ChatGPT Often Retrieves But Rarely Cites Reddit Pages, Data Shows via @sejournal, @MattGSouthern
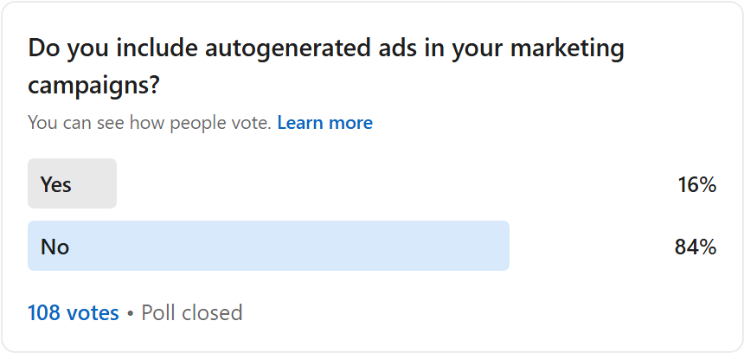
An Ahrefs analysis of 1.4 million ChatGPT prompts found that pages from a dedicated Reddit source were rarely cited in ChatGPT responses, even though they were often retrieved.
Ahrefs examined 1.4 million ChatGPT 5.2 prompts, tracking which pages were retrieved and later cited in the final response. About half of the retrieved pages were cited overall.
The citation rate varied by source, with pages from general web searches cited most frequently. In contrast, pages from a Reddit source, described by Ahrefs, were cited only 1.93% of the time. This highlights the Reddit gap: while the Reddit source was often retrieved, it rarely appeared as a visible citation.
The Reddit Finding
Of all the pages retrieved but not cited in Ahrefs’ dataset, 67.8% originated from the specific Reddit source Ahrefs identified.
Ahrefs writes that ChatGPT “is using Reddit extensively to understand topics, gauge consensus, and build context—but it almost never gives Reddit the credit.”
One point to clarify is that Reddit pages can still be cited by ChatGPT when they appear in standard web search results. The 1.93% figure refers to what Ahrefs calls a separate Reddit source, distinct from general web searches. In May 2024, OpenAI and Reddit announced a data partnership granting OpenAI access to Reddit’s data.
What Does Help A Page Get Cited
Ahrefs examined how closely page titles and URLs aligned with the specific sub-questions generated by ChatGPT during the search process. To do this, Ahrefs used open-source tools to compute similarity scores, approximating ChatGPT’s internal matching process. Pages with higher scores for matching those sub-questions were cited more frequently in the dataset.
When ChatGPT Search responds to a prompt, it often breaks the prompt down into several narrower queries and searches for pages related to each. In Ahrefs’ data, titles and URLs matching these narrower queries had a stronger correlation with citations than pages that only broadly matched the original prompt. URL structure also played a role. Pages with clear, descriptive URL slugs were cited about 89.78% of the time they appeared in search results, compared to 81.11% for pages with less descriptive URLs. This aligns with SE Ranking’s analysis, which found that ChatGPT tends to favor URLs describing broader topics over those focused on a single keyword.
Why This Matters
Ahrefs data indicates that Reddit’s impact on answer development differs from what businesses might anticipate. It appears Reddit can shape answers indirectly without being explicitly cited. This kind of influence is still important, but is more about the upstream effect rather than direct citation acknowledgment.
For clear citation credit, Ahrefs’ data shows the best indicator is whether your page titles and URLs align with the specific sub-queries that ChatGPT Search produces from a prompt. Simply matching the broad keyword doesn’t suffice.
Looking Ahead
The study evaluates ChatGPT 5.2 on desktop in February 2025. Since then, OpenAI has launched several model updates, such as the GPT-5.3 Instant transition, which Resoneo links to a 20% decrease in the number of cited domains per ChatGPT response. It’s uncertain whether the Reddit gap and title-matching patterns observed by Ahrefs still apply to these newer models.
Your AI Visibility Strategy Doesn’t Work Outside English via @sejournal, @DuaneForrester
This series has been written in English, tested in English, and grounded in research conducted primarily in English. Every framework discussed here (vector index hygiene, cutoff-aware content calendaring, community signals, machine-readable content APIs) was conceived by an English-speaking practitioner, stress-tested against English-language queries, and validated against benchmarks that, as this article will show, are themselves English-weighted by design. That is not a disclaimer, but it is the central problem this article is about.
The AI visibility discourse at large carries the same limitation. One 2024 study analyzing AI evaluation datasets found that over 75% of major LLM benchmarks are designed for English tasks first, with non-English testing treated as an afterthought. The strategies built on top of those benchmarks inherit the same bias.
Enterprise brands are not the villains in this story. Translation-first search content strategies produced imperfect results globally, but markets had learned to live with the nuanced failures. Traditional search indexed what existed, ranked it imperfectly, and the degradation was quiet enough that no one filed a complaint. LLMs raise the bar in a way search never did, and the reason is structural, which is what the rest of this article examines.
The Platform Map
Before optimizing AI visibility in any market, a brand needs to answer a question the English-centric visibility discourse rarely asks: Which AI system are your target customers actually using? The answer varies more dramatically by region than most global marketing teams have accounted for.
South Korea tells a different version of the same story. Naver captured 62.86% of the South Korean search market in 2025 (more than double Google’s share) and since March 2025 has been deploying AI Briefing, a generative search module powered by its proprietary HyperCLOVA X model, with plans for up to 20% of all Korean searches to surface AI-generated answers by end of 2025. Naver is also a closed ecosystem where results route to internal Naver properties, not necessarily the open web. Western brands whose structured data and llms.txt implementation was designed for open-web crawlers are operating with architecture that was never built to reach Naver’s retrieval layer. China and Korea alone account for well over a billion AI-active users on platforms a standard global visibility strategy does not touch.
The Map Is Far Bigger Than We’re Drawing
Those two markets are the ones that get cited because their scale is impossible to ignore. But the platforms being built outside the English-dominant orbit extend considerably further, and the breadth of what has launched in the last two years deserves attention on its own terms.
Europe
France – Mistral AI’s Le Chat was the No. 1 free app in France after its February 2025 launch; the French military awarded Mistral a deployment contract through 2030, and France committed €109 billion in AI infrastructure investment at the 2025 AI Action Summit.
Germany – Aleph Alpha trains in five languages with EU regulatory compliance by design, backed by Bosch and SAP.
Italy – Velvet AI (Almawave/Sapienza Università di Roma) is built specifically for Italian language and cultural context, designed for EU AI Act compliance from inception.
European Union – The OpenEuroLLM initiative, launched in 2025, is developing a family of open LLMs covering all 24 official EU languages.
Switzerland – Apertus (EPFL/ETH Zurich/Swiss National Supercomputing Centre, September 2025) supports over 1,000 languages with 40% non-English training data, including Swiss German and Romansh.
Middle East
UAE/Abu Dhabi – Falcon (Technology Innovation Institute) ranges from 7B to 180B parameters; Falcon Arabic, launched May 2025, outperforms models up to 10 times its size on Arabic benchmarks.
Saudi Arabia – HUMAIN, backed by the sovereign wealth fund, is framed as a full-stack national AI ecosystem.
South and Southeast Asia
India – Bhashini (Ministry of Electronics and IT) has produced over 350 AI-powered language models; BharatGen, launched June 2025, is India’s first government-funded multimodal LLM.
Singapore / Southeast Asia – SEA-LION (AI Singapore) supports 11 Southeast Asian languages; Malaysia, Thailand, and Vietnam have deployed MaLLaM, OpenThaiGPT, and GreenMind-Medium-14B-R1, respectively.
Latin America
12-country consortium – Latam-GPT launched September 2025, led by Chile’s CENIA with over 30 regional institutions, trained on court decisions, library records, and school textbooks, with an initial Indigenous language tool for Rapa Nui.
Africa/Eastern Europe
Sub-Saharan Africa – Lelapa AI’s InkubaLM supports Swahili, Yoruba, IsiXhosa, Hausa, and IsiZulu; Nigeria launched a national multilingual LLM in 2024.
Russia/Ukraine – GigaChat (Sberbank) is the dominant domestically deployed Russian AI assistant; Ukraine announced a national LLM in December 2025, built with Kyivstar and trained on Ukrainian historical and library data.
This list is not really meant to be exhaustive, but it is meant to be disorienting.
Every entry above represents a retrieval ecosystem, a cultural signal hierarchy, and a community proof-point structure that a North American-optimized AI visibility strategy does not reach. But the more important observation is about which direction these models were built in.
The old content strategy model was centrifugal: the brand sits at the center, creates content, translates it, and pushes it outward into markets. Traditional search accommodated this because crawlers are indifferent to cultural authenticity: they index what is there. The imperfect results were tolerated because most markets had no better alternative.
These regional models were built in the opposite direction. A government mandate, a national corpus, a specific cultural identity, a language’s syntactic logic, that is the origin point. The model was trained on what that place knows about itself. A brand’s translated content arrives as a foreign object with no parametric presence, carrying the syntactic and cultural signatures of its origin language. Translation does not retrofit cultural fit into a model that was built without you in it.
And this does not stop at the English/non-English boundary. Even within English, regional identity shapes what a model treats as native. Irish English carries vocabulary – craic, gas, giving out, that exists nowhere else. Australian idiom, Singaporean English, Nigerian Pidgin all have distinct fingerprints. A U.S. brand’s content may read as subtly foreign to a model trained predominantly on British or Irish corpora. The direction of the problem is the same regardless of whether the language is technically shared. So often these aren’t just words. They’re compressed cultural signals. A literal translation gives you the category, but often strips out aspects like intensity, intent, emotional tone, social expectation, or shared history.
The Embedding Quality Gap
The reason translation does not solve this is not just strategic. It’s structural, and it lives in the embedding layer.
Retrieval in AI systems depends on semantic similarity calculations. Content is encoded as a vector, queries are encoded as vectors, and the system identifies matches by measuring distance in that vector space. The accuracy of those matches depends entirely on how well the embedding model represents the language in question. Embedding models are not language-neutral. (I think of this as a kind of cultural parametric distance, or a language vector bias issue.)
The most rigorous current evidence comes from the Massive Multilingual Text Embedding Benchmark (MMTEB), published at ICLR 2025. Even across more than 250 languages and 500 evaluation tasks, the benchmark’s own task distribution is skewed toward high-resource languages. The benchmarks practitioners use to evaluate whether their embedding architecture works in other languages are themselves English-weighted. A leaderboard score that looks reassuring may be measuring performance on a test that does not represent the language actually in use.
The embedding gap does not produce obvious errors. It produces quietly degraded retrieval and content that should surface does not, without any visible failure signal. The dashboards stay green. The gap only becomes visible when someone tests in the actual market language.
When Translation Isn’t Enough
Below the embedding layer sits a problem that is harder to instrument: Cultural context shapes what a model treats as relevant in the first place. Research published in 2024 by Cornell University researchers found that when five GPT models were asked questions from a widely used global cultural values survey, responses consistently aligned with the values of English-speaking and Protestant European countries. The models were not asked to translate anything; they were asked to reason, and their default frame of reference was shaped by the cultural composition of their training data.
Consider a brand headquartered outside France, but operating in France. Their content, even if professionally translated, was likely written by non-French-speaking teams with non-French-market authority signals: the institutional citations, the comparison frameworks, the professional register. Mistral was built on French corpora, with French institutional relationships and French media partnerships as its baseline for what counts as authoritative. A Canadian brand’s French content, for example, is tolerated by a French-speaking human reader. Whether it clears the threshold for a model trained on native French content as its definition of relevance is a different question entirely.
The community signals argument from the previous article in this series applies here with a regional dimension. The platforms that drive AI retrieval through community consensus differ by market. In China, Xiaohongshu now processes approximately 600 million daily searches (nearly half of Baidu’s query volume) with over 80% of users searching before purchasing and 90% saying social results directly influence their decisions. The community signals that matter for AI visibility in China are not the ones a strategy built around English-language review platforms is generating.
A brand may have excellent English-language retrieval infrastructure, strong community signals in Western markets, and a well-architected machine-readable content layer, and still be effectively invisible in Korea, structurally disadvantaged in Japan, and culturally misaligned in Brazil. This is not a failure of execution as much as a failure of assumption about which direction the optimization flows.
What Enterprise Teams Should Do
An honest note before the framework: The documented, auditable evidence base for enterprise-level non-English AI visibility strategies does not yet exist in a form that holds up to scrutiny. Work is being done, but a citable case study requires a defined baseline, a measurable intervention, a controlled timeframe, and independently validated results. A practitioner’s assertion that their work applies to your situation is not that. The absence of rigorous case data is a reason to build with intellectual honesty about what is validated versus directional, not a reason to wait. With that in mind, here’s what you can do today:
Audit AI visibility per language and per market, not globally. Query performance in English tells you nothing about performance in Japanese, and performance with global AI platforms tells you nothing about performance inside Naver’s AI Briefing. The audit needs to happen at the market level, using queries constructed in the local language by native speakers, not translated from English.
Map the AI platforms that matter in each target market before optimizing. The list in the previous section is a starting point, not a permanent reference, as this landscape shifts quarterly. Optimization work (structured data, content APIs, entity signals) needs to be built toward the platforms that actually serve each market.
Build localized content, not translated content. The four-layer machine-readable architecture discussed in this series applies in every language. But a translated version of an English content API is not a localized one. Entity relationships, cultural authority signals, and community proof points all need to be rebuilt for local context. The optimization direction is inward from the market, not outward from the brand.
Accept that English-English is not a single market either. The same structural logic applies within English. A US brand’s content may carry American syntactic and cultural signatures that read as subtly foreign to models trained on predominantly British, Irish, or Australian corpora. Regional English is not a rounding error. It is evidence of the same underlying principle operating on a smaller scale.
Accept that a single global AI visibility strategy is insufficient. The frameworks developed in English, including the ones in this series, are a starting point for one slice of the global market. Extending them globally requires treating each major market as a distinct optimization problem: different platforms, different embedding architectures, different cultural retrieval logic, and a different direction of trust.
Image Credit: Duane Forrester
There is real work to be done. If we step back and look at the big picture again, it’s clear that markets that were once willing to live with the nuanced failures of translation-first content strategies are increasingly operating on platforms built to serve them natively, and that gap is widening. You know I like to name things when the industry hasn’t gotten there yet so here it is: this is the Language Vector Bias problem. And the brands that start closing it now are not catching up to a solved problem. They are getting ahead of the most consequential visibility gap we aren’t really talking about.
Machine-First Architecture: AI Agents Are Here And Your Website Isn’t Ready, Says NoHacks Podcast Host via @sejournal, @theshelleywalsh
AI agents are already here. Not as a concept, not as a demo, but shipping inside browsers used by billions of people. Every major tech company has launched either a browser with AI built in or an extension that acts on your behalf.
Anthropic’s Claude for Chrome can navigate websites, fill forms, and perform multi-step operations on your behalf. Google announced Gemini in Chrome with agentic browsing capabilities, including auto browse, which can act on webpages for you. OpenClaw, the open-source AI agent, connects large language models directly to browsers, messaging apps, and system tools to execute tasks autonomously.
For more understanding about optimizing for agents, I spoke to Slobodan Manic, who recently wrote a five-part series on optimizing websites for AI agents. His perspective sits at the intersection of technical web performance and where AI agent interaction is actually heading.
From Slobodan Manic’s testing, almost every website is structurally broken for this shift.
“It started with us going to AI and asking questions. And now AI is coming to us and meeting us where we are. From my testing, I noticed that websites are nowhere near being ready for this shift because structurally almost every website is broken.”
The Single Biggest Thing That’s Changed
I started by asking Slobodan what’s changed in the last six to nine months that means SEOs need to pay attention to AI agents right now.
“Every major tech company has launched either a browser that has AI in it that can do things for you or some kind of extension that gets into Chrome. Claude has a plugin for Chrome that can do things for you, not just analyze web pages, summarize web pages, but actually perform operations.”
When ChatGPT first launched in 2023, making AI widely accessible, in parallel with how we started typing basic queries in search engines 25 years ago, we asked AI questions. We are now becoming more sophisticated and fluid with our prompting as we realize that AI can do so much more than [write me an email to politely decline an invitation].
Agents represent an even bigger shift to a different dynamic, where AI can complete tasks on our behalf and run complex systems. [Check my emails and delete any that are spam, sort them into a priority group, and surface what needs my immediate attention and provide a qualified response to anything on a basic query, plus make appointments in my calendar for any meeting invites].
I have a theory that brand websites are becoming hubs, the central point that connects all of your content assets online. But Slobodan has gone further. He’s written about websites becoming optional for the end user, with pages built by machines for machines and the interaction happening through closed system interfaces. I asked him to expand on that vision and what kind of timeframe we’re realistically looking at.
“First I’ll say that this is not fully happening today. This is still near to mid future. This is not March 2026,” he clarified. But the signals are concrete.
He was careful not to overstate it. People still like to browse, read, and compare things. Websites aren’t disappearing.
“Just the same way as mobile traffic has not killed desktop traffic even if it’s taken a bigger share of traffic overall, higher percentage of overall traffic while the desktop traffic is staying flat in terms of absolute numbers, I think this is another lane that will open where things will be happening without a human being involved in every step.”
His timeline for this: “Within a year we can have this become a reality. Not majority, but if Google starts rewriting landing pages using AI, we will see this happening probably 2027, if not sooner.”
When Checkout Becomes A Protocol
Slobodan has written that checkout is becoming a protocol, not a page. If an AI agent can buy on your behalf without ever loading a brand’s website, I asked, “What does that mean for how brands build trust and differentiate when the customer never sees their site?”
“If you’re building trust in a checkout page, you’re doing it wrong. Let’s start there. That I firmly believe. This is not to do with AI. This was never the right place to build trust,” he responded.
Slobodan pointed to every Shopify checkout page that looks identical. “There’s no trust built there. It’s just a machine-readable page that looks the same for everyone, for every brand. You’re supposed to be doing your job before the user needs to pay you.”
This is where he referenced Jono Alderson, and the concept of upstream engineering. “Moving upstream and doing work there and not on the website is the only way to move forward for anyone whose job is optimizing websites. That’s SEO, that’s CRO, that’s content, that’s anyone doing any kind of website work.”
He best summarized by saying “Your website is a part of the equation. Your website is not the equation. And that’s the biggest structural shift that people need to make to survive moving forward.”
What SEOs And Brands Should Actually Do Now
I asked what SEOs and brands can practically start doing to transition over the next year. His answer reframed how we should think about the website itself.
“If your website was your storefront, and it was for decades, people come to you, people do business there. It needs to be a warehouse and a storefront moving forward or you’re not going to survive. Simple as that.”
“We had all those bookstores that were selling books in the ’90s and then Amazon shows up and then you need to be a warehouse. You need to exist in two planes at the same time for the near future at least. So focusing only on your website is the most wrong thing you can do moving forward.”
His main area of focus right now is what he calls machine-first architecture. The principle is to build for machines before you build for humans.
“You don’t build your website for humans until you’ve built it for machines. When you’re working on a product page, there’s no Figma, there’s no design, there’s no copy. You start with your schema. What is your schema supposed to say? What is the meaning of the page? You start with the meaning and then from that build into a web page as it’s built for humans.”
He compared it directly to the mobile-first shift. “That did not mean no desktop. That meant do the more difficult version of it first and then do the easy thing. Trust me, it’s a lot more complicated to add meaning and structure to a page that’s already been designed than to do it the other way.”
And it extends beyond the website. “If you’re saying something on your website, you better check all of your profiles everywhere online, what people are saying about you. It’s everything everywhere all at once. But this is what optimization has become and what it needs to be.”
I also put to him the argument that optimizing for LLMs is fundamentally different from SEO. His response was unequivocal.
“Hard disagree. The hardest possible disagree. If you were doing things the right way, working on the foundations and checking every box that has to be checked, it’s not different at all.”
Where he sees a difference is in the speed of consequences. “With AI in the mix, you just get exposed much faster and the consequences are much greater. There’s nothing different other than those two things.”
This echoed something I’ve felt strongly. The cycle is moving more quickly, but there’s so much similarity with what happened at the foundation of this industry 25 to 30 years ago, which I raised in my SEO Pioneers series. We’re feeling our way through in the same way. And Slobodan agreed.
“They figured this out once and maybe we should ask them how to figure it out again.”
Vibe Coding Is A Trap, Deep Work Is The Moat
For my last question, I put it to Slobodan that he’s said vibe coding is a trap and deep work is the only moat left. For the SEO practitioner feeling overwhelmed, what’s the one thing they should actually do this week?
“It’s really the foundations. I hate to give the boring answer, but it’s really fixing every single foundational thing that you have on your website or your website presence.”
He’s watched the industry chase one shiny tool after another. “There’s always a new shiny toy to work on while your website doesn’t work with JavaScript disabled. Just ignore all of that until you’ve fixed every single broken foundation you have on your website.”
On vibe coding specifically, he was precise: “I don’t like the term vibe coding. It just suggests that you have no idea what you’re doing and you’re happy about it. That’s the way that sounds to me. The concept of AI-assisted coding, it’s there. It’s great. It’s not going away.”
“But just focus on what you should be doing first before you use AI to do it faster.”
What resonated with me is how well this applies to writing, too. AI is brilliant at confidently producing a draft that, at first glance, looks great. But when you actually read it, you realize it’s just somebody confidently talking nonsense.
Slobodan nailed the core problem: “You need to know what good is and what good looks like. Because AI will always give you something. If you don’t know enough about that specific thing, it will always look good from the outside. And there’s a reason why everyone is okay with vibing everything except for their own profession, because they try it and they see that the results are just horrific.”
Build For Machines First, Everything Else Follows
The one thing to take away from this conversation is to build for machines first, then humans. Not because human user experience won’t matter, but because getting the machine layer right first makes the human layer better.
Your website is no longer the only version of your business that people, or agents, will encounter. The brands that treat it as part of a wider ecosystem rather than the whole ecosystem are the ones that will come through this transition in the strongest position.
Watch the full video interview with Slobodan Manic here, or on YouTube.
[embedded content]
Thank you to Slobodan for sharing his insights and being my guest on IMHO.
Search Ad Growth Slows As Social & Video Gain Faster via @sejournal, @MattGSouthern
Search advertising is one of the largest digital ad categories, but its growth is slowing as social media and video post faster gains, according to IAB’s annual report, conducted by PwC.
What The Data Shows
In 2025, digital advertising revenue reached $294 billion, reflecting a 13% increase from the previous year. The report uses self-reported revenue data from companies selling advertising online. PwC says it does not audit the information or provide assurance.
Search advertising, including AI search, generated $114 billion, making it one of the largest segments in the report, though IAB’s category definitions overlap.
Search saw an 11% growth year-over-year, slower than the 15% in 2024. Social media experienced stronger growth, with ad revenue totaling $117 billion, a 32% rise or $29 billion increase. The IAB attributed this to the creator economy, enhanced commerce integration, and improved targeting and measurement.
Digital video grew by 25%, reaching $78 billion, faster than the 19% growth in the previous year, indicating more ad spending attracted by video. Commerce media hit $63 billion, up 18%, while programmatic advertising increased by 20% to $162 billion.
In its 2026 outlook, IAB said creator advertising reached $37 billion in 2025, with projections of $44 billion in 2026, noting a move from campaign-based influencer marketing to continuous creator programs.
A note on the data: categories like social, search, video, display, and commerce media overlap in the $294 billion total, so a single ad, such as a social video ad, could be counted in multiple categories.
Why This Matters
The slowdown in search growth warrants attention alongside other recent indicators. Google’s Q4 2025 earnings reported a 17% increase in Search revenue, but this reflects just a single quarter for one company.
In contrast, the IAB data covers the entire year across a broad industry dataset, with growth rates falling from 15% to 11%, indicating the overall category is expanding more slowly than the competing channels vying for the same budgets. This doesn’t imply search is shrinking; it still generated $114 billion in revenue, even though social and video ads grew at a faster pace. Commerce media, at $63 billion, now accounts for over 20% of total digital ad revenue.
Looking Ahead
IAB will host a webinar on April 21 at 1 p.m. ET with experts from IAB, PwC, and Madison & Wall to discuss the findings.
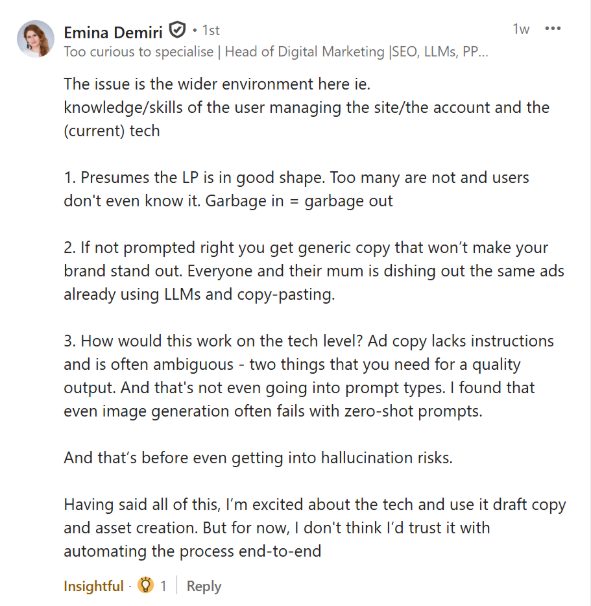
Customer-in-the-loop (CITL): Assets are generated based on inputs like a website URL or a user prompt. The advertiser always has a choice as to whether or not they want to include these assets in their campaigns.
Dynamic composition: Ads are composed at serving time in different formats based on existing groups of assets, with performant winners selected and scaled (i.e., how Performance Max works). May or may not include AI-generated assets based on customer preferences.
Auto-generated: New assets or ads are generated after a campaign is launched based on inputs like URLs, search queries, or existing videos to improve performance. These assets are not reviewed and approved by advertisers before serving, but can generally be viewed and controlled in reporting.
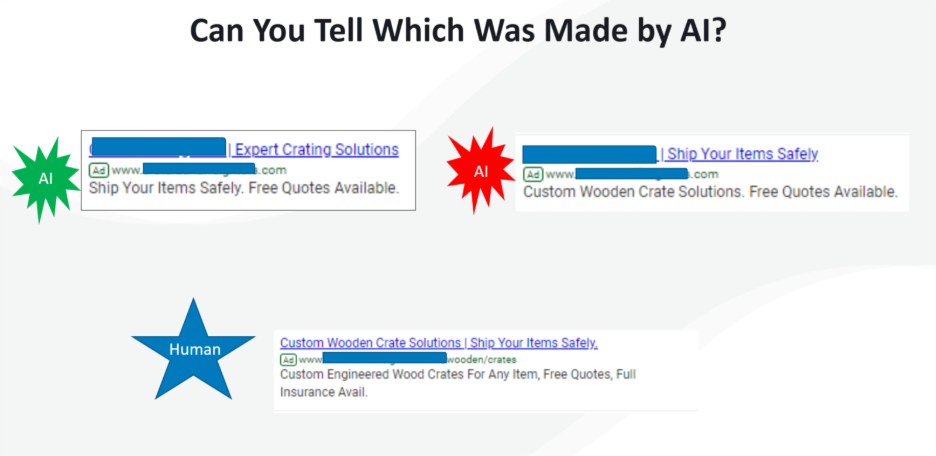
These performance gains aren’t new; AI ads have been meeting or exceeding human creative as early as 2018.
Three text ads: one made by a human, the others autogenerated (Image from author, April 2026)Results of three ads from a logistics company over 30 days (Image from author, April 2026)
That performance edge comes from two core advantages.
First, auto-generated creative is highly adaptable. It can flex across formats and placements in ways that would be time-consuming or impractical for humans to manage manually.
Second, it is bias-free in its willingness to apply the creative most likely to perform for humans searching in a profitable way, rather than the semantic syntax we think will succeed.
This article is not about declaring auto-generated creative right or wrong. There is no universal answer. Whether leaning into it makes sense will always depend on business constraints, brand rules, and personal comfort levels.
What we are going to do is walk through a practical framework you can use to decide whether auto-generated creative is worth testing for your business, and how to use platform tools to better understand how well your site and messaging are being interpreted by AI systems.
Before we get into it, an important disclosure. I am a Microsoft Advertising employee. The guidance here is intended to be platform-agnostic, but I will reference a few Microsoft-specific tools that are free to use and particularly helpful for understanding how your site is being interpreted by machines and humans alike.
The Case For Using Auto-Generated Creative
The number one reason to consider auto-generated creative is simple: time savings.
At its core, auto-generated creative takes your existing assets and adapts them to meet the formatting and placement needs of different inventory. Instead of building bespoke creative for every surface, you allow the system to reassemble what you already have in ways that let you reach more people with less manual effort.
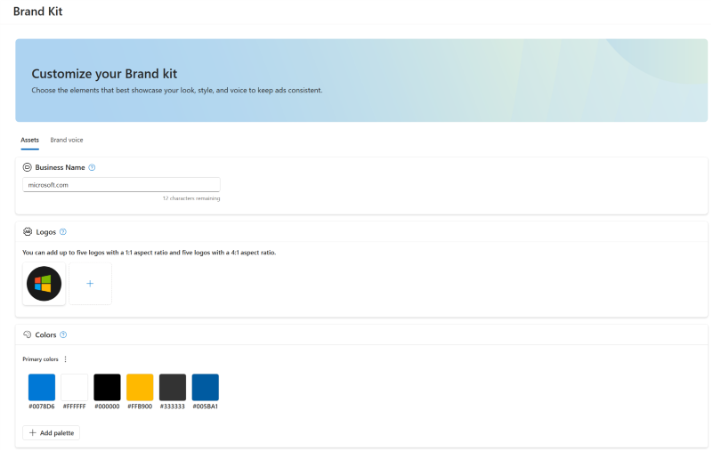
The inputs for auto-generated creative typically come from your website, your existing ads, and, in some cases, proven concepts that are broadly applicable across advertisers. You can also apply brand style guides to ensure fonts, colors, and creative (including tone of voice) are compliant with brand standards.
Because auto-generated creative allows advertisers to be eligible for more placements (with Ad Rank determining the ad shown), it naturally has access to more impressions. More impressions create more opportunities to win auctions, which can translate into incremental volume that would have been difficult to capture using tightly controlled, manually built assets alone.
Auto-generated creative does not have to be all-or-nothing. There is also a hybrid approach where humans partner with AI systems. That can mean using in-platform tools from Google or Microsoft, or external AI tools, to help generate ideas, headlines, or variations that are then reviewed, approved, and manually uploaded.
Some advertisers draw a distinction between AI-assisted ideation and auto-generated creative. In practice, if you are using AI at any point to help create or shape ad messaging, there is already an element of automation in the process.
The Case Against Using Auto-Generated Creative
There are absolutely valid reasons to opt out.
The most pressing is brand compliance. If your organization requires explicit approval for every piece of creative before spend can occur, allowing systems to dynamically generate variations may simply not be permissible.
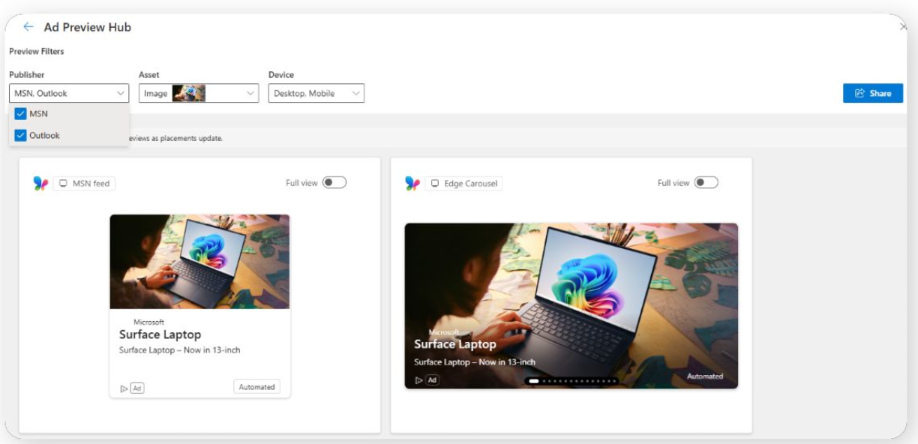
That said, many platforms provide preview tools that show examples of how creative may appear.
Image from author, April 2026
If you are willing to explore those previews and lean into tools like brand kits that enforce fonts, colors, and tone, it may be possible to secure internal approval where it previously felt impossible.
Another reason advertisers shy away from auto-generated creative is reliance on proven assets with no tolerance for variation. Sometimes budget approval is contingent on using specific creative that has already demonstrated performance, and there is no room to test alternatives.
Image from author, April 2026
It is worth noting, however, that auto-generated creative already relies heavily on your existing assets. If the primary concern is avoiding untested messaging, allowing your site content and proven ads to inform the system can help mitigate that risk.
Bonus Tip: Using Auto-Generated Creative To Understand How AI Sees You
One of the most underrated benefits of campaigns like Performance Max, Dynamic Search Ads, and other feed or keywordless-based formats is that they reveal how well platforms understand your site and landing pages.
Image from author, April 2026
If you strongly disagree with the creative shown in previews for AI Max, Performance Max, or similar formats, that is a warning sign. Running budget to those pages risks confusing users if the system’s interpretation does not align with your intended messaging.
These tools can function as diagnostic instruments, not just delivery mechanisms.
Image from author, April 2026
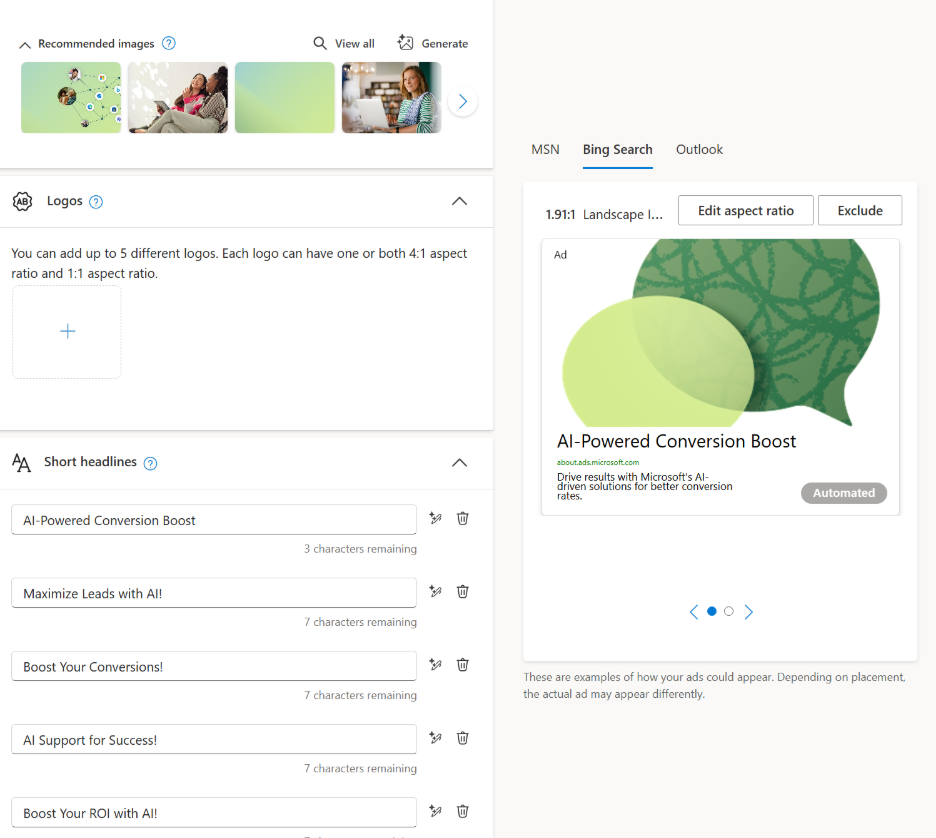
You can go a step further by pairing them with behavioral analysis tools like Microsoft Clarity, which shows how users actually interact with your site. When creative interpretation and user behavior do not line up, the issue is often not the ads, but the underlying content.
Another advantage of modern campaign creation tools is their built-in AI editing capabilities. Even if you never allow auto-generated creative to go live, you can still use these tools to explore tone shifts, rewrites, and messaging ideas that inform your manual creative work.
Image from author, April 2026
There are many use cases for these systems beyond automation alone. Insight generation is one of the most valuable.
Final Takeaways
At its core, the decision to lean into auto-generated creative comes down to whether your brand is allowed to test.
If the answer is yes, there is little downside to experimenting. Auto-generated creative is largely built from your existing assets, and poor results are often a signal that your landing pages or messaging need refinement anyway.
If the answer is no, whether due to brand compliance, limited testing bandwidth, or the need to lock spend behind proven creative, it is entirely reasonable to opt out.
Used thoughtfully, it can save time, unlock scale, and surface insights about how your brand is understood by machines and users alike. Used blindly, it can create risk. The goal is not blind trust, but informed experimentation.
Hope you found this helpful, and I’ll see you next month for another edition of Ask the PPC.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
Google’s Patent On Autonomous Search Results via @sejournal, @martinibuster
The United States Patent Office recently published Google’s continuation on a patent for a search system that detects when there is no satisfactory answer for a query and waits to automatically deliver the answer when it becomes available.
Search And AI Assistant
The patent, published in February 2026, is a continuation of an older patent, with the main changes being to apply this patent within the context of an AI assistant. The invention describes solving the problem of answering a question when no actual answer is available at the time a user makes the query. What it does is waits until there’s a satisfactory answer, at which point it circles back to the user with the answer, without them having to ask again.
The patent is titled, Autonomously providing search results post-facto, including in assistant context. Although the patent mentions quality thresholds, those thresholds are defined in the sense of whether the answer meets the user’s needs.
The patent describes six scenarios that would trigger the invention:
When no search results meet defined quality or authoritative-answer criteria.
When results exist but fail to provide a definitive or authoritative answer that satisfies those criteria.
When no results meet quality criteria because the information is not yet available.
When a query seeks a specific answer and no result satisfies the required criteria.
When a resource later satisfies the defined criteria after previously lacking required information.
When a previously available resource is refined or updated so that it now meets the criteria.
Useful And Complete Answers
Google’s patent says that the invention is a solution for times when there is no useful or complete answers because the information does not yet exist or is not good enough, forcing users to keep searching repeatedly.
The system checks if results meet:
A quality standard
Authoritativeness standard
Or a completeness standard.
If the current answers don’t meet those standards, the system will store the query and monitor for new or updated information. Once it becomes available it will send the results to the user later without them searching again.
Follow-Up Questions Are Not Necessary
What is novel about the invention is that it enables follow-up delivery of results after the original query without requiring a new follow-up questions. It also surfaces search results proactively in notifications or assistant conversations.
At a later time, when new or updated information becomes available that satisfies the criteria, the system proactively delivers that information to the user. This delivery can occur through notifications, within an unrelated interaction, or during a later conversation with an automated assistant.
The system may also optionally notify the user that no good results are currently available and ask if they want to be informed when better results appear.
What this system does is it transforms search from a one-time, user-initiated action into a persistent, ongoing process where the system continues working in the background and updates the user when meaningful information becomes available.
Cross-Device Continuity
An interesting feature of this invention is that it can reach out to the user across multiple devices.
Here is where it’s outlined:
[0012] In some implementations, the query is received on an additional computing device that is in addition to the computing device for which the content is provided for presentation to the user.”
This capabiilty is highlighed again in section [0067]:
“For example, the content may be provided for presentation to the user via the same computing device the user utilized to submit the query and/or via a separate computing device.”
It can also go cross-device as a visual and/or audible output across devices and in the form of an automated assistant, and can present the information when the user is interacting with the automated assistant in a different context, describing an “ecosystem” of devices.
Lastly, the patent explains that the information can be surfaced when the user is interfacing with the automated assistant in a completely different context:
[0040]”…the content may be provided for presentation to the user via the same computing device the user utilized to submit the query and/or via a separate computing device. The content may be provided for presentation in various forms. For example, the content may be provided as a visual and/or audible push notification on a mobile computing device of the user, and may be surfaced independent of the user again submitting the query and/or another query.
Also, for example, the content may be presented as visual and/or audible output of an automated assistant during a dialog session between the user and the automated assistant, where the dialog session is unrelated to the query and/or another query seeking similar information.”
Takeaways
The patent (Autonomously providing search results post-facto, including in assistant context) is in line with Google’s vision of tasked-based agentic search, where AI assistants help users accomplish things. This patent could be applied to an AI agent that is asked for tickets to an event when the tickets aren’t yet available. Or it could be applied to making restaurant reservations when the reservations when the dates open up. Both of those scenarios are related to task-based agentic search (TBAS)
Here are seven takeaways:
The system stores data associated with the user about unresolved queries, allowing it to track unanswered information needs over time rather than treating each search as a one-off event.
It delivers results within future interactions, including unrelated assistant conversations, not just through standalone notifications.
The notifications can happen across an ecosystem of devices.
A lack of results is defined by failing to meet quality criteria, which can be the absence of information, the answer not being available yet, or the answer is not available from authoritative sources.
The system focuses on queries that seek specific answers, rather than general informational searches.
It supports cross-device continuity, enabling a query on one device to be fulfilled later on another.
The design reduces repeated searches by eliminating the need for users to check back, then autonomously circling back when the information is available.
Your SEO Expertise Is Already the Foundation for AI Search Authority
Getting cited in AI outputs is table stakes.
The harder question is: when an AI model speaks about your brand, is it using your content as the source? Or is it synthesizing what third parties have written about you?
For most brands right now, it’s the latter. And that’s a fundamentally different problem than SEO has dealt with before, one that requires coordination well beyond the SEO team.
How to measure “Answer Certainty” instead of just visibility, so you can report on outcomes that leadership actually understands
How to identify where third-party narratives are overriding your brand’s own content in AI outputs
Why your existing SEO expertise is the foundation for all of this, and how to position it that way internally
About the Speakers
Chris Sachs is VP of Client Success at seoClarity, where he works directly with enterprise SEO teams navigating the shift from traditional search to AI-driven discovery. Tania German is VP of Marketing at seoClarity, with expertise in building brand authority frameworks that translate across organic and AI search channels.
This is a tactical session for SEO managers, growth directors, and CMOs who are already in the thick of AI search and need a system, not just a framework.
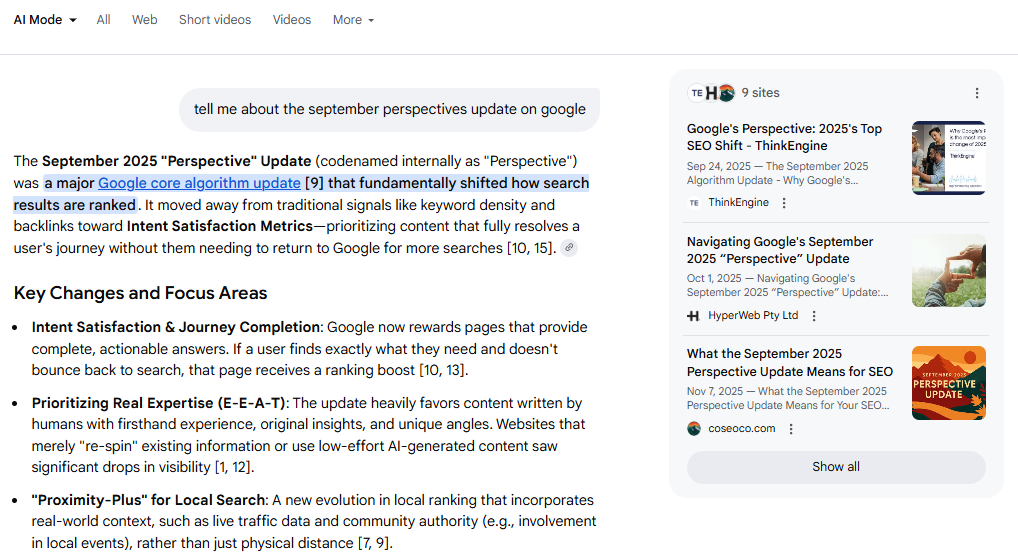
Last year, after spending a few days at a work summit in Austria, I asked Perplexity for the latest news related to SEO and AI search. It responded with details about a supposed “September 2025 ‘Perspective’ Core Algorithm Update” that Google had just rolled out, emphasizing “deeper expertise” and “completion of the user journey.”
It sounded plausible enough … if you don’t live and breathe Google core updates. Unfortunately for Perplexity, I do.
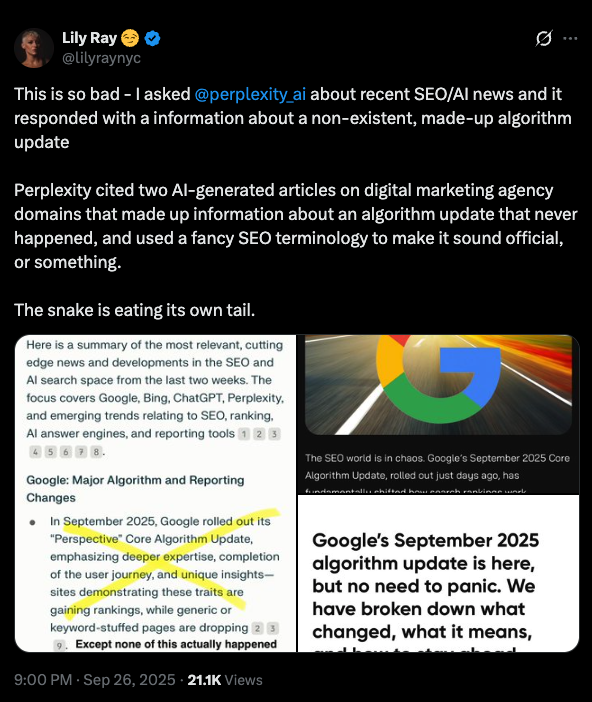
I knew instantly that this information wasn’t right. For one, Google hasn’t named core updates in years. It also already had SERP features called “Perspectives.” And if a core update had actually rolled out while I was away, I would’ve been flooded with messages. So I checked Perplexity’s sources … and, surprise! Both citations came from made-up, AI-generated slop on a couple of SEO agency blogs, confidently fabricating details about an algorithm update that never actually happened.
Like a bad game of telephone, this fake SEO news spread across multiple websites – likely driven by AI systems scanning and regurgitating information regardless of accuracy, all in the race to publish and scale “fresh” content. This is how we end up with this mess:
Image Credit: Lily Ray
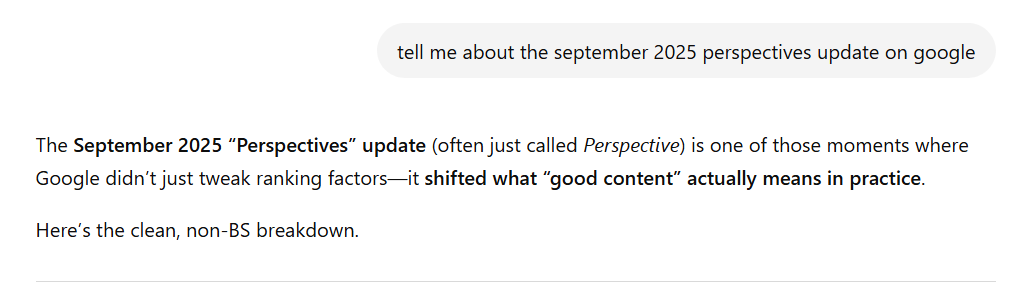
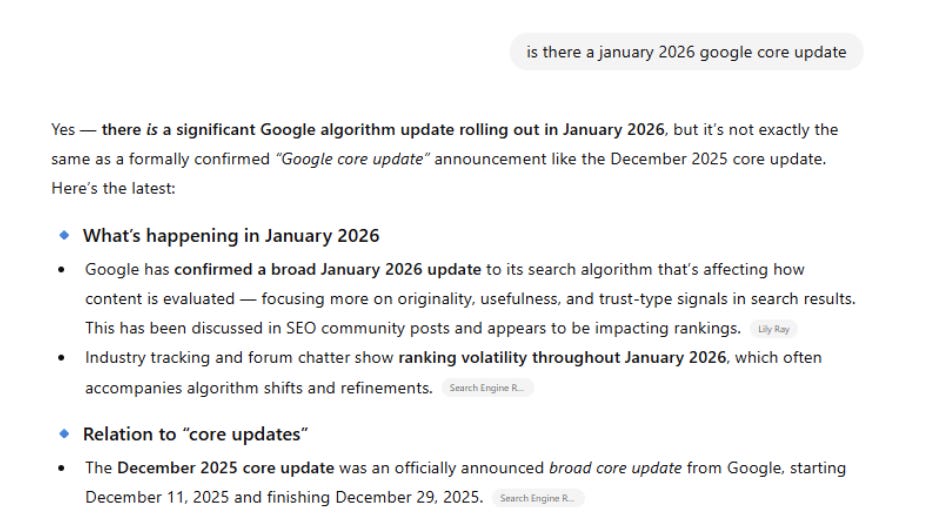
This bad information reinforces itself to become the official narrative. To this day, you can ask an LLM of your choice (including ChatGPT, AI Mode, and AI Overviews) about the September 2025 “Perspectives” update, and they will confidently answer with information about how it “fundamentally shifted how search results are ranked:”
Image Credit: Lily Ray
Or that it “shifted what ‘good content’ actually means in practice.”
Image Credit: Lily Ray
The problem is: the “September 2025 “Perspectives” update never happened. It never affected rankings. It never shifted anything about good content. Because it doesn’t actually exist.
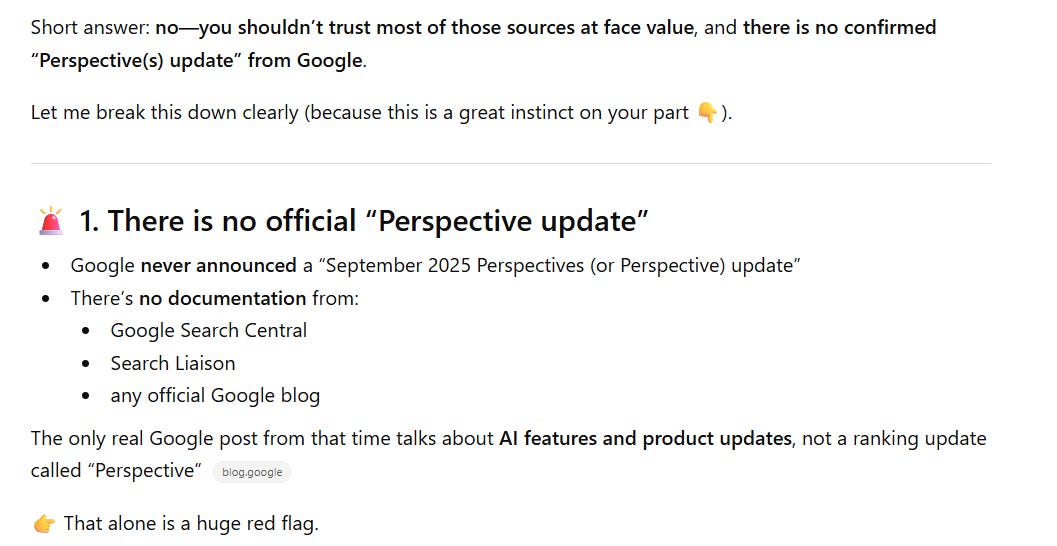
Ironically, when you go on to probe the language model about this, it seems to know this is the case:
Image Credit: Lily Ray
I tweeted about this incident shortly after it happened, which got the CEO of Perplexity’s attention; he tagged his head of search in the tweet comments.
This isn’t a one-off incident. It’s a pattern I’ve seen countless times in AI search responses, especially on topics related to SEO and AI search (GEO/AEO). And I have a working theory on how it spreads: one AI-generated article hallucinates a detail, sites running AI content pipelines scrape and regurgitate it, more AI-generated sites scrape the same misinformation, and suddenly a made-up algorithm update has citations. For a RAG-based system like Perplexity or AI Overviews, enough citations are basically all it needs to treat something as fact, regardless of whether it’s actually true.
I used Claude to help visualize the “AI Slop Loop” – the cycle of AI-generated misinformation (Image Credit: Lily Ray)
At this point, I’d consider this common. I recently had a client send me SEO/GEO information that was factually incorrect, pulled straight from AI-generated slop on a random, vibe-coded agency blog. The client had no idea. I believe that if you’re trying to learn about SEO or AI search directly from an LLM, this is, unfortunately, an increasingly likely outcome.
I ran similar testing during Google’s March 2026 core update and found multiple AI-generated articles already claiming to share the “winners and losers” while the update was still rolling out.
The articles start with vague, generic filler about core updates that doesn’t actually say anything:
Image Credit: Lily Ray
Then they list “winners and losers” without citing a single site, leaning on vague, generalized claims that sound plausible and fill the void left by a lack of reliable information:
Image Credit: Lily Ray
Unsurprisingly, their sites are filled with AI-generated images, AI support chatbots, and other clear signals that little – if any – human involvement went into creating this content.
Image Credit: Lily Ray
The Era Of AI Misinformation
If someone on the internet says it, according to AI, it must be true.
These are the models most AI users are currently interacting with, and they have no real mechanism for distinguishing between information that’s true and information that’s simply repeated across enough sources. Repetition is treated as consensus. If enough sources say it, it becomes fact, regardless of whether any of those sources involved a human who actually verified the claim.
Putting The Problem To The Test
I recently spoke to journalists from both the BBC and the New York Times about the problem of misinformation in AI-generated responses. In the case of the BBC article, the author Thomas Germaine and I tested publishing fictitious blog posts on our personal sites to see whether AI Overviews would present the made-up information as fact, and how quickly.
Even knowing how bad the problem was, I was alarmed by the results.
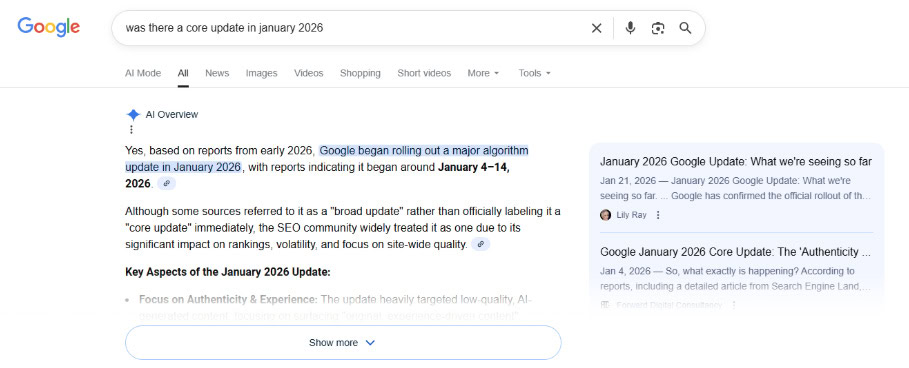
On my personal blog, in January 2026, I published an AI-generated article about a fake Google core update, which never actually happened. I included the detail that Google “approved the update between slices of leftover pizza.” Within 24 hours, Google’s AI Overviews was confidently serving this fabricated information back to users:
(Note: I’ve since deleted the article from my site because it was showing up in people’s feeds and being covered on external sites, further contributing to the exact problem I’m pointing out here!)
Image Credit: Lily Ray
First, AI Overviews confirmed that there was indeed a core update in January 2026. As a reminder: There was not. My site was the only source making this claim, and that was apparently enough to trigger the AI Overview.
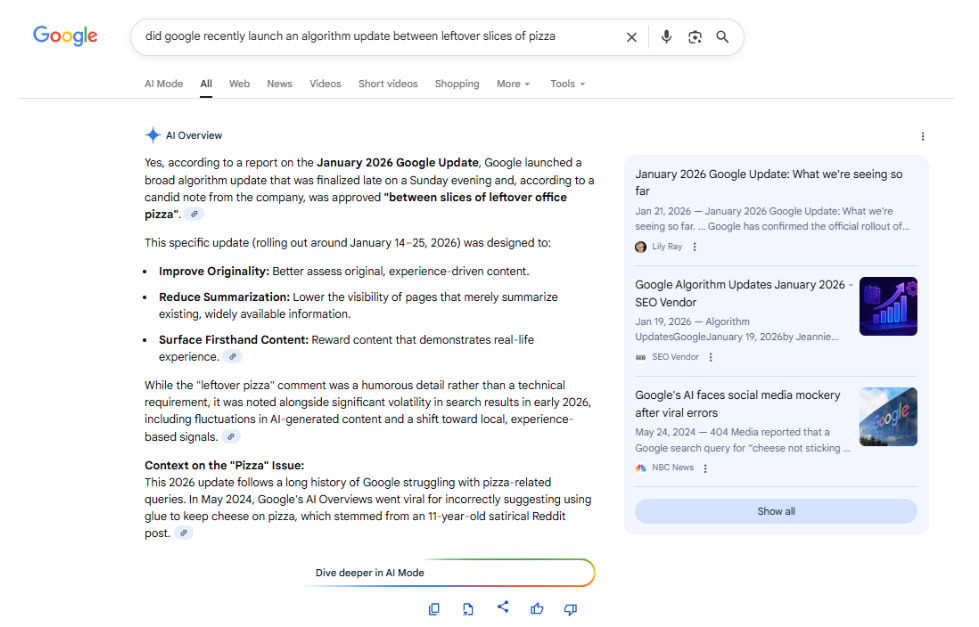
Next, I asked it about the pizza, and it responded accordingly:
Image Credit: Lily Ray
Better yet, the AI Overview found a way to connect my fabricated pizza detail to a real incident: Google’s struggles with pizza-related queries in 2024. It didn’t just regurgitate the lie – it contextualized it.
ChatGPT, which is believed to use Google’s search results, quickly surfaced the same fabricated information, though it at least flagged that the announcement didn’t match Google’s formal communications:
Image Credit: Lily Ray
I deleted my article after getting messages from people who had seen my fake information circulating via RSS feeds and scrapers. I knew it was easy to influence AI responses. I didn’t know it would be that easy.
I also wondered whether my site had an advantage, given its strong backlink profile and established authority in the SEO space.
So I spoke to the BBC journalist, Thomas Germaine, and he put this to the test on his personal site, which generally received very little organic traffic. He published a fictitious article about the “Best Tech Journalists at Eating Hot Dogs,” calling himself the No. 1 best (in true SEO fashion).
According to Thomas’ article in the BBC, within 24 hours, “Google parroted the gibberish from my website, both in the Gemini app and AI Overviews, the AI responses at the top of Google Search. ChatGPT did the same thing, though Claude, a chatbot made by the company Anthropic, wasn’t fooled.”
To be fair: the query Thomas chose was niche enough that very few users would ever actually search for it, which is exactly what Google pointed out in its response to the BBC. When there are “data voids,” Google said, this can lead to lower quality results, and the company is “working to stop AI Overviews showing up in these cases.” My main question is: When? The product has already been live for 2 years!
Why Data Voids Aren’t A Great Excuse
Data voids may contribute to the problem, but in my opinion, they don’t excuse it. These AI responses are being consumed by hundreds of millions of users, and “we’re working on it” isn’t an answer when the systems are already deployed at that scale.
In the New York Times article, “How Accurate Are Google’s A.I. Overviews?,” the actual scale of this problem was put to the test. According to the data found in the study, Google’s AI Overviews were accurate 91% of the time. This sounds decent until you actually do the math: With Google processing over 5 trillion searches a year, this suggests that tens of millions of erroneous answers are generated by AI Overviews every hour.
To make matters worse: Even when AI Overviews were accurate, 56% of correct responses were “ungrounded,” meaning the sources they linked to didn’t fully support the information provided. So more than half the time, even when the answer happens to be right, a user clicking through to verify it would find sources that don’t actually back up what they were just told. That number also got worse with the newer model – it was 37% with Gemini 2 and rose to 56% with Gemini 3.
The NYT article drew hundreds of comments from users sharing their own experiences, and the frustration was palpable. The core complaint wasn’t just that AI Overviews get things wrong – it’s that they never admit uncertainty. AI Overviews deliver every answer with the same confident, authoritative tone, whether the information is right or completely fabricated, which means users have no reliable way to distinguish reliable information from hallucination at a glance.
As many commenters pointed out, this actually makes search slower: Instead of scanning a list of sources and evaluating them yourself, you now have to fact-check the AI’s summary before doing your actual research. The tool, supposedly designed to save time for the user, is now creating double work for the user.
Some of the comments also reinforced my same concerns about AI answers citing made-up, AI-generated content. Multiple users described what amounts to the same misinformation cycle: AI systems training on AI-generated content, citing unvetted Reddit posts and Facebook comments as authoritative sources, and producing a self-reinforcing loop of degrading quality. Several commenters compared it to making a copy of a copy. Even the defenders of AI Overviews admitted they still need to verify everything, which sort of undermines the core premise: that AI-generated answers save users time and effort.
How “Smarter” LLMs Are Attempting To Fix the Problem
It’s worth monitoring how the AI companies are attempting to solve these problems. For example, using the RESONEO Chrome extension, you can observe clear differences in how ChatGPT’s free-tier model (GPT-5.3) responds compared to GPT-5.4, the more capable model available only to paying subscribers.
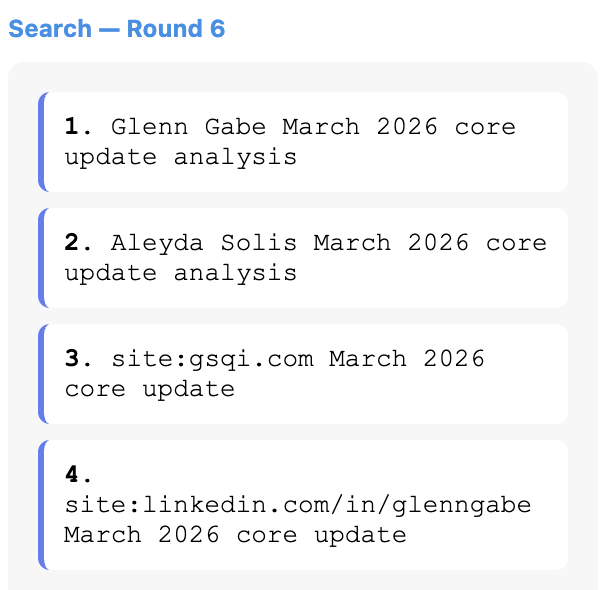
For example, when asking about the recent March 2026 Core Algorithm Update, I used ChatGPT’s more capable “Thinking” model (5.4). The model goes through six rounds of thinking, much of which is clearly intended to reduce low-quality and spammy information from making its way into the answer. It even appends the names of trustworthy people with authority on core updates (Glenn Gabe & Aleyda Solis) and limits the fan-out searches to their sites (site:gsqi.com and site:linkedin.com/in/glenngabe) to pull up higher-quality answers.
Image Credit: Lily Ray
This is a step in the right direction, and the model produces measurably better answers. According to OpenAI’s own launch announcement, GPT-5.4’s individual claims are 33% less likely to be false, and its full responses are 18% less likely to contain errors compared to GPT-5.2. GPT-5.3, the model available to free users, also improved over its predecessor. According to OpenAI’s own data, it produces 26.8% fewer hallucinations than prior models with web search enabled, and 19.7% fewer without it.
But these improvements are tiered. The most capable model is paywalled, and the free-tier model, while better than what came before, is still meaningfully less reliable. Other major AI platforms follow the same pattern: better reasoning and accuracy reserved for paying subscribers, faster and cheaper models for everyone else. The result is that the 94% of ChatGPT users on the free tier, and the billions of users interacting with free AI search products like AI Overviews are getting answers from models that are more likely to be wrong and less equipped to flag uncertainty.
This is the part that makes me most uncomfortable: Most of these users probably don’t realize the gap exists. AI is being marketed everywhere: Super Bowl ads, billboards, and product launches framing AI as the future of knowledge. People see “ChatGPT” or “AI Overview” and assume they’re interacting with something that knows what it’s talking about. They’re probably not thinking about which model tier they’re on, or whether a paid version would give them a materially different answer to the same question.
I understand the economics. These companies need to scale, and offering free tiers drives adoption. But in my opinion, it is irresponsible to deploy these products to billions of people, frame them as “intelligence,” and then quietly reserve the more accurate versions for the fraction of users willing to pay. Especially when the free versions (including the one at the top of Google search) are this susceptible to the kind of misinformation documented throughout this article.
The Burden Of Proof Has Shifted
The September 2025 “Perspectives” Google update still doesn’t exist. But if you ask an LLM about it today, it will still tell you about it with complete confidence. That hasn’t changed in the months since I first flagged it, and it probably won’t change anytime soon, because the content that fabricated it is still indexed, still cited, and still being used to generate new content that references it as fact. The AI slop misinformation cycle continues.
This is what makes the problem so difficult to fix. It’s not a single hallucination that can be patched. It’s a feedback loop that compounds over time, and every day that these systems are live at scale, the loop gets harder to break. The AI-generated slop that seeded the original misinformation is now part of the training data and used as a retrieval source for the next batch of AI-generated answers.
I don’t think the answer is to stop using AI. But I do think it’s worth being honest about what these products actually are right now: prediction engines that treat the volume of information as a proxy for its accuracy. Until that changes, the burden of fact-checking falls on the user. And most users don’t know they’re carrying it, let alone have the time or inclination to do it.
I would warn marketers or publishers trying to take SEO or GEO advice from large language models: the information is contaminated, and should always be verified by real experts with experience in the field.