Machine learning can offer new tools, fresh insights for the humanities

{kind=link}
Truly revolutionary political transformations are naturally of great interest to historians, and the French Revolution at the end of the 18th century is widely regarded as one of the most influential, serving as a model for building other European democracies. A paper published last summer in the Proceedings of the National Academy of Sciences offers new insight into how the members of the first National Constituent Assembly hammered out the details of this new type of governance.
Specifically, rhetorical innovations by key influential figures (like Robespierre) played a critical role in persuading others to accept what were, at the time, audacious principles of governance, according to co-author Simon DeDeo, a former physicist who now applies mathematical techniques to the study of historical and current cultural phenomena. And the cutting-edge machine learning methods he developed to reach that conclusion are now being employed by other scholars of history and literature.
It’s part of the rise of so-called “digital humanities.” As more and more archives are digitized, scholars are applying various analytical tools to those rich datasets, such as Google N-gram, Bookworm, and WordNet. Tagged and searchable archives mean connecting the dots between different records is much easier. Close reading of selected sources—the traditional method of historians—gives a deep but narrow view. Quantitative computational analysis has the potential to combine that kind of close reading with a broader, more generalized bird’s-eye approach that might reveal hidden patterns or trends that otherwise might have escaped notice.
“One thing this so-called ‘distant reading’ can do is help us identify new questions.”
“It’s like any other tool and can be used for good or bad; it depends on how you use it,” said co-author Rebecca Spang, a historian at Indiana University Bloomington. “Crucially, one thing this so-called ‘distant reading’ can do is help us identify new questions and things we could not have recognized as questions reading in the slow, close way that human individuals read.” Small wonder that an increasing number of historians is applying these kinds of digital tools to the growing number of digitized archives. Stanford University historian Caroline Winterer, for instance, has used the digitized letters of Benjamin Franklin to map his “social network,” revealing a picture of his rise to global prominence that was previously hidden.
The French Revolution study builds on one of DeDeo’s earlier collaborations in 2014 with historian Tim Hitchcock of the University of Sussex, analyzing the digitized archives of London’s Old Bailey courthouse over a period of about 200 years. The goal was to pinpoint how the way different crimes were spoken about at trial changed over time. They split all the trials into two categories—violent crimes like murder or assault, and non-violent crimes like pickpocketing or fraud—and looked at the words used in the transcripts for each trial.
A word picked at random from the Old Bailey archive receives a score based on how useful it is in predicting whether it comes from an account of a violent or a non-violent trial. In this way, DeDeo and Hitchcock’s analysis showed the gradual criminalization of violence over those two centuries. This was not necessarily evidence that our nature has become less violent, rather, society changed its definition of what would be considered a violent criminal offense.

For another study, DeDeo trawled the digital archives of US congressional debates from the 1960s to the present to identify buzzwords that might peg the political leanings of the various speakers. He was able to track the development of political parties (and the origins of their current polarization) via subtle shifts in rhetoric. In the 1960s data, it’s not possible to determine political affiliation solely on someone’s vocabulary. That has changed dramatically, and now each party has very distinct vocabulary terms that serve as political indicators.
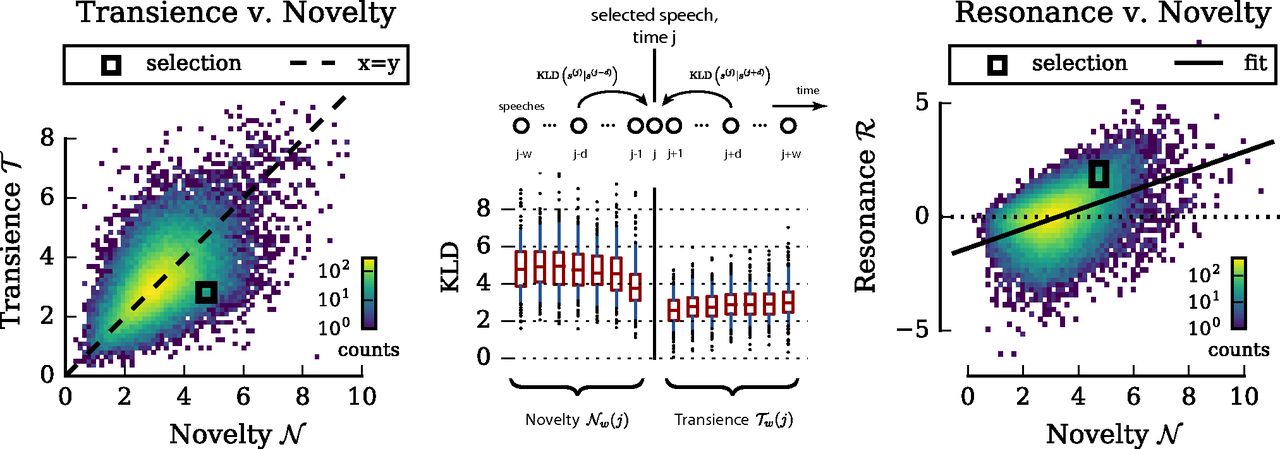
For his analysis of the French National Constituent Assembly dataset with Spang, DeDeo developed a similar machine-learning technique to comb through transcripts of some 40,000 speeches made during that body’s deliberations, as legislators hashed out what the new laws and institutions would be for post-Revolutionary France. The researchers determined how “novel” the speech patterns were, in terms of using new turns of phrase to communicate new ideas, as well as noting whether the speech was given in a public forum or behind closed doors in committee.
DeDeo and Spang discovered that assembly members who used innovative language to propose their ideas (say, liberty, equality, fraternity), were much more successful at swaying the other members to adopt their ideas. Their ideas “persisted,” as it were, which wasn’t true for every new idea that was proposed. That new revolutionary vocabulary developed over time rather than springing into being fully formed in the summer of 1789.
The idea is fairly simple at its core, and that’s what makes DeDeo’s latest analytic tool so broadly applicable to other areas of the humanities. “It’s a very useful model for thinking about how culture works, because we’re very interested in the influencers—who the movers and shakers are,” said Andrew Piper, a professor at McGill University. He is also founder of the Journal of Cultural Analytics and heads up an interdisciplinary initiative, NovelTM: Text Mining the Novel, with the goal of producing “the first large-scale cross-cultural study of the novel according to quantitative methods.”
“People have made very grandiose claims about the novel with a very, very small dataset.”
“People have made very grandiose claims about the novel with a very, very small dataset,” Piper said. “It has real repercussions for the credibility of our field. By taking into account large sets of documents, you can have more confidence when you’re [making such claims] that this is something that is accurate, reliable, and reproducible.” He is adapting DeDeo’s approach to conduct more of a meta-analysis of literary studies. Piper has compiled some 60,000 articles in the field dating back to 1950 with an aim toward identifying large-scale ideological shifts.
For instance, many new ideas and related jargon entered the field in the 1970s, when gender studies became a hot academic ticket—one of the most significant shifts in the last 50 years, according to Piper. A similar shift occurred in the late 1980s with race and post-colonialism. “People have talked anecdotally about these big shifts in the field, but [quantitative analysis] gives you very precise ways of measuring how severe they are,” said Piper. Over the last decade, however, the field has experienced a period of stagnation, as past upheavals have become fully incorporated and normalized.
Ted Underwood, a literature professor at the University of Illinois, is using DeDeo’s tools to analyze the text of 40,000 novels spanning two centuries. Underwood originally specialized in British Romantic literature, focusing on individual authors and books. But he now focuses on longer time scales, “because that’s the scale where I think we know the least,” he said.
DeDeo’s method is particularly suited for that kind of analysis. They met at one of Piper’s McGill workshops, where DeDeo spoke on using text mining to study the novel. “I’m on record as saying the talk made me want to run immediately out of the room and try and apply it to lit history to see what we can learn,” said Underwood.
Underwood’s approach involves topic modeling to identify key organizing topics in his digitized dataset—a term that describes the ways in which people were writing, such as greater use of profanity or vulgar language. By looking at the distribution of topics represented in each novel and comparing it to novels 20 or 40 years in the future, it’s possible to identify influential works that were just a bit ahead of their time, like Uncle Tom’s Cabin by Harriet Beecher Stowe.
“We’re doing a longer timeline, but it’s basically the same idea [as DeDeo’s],” he said. “Can we think about literary change by looking at books, how much they’re like the past, how much they’re like the future, and looking at the ratio between those to learn something new.”
There is naturally a certain amount of pushback against the notion that the quantitative methods of science could yield insight into the humanities, where the emphasis has long been on individual close reading of texts by people with narrow expertise in their chosen field. There’s a sense that machine learning is meant to replace that kind of in-depth scholarship. But the best such studies (DeDeo’s included) always involve a so-called “domain expert” to ensure there is no misinterpretation of the data. Quantitative analysis can identify a pattern; it takes a domain expert to fully understand what that means contextually.
“If you work with data, you know this,” said Piper. “I think people who haven’t really accepted the interpretive power you get when you work at a larger scale, only work at that traditional, close, analytical level.”
“It seems like it might be a peanut butter and pizza kind of combination,” said Ben Orlin, math teacher and author of Math with Bad Drawings, who is not involved in any of the aforementioned studies. While history or literature provide a rich dataset, “maybe it’s not such a good idea to shred it up and treat it as this very disconnected set of words and frequencies.”
But he agrees that involving domain experts can preserve the respective strengths of each discipline in a mutually beneficial way. “Digital humanities gives us this wonderful set of techniques that people can use to ask questions of literature,” said Orlin. “But you definitely need people who are experts to frame which questions are gonna be interesting.”
DOI: PNAS, 2018. 10.1073/pnas.1717729115 (About DOIs).
https://arstechnica.com/?p=1434415