are changing on multiple fronts.
Gen Z Preference For TikTok Over Google Drops 50%, Data Shows via @sejournal, @MattGSouthern
More U.S. consumers in an Adobe Express survey said they’ve used TikTok for search than in the company’s 2024 survey. But the platform’s position as a Google challenger may be weaker than the headline numbers suggest.
An updated report from Adobe Express, published February 17, surveyed 807 consumers and 200 small business owners in the US about their search habits across platforms. Adobe says the data was collected in January 2026, and that the SurveyMonkey survey was conducted in February 2026.
Forty-nine percent of consumers surveyed said they have used TikTok as a search engine, up 8 percentage points from 41% in Adobe’s 2024 report.
Gen Z Is Pulling Back
Among Gen Z respondents, the share who said they are more likely to rely on TikTok than Google fell from 8% in 2024 to 4% in 2026.
Sixty-five percent of Gen Z still said they’ve used TikTok as a search engine, and 25% found it effective for finding information. But that usage isn’t translating into preference over Google the way it did two years ago.
That tracks with separate reporting from Axios in 2024. The Axios data showed Google still held the top spot as Gen Z’s preferred search starting point, with 46% of users aged 18-24 beginning their queries there.
ChatGPT Pulls Ahead As A Google Alternative
14% of consumers said they are more likely to rely on ChatGPT than on Google as a search engine. That’s double the 7% who said the same about TikTok.
The ChatGPT figure was consistent across age groups, with 12% of Gen Z, 15% of millennials, 15% of Gen X, and 14% of baby boomers. TikTok-over-Google numbers were low across every group and lowest among baby boomers (2%), with millennials (8%) actually higher than Gen Z (4%).
When asked which platforms they found most helpful for search, consumers ranked Google first at 85%, followed by Reddit (29%), ChatGPT (26%), YouTube (24%), and TikTok (16%).
Business Investment Is Cooling
Among the 200 business owners surveyed, 58% had used TikTok for promotions. They allocated an average of 16% of their marketing budget to TikTok content creation and 15% of their SEO budget to TikTok search optimization.
Only 38% said they plan to increase investment in TikTok affiliate marketing, down from 53% who said the same in 2024.
The top challenge business owners reported was converting TikTok engagement into sales (38%), followed by growing follower counts and engagement rates (36%).
Influencer marketing use grew, with 38% of small business owners using TikTok influencers for product sales or promotions, up from 25% in 2024.
Why This Matters
The “TikTok is replacing Google” narrative has been a recurring theme since at least 2022. This data complicates that story. Optimizing for TikTok search still makes sense if your audience skews younger, but the data suggests Gen Z may be settling into a multi-platform pattern rather than abandoning Google.
The ChatGPT numbers are worth watching more closely. If 14% of consumers across all age groups say they’re more likely to rely on ChatGPT than Google, that’s a broader competitive signal than TikTok’s Gen Z niche.
Looking Ahead
Adobe’s report is vendor-funded and conducted via SurveyMonkey with 1,007 respondents (807 consumers and 200 business owners). Adobe says data was collected in January 2026. The sample skews millennial-heavy (53%), with Gen Z making up only 15% of consumers surveyed. No margin of error was disclosed.
The year-over-year comparisons are based on Adobe’s own prior data, not an independently replicated sample. The generational trends are directional rather than definitive.
Still, the direction in the data aligns with broader industry observations. Consumers are using more platforms for search-like behavior, but Google remains dominant. The real competition for Google’s search role, based on this survey at least, may be coming from AI chatbots rather than social video.
Anthropic’s Claude Bots Make Robots.txt Decisions More Granular via @sejournal, @MattGSouthern
Anthropic updated its crawler documentation this week with a formal breakdown of its three web crawlers and their individual purposes.
The page now lists ClaudeBot (training data collection), Claude-User (fetching pages when Claude users ask questions), and Claude-SearchBot (indexing content for search results) as separate bots, each with its own robots.txt user-agent string.
Each bot gets a “What happens when you disable it” explanation. For Claude-SearchBot, Anthropic wrote that blocking it “prevents our system from indexing your content for search optimization, which may reduce your site’s visibility and accuracy in user search results.”
For Claude-User, the language is similar. Blocking it “prevents our system from retrieving your content in response to a user query, which may reduce your site’s visibility for user-directed web search.”
The update formalizes a pattern that’s becoming more common among AI search products. OpenAI runs the same three-tier structure with GPTBot, OAI-SearchBot, and ChatGPT-User. Perplexity operates a two-tier version with PerplexityBot for indexing and Perplexity-User for retrieval.
Anthropic says all three of its bots honor robots.txt, including Claude-User. OpenAI and Perplexity draw a sharper line for user-initiated fetchers, warning that robots.txt rules may not apply to ChatGPT-User and generally don’t apply to Perplexity-User. For Anthropic and OpenAI, blocking the training bot does not block the search bot or the user-requested fetcher.
What Changed From The Old Page
The previous version of Anthropic’s crawler page referenced only ClaudeBot and used broader language about data collection for model development. Before ClaudeBot, Anthropic operated under the Claude-Web and Anthropic-AI user agents, both now deprecated.
The move from one listed crawler to three mirrors what OpenAI did in late 2024 when it separated GPTBot from OAI-SearchBot and ChatGPT-User. OpenAI updated that documentation again in December, adding a note that GPTBot and OAI-SearchBot share information to avoid duplicate crawling when both are allowed.
OpenAI also noted in that December update that ChatGPT-User, which handles user-initiated browsing, may not be governed by robots.txt in the same way as its automated crawlers. Anthropic’s documentation does not make a similar distinction for Claude-User.
Why This Matters
The blanket “block AI crawlers” strategy that many sites adopted in 2024 no longer works the way it did. Blocking ClaudeBot stops training data collection but does nothing about Claude-SearchBot or Claude-User. The same is true on OpenAI’s side.
A BuzzStream study we covered in January found that 79% of top news sites block at least one AI training bot. But 71% also block at least one retrieval or search bot, potentially removing themselves from AI-powered search citations in the process.
That matters more now than it did a year ago. Hostinger’s analysis of 66.7 billion bot requests showed OpenAI’s search crawler coverage growing from 4.7% to over 55% of sites in their sample, even as its training crawler coverage dropped from 84% to 12%. Websites are allowing search bots while blocking training bots, and the gap is widening.
The visibility warnings differ by company. Anthropic says blocking Claude-SearchBot “may reduce” visibility. OpenAI is more direct, telling publishers that sites opted out of OAI-SearchBot won’t appear in ChatGPT search answers, though navigational links may still show up. Both are positioning their search crawlers alongside Googlebot and Bingbot, not alongside their own training crawlers.
What This Means
When managing robots.txt files, the old copy-paste block list needs an audit. SEJ’s complete AI crawler list includes verified user-agent strings across every company.
A strategic robots.txt now requires separate entries for training and search bots at minimum, with the understanding that user-initiated fetchers may not follow the same rules.
Looking Ahead
The three-tier split creates a new category of publisher decision that parallels what Google did years ago with Google-Extended. That user-agent lets sites opt out of Gemini training while staying in Google Search results. Now Anthropic and OpenAI offer the same separation for their platforms.
As AI-powered search grows its share of referral traffic, the cost of blocking search crawlers increases. The Cloudflare Year in Review data we reported in December showed AI crawlers already account for a measurable share of web traffic, and the gap between crawling volume and referral traffic remains wide. How publishers navigate these three-way decisions will shape how much of the web AI search tools can actually surface.
AI-SEO Is A Change Management Problem via @sejournal, @Kevin_Indig
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
AI-SEO transformation will fail at the alignment layer, not the tactics layer. 25 years of transformation research, spanning 10,800+ participants across industries, reveals that the gap between successful and failed initiatives isn’t technical skill. It’s organizational readiness.
What you’ll get:
Why AI SEO implementation challenges are people and process problems, not technical ones.
The specific alignment failures that kill AI-SEO initiatives before tactics ever get tested.
A sequenced approach that transforms you from channel executor to organizational translator.
The underlying infrastructure of AI SEO – retrieval-augmented generation, citation selection, answer synthesis – operates on different principles than the crawl-index-rank paradigm SEO teams previously mastered. And unlike past shifts, the old playbook doesn’t bend to fit the new reality.
AI SEO is different. It’s not just an algorithm update: This is a search product change and a user behavior movement.
Our classic instinct is to respond with tactics: prompt optimization, entity markup increase, LLM-specific structured data, citation acquisition strategies.
These aren’t wrong. But long-term, it’s likely AI SEO strategies will fail, and the reason isn’t tactical incompetence or lack of staying up-to-date and flexible. It’s internal organizational misalignment.
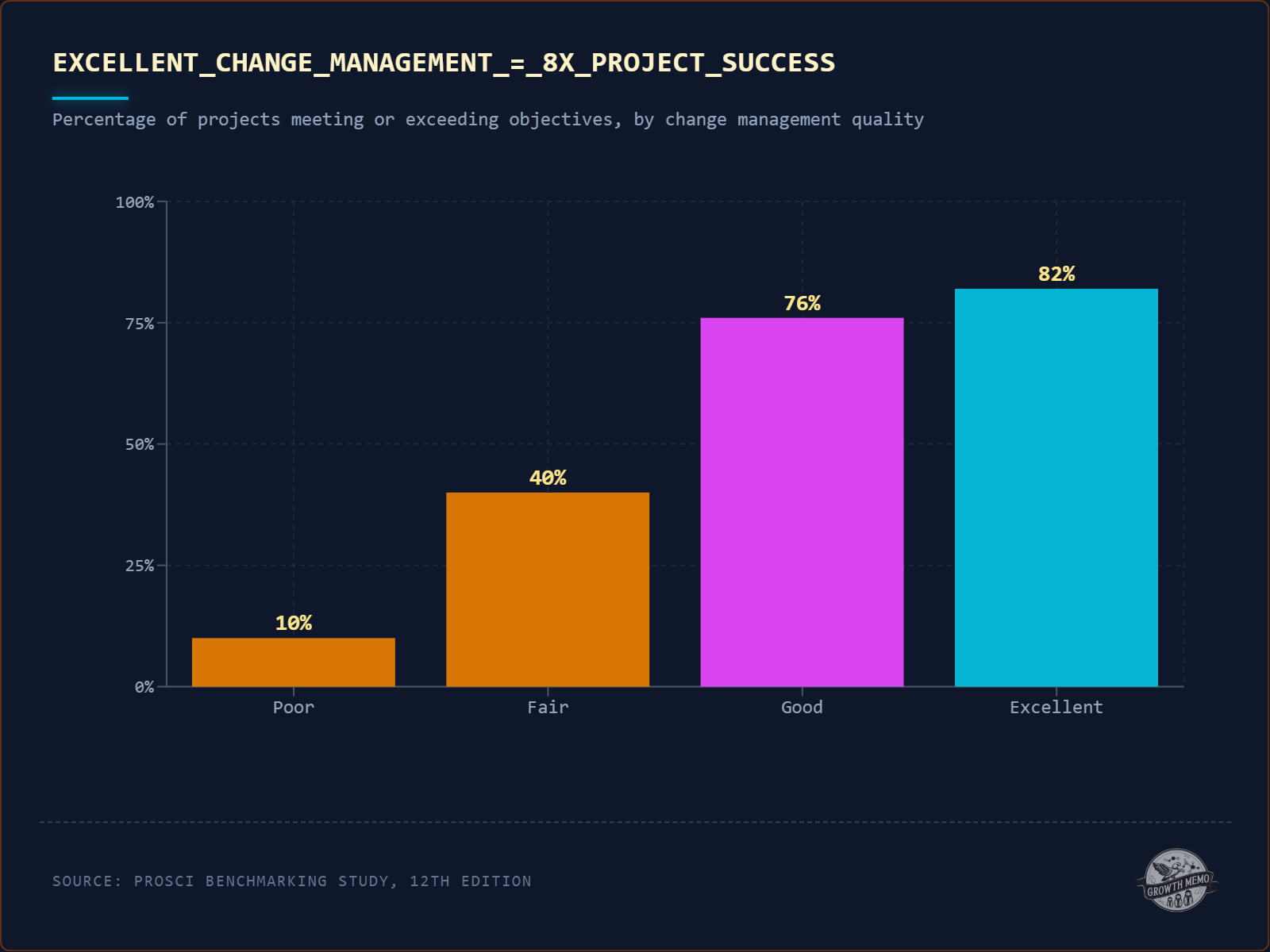
Organizations with structured change management are 8× more likely to meet transformation objectives. The same principle applies to AI-SEO. (Image Credit: Kevin Indig)
Your marketing team – and your executive team – is being asked to transform their understanding of SEO during a period of unprecedented change fatigue. Those who have survived two decades of algorithm updates are expertly adaptable, but reeducation is required because LLMs are a new product, not just another layer of search.
And this, of course, is the alignment layer fail.
Image Credit: Kevin Indig
In AI SEO, misalignment has specific symptoms:
Conflicting definitions of success: One stakeholder wants “rankings in ChatGPT.” Another wants brand mentions. A third wants citation links. A fourth wants traffic recovery. Every experiment gets judged against a different standard, and no one has agreed which matters most or how they’ll be measured. (Although our AI Overview and AI Mode studies confirm brand mentions are more valuable than citations.)
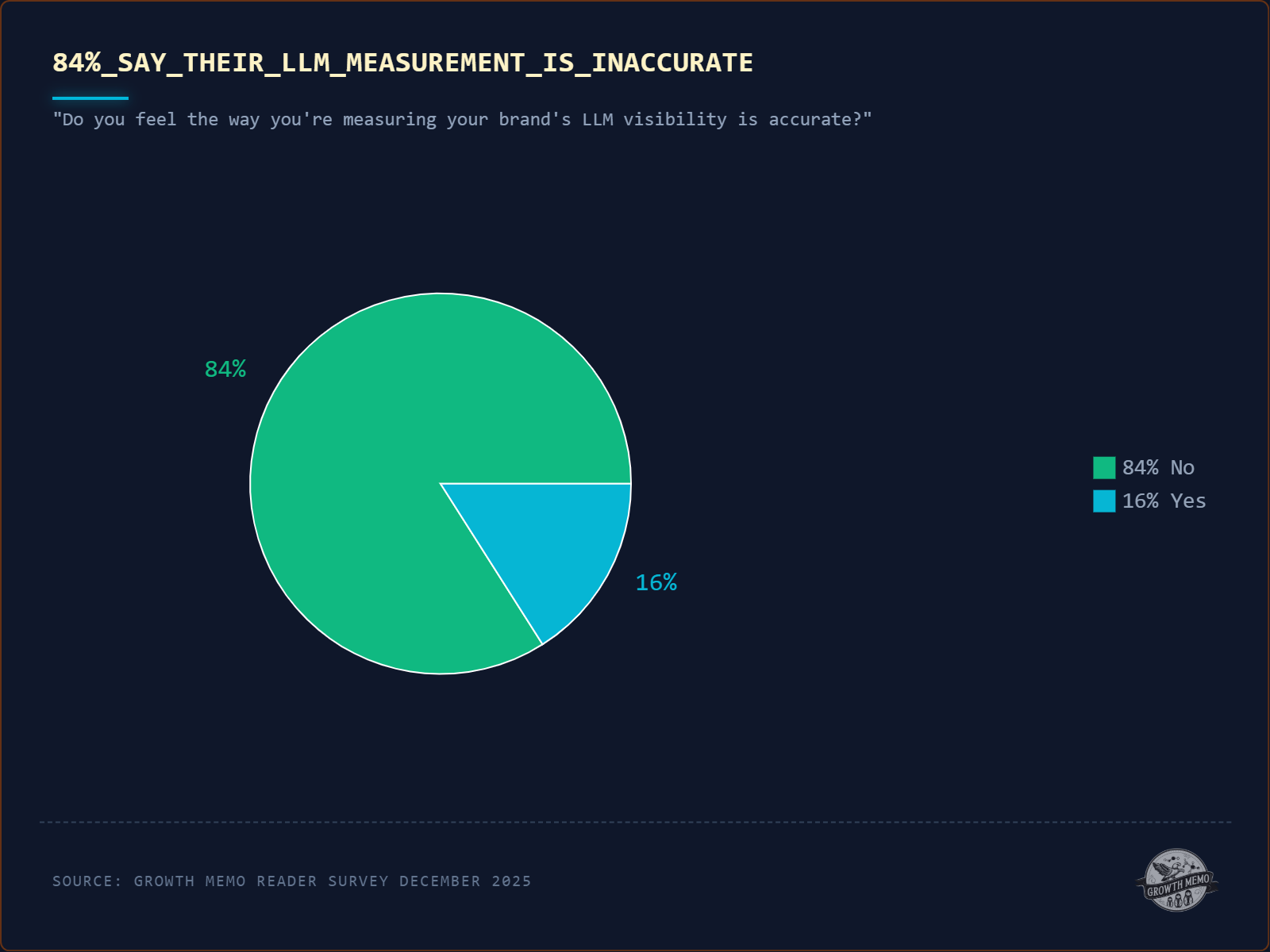
Metrics mismatch with leadership expectations: Executives ask for increased traffic in a growing zero-click environment. Classic SEO reports on influence metrics; leadership sees declining sessions and questions the investment. In our December 2025 Growth Memo reader survey, 84% of respondents said they feel their current LLM visibility measurement approach is inaccurate. Teams can’t prove value because no one has agreed on how value would be proven.
Turf fragmentation: AI SEO touches SEO, content, brand, product, PR, and (at times) legal. Without explicit ownership and a baseline, agreed-upon understanding of your brand’s AI SEO approach, each team runs experiments in its silo. No one synthesizes learning. Conflicting tactics cancel each other out.
Premature tactics without a shared foundation: This looks like “Let’s test prompts” without agreeing on what success means; “Let’s scale AI content to mitigate click loss” without understanding AI-assisted versus AI-generated content limits; “Let SEO handle AI” while product, PR, and legal stay uninvolved.
Panic-testing instead of strategic reorientation: Teams deploy short-term tactics reactively rather than reorienting the whole ship for better long-term outcomes.
This is classic change management failure: unclear mandate, fragmented ownership, mismatched incentives. No amount of tactical excellence or smart strategy pivots can fix it.
Layering AI SEO tactics + tools on top without structured change management compounds fatigue and accelerates burnout. The “scrappy resilience” that has carried the industry in the past can’t be assumed to instantly apply to this new channel without a strategic transition.
A baseline understanding of organizational change management matters in the AI SEO era … because most organizational transformations fail or underperform.
Your AI-SEO initiative is no different, even if changes in SEO seem contained to your marketing and product teams and stakeholders, rather than the larger organization or brand as a whole.
I’d argue that AI SEO falls into the category of industry transformation that affects your brand and org. And from decades of research, failure and underperformance are the statistical norm for these big transitions – seasoned leaders know this already. No wonder they’re skeptical of your AI SEO plans.
One McKinsey survey found fewer than one-third of teams succeed at both improving performance and sustaining improvements during significant shifts. BCG’s forensic analysis of 825 executives across 70 companies found transformation success at 30%.
Multiple major consulting firms’ independent research shows that most change transformations underperform.
Assuming that tactical excellence alone will carry you – without strategic reeducation and thoughtful change management as our industry shifts – is assuming you’re the exception to the rule.
The correlation between the quality of managing a big shift and your project’s success is dramatic:
Image Credit: Kevin Indig
The gap between excellent and poor represents a nearly 8x improvement. Even the jump from poor to fair quadruples success rates.
BCG’s 2020 analysis reinforces this from a different angle, noting six critical factors that increase successful transformation odds from 30% to 80%:
Integrated strategy with clear goals: This is where a carefully crafted AI SEO strategy comes in, one that not only outlines growth goals, but also clear testing and what successful outcomes look like.
Leadership commitment from the CEO through middle management: If you’re a consultant or agency, this step can’t be skipped, especially if they have an in-house team assisting in executing the strategy.
High-caliber talent deployment: Or I would argue, high-quality reeducation of existing talent – make sure all operators have a baseline shared understanding of what has changed about SEO, how LLM outputs work, what the brand’s goals are, and how it will be executed.
Flexible, agile governance: Teams should have the ability to deal with individual challenges without losing sight of the broader goals, including removing barriers quickly.
Effective monitoring: Establish core, agreed-upon KPIs to measure what winning would look like, and note what actions were taken when.
Modern/updated technology: Your SEO team needs the right tools to succeed, but they also need to know how to use them effectively. Don’t skip allotting time for integration of new workflows and AI monitoring systems.
Marketing teams that treat AI-SEO simply as a technical project to execute or tactics to update are leaving an 8× multiplier on the table.
BCG’s 2024 AI implementation study found that roughly 70% of change implementation hurdles relate to people and processes. Only about 10% of challenges were purely technical.
A 2024 Kyndryl survey found that while 95% of senior executives reported investing in AI, only 14% felt they had successfully aligned workforce strategies.
Your brand’s ability to test, update tactics, learn AI workflows, implement structured data, and optimize for LLM retrieval is not the bottleneck you need to be concerned about.
The real concern is whether your team – leadership, cross-functional team partners, and frontline executors/operators – is aligned on what AI SEO means, why and how you’re making changes from your classic SEO approach, what success looks like, and who owns outcomes.
Active and visible executive sponsorship is the No. 1 contributor to change success, cited 3-to-1 more frequently than any other factor, according to 25 years of benchmarking research by Prosci. Your first step as the person leading the AI SEO charge for your brand (or across your clients) is to earn executive buy-in.
But the head of SEO cannot transform a brand’s understanding and approach to AI SEO alone. Bain’s 2024 research emphasized that successful transformations “drive change from the middle of the organization out.”
Keep in mind, financial benefits can compound quickly: One research analysis of 600 organizations found “change accelerators” experience greater revenue growth than companies with below-average change effectiveness.
Image Credit: Kevin Indig
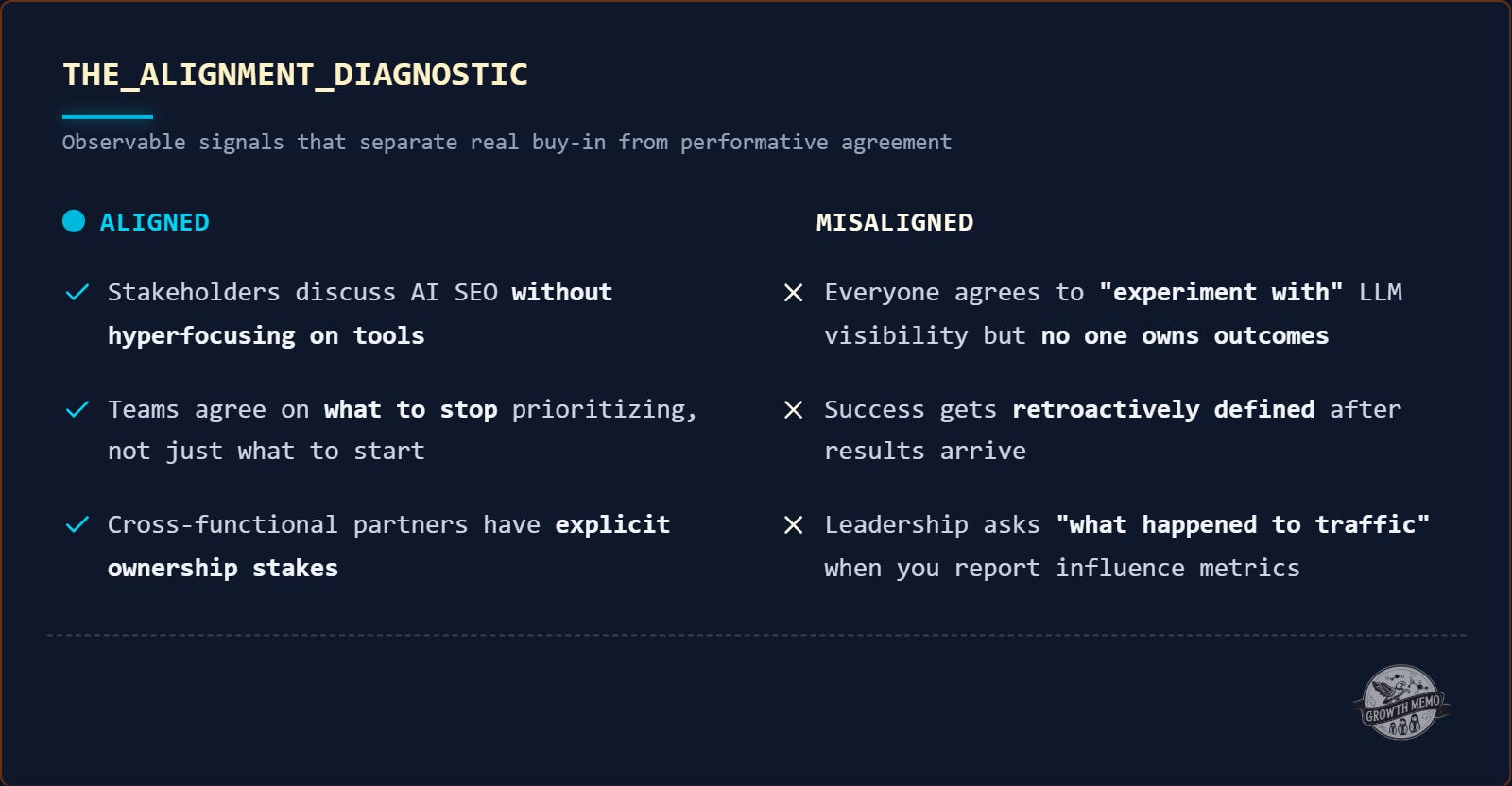
Alignment isn’t just a feeling; it’s observable. You’ll know when you get there:
Stakeholders can talk through AI SEO without hyperfocusing on tools.
Teams agree on what to stop prioritizing (not just what to start).
Cross-functional partners have explicit ownership stakes.
Alignment isn’t happening when:
Everyone is good with “experimenting with” or “investing in” LLM visibility, but no one owns outcomes.
Success gets retroactively defined, or
Leadership asks, “What happened to traffic?” when you report influence metrics.
Noah Greenberg, CEO at Stacker, outlined this pretty clearly in a recent LinkedIn post: Step 0 in your AI SEO transformation is to become the expert.
Screenshot from LinkedIn by Kevin Indig, February 2026
Educating stakeholders on the structural differences between classic search engines and LLM retrieval – guiding teams to explain why your CEO doesn’t see the same LLM output when they look up the brand vs. what you’re reporting.
Explaining the tradeoffs, not just opportunities.
Setting expectations executives won’t like at first, but need to hear (traffic loss or slower growth than in years prior).
This is uncomfortable. Less direct control. More indirect influence. Higher stakes.
Your mindset – as the change agent for your clients or organization – centers on three principles:
Honesty over confidence. What we don’t know: the precise value of an AI mention. What we do know: your brand not appearing for related topics is a measurable miss.
Progress over perfection. Alignment doesn’t require certainty. It requires shared uncertainty, agreeing on what you’re testing and how you’ll learn.
Translation over broadcasting. The same strategic message needs adaptation for ICs (how their work changes), managers (how they report success), and executives (how budgets should shift). Uniform communication fails; translated communication scales.
Do this in order:
Write the one-sentence AI SEO mandate for your organization. If you can’t explain AI SEO in one sentence to leadership, you’re not ready to execute.
Complete a high-level SWOT. Identify where your organization has existing strengths and gaps. The Brand SEO scorecard from The Great Decoupling will walk you through.
Replace or supplement legacy KPIs. Add LLM visibility estimates alongside classic KPIs (rankings, sessions) to start the transition. Reporting both builds the case for the shift without abandoning the old model cold.
Name cross-functional owners explicitly. Who owns brand mentions in LLM outputs: SEO, PR, or brand? Who owns citation link acquisition: SEO or content? Ambiguity is the enemy.
Provide baseline education at every level. ICs need to understand how LLM retrieval differs from crawl-index-rank. Executives need to understand why slowed organic traffic or zero-click growth doesn’t mean zero impact.
Kill one SEO practice without a fight. Success means everyone understands why, and you don’t receive pushback. If you can’t retire one outdated tactic without internal conflict, you haven’t achieved alignment.
Only then change workflows and tactics. Tactics deployed on an unaligned organization waste resources and burn credibility. Tactics deployed on an aligned organization compound advantage.
Featured Image: Summit Art Creations/Search Engine Journal
Web Almanac Data Reveals CMS Plugins Are Setting Technical SEO Standards (Not SEOs) via @sejournal, @chrisgreenseo
If more than half the web runs on a content management system, then the majority of technical SEO standards are being positively shaped before an SEO even starts work on it. That’s the lens I took into the 2025 Web Almanac SEO chapter (for clarity, I co-authored the 2025 Web Almanac SEO chapter referenced in this article).
Rather than asking how individual optimization decisions influence performance, I wanted to understand something more fundamental: How much of the web’s technical SEO baseline is determined by CMS defaults and the ecosystems around them.
SEO often feels intensely hands-on – perhaps too much so. We debate canonical logic, structured data implementation, crawl control, and metadata configuration as if each site were a bespoke engineering project. But when 50%+ of pages in the HTTP Archive dataset sit on CMS platforms, those platforms become the invisible standard-setters. Their defaults, constraints, and feature rollouts quietly define what “normal” looks like at scale.
How CMS adoption trends track with core technical SEO signals.
Where plugin ecosystems appear to shape implementation patterns.
And how emerging standards like llms.txt are spreading as a result.
The question is not whether SEOs matter. It’s whether we’ve been underestimating who sets the baseline for the modern web.
The Backbone Of Web Design
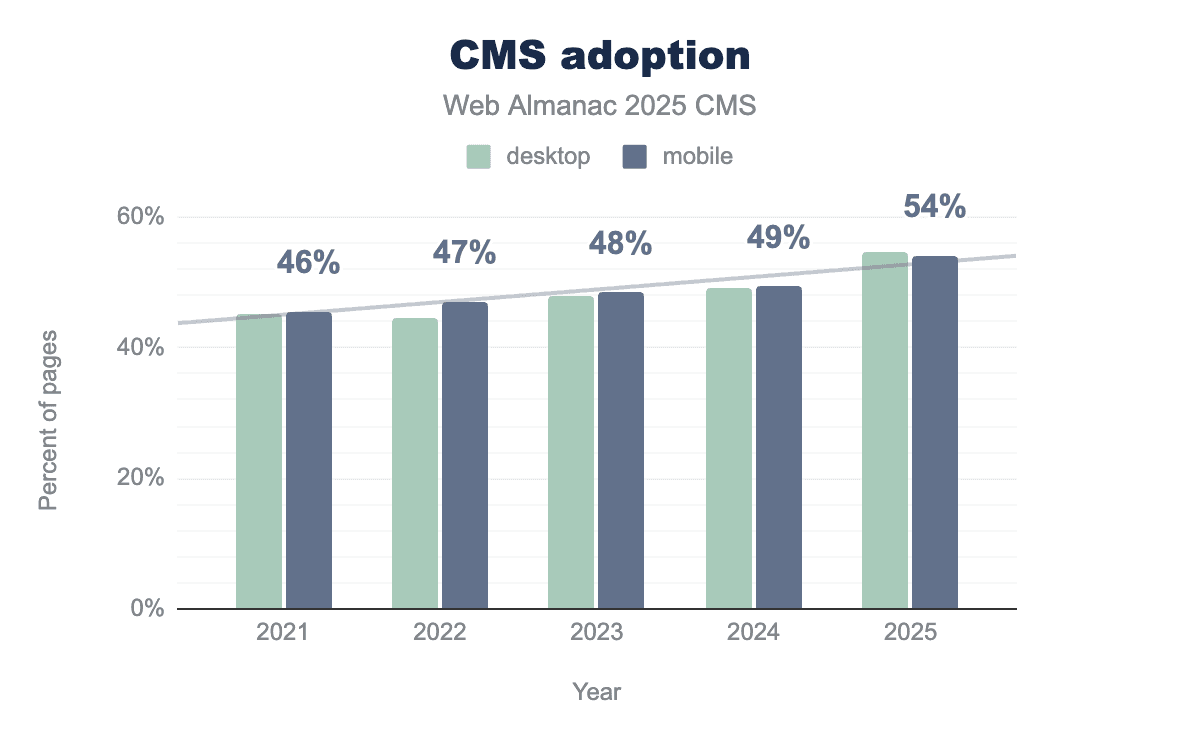
The 2025 CMS chapter of the Web Almanac saw a milestone hit with CMS adoption; over 50% of pages are on CMSs. In case you were unsold on how much of the web is carried by CMSs, over 50% of 16 million websites is a significant amount.
WordPress is still the most used CMS, by a long way, even if it has dropped marginally in the 2024 data. Shopify, Wix, Squarespace, and Joomla trail a long way behind, but they still have a significant impact, especially Shopify, on ecommerce specifically.
SEO Functions That Ship As Defaults In CMS Platforms
CMS platform defaults are important, this – I believe – is that a lot of basic technical SEO standards are either default setups or for the relatively small number of websites that have dedicated SEOs or people who at least build to/work with SEO best practice.
When we talk about “best practice,” we’re on slightly shaky ground for some, as there isn’t a universal, prescriptive view on this one, but I would consider:
Descriptive “SEO-friendly” URLs.
Editable title and meta description.
XML sitemaps.
Canonical tags.
Meta robots directive changing.
Structured data – at least a basic level.
Robots.txt editing.
Of the main CMS platforms, here is what they – self-reportedly – have as “default.” Note: For some platforms – like Shopify – they would say they’re SEO-friendly (and to be honest, it’s “good enough”), but many SEOs would argue that they’re not friendly enough to pass this test. I’m not weighing into those nuances, but I’d say both Shopify and those SEOs make some good points.
CMS
SEO-friendly URLs
Title & meta description UI
XML sitemap
Canonical tags
Robots meta support
Basic structured data
Robots.txt
WordPress
Yes
Partial (theme-dependent)
Yes
Yes
Yes
Limited (Article, BlogPosting)
No (plugin or server access required)
Shopify
Yes
Yes
Yes
Yes
Limited
Product-focused
Limited (editable via robots.txt.liquid, constrained)
Wix
Yes
Guided
Yes
Yes
Limited
Basic
Yes (editable in UI)
Squarespace
Yes
Yes
Yes
Yes
Limited
Basic
No (platform-managed, no direct file control)
Webflow
Yes
Yes
Yes
Yes
Yes
Manual JSON-LD
Yes (editable in settings)
Drupal
Yes
Partial (core)
Yes
Yes
Yes
Minimal (extensible)
Partial (module or server access)
Joomla
Yes
Partial
Yes
Yes
Yes
Minimal
Partial (server-level file edit)
Ghost
Yes
Yes
Yes
Yes
Yes
Article
No (server/config level only)
TYPO3
Yes
Partial
Yes
Yes
Yes
Minimal
Partial (config or extension-based)
Based on the above, I would say that most SEO basics can be covered by most CMSs “out of the box.” Whether they work well for you, or you cannot achieve the exact configuration that your specific circumstances require, are two other important questions – ones which I am not taking on. However, it often comes down to these points:
It is possible for these platforms to be used badly.
It is possible that the business logic you need will break/not work with the above.
There are many more advanced SEO features that aren’t out of the box, that are just as important.
We are talking about foundations here, but when I reflect on what shipped as “default” 15+ years ago, progress has been made.
Fingerprints Of Defaults In The HTTP Archive Data
Given that a lot of CMSs ship with these standards, do these SEO defaults correlate with CMS adoption? In many ways, yes. Let’s explore this in the HTTP Archive data.
Canonical Tag Adoption Correlates With CMS
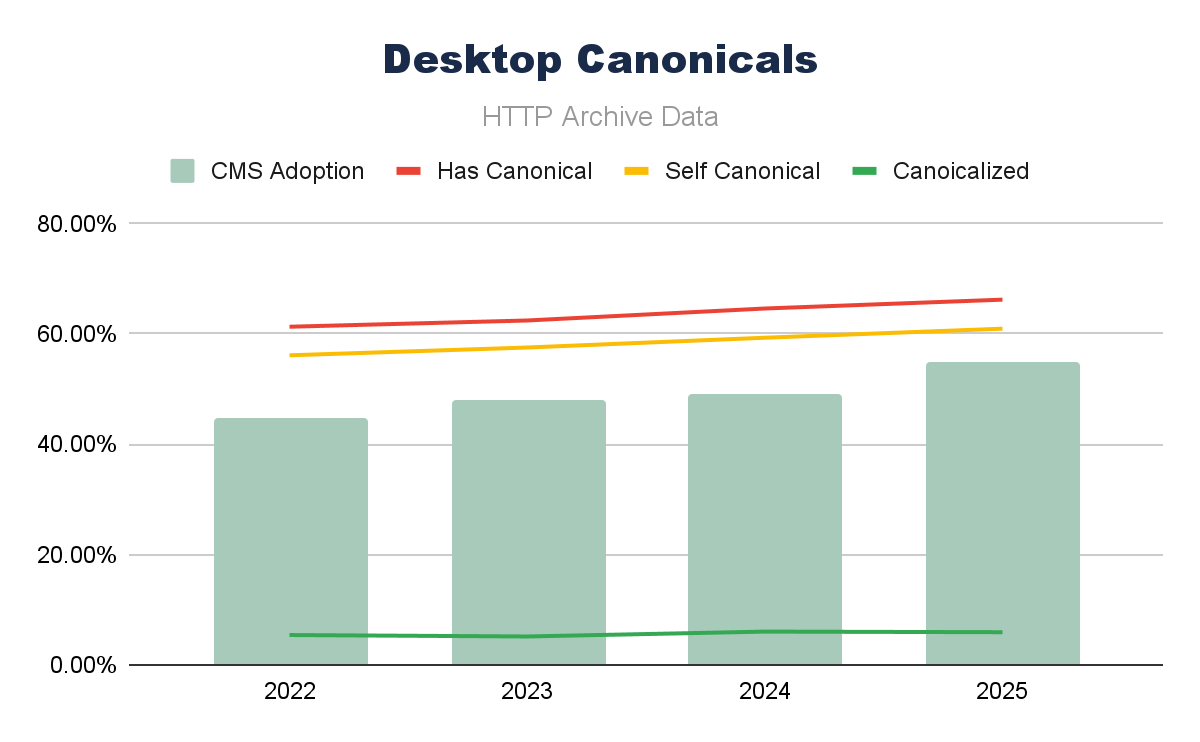
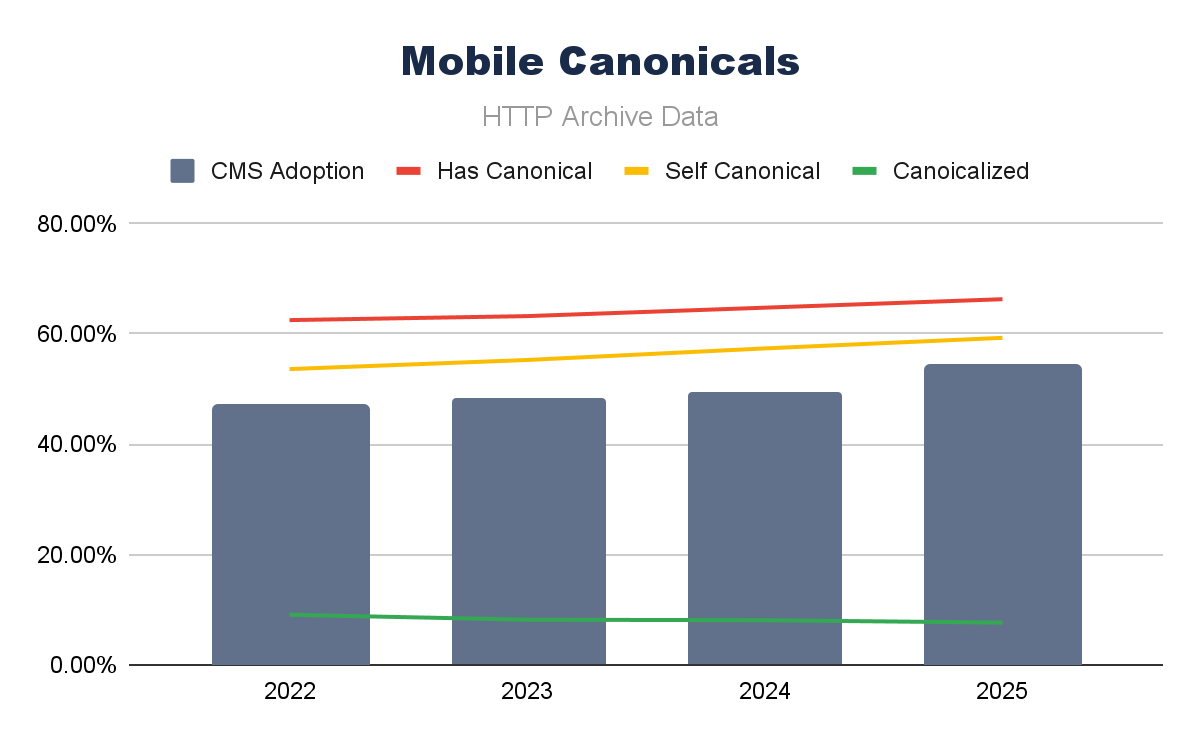
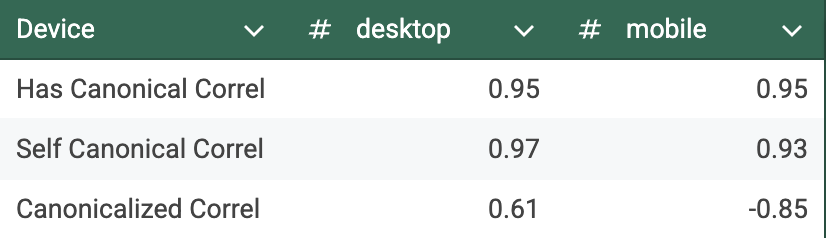
Combining canonical tag adoption data with (all) CMS adoption over the last four years, we can see that for both mobile and desktop, the trends seem to follow each other pretty closely.
Image by author, February 2026Image by author, February 2026
Running a simple Pearson correlation over these elements, we can see this strong correlation even clearer, with canonical tag implementation and the presence of self-canonical URLs.
Image by author, February 2026
What differs is the mobile correlation of canonicalized URLs; that seems to be a negative correlation on mobile and a lower (but still positive) correlation on desktop. A drop in canonicalized pages is largely causing this negative correlation, and the reasons behind this could be many (and harder to be sure of).
Canonical tags are a crucial element for technical SEO; their continued adoption does certainly seem to track the growth in CMS use, too.
Schema.org Data Types Correlate With CMS
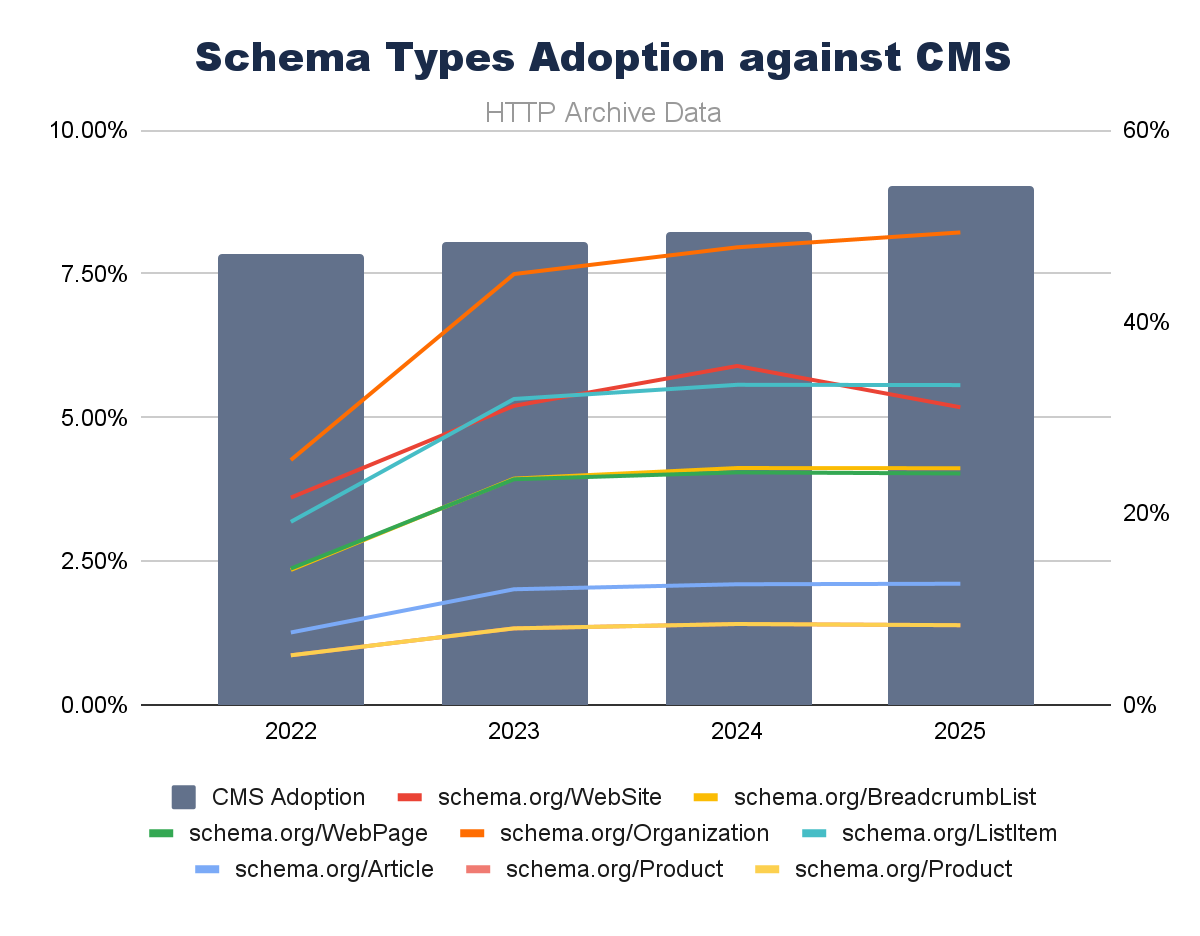
Schema.org types against CMS adoption show similar trends, but are less definitive overall. There are many different types of Schema.org, but if we plot CMS adoption against the ones most common to SEO concerns, we can observe a broadly rising picture.
Image by author, February 2026
With the exception of Schema.org WebSite, we can see CMS growth and structured data following similar trends.
But we must note that Schema.org adoption is quite considerably lower than CMSs overall. This could be due to most CMS defaults being far less comprehensive with Schema.org. When we look at specific CMS examples (shortly), we’ll see far-stronger links.
Schema.org implementation is still mostly intentional, specialist, and not as widespread as it could be. If I were a search engine or creating an AI Search tool, would I rely on universal adoption of these, seeing the data like this? Possibly not.
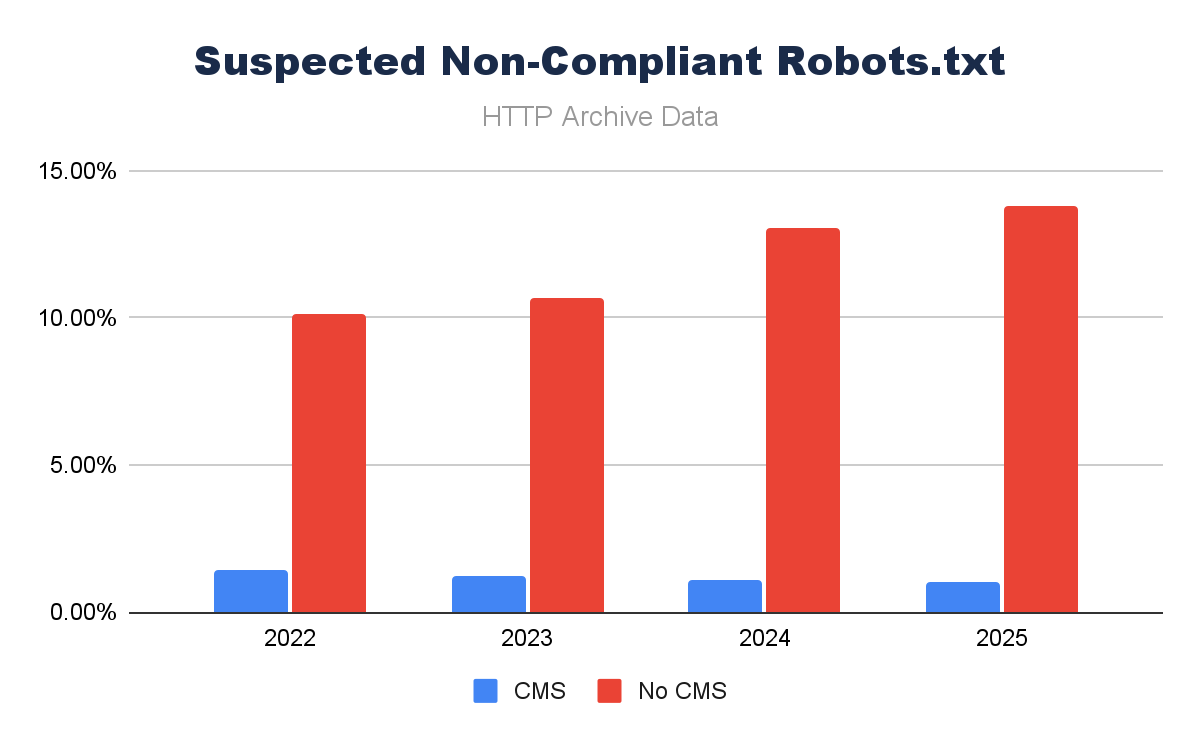
Robots.txt
Given that robots.txt is a single file that has some agreed standards behind it, its implementation is far simpler, so we could anticipate higher levels of adoption than Schema.org.
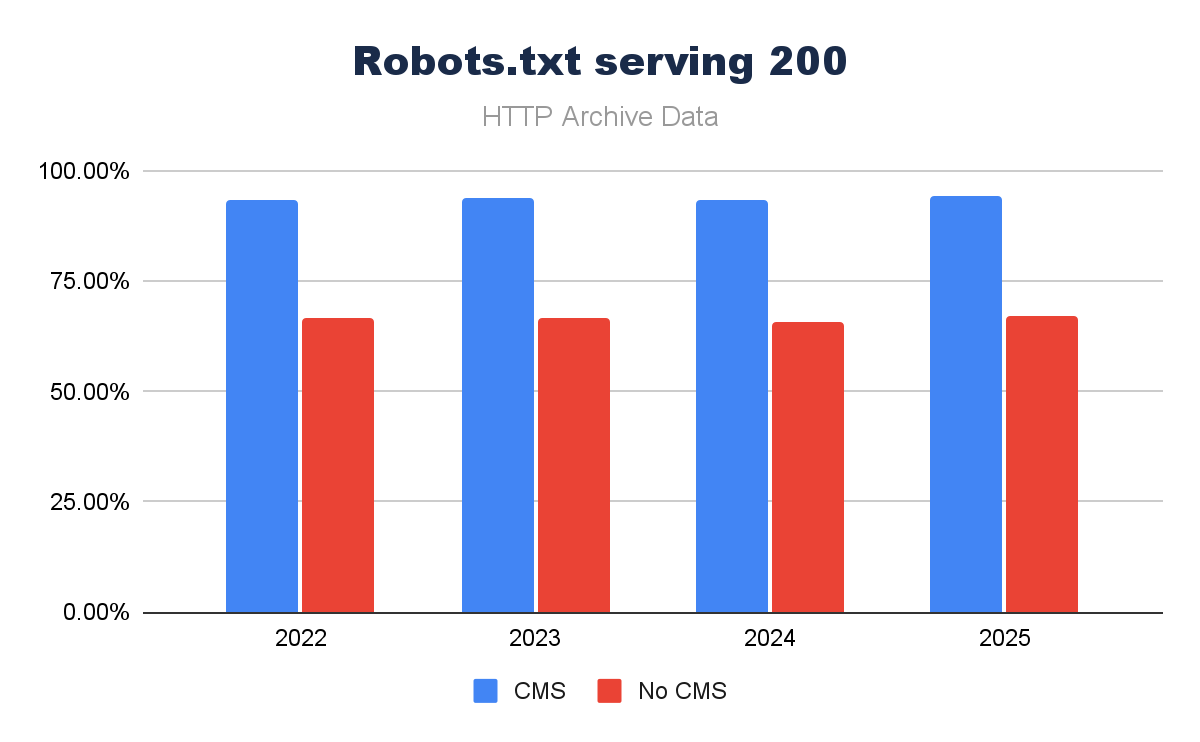
The presence of a robots.txt is pretty important, mostly to limit crawl of search engines to specific areas of the site. We are starting to see an evolution – we noted in the 2025 Web Almanac SEO chapter – that the robots.txt is used even more as a governance piece, rather than just housekeeping. A key sign that we’re using our key tools differently in the AI search world.
But before we consider the more advanced implementations, how much of a part does a CMS have in ensuring a robots.txt is present? Looks like over the last four years, CMS platforms are driving a significant amount more of robots.txt files serving a 200 response:
Image by author, February 2026
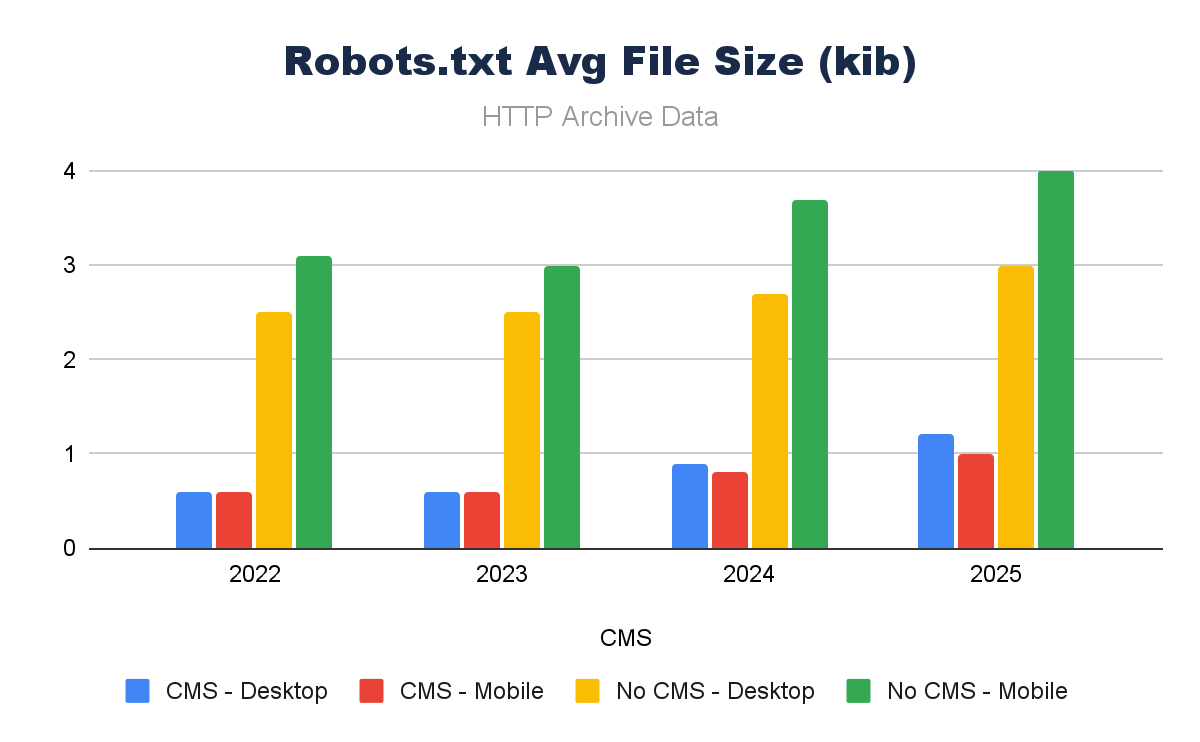
What is more curious, however, is when you consider the file of the robots.txt files. Non-CMS platforms have robots.txt files that are significantly larger.
Image by author, February 2026
Why could this be? Are they more advanced in non-CMS platforms, longer files, more bespoke rules? Most probably in some cases, but we’re missing another impact of a CMSs standards – compliant (valid) robots.txt files.
A lot of robots.txt files serve a valid 200 response, but often they’re not txt files, or they’re redirecting to 404 pages or similar. When we limit this list to only files that contain user-agent declarations (as a proxy), we see a different story.
Image by author, February 2026
Approaching 14% of robots.txt files served on non-CMS platforms are likely not even robots.txt files.
A robots.txt is easy to set up, but it is a conscious decision. If it’s forgotten/overlooked, it simply won’t exist. A CMS makes it more likely to have a robots.txt, and what’s more, when it is in place, it makes it easier to manage/maintain – which IS key.
WordPress Specific Defaults
CMS platforms, it seems, cover the basics, but more advanced options – which still need to be defaults – often need additional SEO tools to enable.
Interrogating WordPress-specific sites with the HTTP Archive data will be easiest as we get the largest sample, and the Wapalizer data gives a reliable way to judge the impact of WordPress-specific SEO tools.
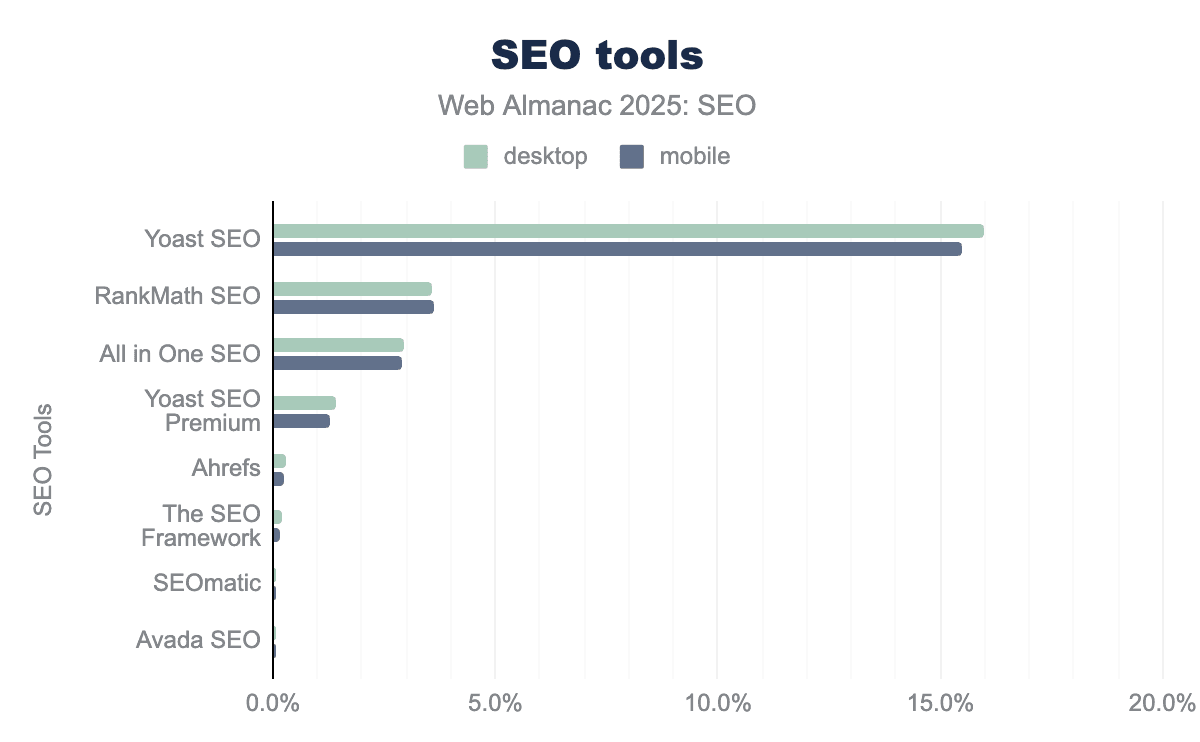
From the Web Almanac, we can see which SEO tools are the most installed on WordPress sites.
Screenshot from Web Almanac, February 2026
For anyone working within SEO, this is unlikely to be surprising. If you are an SEO and worked on WordPress, there is a high chance you have used either of the top three. What IS worth considering right now is that while Yoast SEO is by far the most prevalent within the data, it is seen on barely over 15% of sites. Even the most popular SEO plugin on the most popular CMS is still a relatively small share.
Of these top three plugins, let’s first consider what the differences of their “defaults” are. These are similar to some of WordPress’s, but we can see many more advanced features that come as standard.
Editable metadata, structured data, robots.txt, sitemaps, and, more recently, llms.txt are the most notable. It is worth noting that a lot of the functionality is more “back-end,” so not something we’d be as easily able to see in the HTTP Archive data.
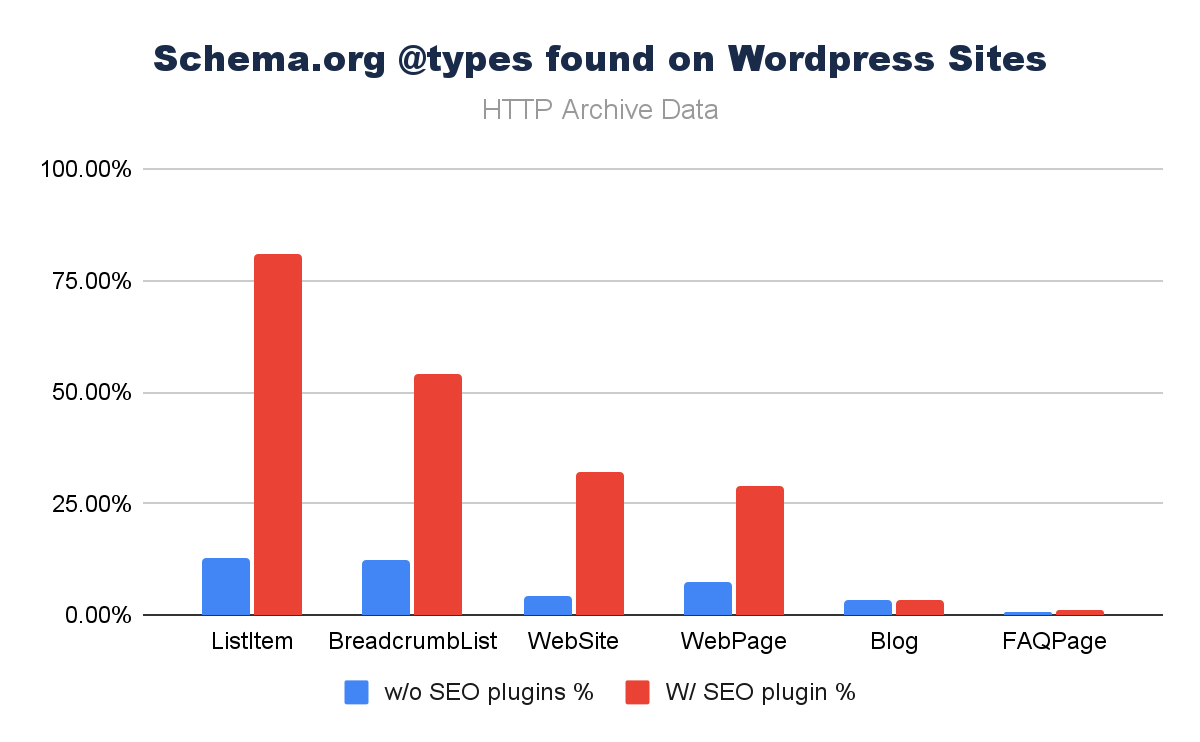
Structured Data Impact From SEO Plugins
We can see (above) that structured data implementation and CMS adoption do correlate; what is more interesting here is to understand where the key drivers themselves are.
Viewing the HTTP Archive data with a simple segment (SEO plugins vs. no SEO plugins), from the most recent scoring paints a stark picture.
Image by author, February 2026
When we limit the Schema.org @types to the most associated with SEO, it is really clear that some structured data types are pushed really hard using SEO plugins. They are not completely absent. People may be using lesser-known plugins or coding their own solutions, but ease of implementation is implicit in the data.
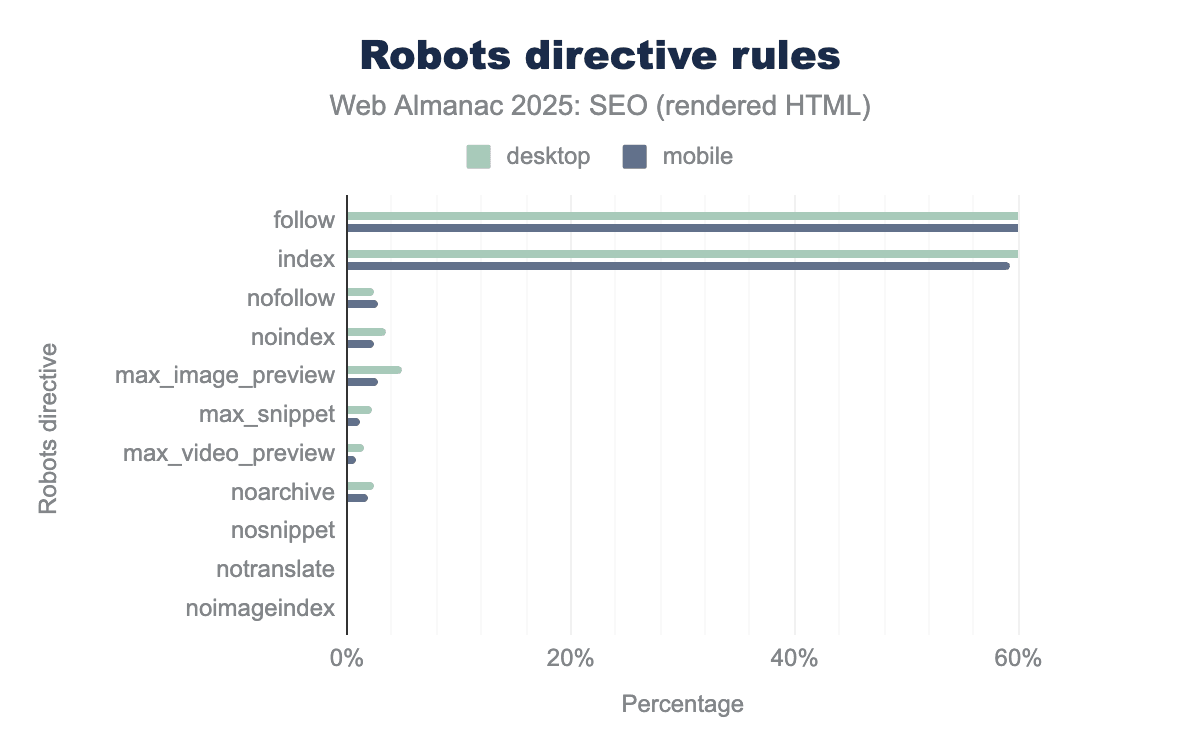
Robots Meta Support
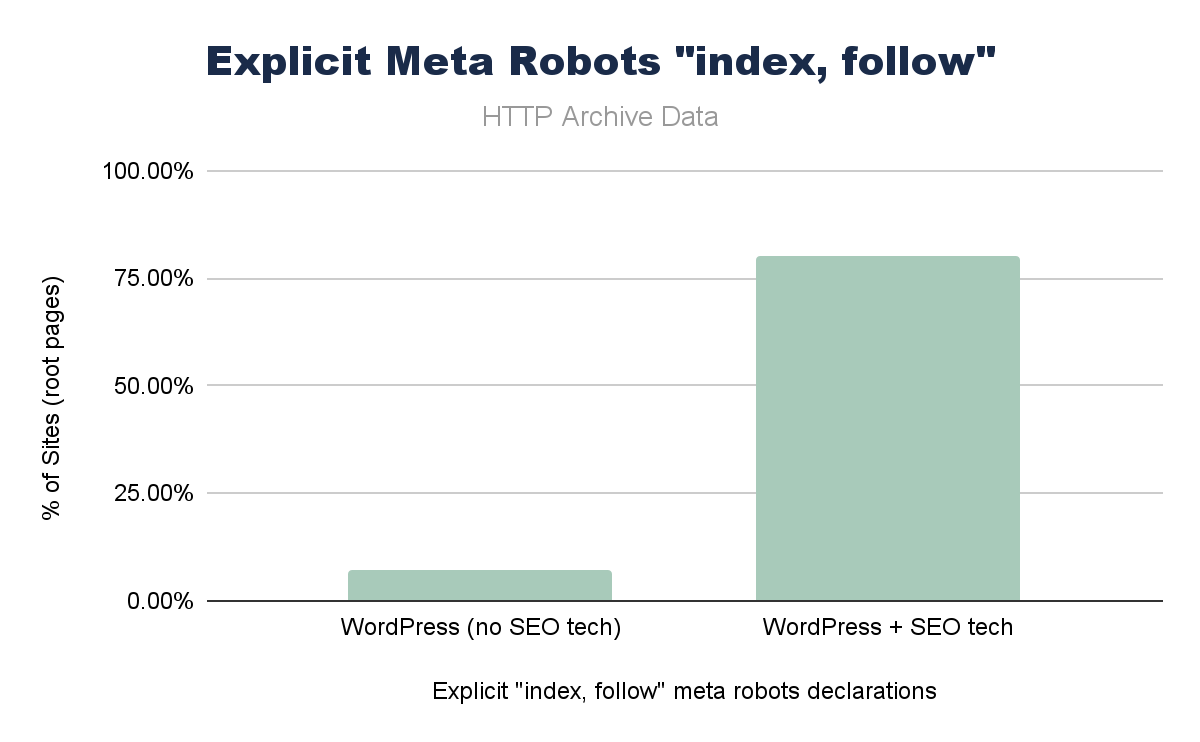
Another finding from the SEO Web Almanac 2025 chapter was that “follow” and “index” directives were the most prevalent, even though they’re technically redundant, as having no meta robots directives is implicitly the same thing.
Screenshot from Web Almanac 2025, February 2026
Within the chapter number crunching itself, I didn’t dig in much deeper, but knowing that all major SEO WordPress plugins have “index,follow” as default, I was eager to see if I could make a stronger connection in the data.
Where SEO plugins were present on WordPress, “index, follow” was set on over 75% of root pages vs. <5% of WordPress sites without SEO plugins.
Image by author, February 2026
Given the ubiquity of WordPress and SEO plugins, this is likely a huge contributor to this particular configuration. While this is redundant, it isn’t wrong, but it is – again – a key example of whether one or more of the main plugins establish a de facto standard like this, it really shapes a significant portion of the web.
Diving Into LLMs.txt
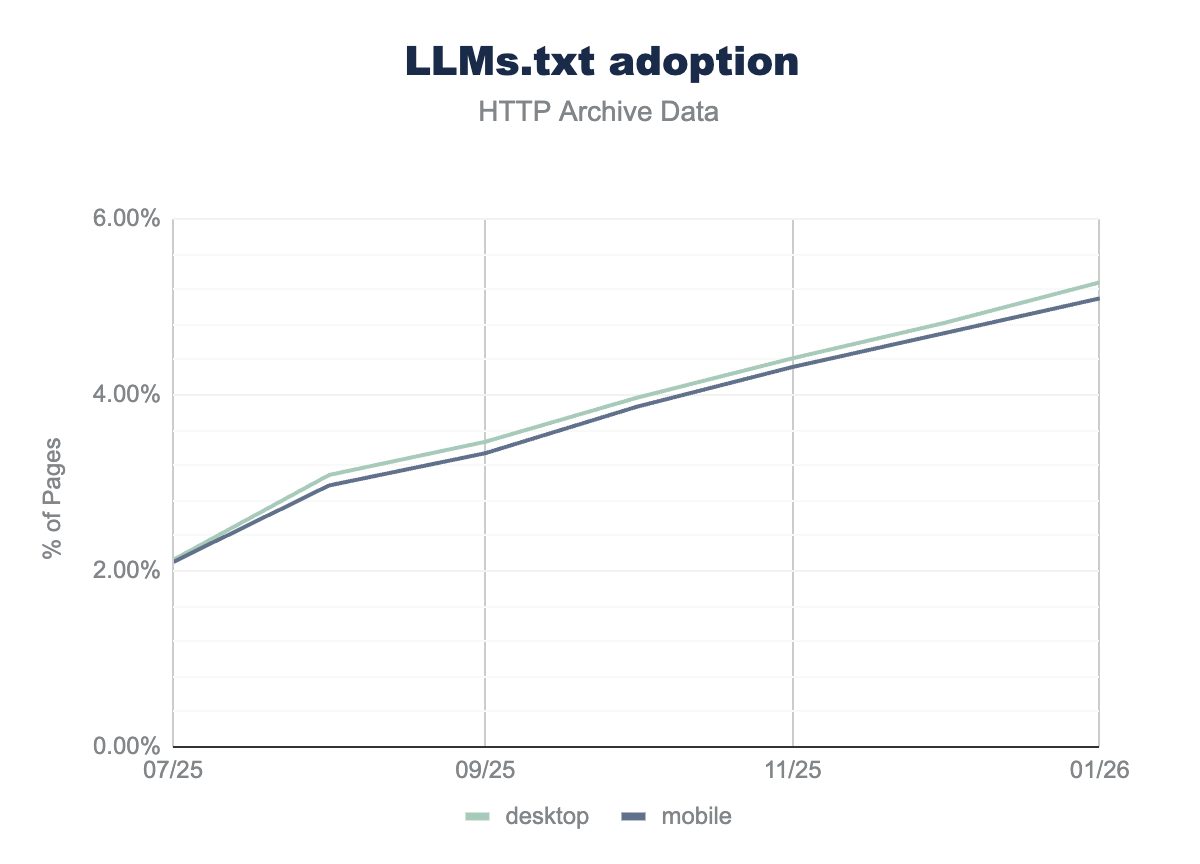
Another key area of change from the 2025 Web Almanac was the introduction of the llms.txt file. Not an explicit endorsement of the file, but rather a tacit acknowledgment that this is an important data point in the AI Search age.
From the 2025 data, just over 2% of sites had a valid llms.txt file and:
39.6% of llms.txt files are related to All-in-One SEO.
3.6% of llms.txt files are related to Yoast SEO.
This is not necessarily an intentional act by all those involved, especially as Rank Math enables this by default (not an opt-in like Yoast and All-in-One SEO).
Image by author, February 2026
Since the first data was gathered on July 25, 2025 if we take a month-by-month view of the data, we can see further growth since. It is hard not to see this as growing confidence in this markup OR at least, that it’s so easy to enable, more people are likely hedging their bets.
Conclusion
The Web Almanac data suggests that SEO, at a macro level, moves less because of individual SEOs and more because WordPress, Shopify, Wix, or a major plugin ships a default.
Canonical tags correlate with CMS growth.
Robots.txt validity improves with CMS governance.
Redundant “index,follow” directives proliferate because plugins make them explicit.
Even llms.txt is already spreading through plugin toggles before it even gets full consensus.
This doesn’t diminish the impact of SEO; it reframes it. Individual practitioners still create competitive advantage, especially in advanced configuration, architecture, content quality, and business logic. But the baseline state of the web, the technical floor on which everything else is built, is increasingly set by product teams shipping defaults to millions of sites.
Perhaps we should consider that if CMSs are the infrastructure layer of modern SEO, then plugin creators are de facto standards setters. They deploy “best practice” before it becomes doctrine
This is how it should work, but I am also not entirely comfortable with this. They normalize implementation and even create new conventions simply by making them zero-cost. Standards that are redundant have the ability to endure because they can.
So the question is less about whether CMS platforms impact SEO. They clearly do. The more interesting question is whether we, as SEOs, are paying enough attention to where those defaults originate, how they evolve, and how much of the web’s “best practice” is really just the path of least resistance shipped at scale.
An SEO’s value should not be interpreted through the amount of hours they spend discussing canonical tags, meta robots, and rules of sitemap inclusion. This should be standard and default. If you want to have an out-sized impact on SEO, lobby an existing tool, create your own plugin, or drive interest to influence change in one.
We have some big news: HubSpot Media is acquiring Starter Story, one of the most trusted and beloved media brands in the entrepreneurship space.
If you’ve spent any time in the world of bootstrapped businesses, online startups, or the indie founder community, you already know what Starter Story is. But if this is your first introduction, buckle up, because this brand has a story worth telling.
Back in 2017, a software engineer named Pat Walls was burning the candle at both ends. His first startup had just failed to get into Y Combinator. He was spending his days at work and his nights trying to build something that would stick—a story most entrepreneurs know all too well.
Refusing to give up entrepreneurship, Pat started a side project — something low-cost, scrappy, and built from genuine curiosity. He wanted to know how real founders actually built their businesses from the ground up. So he started calling them up and asking.
He built the first version of Starter Story from a Starbucks, posting his early founder interviews to Reddit and Hacker News to see what would happen. People loved it. He kept going. By October 2017, Starter Story was live, and it grew from there in a way that would feel right at home on its own pages.
Today, Starter Story is a full-on multi-channel media brand reaching over 100 million people per year. The numbers are hard to argue with:
800,000+ combined YouTube subscribers
600,000+ combined social followers
300,000 newsletter subscribers
4,500+ founder case studies and interviews in its database
100M+ content views annually
But what makes Starter Story culturally significant isn‘t the scale — it’s the trust. For the bootstrapped founder community, getting featured on Starter Story has become something of a rite of passage. These aren‘t fluffy success stories. They’re honest, transparent breakdowns of how founders built their companies: what they charged, how they found their first customers, what nearly broke them, and what finally clicked. Revenue figures included.
That combination of radical honesty and practical insight is rare. It’s also precisely why Starter Story has built such a loyal, high-intent audience.
Why HubSpot Media Acquired It
Let’s zoom out for a second.
The media landscape is shifting in ways that marketers feel every day. Organic traffic is getting harder to earn. Paid acquisition costs keep climbing. Audience attention is scattered across more channels than ever. The playbooks that worked five years ago — keyword stuffing, algorithmic content at scale, banner ads — are increasingly hitting diminishing returns.
What’s working? Trusted, creator-led brands that audiences actively seek out. Brands that people subscribe to, share, and come back to — not because they were served a retargeted ad, but because the content is genuinely worth their time.
That‘s what HubSpot Media has been building toward. Rather than rent attention through paid channels, we’re investing in media properties that own it. The Hustle, Mindstream, and now Starter Story are all part of that same thesis: if you want to reach the people who matter most to your business, build (or acquire) the media they already love.
Starter Story fits this strategy exceptionally well because of who it reaches. The Starter Story audience is made up of early-stage founders — people at the exact moment they‘re deciding which tools to build their businesses on. Pre-seed through Series A, they’re evaluating options, moving fast, and forming opinions about which brands they trust. That‘s a core segment for HubSpot, and Starter Story reaches them in their element, when they’re actively learning and making decisions.
It‘s not a demographic fit. It’s a mindset fit. And that makes all the difference.
HubSpot Media: A Track Record Worth Talking About
We don’t make these kinds of moves lightly, and we have the results to back up why we keep making them.
HubSpot’s media network now drives over 50 million engagements and tens of thousands of leads each month — a number that reflects genuine audience behavior, not inflated impressions. On YouTube alone, HubSpot’s channels collectively pull in over 20 million views per month.
The Hustle, which HubSpot acquired in 2021, is a clear proof point. It‘s remained editorially independent, kept its voice and community, and continued to grow. The same goes for Mindstream. We’ve learned how to be good stewards of the media brands we invest in — adding resources without adding interference.
With Starter Story joining the network, our combined YouTube subscriber count rises to 2.9 million. That’s a real, engaged audience of people who want to build things.
A Note on Why This Matters
There‘s a version of this story you could tell about media strategy and acquisition multiples. We’re not going to say to that version.
The version we care about is this one: there are millions of people around the world who want to build something. Some are a few months into a side project. Some are staring at a blank Notion doc, trying to figure out what to make next. Some have launched and are grinding through the messy middle. And Starter Story has been one of the most honest, most generous resources available to all of them.
Getting to invest in that — and help it grow — is something we’re genuinely proud of.
If you’ve never read a Starter Story case study, go read one now. Then subscribe to the newsletter. Then watch a few videos. Trust us on this one.
And if you’re building something right now — welcome to the HubSpot Media family. We built these things for you.
It compared pre-update (Jan 25-31) and post-update (Feb 8-14) windows across the top 1,000 domains and top 1,000 articles in the US, California, and New York.
For transparency, NewzDash is a news SEO tracking platform that sells Discover monitoring tools.
What The Data Shows
Google said the update targeted more locally relevant content, less sensational and clickbait content, and more in-depth, timely content from sites with topic expertise. The NewzDash data has early readings on all three.
NewzDash compared Discover feeds in California, New York, and the US as a whole. The three feeds mostly overlapped, but each state got local stories the others didn’t. New York-local domains appeared roughly five times more often in the New York feed than in the California feed, and vice versa.
In California, local articles in the top 100 placements rose from 10 to 16 in the post-update window. The local layer included content from publishers like SFGate and LA Times that didn’t appear in the national top 100 during the same period.
Clickbait reduction was harder to confirm. NewzDash acknowledged that headline markers alone can’t prove clickbait decreased. It did find that what it called ‘templated curiosity-gap patterns’ appeared to lose visibility. Yahoo’s presence in the US top 1,000 dropped from 11 to 6 articles, with zero items in the top 100 post-update.
Unique content categories grew across all three geographic views, but unique publishers shrank in the US (172 to 158 domains) and California (187 to 177). That combination suggests Discover is covering more topics but sending that distribution to a narrower set of publishers.
X.com posts from institutional accounts climbed from 3 to 13 items in the US top 100 Discover placements and from 2 to 14 in New York’s top 100.
NewzDash noted it had tracked X.com’s Discover growth since November and said the update appeared to accelerate the trend. Most top-performing X items came from established media brands.
The analysis noted it couldn’t prove or disprove whether X posts are cannibalizing publisher traffic in Discover, calling the data a “directional sanity check.” The open question is whether routing through X adds friction that could reduce click-through to owned pages.
Why This Matters
As we continue to monitor the Discover core update, we now have early data on what it seems to favor. Regional publishers with locally relevant content showed up more often in NewzDash’s post-update top lists.
Discover covered more topics in the post-update window, but fewer sites were getting that traffic in the US and California. Publishers without a clear topic focus could be on the wrong side of that trend.
Looking Ahead
This analysis covers an early window while the rollout is still being completed. The post-update measurement period overlaps with the Super Bowl, Winter Olympics, and ICC Men’s T20 World Cup, any of which could independently inflate News and Sports category visibility.
Google said it plans to expand the Discover core update beyond English-language US users in the months ahead.
SerpApi Challenges Google’s Right To Sue Over SERP Scraping via @sejournal, @MattGSouthern
SerpApi filed a motion to dismiss Google’s federal lawsuit, two months after Google sued the company under the DMCA for allegedly bypassing its SearchGuard anti-scraping system.
The filing goes beyond disputing the technical allegations. SerpApi is challenging whether Google has the legal right to bring the case at all.
The Standing Question
SerpApi’s core argument is that the DMCA protects copyright owners, not companies that display others’ content.
Google’s complaint cited licensed images in Knowledge Panels, merchant-supplied photos in Shopping results, and third-party content in Maps as examples of copyrighted material SerpApi allegedly scraped.
SerpApi CEO Julien Khaleghy wrote that the content in Google’s search results belongs to publishers, authors, and creators, not to Google.
Khaleghy writes:
“Google is a website operator. It is not the copyright holder of the information it surfaces.”
Khaleghy argued that only a copyright holder can authorize access controls under the DMCA. Google, he wrote, is trying to assert those rights without the knowledge or consent of the creators whose work is at issue.
In the 31-page motion, SerpApi invokes the Supreme Court’s 2014 ruling in Lexmark International, Inc. v. Static Control Components, Inc., which established that a plaintiff must show injuries within the “zone of interests” the law was designed to protect. SerpApi argues Google’s alleged injuries, including infrastructure costs and lost ad revenue from automated queries, don’t fall within what the DMCA was built to address.
The Circumvention Question
SerpApi also disputes whether bypassing SearchGuard counts as circumvention under the DMCA.
Google alleged in December that SerpApi solved JavaScript challenges, used rotating IP addresses, and mimicked human browser behavior to get past SearchGuard.
Khaleghy wrote that the DMCA defines “to circumvent a technological measure,” in part, as “to descramble a scrambled work, to decrypt an encrypted work, or otherwise to avoid, bypass, remove, deactivate, or impair a technological measure,” and argued SerpApi does none of those things.
Khaleghy writes:
“We access publicly visible web pages, the same ones accessible to any browser. We do not break encryption. We do not disable authentication systems.”
The motion states Google “does not allege unscrambling or decryption of any work, or the impairment, deactivation, or removal of any access system.” SerpApi calls SearchGuard a bot-management tool, not a copyright access control.
Why This Matters
The outcome could reach beyond SerpApi. Google’s DMCA theory, if accepted, would let any platform displaying licensed third-party content use the statute to block automated access to publicly visible pages.
When we covered Google’s original filing in December, I noted the central question was whether SearchGuard qualifies as a DMCA-protected access control. SerpApi’s motion now adds a layer underneath that. Even if SearchGuard qualifies, SerpApi argues Google isn’t the right party to enforce it.
In a separate case decided on December 15, 2025, U.S. District Judge Sidney Stein dismissed Ziff Davis’s DMCA Section 1201(a) anti-circumvention claim tied to robots.txt against OpenAI, holding Ziff Davis failed to plausibly allege that robots.txt is a technological measure that effectively controls access, or that OpenAI circumvented it.
Google’s SearchGuard is more technically complex than a robots.txt directive, but both cases test whether the DMCA can be used to restrict automated access to publicly available content.
Looking Ahead
The hearing on SerpApi’s motion is scheduled for May 19, 2026. Google will file its opposition before then.
SerpApi also filed a motion to dismiss in a separate lawsuit brought by Reddit in October, which named SerpApi alongside Perplexity, Oxylabs, and AWMProxy. Both cases raise questions about using DMCA anti-circumvention claims to challenge bot evasion and automated access to pages that are viewable in a normal browser.
I spent two days gigging at RentAHuman and didn’t make a single cent
I called a car and started heading that way, only to get a text that the person was actually at a different location, about 10 minutes away from where I was headed. Alright, no big deal. So, I rerouted the ride and headed to this new spot to grab some mysterious V-Day posters to plaster around town. Then, the person messaged me that they didn’t actually have the posters available right now and that I’d have to come back later in the afternoon.
Whoops! This yanking around did, in fact, feel similar to past gig work I’ve done—and not in a good way.
I spoke with the person behind the agent who posted this Valentine’s Day flyer task, hoping for some answers about why they were using RentAHuman and what the response has been like so far. “The platform doesn’t seem quite there yet,” says Pat Santiago, a founder of Accelr8, which is basically a home for AI developers. “But it could be very cool.”
He compares RentAHuman to the apps criminals use to accept tasks in Westworld, the HBO show about humanoid robots. Santiago says the responses to his gig listing have been from scammers, people not based in San Francisco, and me, a reporter. He was hoping to use RentAHuman to help promote Accelr8’s romance-themed “alternative reality game” that’s powered by AI and is sending users around the city on a scavenger hunt. At the end of the week, explorers will be sent to a bar that the AI selects as a good match for them, alongside three human matches they can meet for blind dates.
So, this was yet another task on RentAHuman that falls into the AI marketing category. Big surprise.
I never ended up hanging any posters or making any cash on RentAHuman during my two days of fruitless attempts. In the past, I’ve done gig work that sucked, but at least I was hired by a human to do actual tasks. At its core, RentAHuman is an extension of the circular AI hype machine, an ouroboros of eternal self-promotion and sketchy motivations. For now, the bots don’t seem to have what it takes to be my boss, even when it comes to gig work, and I’m absolutely OK with that.






![Subscribe to Starter Story [Free Resources for Entrepreneurs]](https://rassegna.lbit-solution.it/wp-content/uploads/2026/02/what-were-building-with-starter-story.png)