Don’t Be Fooled by Data: 4 Data Analysis Pitfalls & How to Avoid Them
Digital marketing is a proudly data-driven field. Yet, as SEOs especially, we often have such incomplete or questionable data to work with, that we end up jumping to the wrong conclusions in our attempts to substantiate our arguments or quantify our issues and opportunities.
In this post, I’m going to outline 4 data analysis pitfalls that are endemic in our industry, and how to avoid them.
1. Jumping to conclusions
Earlier this year, I conducted a ranking factor study around brand awareness, and I posted this caveat:
“…the fact that Domain Authority (or branded search volume, or anything else) is positively correlated with rankings could indicate that any or all of the following is likely:
- Links cause sites to rank well
- Ranking well causes sites to get links
- Some third factor (e.g. reputation or age of site) causes sites to get both links and rankings”
~ Me
However, I want to go into this in a bit more depth and give you a framework for analyzing these yourself, because it still comes up a lot. Take, for example, this recent study by Stone Temple, which you may have seen in the Moz Top 10 or Rand’s tweets, or this excellent article discussing SEMRush’s recent direct traffic findings. To be absolutely clear, I’m not criticizing either of the studies, but I do want to draw attention to how we might interpret them.
Firstly, we do tend to suffer a little confirmation bias — we’re all too eager to call out the cliché “correlation vs. causation” distinction when we see successful sites that are keyword-stuffed, but all too approving when we see studies doing the same with something we think is or was effective, like links.
Secondly, we fail to critically analyze the potential mechanisms. The options aren’t just causation or coincidence.
Before you jump to a conclusion based on a correlation, you’re obliged to consider various possibilities:
- Complete coincidence
- Reverse causation
- Joint causation
- Linearity
- Broad applicability
If those don’t make any sense, then that’s fair enough — they’re jargon. Let’s go through an example:
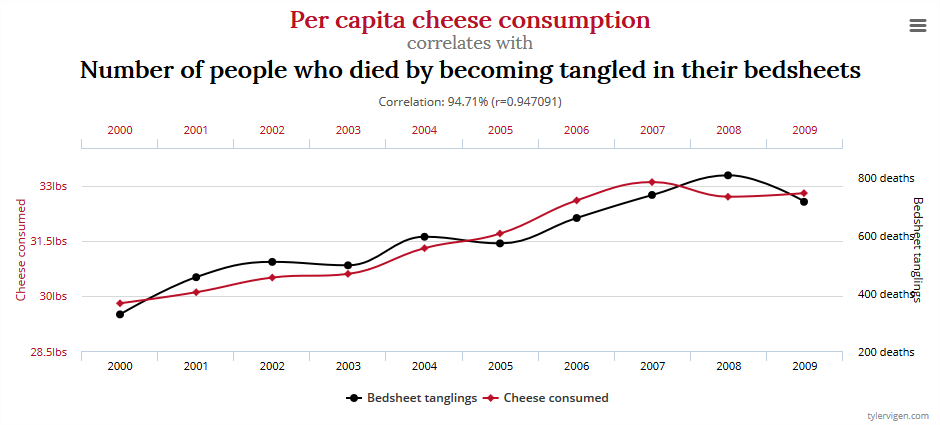
Before I warn you not to eat cheese because you may die in your bedsheets, I’m obliged to check that it isn’t any of the following:
- Complete coincidence – Is it possible that so many datasets were compared, that some were bound to be similar? Why, that’s exactly what Tyler Vigen did! Yes, this is possible.
- Reverse causation – Is it possible that we have this the wrong way around? For example, perhaps your relatives, in mourning for your bedsheet-related death, eat cheese in large quantities to comfort themselves? This seems pretty unlikely, so let’s give it a pass. No, this is very unlikely.
- Joint causation – Is it possible that some third factor is behind both of these? Maybe increasing affluence makes you healthier (so you don’t die of things like malnutrition), and also causes you to eat more cheese? This seems very plausible. Yes, this is possible.
- Linearity – Are we comparing two linear trends? A linear trend is a steady rate of growth or decline. Any two statistics which are both roughly linear over time will be very well correlated. In the graph above, both our statistics are trending linearly upwards. If the graph was drawn with different scales, they might look completely unrelated, like this, but because they both have a steady rate, they’d still be very well correlated. Yes, this looks likely.
- Broad applicability – Is it possible that this relationship only exists in certain niche scenarios, or, at least, not in my niche scenario? Perhaps, for example, cheese does this to some people, and that’s been enough to create this correlation, because there are so few bedsheet-tangling fatalities otherwise? Yes, this seems possible.
So we have 4 “Yes” answers and one “No” answer from those 5 checks.
If your example doesn’t get 5 “No” answers from those 5 checks, it’s a fail, and you don’t get to say that the study has established either a ranking factor or a fatal side effect of cheese consumption.
A similar process should apply to case studies, which are another form of correlation — the correlation between you making a change, and something good (or bad!) happening. For example, ask:
- Have I ruled out other factors (e.g. external demand, seasonality, competitors making mistakes)?
- Did I increase traffic by doing the thing I tried to do, or did I accidentally improve some other factor at the same time?
- Did this work because of the unique circumstance of the particular client/project?
This is particularly challenging for SEOs, because we rarely have data of this quality, but I’d suggest an additional pair of questions to help you navigate this minefield:
- If I were Google, would I do this?
- If I were Google, could I do this?
Direct traffic as a ranking factor passes the “could” test, but only barely — Google could use data from Chrome, Android, or ISPs, but it’d be sketchy. It doesn’t really pass the “would” test, though — it’d be far easier for Google to use branded search traffic, which would answer the same questions you might try to answer by comparing direct traffic levels (e.g. how popular is this website?).
2. Missing the context
If I told you that my traffic was up 20% week on week today, what would you say? Congratulations?
What if it was up 20% this time last year?

What if I told you it had been up 20% year on year, up until recently?

It’s funny how a little context can completely change this. This is another problem with case studies and their evil inverted twin, traffic drop analyses.
If we really want to understand whether to be surprised at something, positively or negatively, we need to compare it to our expectations, and then figure out what deviation from our expectations is “normal.” If this is starting to sound like statistics, that’s because it is statistics — indeed, I wrote about a statistical approach to measuring change way back in 2015.
If you want to be lazy, though, a good rule of thumb is to zoom out, and add in those previous years. And if someone shows you data that is suspiciously zoomed in, you might want to take it with a pinch of salt.
3. Trusting our tools
Would you make a multi-million dollar business decision based on a number that your competitor could manipulate at will? Well, chances are you do, and the number can be found in Google Analytics. I’ve covered this extensively in other places, but there are some major problems with most analytics platforms around:
- How easy they are to manipulate externally
- How arbitrarily they group hits into sessions
- How vulnerable they are to ad blockers
- How they perform under sampling, and how obvious they make this
For example, did you know that the Google Analytics API v3 can heavily sample data whilst telling you that the data is unsampled, above a certain amount of traffic (~500,000 within date range)? Neither did I, until we ran into it whilst building Distilled ODN.
Similar problems exist with many “Search Analytics” tools. My colleague Sam Nemzer has written a bunch about this — did you know that most rank tracking platforms report completely different rankings? Or how about the fact that the keywords grouped by Google (and thus tools like SEMRush and STAT, too) are not equivalent, and don’t necessarily have the volumes quoted?
It’s important to understand the strengths and weaknesses of tools that we use, so that we can at least know when they’re directionally accurate (as in, their insights guide you in the right direction), even if not perfectly accurate. All I can really recommend here is that skilling up in SEO (or any other digital channel) necessarily means understanding the mechanics behind your measurement platforms — which is why all new starts at Distilled end up learning how to do analytics audits.
One of the most common solutions to the root problem is combining multiple data sources, but…
4. Combining data sources
There are numerous platforms out there that will “defeat (not provided)” by bringing together data from two or more of:
- Analytics
- Search Console
- AdWords
- Rank tracking
The problems here are that, firstly, these platforms do not have equivalent definitions, and secondly, ironically, (not provided) tends to break them.
Let’s deal with definitions first, with an example — let’s look at a landing page with a channel:
- In Search Console, these are reported as clicks, and can be vulnerable to heavy, invisible sampling when multiple dimensions (e.g. keyword and page) or filters are combined.
- In Google Analytics, these are reported using last non-direct click, meaning that your organic traffic includes a bunch of direct sessions, time-outs that resumed mid-session, etc. That’s without getting into dark traffic, ad blockers, etc.
- In AdWords, most reporting uses last AdWords click, and conversions may be defined differently. In addition, keyword volumes are bundled, as referenced above.
- Rank tracking is location specific, and inconsistent, as referenced above.
Fine, though — it may not be precise, but you can at least get to some directionally useful data given these limitations. However, about that “(not provided)”…
Most of your landing pages get traffic from more than one keyword. It’s very likely that some of these keywords convert better than others, particularly if they are branded, meaning that even the most thorough click-through rate model isn’t going to help you. So how do you know which keywords are valuable?
The best answer is to generalize from AdWords data for those keywords, but it’s very unlikely that you have analytics data for all those combinations of keyword and landing page. Essentially, the tools that report on this make the very bold assumption that a given page converts identically for all keywords. Some are more transparent about this than others.
Again, this isn’t to say that those tools aren’t valuable — they just need to be understood carefully. The only way you could reliably fill in these blanks created by “not provided” would be to spend a ton on paid search to get decent volume, conversion rate, and bounce rate estimates for all your keywords, and even then, you’ve not fixed the inconsistent definitions issues.
Bonus peeve: Average rank
I still see this way too often. Three questions:
- Do you care more about losing rankings for ten very low volume queries (10 searches a month or less) than for one high volume query (millions plus)? If the answer isn’t “yes, I absolutely care more about the ten low-volume queries”, then this metric isn’t for you, and you should consider a visibility metric based on click through rate estimates.
- When you start ranking at 100 for a keyword you didn’t rank for before, does this make you unhappy? If the answer isn’t “yes, I hate ranking for new keywords,” then this metric isn’t for you — because that will lower your average rank. You could of course treat all non-ranking keywords as position 100, as some tools allow, but is a drop of 2 average rank positions really the best way to express that 1/50 of your landing pages have been de-indexed? Again, use a visibility metric, please.
- Do you like comparing your performance with your competitors? If the answer isn’t “no, of course not,” then this metric isn’t for you — your competitors may have more or fewer branded keywords or long-tail rankings, and these will skew the comparison. Again, use a visibility metric.
Conclusion
Hopefully, you’ve found this useful. To summarize the main takeaways:
- Critically analyse correlations & case studies by seeing if you can explain them as coincidences, as reverse causation, as joint causation, through reference to a third mutually relevant factor, or through niche applicability.
- Don’t look at changes in traffic without looking at the context — what would you have forecasted for this period, and with what margin of error?
- Remember that the tools we use have limitations, and do your research on how that impacts the numbers they show. “How has this number been produced?” is an important component in “What does this number mean?”
- If you end up combining data from multiple tools, remember to work out the relationship between them — treat this information as directional rather than precise.
Let me know what data analysis fallacies bug you, in the comments below.