AI SEO: Writing That’s Specific May Get Cited More via @sejournal, @martinibuster
Someone posted on social media about their experience writing deep and insightful articles last year and was pleasantly surprised to see that AI was leaning on their articles and even referencing them. Their secret was to choose highly specific topics, which is a good idea.
SEO And Natural Language AI
SEOs like to write articles based on keywords, and that’s actually how people did it in the relative caveman days of SEO, well over 25 years ago. Natural language processing has come a long way, and LLMs are now able to understand topics and questions in a conversational manner. So it’s truly outdated to proceed with SEO by focusing on keywords.
User behavior and what other sites and people are saying about a site or product are increasingly important. The best way to influence that is with content that’s insightful and gives users what they’re looking for and a lot of it, as often as possible.
It’s Not Just About Being Insightful
The person who started the discussion pointed out that they chose a “specific enough topic” and wrote something insightful about it. That’s a deceptively simple tip, but it is one of the key points about writing for an audience of humans and machines that interpret content as if they were humans.
Choosing a specific enough topic is about keeping the article focused on a topic and not allowing it to stray. One of the hallmarks of good writing is the willingness to remove the bits that tend to wander off topic. This is an American style of writing, although Europeans as far back as Charles Dickens knew the value of staying on topic so that the effect is a constant stream of interesting sentences that pull a reader all the way to the end of the page.
Writing is an art, like painting and composing music. But you don’t have to have a literature or journalism degree to engage users with text.
How Someone Got Lots Of Love From Claude AI
Bluesky user @danabra.mov posted about their experience writing an insightful article that subsequently began getting referred to by Claude AI.
“If you write an insightful blog post on a specific enough topic, and people link to it, you have a real chance at influencing everyone’s LLM output in a year or so. it’s a bit wild.
I wrote some articles last year that I thought nobody would read because they’re super long. And now I see Claude regurgitating what I wrote in those articles in a perfectly condensed way (and occasionally explicitly referring to the posts). they took away exactly what I wanted the reader to take!
For me it’s a relief because i was worried about falling interest to longform blogs and declining readership. but in a sense maybe it has significantly expanded! It’s just that my reader is now infinitely patient and really wants to hear the entire thing.”
Others Agree That Being Specific Is Key To Success With AI Citations
The response to Dan’s post was overwhelmingly positive, with one person commenting that it gave them hope.
One person named Tyler shared that they had a similar experience with content they published that was specific.
“I’ve seen a couple of mine, not even that insightful, just specific, get pulled into them and used within like 6 months. Wild.”
The person who started the discussion, Dan, agreed:
“I mean yeah but I think being specific by itself is enough…”
Why Is Being Specific Enough?
Based on my well over forty years of writing experience, including writing poems, short stories, one novel, blog posts, and articles for Search Engine Journal, my opinion on the matter is that focusing on being specific helps to keep a work focused in a way that matches the reader’s focus. The moment the article strays off topic is when the reader loses interest and jumps away.
Being insightful is not enough. Being witty or clever is nice in moderation, but in higher doses it becomes off topic and will, in my opinion, lose the reader. That’s why anyone who writes content must be willing to ruthlessly cut words out to keep it focused and specific (on topic).
What Google Said About The Topic
Google’s John Mueller reposted Dan’s post with the comment:
“Make more insightful & useful stuff.”
There was one skeptic in the crowd who argued that the economics remove the incentive to put in the work.
“Why on earth would anyone put in the effort required at this point only to have it immediately stolen, receive no compensation and no credit. It’s never been more hostile environment to be a creative. The economics DO NOT WORK.”
Yes, it’s true that today’s environment is hostile to creators because of AI. Yet there is always an opportunity for success by writing about the topics that interest you because they will be sure to be of interest to someone else.
Google Is Using Social Media Signals To Mask AI Search Click Loss via @sejournal, @TaylorDanRW
As you may already know, Google recently updated Search Console to let brands track how their social media and video posts perform in search results.
Most marketers view this update as a helpful gift. They believe Google wants to reward brands that build strong footprints across TikTok, YouTube, and X. And not wanting to be glass-half-full, I think this is the positive optics Google was hoping for.
If you look past the official announcements, a different picture comes into focus; this update is a clever trap. It serves as a shield to hide the traffic loss caused by artificial intelligence while positioning creators into further training Google’s AI models.
Redefining Success In The Era Of Click Loss
To understand this strategy, you must look at the crisis Google faces with web publishers.
Organic traffic to a company website was the main measure of marketing success, and a narrative we as an industry pinned to the mast for years as to whether or not we were justifying our budgets.
By tracking social media views inside Search Console, Google is trying to change the definition of success. If your website traffic drops by a third, Google can point to your social media data. They can show you that your TikTok videos received thousands of impressions on the search page; they want you to believe you are still winning, even if you do not get actual clicks.
It forces marketers to view Google as the central control room for all visibility, even when Google stops sending visitors to their websites, as they’re still providing visibility.
Outsourcing The Search Graph To Creators
The update also serves as a tool to train Google’s artificial intelligence and to power generative search, Google needs to understand the real world.
The engine maps relationships between people, brands, and topics. This process is called entity resolution.
Google needs to know who is an expert, what they write about, and whether they are a real person or just an automated spam site.
By encouraging you to verify your social accounts inside Search Console, Google makes you do their work. You hand over the exact connections they need, tell them that your website, your X profile, and your TikTok account are all the same entity.
Instead of Google guessing which profile belongs to which author, publishers hand-deliver verified identity maps. Google can then use this clean data to train its language models on who the true authorities are.
Having verified data is essential in the age of generative text.
Anyone can build a website, buy a drop domain, and programmatically generate thousands of articles with AI, and inflate third-party authority metrics.
Social profiles with real human engagement are the best proof of life. Real companies and real brands operate across the multiple channels and have a form of pulse and presence outside their single web domain.
Google uses these connections as a trust filter to separate real brands from synthetic spam. You are giving Google the exact blueprints it needs to verify content ownership. This helps Google decide which sources are reliable and which sources are junk.
Looking at this cynically, the ability to verify social profiles in Google Search Console is an optics masterclass in platform survival.
It somewhat pacifies publishers by giving them new vanity metrics to track, and at the same time, it creates a new network for those same publishers to map the entity relationships that Google needs to build its AI future.
How Google Get Social Content
Google pulls social media posts into search engine results pages through a combination of live data firehoses, standard web crawling, and dynamic JavaScript rendering. The process differs based on the specific platform and user privacy settings.
Some of these data pipelines have been around for almost a decade, with the X (then Twitter) firehose deal coming into play in 2015.
This doesn’t mean that fresh posts are the only ones considered. In my own Search Console profile, I’m seeing X posts receiving clicks on Google that I posted in October 2024.
LLMs behave in a similar manner, and because of this we need to look at a post deprecation strategy.
Reviewing pricing prompts for one of our clients, I found that a couple of LLMs were returning pricing information from an X post advertising a student only offer from July 2022. This isn’t only misinformation, but can lead to a negative brand experience when a user clicks through expecting to receive one price, but find one substantially different.
Your Audience, Google’s Platform
The brands that win in this new landscape will not focus on these new Google metrics, but understand these are now another piece of the puzzle.
We need to stop treating Google as a neutral partner, as Google needs Search to bring people to the platform for Ads.
We should use our social channels to build a direct connection with your audience. Gather your community on platforms you control, rather than a search engine that wants to keep your visitors for itself.
How Do I Split Pages Between Brand Building & Converting? – Ask An SEO via @sejournal, @rollerblader
I was asked a great question, and it’s something I talk to clients about on a very regular basis:
“Should every page do all things? I’m struggling to work out which pages should be optimized for CRO and which should be to build the brand.”
Blog posts and informative pages (brand-building pages) are likely meant to inform, not be conversion tools. They bring in traffic to build an audience that subscribes, and you can remarket to via Meta and Google, etc. Product pages for converting sales aren’t always meant to rank in search engines unless you are the manufacturer and there is no better option with a category page.
There are always exceptions to the rules, like a comparison blog post that helps with the lead funnel, or a “how to” guide that shares an accessory or missing part to complete a solution, and a product page where the query is for a specific product like a [size 11 (insert brand) running shoe]. But those are exceptions, not a general strategy.
A way to apply what should get traffic, what should convert, and pages for both is to split the purpose of the pages into a document and try not to cross the boundaries by making a conversion page rank. Focus your time converting pages that are meant for conversions, and providing the best information experience for the ones meant for branding. This will make your life easier and give your website a better opportunity to grow in both traffic and revenue. It also allows the CRO team to do their job while you do yours. The goal is to learn how to work with CRO and other teams.
For this post, I’m combining brand building with traffic-generating (i.e., SEO) pages to make it simple. The concepts apply to both.
CRO And SEO Need To Work Together
The goal of conversion rate optimization (CRO) is to help the person take a specific action, which could be adding a product to a cart, joining a newsletter or SMS list, subscribing to a service or publication, taking a specific action like adding an upsell to a shopping cart, increasing pageviews, etc. While SEO and CRO can work together, they’re normally siloed, and a CRO specialist is not an SEO or required to know SEO, just like an SEO is not required to know CRO.
CRO strategies can include:
Deleting blocks of copy.
Weighing the page down with video and moving specific SEO elements that are needed.
Reinforcing the brand in the headers vs. the topics of the section of the page.
Pushing videos down on a page so images, reviews, testimonials, etc., can be present even though this stops the video SEO performance.
Setting up split tests on live pages without checking canonical tags, meta robots, etc.
These are all things a CRO can and will do to help convert more traffic on the page, even though they can stop pages from doing well in both SEO and AIO/GEO. This is why educating and working with a CRO team to ensure they do not touch the content that matters, such as schema, internal links, site structure, positioning of specific elements, is important. It’s the way you approach the situation and how you can be proactive vs. reactive.
Pro tip: One thing that helps me when we get into a debate is reminding the CRO that without traffic from SEO, there are no users to convert and we’re both out a job.
How To Stop CRO And Branding From Damaging SEO
The first thing we do with clients that we do not do CRO for, and that are heavily focused on “brand” vs. marketing, is to create a help guide that includes:
SEO and AIO/GEO best practices for page types like product, blog post, how-to guide or comparison, listicle, homepage, and category pages.
A map of the pages or folders that are 100% off limits for CRO.
An easy-to-reference tech SEO guide to common CRO tasks, like split-testing designs that won’t impact SEO so they can run their tests and we can continue to thrive.
The goal, especially at an enterprise level, is to have something quick and easy for other teams to understand and reference. If it gets too long or too complicated, it will get ignored, and your job becomes more difficult.
Page Type Guides
While we all want our wish lists to be present for pages that are being modified for conversions, not everything matters. Include the high-level items that are a must-have for the pages. If it is a how-to guide, your SEO must-haves could include:
Specific keywords in section headers like “tools you’ll need” in a bullet list and “the steps to do XYZ” in a numbered list.
No sales pitches in the opening or paragraphs about the company, as the goal is to provide a solution, then we can share we offer an alternative or a product and service.
Category pages on an ecommerce site could require copy, breadcrumbs, and possibly FAQs if relevant. And a blog could have restrictions on being self-serving, like a company picnic or short-term promotion vs. something evergreen that is a solution consumers ask about regularly.
Pro tip: When you say the blog cannot have X type of content, make sure to provide an alternative as a way to prevent pushback. Being proactive with solutions makes it easier to prevent self-serving content from impacting informative content that needs to rank.
Off-Limit Folders And Pages
One of the most important things we do with CRO and branding teams is create a site structure where we have our “SEO” or traffic content. There could be two or three blogs on the website, with one being for SEO, one for company updates and product releases, and another for support and help. The two that are not for generating traffic can be fair game, and you have IT either block them in robots.txt or use a meta robots noindex, follow on them.
Landing pages designed for partnerships that have statistics and information you use for backlink acquisition, or pages that are old but authoritative, can all be listed as off limits. Create a document or sheet with these pages and add a quick blurb with why they cannot be modified without SEO approval. A short bullet list of the negatives (in plain English) that are likely to happen if modified can help let the decision maker know the risks. This way everyone is aware of potential losses.
Be cautious with how restrictive you are. Not every page needs to rank. Product pages on an ecommerce site, for example, are rarely important for ranking as they compete with other products and category or collection pages. If the collection pages rank, you have more stability, as products can go out of stock more quickly, and if that product is never coming back, you lose the revenue if you don’t focus on collections instead. Let the team mess with the product pages and keep the categories safe if traffic is your goal. Then have requirements that must be kept intact for the product pages, like internal links and schema.
Tech SEO Guides
The last thing we do to balance pages for conversions and pages for building authority (SEO) is to have simple tech SEO guides available in case the teams are making decisions while you’re offline or on vacation. Have a header for each page type and a list of general guidance.
The list of general guidance could be a bulleted list with explanations.
Any split-tested pages should have a canonical link back to the main and guaranteed-to-exist page.
URL: yourdomain.com/product/XYZ is the main URL.
yourdomain.com/product/XYZ1 and yourdomain.com/product/XYZ2 are the split test URLs.
Both split test URLs should have a canonical link back to yourdomain.com/product/XYZ
H1 tags on category pages must have the main product category mentioned. Branding statements can go in regular paragraph format and use font size for formatting.
Landing pages that are temporary and not for SEO should be placed in the test folder yourdomain.com/test/, which is blocked by robots.txt, so search engines do not crawl it.
Long-term landing pages that are optimized and do not compete with brand-building (SEO) pages go into the proper site structure. If they are competing topics to a main page, place meta robots noindex, follow on it, or use a canonical link to the main page.
Any tool that needs to be installed in the head of the page, specifically JavaScript, should be tested in Search Console to make sure it does not block page rendering (Google’s ability to see the page).
Place the script on the page.
Copy the URL and paste it into Search Console (insert screenshot of the place).
Click View Test and then look at the screenshot.
If the page displays correctly, we’re likely safe to run the tool.
If the page does not display correctly, this could impact SEO, and we should place the script elsewhere or use a different tool.
Brand building pages to bring in SEO traffic and conversion optimization can both happen in unison. It’s a matter of working with the teams and making sure they have the tools needed so they can do their jobs without causing damage to your channels. These are three of the things we do regularly with our clients, especially enterprise-level or small teams where people are in a hurry and don’t have time to research.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
Google Brings Calendar To Personal Intelligence In AI Mode via @sejournal, @MattGSouthern
Robby Stein, VP of Product, Google Search, says Personal Intelligence in AI Mode now connects to Google Calendar. He announced the update in a post on X, writing that Personal Intelligence in Search “now connects to Google Calendar.”
With this update, AI Mode can “add invites or other meetings to your Calendar directly,” and responses become more tailored because they consider what’s on your schedule.
Unlike Gmail and Photos, which only give AI Mode information to reference, Calendar is the first announced Personal Intelligence connection that can also create an entry directly.
Stein confirmed the connection is available now in the U.S., with more countries to come.
Every connected app is another variable that can make the same query produce a different answer for different people. That’s already measurable: iPullRank’s May report found that connecting Gmail to Personal Intelligence changed which brands showed up in AI Mode responses, using identical prompts across test accounts.
Calendar adds a different kind of variable tied to timing rather than interests. Ask AI Mode for dinner spots and, with Calendar connected, the answer can account for whether tonight is already booked. Multiply that by however many apps Google eventually connects, and the old idea of a single results page for a given query gets harder to hold onto.
Two people typing the same words could reasonably land on two different answers, based on nothing more than what’s already sitting in their calendars.
Looking Ahead
Google hasn’t announced when the Calendar connection will expand beyond the U.S. The bigger question is how tracking will evolve as personalization grows: if AI Mode answers rely more on connected apps, there’s no single result to verify, only a range of answers influenced by the searcher’s connected apps.
ChatGPT Calls Turn Into Leads More Often: Invoca Report via @sejournal, @MattGSouthern
According to a benchmark report published by Invoca on July 13, calls referred by ChatGPT are more likely to qualify as sales leads than calls from any other channel. However, once answered, these calls convert at approximately the average rate.
The report states that the lead rate for ChatGPT-referred calls is 49%, which is approximately 10 percentage points higher than the average of the seven channels tracked by Invoca and 6 points above Google Business Profiles at 43%. The conversion rate from these leads is 40%, compared to an all-channel average of 42%. Invoca considers this to be about average.
All figures represent averages from Invoca’s customer base, based on over 70 million calls and 600 million minutes of conversations across 10 industries. Invoca sells the call tracking and conversation analytics that generate this data.
Invoca says this is the first year it had enough data to measure calls driven by generative AI search at all.
What The Data Shows
Across all industries, approximately 56% of calls to businesses are answered by a person. If a call lasts more than 15 seconds, the answer rate increases to about 65%, and for calls over 30 seconds, it rises to around 71%. Out of the answered calls, roughly 38% qualify as leads, and about 42% of those leads convert during the call.
ChatGPT sits above that baseline on the first number and below it on the second.
Paid search continues to generate the most calls, leads, and conversions among paid channels in the dataset. For multi-location businesses, Google Business Profiles are the top organic source. Invoca emphasizes that channel efficiency and scale are different factors, and percentages alone don’t reveal which channel brings in the most business.
What The Report Doesn’t Say
Invoca does not publish how many ChatGPT-referred calls the 49% is calculated from, only noting thatInvoca does not publish how many ChatGPT-referred calls the 49% is calculated from, only noting that the overall volume attributable to generative AI remains very low. When a rate is derived from a small base, it tends to be less reliable compared to the same rate calculated from the significantly larger paid search volume.
The report doesn’t specify a measurement window. The methodology explains that the figures are based on calls tracked and analyzed on the Invoca platform across 10 industries and seven marketing channels, but it doesn’t mention a specific start or end date. Gemini, Claude, and Perplexity aren’t included in the channel breakdown. Invoca notes that this is a measurement limit rather than a comment on those assistants, mentioning that ChatGPT is the only large language model generating measurable call volume in their dataset.
How Invoca Attributes The Calls
Invoca labels calls as ChatGPT-referred, but the report lacks details on how this attribution works, such as whether callers clicked from ChatGPT, used tracked numbers, or contacted the business through other means. It only accounts for calls directly attributable to ChatGPT and not those from users who researched a business in an assistant and later called via untracked methods.
I covered a version of that boundary in June, when Similarweb data linked ChatGPT brand recommendations to a 2.5x higher chance of a site visit within seven days. Most of the associated traffic appeared as branded search rather than as a direct referral, limiting what standard referral reporting could show. Calls add another attribution problem because the report doesn’t explain what digital trail Invoca used to connect them to ChatGPT.
Why This Matters
Calls attributed to ChatGPT qualify as leads more often than calls from the other channels Invoca tracks, by about 10 points. Once someone picks up, they convert at about the rate businesses manage with everyone else. That complicates the read that’s been forming around AI referrals over the past year.
I wrote in May about Adobe’s finding that the conversion sign flipped on AI-referred traffic to U.S. retailers. In twelve months, it went from the worst-performing channel to converting 42% better than the others. The explanation on offer was that the research had already happened inside the assistant. Invoca’s data fits the first half of that. Someone who compares options with an assistant and then calls may be further along in the buying decision, which is how Invoca reads it, too.
The second half of the data doesn’t quite match up. While a higher lead rate is observed, it doesn’t translate into a higher on-call conversion rate when looking at Invoca’s averages. In this dataset, the difference appears at the qualifying stage but then vanishes afterward.
Looking Ahead
Invoca believes this is more of a signal to monitor rather than a channel to invest in, supported by the volume caveat. The key metric influencing this view is call count, which the report doesn’t specify. Another question is whether the 40% moves. If AI-referred callers continue to qualify at the top of the list while converting in the middle, the focus shifts from increasing call volume to understanding what happens during those calls.
The report also notes that 64% of businesses don’t ask callers to make a purchase or schedule an appointment, which is an issue on the business side.
That still means Google processes 2.92 billion clicks to the open web every day. It’s still a figure worth fighting for – particularly for publishers whose business models heavily rely on a click.
So let’s not totally lose sight of what matters in the here and now. And unique content certainly fits that mould.
I have reviewed a few previous patents (Google’s in-depth article patent explained and how Google ranks news sites), and it is not a thoroughly enjoyable experience. A granted patent protects an idea; it doesn’t prove deployment or real-world use cases – and it’s certainly not unlike big tech to claim ownership of something just so it can’t be used elsewhere.
Whether it has international filings? Yes, but with some caveats. US, China, ceased in Europe and worldwide, but extended in the US to 2039 very recently.
Whether Google has protected the ranking technology around the world? Yes, again with some caveats.
Does it broadly align with your understanding of the concept (in this case non-commodity content)? Very much so. As the rasping breaths of SEO-first, commodity content make even iron lungs work hard, it would be inconceivable for Google to not measure or evaluate uniqueness in some manner.
It is more likely to be used in some capacity.
TL;DR
Google has multiple public and leaked systems that appear to evaluate originality, effort, and unique contribution – see OriginalContentScore and ContentEffort.
The patent describes an information gain score (potentially in a 0 – 1 framing) that is assigned to a document based on how much new information it adds beyond documents a user has already seen on the same topic.
In my – and many others’ – opinion, Google’s systems reward originality in some way. Whether that’s directly through an information gain score and re-ranking system, a Bayesian predictive score, or indirectly through positive engagement signals, I couldn’t tell you.
Originality doesn’t mean an entirely different document. As little as a 10% difference could be the delineator between marketing success or failure.
How Does It Work In Practice?
This patent is not about the information gain applied to the current set of search results. It’s about the subsequent set of results – ranking the next set of search results based on wider user search behavior, personalization, and added document value.
It highlights that documents:
May be reranked.
May be excluded.
May be significantly demoted.
May no longer appear in results.
Based on the amount of novel, relevant information provided when compared to other similar documents.
For any tech SEO geeks out there, you’ll be well aware of the concept of preloading. In nerd circles, preloading tells browsers which resources should be prioritized to improve the page load speed and above-the-fold rendering.
I think this patent works in a similar manner, but with bloody unreliable people instead of machines. Maybe bfcache is a more apt comparison, but I haven’t really got stuck into technical SEO for a while, so forgive me for my appalling analogies.
Step-By-Step
A user reads a document about a certain topic, let’s say, growing an apple tree.
Google understands that the majority of users don’t stop at one page here. It’s a rich topic. When should I plant one? Where? What do I feed it?
With 13 months of click and engagement data to hand, Google knows – with, I imagine, an unerring level of accuracy – what piece of content each user should be shown and when based on goal fulfillment.
But new content is written every day. Pages are updated. So this isn’t a static corpus to work with. And maybe someone has a novel way of growing apple trees?
So pages are compared. A user reads a document (d1). Google then compares a new or updated article (d2) to the original.
If d2 generates a favorable information gain score, it will likely be shown to the user as part of their journey. If it doesn’t, it’s doomed.
“An information gain score for a given document is indicative of additional information that is included in the given document beyond information contained in other documents that were already presented to the user.”
Let’s say two documents are chosen based on a user’s search and search history. They’re represented as d1 or d2. D1 is an already-consumed document, and d2 is brand spanking new. Well, to the user at least. These documents can be represented as a vector (or some other semantic representation) to help the model fake understanding of the document and its position against similar documents.
Vector mapping is all about angles and positioning on a graph to quantify a scoring or positioning system (Image Credit: Harry Clarkson-Bennett)
The system provides a quantitative score to assess whether the user should also view d2 after having viewed d1. If the machine learning model generates an information gain score of document d2 over document d1, then d2 is likely to be shown – for future use cases, possibly at the expense of d1.
There are some incredibly practical implications here.
If a topic has been done to death, you have a more limited chance to rank and generate value without providing something extra. In a scenario where your article scores 0, the system has assessed it provides nothing extra, and a user who has seen d1 is less likely to see d2 – your article.
If nothing else, make sure you stand out above your closest competitors in some manner.
As with so many of these Google-led ideas or initiatives there are flaws. You don’t have to follow it to the letter. But E-E-A-T and “information gain” are sound principles. You have to be memorable. There is no alternative.
How Important Is It?
I think uniqueness and standing out are more important than ever. Strip the patent out of the conversation. People or brands who publish content won’t survive if they aren’t memorable to people and – by proxy – search engines.
So you’ve got to do something differently.
In Google’s case, I think it’s more about efficiency than anything else. If they know the information gain scores of two documents are virtually identical, then a user isn’t going to be shown both versions of the document. The second document will be deprioritized in favor of richer, more unique content.
Google has enough engagement data to go along with these proxy scores to understand what document should be shown and when. They can get a user closer to their goal by removing overly similar pages from a user’s SERP or AI response.
Which may be exactly why they’re thinning their index – the removal of non-value-add content. Well, that and all the AI slop you’re creating.
It is quite literally down to a) computational resources (money) and b) getting the user to the point of completion quicker. In the DOJ Antitrust trial, Pandu Nayak’s sworn testimony called Navboost “one of the important signals that we have.”
“…a shorter query session or fewer dialogue turns can provide a corresponding reduction in the resource demands of the system e.g. with respect to memory and/or power usage of the system.”
And the Quality Rater Guidelines make numerous references to effort, originality and talent. Frameworks like E-E-A-T and the product reviews update really highlight the importance of actually using products and showcasing the effort you have gone to. The amount of “effort” you put in is quite literally quantified (highly recommend Sean’s breakdown here). It is part of the Helpful Content update (booooooo) and the more difficult your page is to replicate, the better chance it has of success, all things being equal.
These are not stupid principles. They’re very good ones. The problem is, effort is expensive. The fewer clicks content produces, the less each article will generate.
In an attributable manner at least.
Google Is Building An Audience Loyalty Ecosystem
Don’t take my word for it, take Barry’s. Google has wanted to get rid of click-chasing churnalism for years. Now it can. And it is – in most cases, I think, a positive.
Publishers that can demonstrate they have an audience outside of SEO are being “rewarded.” Although I suspect you could replace rewarded with crushed a little more slowly.
You can follow your favorite publisher via Preferred Sources and as a Search Profile via the Discover feed (U.S.-only at the time of writing this), and badges like “highly cited” have been in play for some time. It doesn’t work very well, but they are trying to promote unique reporting.
You can now see how content from social and video platforms performs on Google Search if you meet the requirements. Your digital footprint and impact within the industry you’re in really matters. Particularly when you consider how prevalent social and creator accounts are in Discover.
I worry that this is completely impossible to explain what is happening to users. What is Preferred Sources vs. a Search Profile?
It’s tough to force people to follow you on platforms – maybe that’s the point. Which I kind of understand – but I think one of these would’ve sufficed.
If you want to know a little more about where Discover is heading, I made a short video about it:
[embedded content]
Does Information Density Matter?
Yes and no. Long articles are not necessarily more effective at satisfying the user.
Google has methods to normalize the length of an article to prevent additional keywords and semantically relevant phrases from ranking the document too highly. Factors like TF-IDF normalization prevent long documents with high word counts from artificially inflating their relevance scores just because they’re quote-unquote richer.
More detail may be the wrong phrasing here. Detail and rigor are typically positives. But it’s less important than answering the question and getting the user closer to their end goal.
User satisfaction is quantified through goal completions and Navboost data – it trumps everything else.
How Does It Affect AI Systems?
Well, traditional search ranking is still crucial in AI systems – whether that’s how effectively you rank for the primary search, your inclusion in the training data, RAG, or suite of fan-out searches run concurrently. And AI searches are extremely personalized – something that’s likely to only increase over time.
When Claude starts knowing what toilet paper I buy or selects a poorly chosen “Happy Mother’s Day” card for my mum’s birthday that showcases my lack of effort and empathy, it’s time to call it a day.
The ideas described in this patent map almost too neatly onto how modern AI search systems retrieve relevant information. Of the SGE. It helps anticipate the user’s next interest in an assistant-like context. Personalized, “helpful” and with extreme memory.
As Roger Montti pointed out, this may give a clearer indication of how AIOs use pages that the user in question may be interested in. Their entire job is to synthesize answers from multiple sources and searches to provide the perfect jumping-off point. I suspect this scoring system is an excellent way to avoid computationally expensive, unnecessary utilization of documents.
contentEffort – described as a ‘Large Language Model (LLM)-based effort estimation for article pages’ – estimates the amount of effort invested in creating an article. As slop makes up more than 50% of the internet, this is seemingly one of Google’s way of dealing with it.
How Can I Use This Effectively?
Make differentiated, non-commodity content. It’s really simple. Apply what we call information gain in this context to your own content – if you cannot add anything of value to the existing index, then don’t bother.
You can use this with:
Original data.
First-hand experience.
Interviews.
Real reporting.
Being first on the scene and developing the story as it happens.
Proprietary analysis.
You don’t need a big budget. You can do amazing things with a few free data sources, some creativity, and a bit of rope. Just make sure the article has an element of uniqueness.
I think this really helps frame whether content is still worth creating. If you’re doing something just for SEO reasons and you can’t add anything extra to the existing suite of information, kill it. If a document contributes very little new information, the patent suggests it’s a strong candidate to be deprioritized when selecting subsequent documents.
Still costs time and money to make, but is less and less likely to drive any real value. Stay in your lane, but drive a nicer car.
I have a feeling your indexation report in GSC is invaluable here. Beige content has a shelf life so low it’s in the running for the new UK Prime Minister. So check for any pages dropping out of the index at scale for more serious issues.
Google Says No SEO Penalty For Year-Long A/B Tests? via @sejournal, @martinibuster
Google’s John Mueller recently answered a question about A/B testing web pages for long durations, warning that an unintended consequence is that enabling variations to be indexed can result in uncertainty as to which will be visible in the search results.
A/B Testing Traffic From Live Search Results
A/B testing is when one or more versions of a web page is shown to users. The reason for doing this is generally for testing conversion rates and user responses.
The important takeaway from the guidelines is that A/B testing live web pages is the guidelines were created to minimize impact on search performance.
The guideline begins:
“This page covers how to ensure that testing variations in page content or page URLs has minimal impact on your Google Search performance.”
While Google does not explicitly forbid using A/B testing to test which page ranks better, the context of the guidelines itself is defined as protecting search performance; measuring search performance is not in the guidelines.
What Google’s document describes getting measured is consistently user behavior, not rankings.
On a side note, something that’s not in the guidelines is that there is no “right” button color and size for improving clicks on a call to action button. Longstanding SEO knowledge and experience about this is that large buttons and/or colors that contrast strongly against the web page backgrounds tend to get more clicks. This likely explains why Amazon’s Add To Cart button is a bright mustard color and Walmart’s version is bright blue contrasted against a solid white background.
Google’s Guidelines On A/B Testing
Google’s guidelines on A/B testing describe it as showing different versions of a website and collecting data on how users react to them. In terms of SEO performance it says not to expect any disruption but by allowing Google to index the slightly different pages once the testing is over the winning combination will be indexed much sooner.
There are two kinds of A/B testing:
A/B Testing Testing two or more changes to a web page. Google uses the example of testing different fonts on buttons.
Multivariate Testing This is a test of multiple changes all at once in order to identify which combination of factors work best together. Google uses the example of testing different combinations of different fonts on buttons and on the web page itself.
Four Considerations For A/B Testing
Google also recommends four best practices:
1. Use The rel=”canonical” Link Attribute This is probably the most important factor to consider. Using the rel=canonical link attribute enables site owners to put all kinds of variations of a web page online and still include a strong hint about which version of a web page is best.
2. Use 302 redirects If you’re randomly redirecting users to different versions of a web page you should be using a 302 redirect, not 301 redirects. 302 means that a resource (like a web page) has been temporarily moved. That’s different from a 301 redirect which means that a move or change in URL is permanent.
3. Don’t Cloak Cloaking is the practice of showing one thing to Google and something else to users. If you’re testing different web pages to see how users react when they click through from search then Google insists that site owners show the same thing to Google, even if the page elements are constantly changing.
4. Don’t A/B Test For A Long Time
Google warns site owners to limit how long A/B testing goes on. They warn that excessive testing could get a site in trouble:
“If we discover a site running an experiment for an unnecessarily long time, we may interpret this as an attempt to deceive search engines and take action accordingly. This is especially true if you’re serving one content variant to a large percentage of your users.”
That last warning relates directly to the question asked on the Bluesky social network.
Google Answers Question About Long-term A/B Testing
The person asking the question specifically wanted to know about how Google handles A/B testing that lasts for as long as a year.
“Hey @johnmu.com, As Google’s A/B testing guide suggests to avoid running same A/B test for long durations, I was wondering how does Google handle long term holdouts (eg. 10% for 6-12 months), especially for a large scale marketplace with 10s of millions of crawls to similar amount of pages.”
Google’s John Mueller answered:
“Depending on your setup, what might happen is that one or the other version is used for indexing. If they’re close enough, probably that doesn’t matter. If they’re significantly different, that could be visible in search results too.”
The person who asked the original question then followed up with an additional question that revealed more about how much the web pages are changing.
They asked:
“…what if it’s fully different like a redesigned page, and since Googlebot is getting alternative versions with each crawl (sometimes in a day). Can that rapid change in core HTML structure cause issues with indexing and lead to Google potentially dropping the pages from index?”
Mueller responded:
“We’d take the content into account the way that we crawl it for indexing. There’s no (as far as I know) “penalty” or “demotion” for having varying content (lots of sites have that), but it can make it harder for you to debug & monitor if the content constantly changes.”
The person asking the question wanted to know how Google handled long-term A/B testing. They did not ask how Google handles indexing, but that’s the question Mueller answered. That may explain why the person followed up with a second question that was more precise about the extent of their A/B testing and Mueller again focused on indexing.
No Penalty For Having Varying Content?
Mueller’s statement seems to contradict Google’s own guidance about long-term A/B experiments.
The relevant context of Google’s guidelines is:
It confirms that A/B testing is legitimate.
Normal experiments are reasonably assumed to be temporary.
Once enough data is collected to reach conclusions the A/B test it’s normal that it ends.
That’s where we get to the warning part of the guidance:
“If we discover a site running an experiment for an unnecessarily long time, we may interpret this as an attempt to deceive search engines and take action accordingly. This is especially true if you’re serving one content variant to a large percentage of your users.”
So the point of where things get fishy is when the experiment goes on longer than what seems reasonable and where one variation of the content becomes the prime version for most users as part of an attempt to “deceive search engines.”
GA4’s AI Assistant Channel Undercounts Your AI Traffic: How To Build One That Doesn’t
I was digging through a Google Analytics 4 account recently, broke the traffic down by source and medium, and saw something that made me stop scrolling. The same source, chatgpt.com, was sitting in three different channels at once. Not three different sources. One source, scattered across three channels, in the same report. If you’ve got GA4’s new AI Assistant channel, there’s a good chance the exact same thing is happening in your data right now. And it means the AI traffic number you’re reporting is almost certainly wrong.
AI traffic is still a small slice for most sites, but it converts well above its weight: Similarweb’s clickstream data has ChatGPT referrals converting at around 7%, ahead of organic search and not far behind paid. A high-intent channel that small is worth measuring properly rather than eyeballing it. Let me show you why it fragments, and how to fix it.
So What Did Google Actually Change?
On May 13, 2026, Google added a native AI Assistant channel to GA4’s Default Channel Group. The idea is simple. When GA4 spots a referrer it recognizes as an AI assistant, it tags the session with the medium ai-assistant, drops it into the AI Assistant channel, and stamps the campaign as (ai-assistant). No setup, no regex, nothing for you to build. It rolled out gradually and reached most properties by early June 2026.
If you spent the last year stitching together custom regex just to see your AI traffic, that’s a genuine win. Before this, those visits sat in Referral, or in Direct when the referrer was missing.
But here’s the catch, and it’s hiding in the word “recognizes.” The list of platforms Google recognizes keeps moving. At launch, it named ChatGPT, Gemini, and Claude. By June, the live documentation listed a different set (ChatGPT, Gemini, DeepSeek, Copilot, and Grok), with Claude quietly dropped. Perplexity, one of the highest-intent AI sources going, still isn’t on the list and keeps landing in Referral. So don’t hard-code a platform list into a client report. Check Google’s channel definitions on the day you publish, because they change.
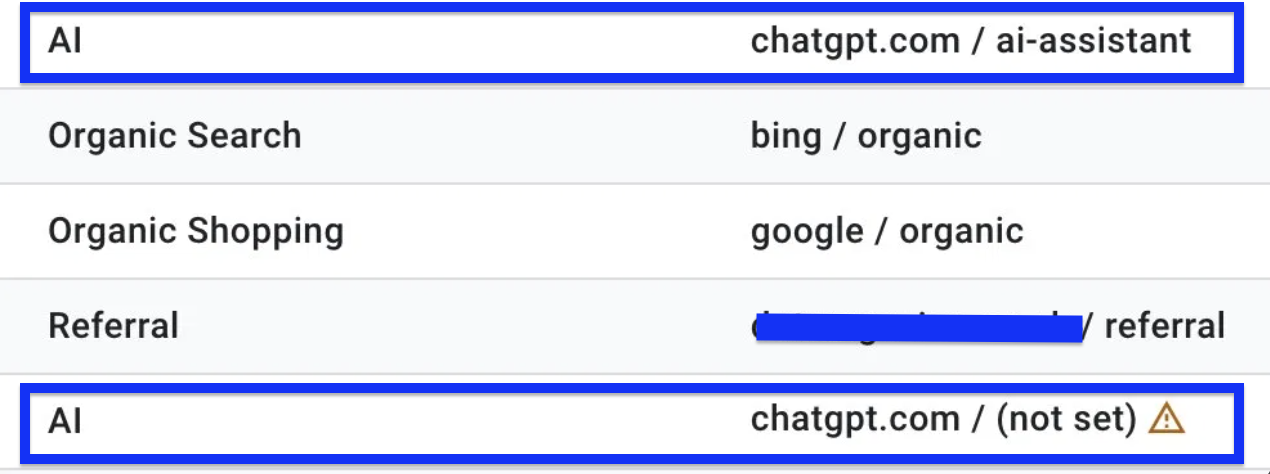
1 Source, 3 Channels: The Problem Hiding In Your Reports
Back to that screenshot. The reason a single source splits across three channels is that GA4 decides the channel using source and medium together, not source on its own. Add Session source/medium as a dimension, and you can watch chatgpt.com break into three:
chatgpt.com / ai-assistant lands in AI Assistant. This is the slice GA4 recognized and tagged.
chatgpt.com / referral lands in Referral. These are the sessions GA4 didn’t tag, plus anything that arrived before the channel switched on for your property (remember, the rollout dragged into June).
chatgpt.com / (not set) lands in Unassigned, the channel almost nobody ever opens. Google’s own rule is blunt here: when source/medium comes through as (not set), there’s no channel rule to catch it, so it falls into Unassigned.
Image from author, June 2026
Why would a source you clearly recognize turn up with no medium? In my experience it’s usually the ChatGPT app and its in-app browser. As MarTech has documented, links opened inside those embedded browsers tend to strip the referrer, so GA4 hangs on to the source but loses the medium.
So your real ChatGPT number isn’t in one place. It’s smeared across three channels, and one of them is a bucket you probably never check. Read the AI Assistant channel on its own, and you’ll undercount every single time.
Why The Obvious Fixes Don’t Work
There are three instinctive fixes here, and I wouldn’t lean on any of them:
Just read the AI Assistant channel. It misses the Referral and Unassigned slices of the very same traffic, and it ignores Perplexity completely.
Compare this month to last. The native channel only counts forward from the rollout date, and it switched on at different times for different properties. So any range reaching back into spring 2026 is comparing tagged traffic against untagged traffic. That’s not a trend; it’s an artifact.
Check your rank tracking. Different question entirely. Rankings tell you about position, not whether an assistant actually sent someone to your site.
The Fix: 1 Custom Channel That Matches On Source
Here’s the move that actually solves it. Build a custom channel group and match for source while ignoring medium completely. The second you do that, the ai-assistant, referral and (not set) versions of chatgpt.com collapse into a single line.
You get two bonuses on top. A custom channel group applies its rules retroactively across your whole date range, so it rescues all those old ChatGPT sessions stuck in Referral. And because you’re writing the rule, you can include the platforms Google leaves out, Perplexity included.
Here’s how I set it up:
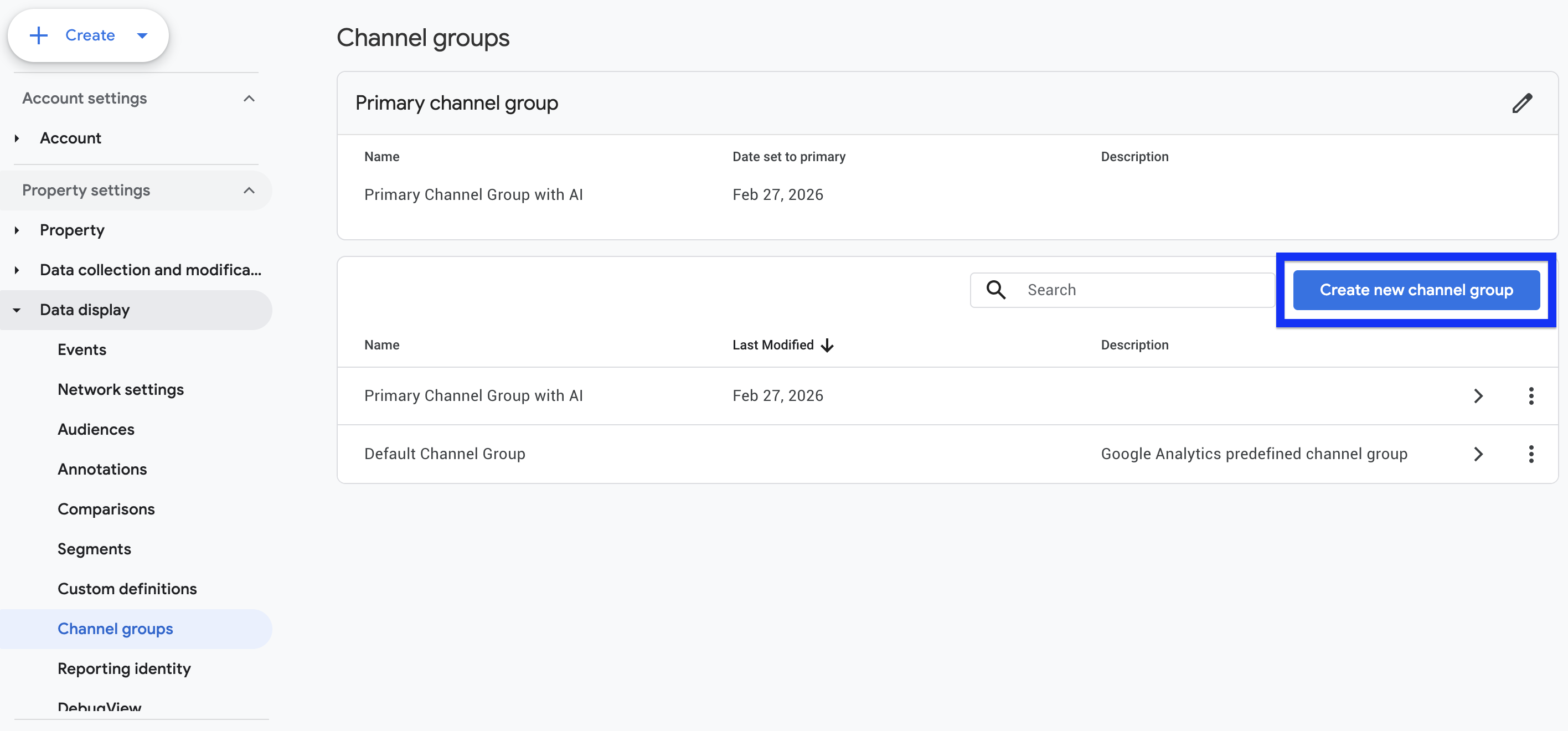
1. Go to Admin > Data display > Channel groups and create a new group.
Image from author, June 2026
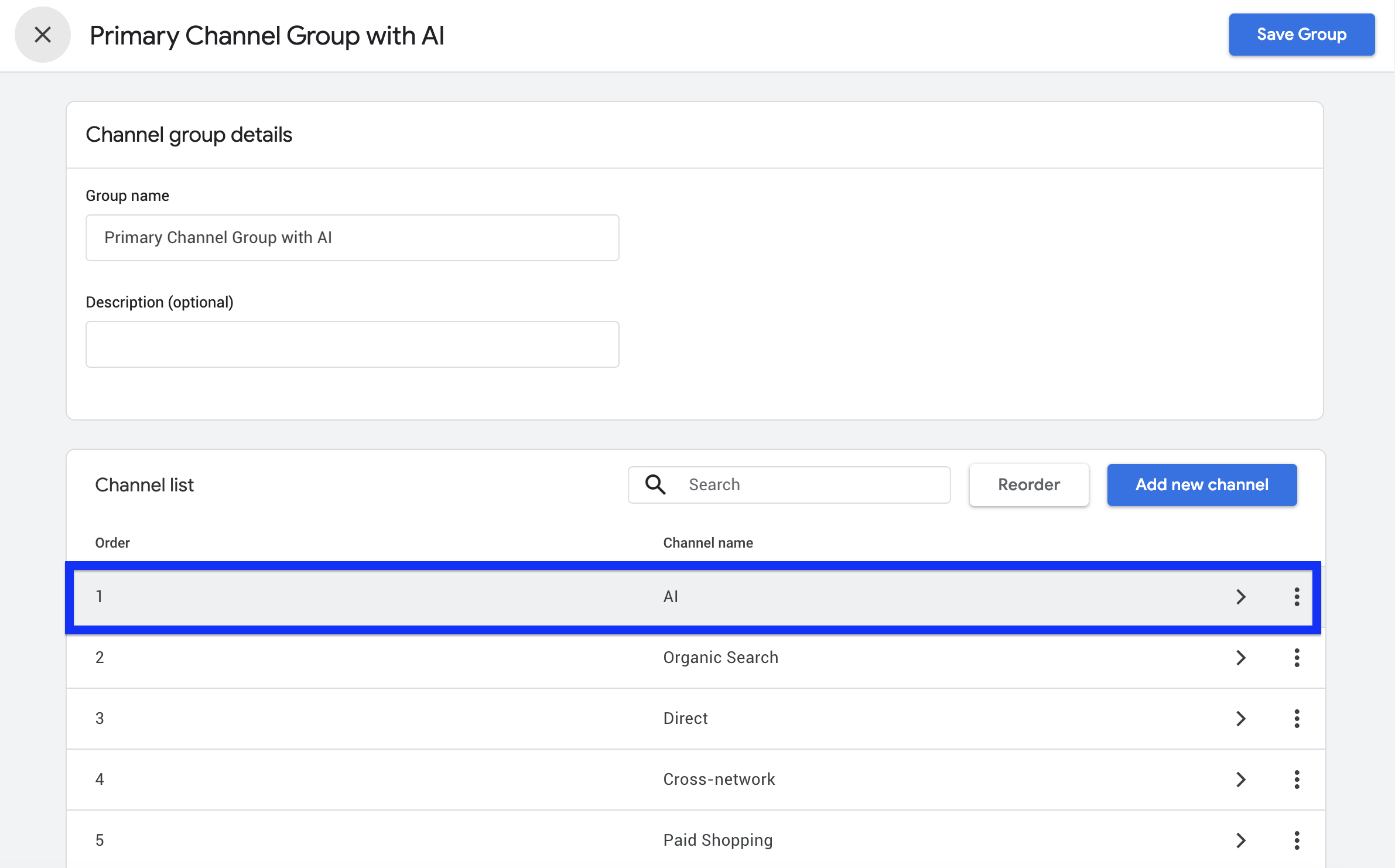
2. Add a channel and call it AI.
Image from author, June 2026
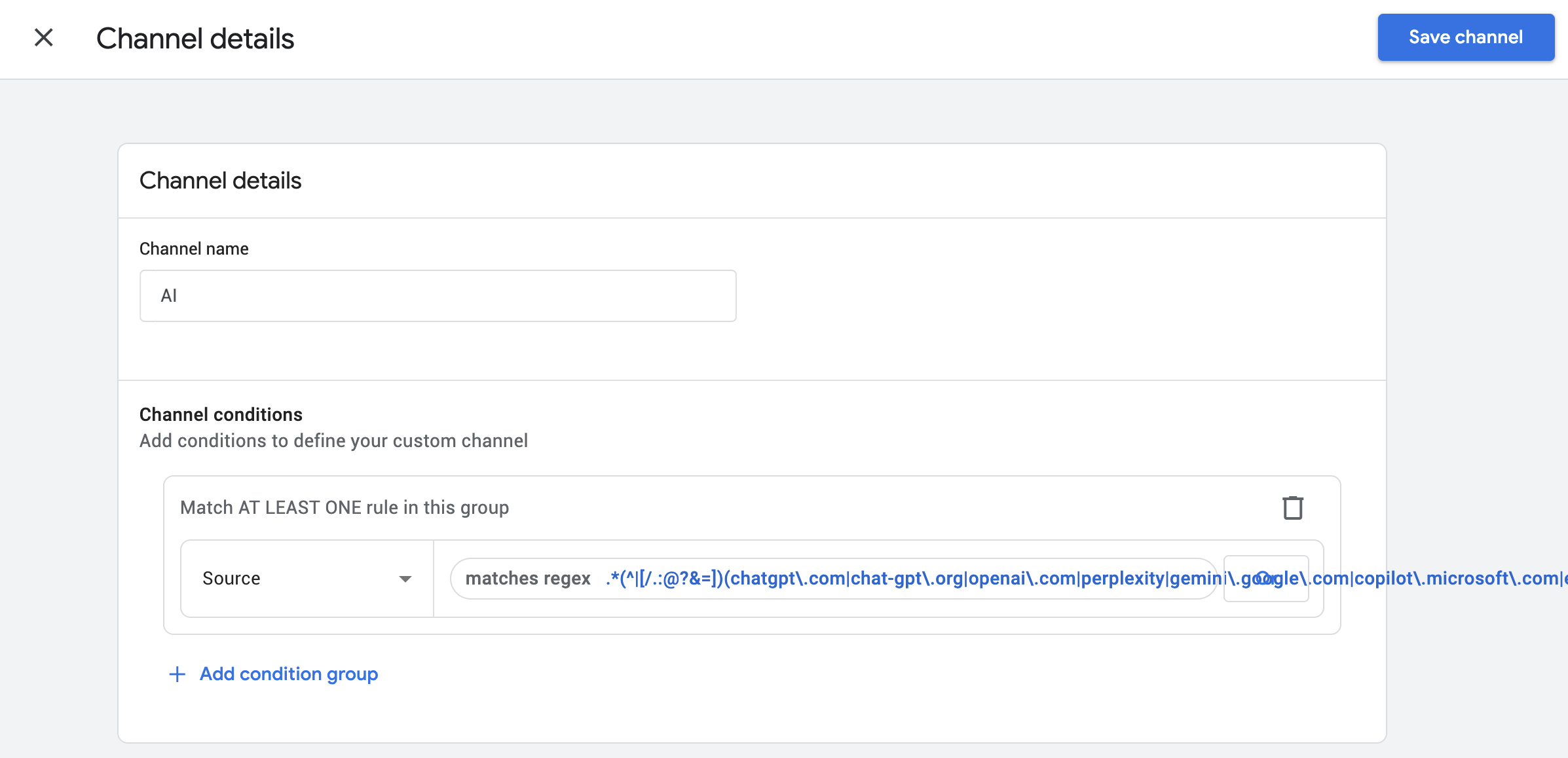
3. Set the condition to Source matches regex, with a pattern covering the AI domains.
Image from author, June 2026
4. Drag the AI channel above Referral and Organic, so it claims those sessions first.
5. Save, then apply the group as your primary dimension in any acquisition report.
The regex is where you can quietly sabotage yourself, so build it carefully. Keep entries tied to recognizable domains or service-specific host tokens. Never throw in a bare token like gpt on its own, because it’ll match any source that happens to contain those three letters and drag in false positives, which is exactly the sort of thing that gets your data picked apart. Here’s a boundary-aware pattern covering the major AI sources you’d want to track:
Two quick notes on that. gemini.google.com is a specific host, so it won’t hoover up all your Google organic, which is exactly why you must never add a bare google to the list. And treat the pattern as perishable. I’d review it every quarter, because platforms come and go and their domains may change.
The Bit Even A Perfect Channel Can’t Fix
This is the part most guides skip, and it’s the part that keeps you honest. A custom channel group fixes how traffic is classified, not whether it gets collected in the first place. A source rule can only catch sessions that showed up with a source it can actually read.
The biggest blind spot is AI traffic with no referrer at all, which lands in Direct. Most of that comes from the AI mobile apps and in-app browsers, which pass nothing for GA4 to read, so there’s no source to match on.
On top of that, Google’s own AI Overviews and AI Mode get counted as Organic Search (google / organic), and Google deliberately keeps them out of the AI Assistant channel. For a lot of sites, that’s the single biggest AI surface there is, and it’s invisible as “AI” in your reports. Don’t try to drag it into your AI channel either, or you’ll swallow up ordinary Google organic by accident.
So, be precise about what you’re claiming. With this custom channel in place, you’ve got a complete and consistent number for the AI sources you can actually identify. What you haven’t got is a measure of total AI influence. Whether an assistant recommended you to someone who never clicked is a completely different problem, and no channel group is going to solve it.
What I’d Do This Week
Treat the native AI Assistant channel as a starting point, not the finished product. Then:
Add Session source/medium to a Traffic acquisition report and go looking for your AI domains spread across AI Assistant, Referral, and Unassigned. Honestly, seeing the split for yourself is half the lesson.
Build the source-based AI custom channel group to pull the fragments back together and recover the history the native channel left behind.
Write down a monthly baseline. With a moving platform list and a big dark slice you can’t see, the month-on-month trend will tell you far more than any single headline figure.
Google finally putting AI traffic on the dashboard is a real step forward. Just remember that the default view hands you the easy slice. The actual work now is knowing exactly which slices it’s quietly leaving out.
The PPC Metrics Your CFO Actually Cares About (And How To Report Them) via @sejournal, @timothyjjensen
You’re finalizing a monthly PPC report, excited to show improvements you’ve seen in the account. You highlight an A/B test that yielded an improvement in CPA, along with a new Meta campaign that is driving marketing qualified leads.
Yet when you present the report to leadership, you still get questions like, “How are these actions helping us grow revenue?”
Knowing your audience is a fundamental principle of marketing, and it applies equally so when creating marketing reports. A report geared to a marketing director who is more in the weeds of individual campaigns will look different from a report geared to a C-level executive.
When creating a report that will be viewed by senior leadership, consider what they are held accountable for. A CFO may answer to shareholders or VC firms, but ultimately, their main concern is increasing revenue. If a report doesn’t clearly answer the question of profitability from an investment in PPC, you’re setting yourself up for failure.
In this article, we’ll consider the metrics your CFO actually cares about when reviewing reporting on paid media campaigns.
A Note On Tracking
Before kicking off any ad campaigns or reporting, make sure that you’ve set up proper conversion tracking on your website to measure key actions in ad and analytics platforms. If you’re not confident in your data measurement approach, you can’t trust the numbers you put in your reports.
Agree On Shared Goals
Before building your first report, you should talk to key stakeholders about what internal revenue goals are and where PPC fits as part of those. For instance, a business may have set an annual goal to grow revenue by 10% or to increase the customer base by 20%.
When considering the metrics you include and how you talk about them, think about how measurement relates to the shared business goals. For instance, you may be able to show not only that Meta had a 10% increase in conversions but that it was the largest contributing channel to the previous month’s growth goal.
It may also be helpful to include a section in your reporting where you highlight overall goals, such as a graph showing total new accounts or revenue vs. planned.
CPA, But Consider The Conversion
Cost Per Acquisition (CPA) is a foundational metric for PPC campaigns. However, one common question faced when presenting performance and including this measure is: “What is a conversion?”
Microconversions, such as form fills and asset downloads, can be helpful for optimization in the right instances, but particularly for higher-level executives, you need to be very clear about what you’re reporting on when sharing a cost tied to a conversion action.
Ideally, CPA in this case should be tied as closely as possible to a customer. While, particularly for long lifecycle businesses, it may not be viable to report on actual customers signed in a monthly PPC report, you may be able to report on sales qualified leads.
In turn, if you have proper CRM tracking to monitor leads through the lifecycle of initial contact to customer, you can include CPAs for customer acquisition over a longer period. For instance, if your average time to final sale is 90 days, show a view of the past 90 days, including total cost and CPAs broken down by marketing qualified leads, sales qualified leads, and final sales.
This leads to a more comprehensive metric: Customer Acquisition Cost (CAC), which represents total sales/marketing expenses divided by the number of customers obtained in the same period.
CAC can be shown as an overall metric, as well as attributed at the channel level if your CRM has the ability to measure customers by the source they came from. You should report on trends over time, which will show both how particular mixes of campaigns and channels are performing, as well as pointing to seasonal trends.
Return On Ad Spend
ROAS may be easier to attribute in some types of accounts than others (for instance, ecommerce vs. B2B products with long sales cycles), but can help point to return on investment from PPC campaigns. If revenue values are being properly measured, ROAS can help to answer the question, “How much did we make from this campaign?”
Of course, be ready to provide context and answer questions about how ROAS is being calculated for your brand. For instance, ad platform numbers may or may not include added costs such as shipping and taxes.
As with CPA and CAC, you should report on ROAS at a blended (cross-account and cross-campaign) level, as well as more granularly, where it makes sense to call out specific efforts.
Lifetime Value
Gaining new customers is great, but what if a customer buys one cheap product and never purchases from your brand again? Or if they pay for a one-month subscription but then cancel?
Incorporating LTV into reporting allows you to see not only which channels and campaigns are driving the most customers but which are contributing to the most valuable ones.
For an ecommerce business, you may look at data for how much revenue is generated from items any one person has purchased over time. For a SaaS business, you may look at the total subscription cost over time. For an industrial equipment supplier, you may look at both how much revenue has come from product purchases and if a customer uses your business for ongoing servicing.
Incremental Growth
When testing a new channel, campaign type, or offer, a key justification for funding is proof that it can drive new revenue that would not otherwise have come from existing efforts. Showing new customer counts and revenue amounts that are incremental to your testing efforts will help in maintaining funding for the future.
Relying solely on in-platform tracking can be tricky here, as a new Google campaign may readily take credit for conversions that are also being tracked in and influenced by Meta. While ad platforms are adding their own methodologies for tracking incremental attribution, these are ultimately still siloed at the platform level.
Using a Media Mix Modeling (MMM) tool here can provide a broader view of how adding to or subtracting from your paid media portfolio is impacting revenue. You can also run incrementality tests either by isolating campaigns to specific geographies and comparing against similar regions, or by comparing two periods of time. Looking at the results at the end of the test can show if a new initiative helped to lift customer and revenue growth.
When presenting on incremental performance, be transparent about the testing methodology, but explain concepts in a way that keeps in mind your leadership team’s level of technical knowledge. Lead with results, and include more technical documentation in an appendix.
Anticipate The Why
When including the above measures that are relevant to your client or stakeholder, think proactively about what questions will come from the data. If conversions are down, you’ll likely be asked why that is the case.
You’ll build rapport with executives reviewing the report if you can be transparent about negative performance, but also be able to provide a reasonable explanation why that is the case. For instance, you might compare seasonal performance to last year at the same time and note that business generally dips. Or a technical issue with a form on the website may have interfered with the ability of prospects to contact you.
Ideally, include brief bullet points in the report addressing these potential concerns up front, and be prepared to talk through deeper explanations if asked.
Start Building Better Reports
Think through the metrics surfaced in this article, along with tactics for presenting them to your CFO and other executives. Now think through how you’ve previously been reporting and any pain points you might have had in reaching shared understanding of performance.
Build on a foundation of solid tracking to highlight the numbers that will resonate the most with the individuals accountable for the purse strings. Be open to hearing out questions you’re asked and additional data that stakeholders might request, and continue to tweak your reports to meet your stakeholders where they are.
Google’s Mueller On First Link Priority & Link Obfuscation via @sejournal, @MattGSouthern
Google Search Advocate John Mueller responded to a plan to hide a homepage button from Google in hopes that a better-worded link further down the page would count instead. He suspects the person behind it is overthinking it.
The r/bigseo thread starts with a question about a homepage that links to the same services page twice. The first link is a ‘Services’ button near the top, while the second sits further down in an FAQ, worded the way the person wants Google to read it.
To get the second link to “win,” they plan to make the more prominent button stop being a link. It would still work when someone clicks it, but the page’s code wouldn’t call it a link anymore. That leaves the FAQ link as the only regular link on the page pointing to the services page.
They asked the thread whether it would make any visible difference.
What Mueller Said
Mueller replied in the thread:
“I suspect you’re overthinking it, Google has practice dealing with lots of websites so I wouldn’t expect you to see any visible change there.
That said, if you wanted to experiment with this, I’d suggest doing something more along the lines of using CSS / JS to position things on the page, regardless of where the link is placed in the HTML. That reduces the potential negative side-effects of “breaking” the HTML (turning links into buttons, or similar, ugh) while still letting you vary the position in your page’s HTML code.”
He didn’t say whether the first link wins. His answer is about the size of the effect and the cost of chasing it.
Why Anyone Would Try This
The idea behind the plan is called first link priority. It says that when one page links to another page twice, Google reads the words in the first link and ignores the second. If that were true, the button would win and the FAQ link would be wasted.
Google has never clearly defined “first link priority.” SEJ’s ranking factors chapter on first link priority traces the idea to a 2008 Rand Fishkin post and finds nothing to support treating it as a rule you can build on. Mueller has said before that Google hasn’t defined the behavior, and that whatever anyone figures out about how Google does it today isn’t necessarily how it will work tomorrow.
Google can run JavaScript, but that doesn’t mean it treats everything clickable as a link. A link written the normal way puts the address inside a link tag, which tells Google where it goes. An address parked in some other element for a script to grab isn’t written as a link at all.
Google’s links best practices documentation says Google can generally only crawl a link when it’s an <a>element with an href attribute, and that it can’t reliably extract URLs from elements that behave like links through script events.
So the button doesn’t turn into a link with its words hidden; it stops being a link. The FAQ link is unaffected, and visitors clicking the button end up in the same place.
What Mueller Suggested Instead
His suggestion leaves the button alone. You move the FAQ link earlier in the page’s code so it comes first, then use CSS to put everything back where visitors expect it. The code order changes, the page looks the same, and both links stay links.
Google’s Martin Splitt made the same point in an SEO 101 session years ago, where his guidance was to use proper anchor markup and avoid buttons and click handlers as navigation.
Why This Matters
Internal anchor text has been an SEO lever for years. That’s why a plan like this sounds reasonable. It also means your homepage’s main button stops being a link, and Mueller wouldn’t expect you to see anything for it.
Looking Ahead
First link priority has gone unconfirmed since at least 2008, roughly as long as people have been running tests to pin it down, and one Reddit reply won’t end that. Anyone who keeps testing it now has Mueller’s version to work from, which changes the order in the code without taking a link away. He gave no indication that changing that order would produce a visible difference.