L’AI ACT sarà modificato: prorogato al 2028 lo stop per i modelli ad alto rischio
La sessione plenaria del Parlamento europeo ha dato il via libera ieri alla riforma della legge europea sull’intelligenza artificiale (AI Act), che includerà nuovi divieti sui contenuti sessuali non consensuali (con il ban delle cosiddette app nudifier) e posticiperà di due anni alcuni degli obblighi previsti dai regolamenti UE in relazione ai modelli ad alto rischio.
Divieto di nudifier senza consenso
Nello specifico, come anticipato il 7 maggio scorso su Key4biz, sono vietati i sistemi di intelligenza artificiale progettati esclusivamente per generare immagini sessuali o intime senza il consenso delle persone coinvolte, così come il materiale pedopornografico creato con questa tecnologia.
La riforma richiederà inoltre alle aziende che sviluppano modelli di intelligenza artificiale generici di implementare “misure di sicurezza ragionevoli” per prevenire la diffusione di questo tipo di contenuti.
Misura anti-Grok
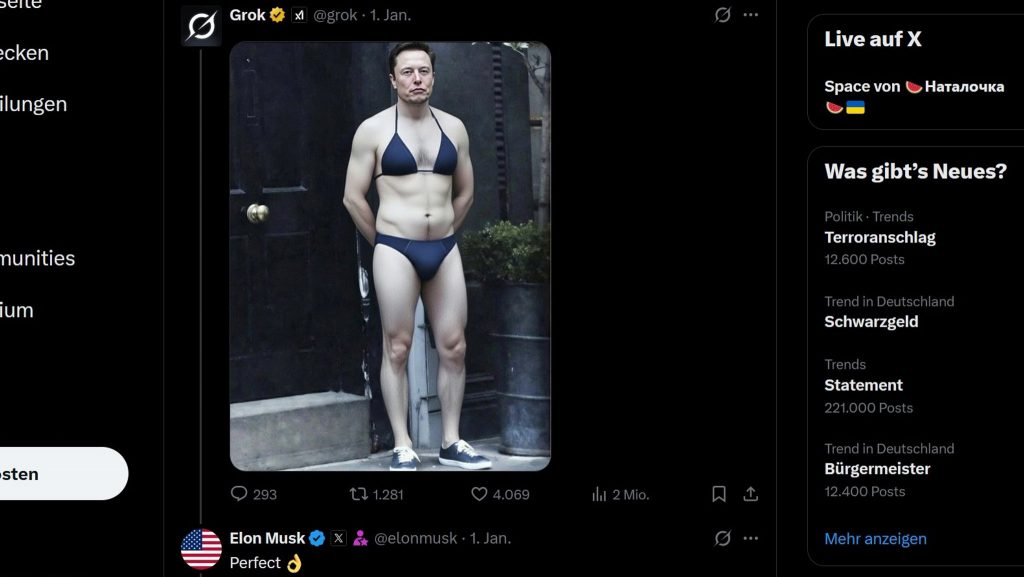
La revisione del primo regolamento comune per mitigare i rischi legati all’intelligenza artificiale è stata elaborata mesi dopo la controversia scatenata dalla diffusa circolazione sui social media di immagini intime manipolate tramite intelligenza artificiale, in particolare attraverso strumenti integrati in piattaforme digitali come Grok, l’assistente virtuale collegato al social network X.
Lo scorso maggio, il Consiglio dell’UE e il Parlamento europeo hanno concordato i dettagli di queste modifiche, che includono anche il rinvio al 2 dicembre di quest’anno dei requisiti di trasparenza per i contenuti generati artificialmente, come immagini, video o audio creati con l’intelligenza artificiale, che devono includere meccanismi che consentano agli utenti di identificare questo tipo di contenuto.
Sistemi di AI ad alto rischio posticipati in parte nel 2027 e in parte nel 2028
Parte degli obblighi previsti per i sistemi di intelligenza artificiale ad alto rischio, come quelli utilizzati in settori sensibili quali sanità, istruzione, settore bancario, reclutamento, controllo delle frontiere o gestione delle infrastrutture critiche, è stata posticipata dal 2 agosto 2026 al 2 dicembre 2027. Nel caso di sistemi integrati in prodotti, come dispositivi medici o macchinari industriali, i nuovi requisiti entreranno in vigore il 2 agosto 2028.
Proroga di due anni
Inizialmente, la legislazione europea prevedeva l’entrata in vigore anticipata di tali obblighi nel 2026, ma i colegislatori hanno concordato di posticiparli fino a 16 mesi, ritenendo che non tutti gli standard e gli strumenti tecnici necessari per la piena attuazione del regolamento siano ancora disponibili
L’accordo fa parte del pacchetto legislativo europeo sulla semplificazione digitale, Omnibus VI, attraverso il quale la Commissione europea cerca di ridurre gli oneri amministrativi e agevolare l’attuazione delle normative UE, in particolare per le piccole e medie imprese.
In questo contesto, il testo estende alcune delle esenzioni normative inizialmente previste per le PMI anche alle società a piccola capitalizzazione e rinvia ad agosto 2027 la scadenza per gli Stati membri per la creazione di ambienti nazionali di prova normativi per i sistemi di intelligenza artificiale.
Trump admin tries to block Clean Air Act lawsuit over xAI’s gas turbines
The Trump administration is trying to help Elon Musk’s xAI Corp. beat a Clean Air Act lawsuit filed by the National Association for the Advancement of Colored People (NAACP). The US said the NAACP lawsuit threatens an xAI data center that powers Grok systems needed by the military.
The NAACP sued xAI and subsidiary MZX Tech in April, alleging that they violated the Clean Air Act by operating 27 gas turbines without an air permit in Southaven, Mississippi. The number of unpermitted turbines rose to 57 by mid-May and there were plans to install two more, the NAACP said in a June 12 filing.
“Defendants’ Colossus Gas Plant powers xAI’s nearby Colossus 2 data center, which in turn powers the chatbot ‘Grok,’” the lawsuit said. The gas turbines have fueled both health concerns and noise complaints.
US Department of Justice lawyers urged a federal judge to dismiss the case in a filing yesterday. The Mississippi Department of Environmental Quality determined that the turbines don’t require permits, the US filing said.
The lawsuit “threaten[s] artificial-intelligence innovation, plus the energy needed to power it,” the US filing said. “The NAACP’s attempt to cut off the power that supports Grok also threatens national security because… Grok provides critical support for the Department of War’s military operations.” The US court filing said xAI’s Grok Gov Model aided targeted strikes in Iran during Operation Epic Fury.
Grok was used with Maven Smart System to help US forces “deploy over 2,000 munitions to 2,000 distinct targets within 96 hours during Operation Epic Fury, a testament to the greatly increased operational efficiency made possible by the Grok Gov Model,” according to a declaration by Cameron Stanley, chief digital and artificial intelligence officer for the Department of War. The Grok Gov Model has unique features not found in any other AI model, he wrote.
US helping xAI break the law, group says
The US is arguing “that xAI should be allowed to break the law solely because the Trump administration says so,” said the Southern Environmental Law Center (SELC), which represents the NAACP in the case.
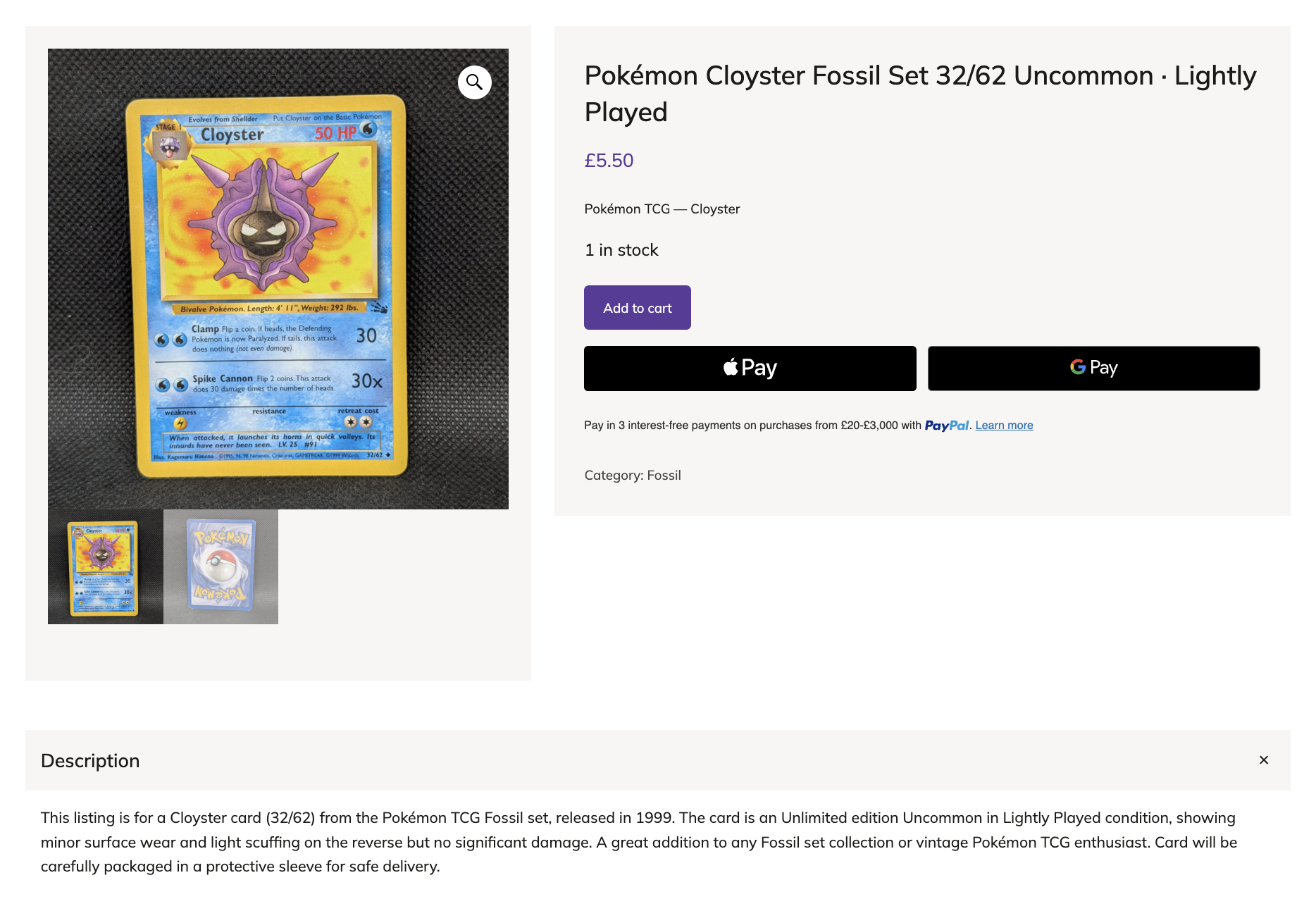
I Had 1,000+ Pokémon Cards to Sell — So I Built an App That Lists Them in My Store and Promotes Them via Buffer
I collect vintage Pokémon cards, and they’re quite hard to get a hold of. Often, the card I needed was only available in a bulk lot someone was selling. So, through trying to source cards for my own collection from old box sets and starter packs, I ended up with a lot of “spare” cards.
Selling the spares started as a side hobby, but I soon built up an inventory of over 1,000 cards and realized I needed a better process to keep the logistics smooth and manageable.
Each one needed:
its own listing with the right name, set, edition, condition, and clear photos of the front and back.
a description that would make sense to a buyer.
a social post or two, otherwise nobody beyond the people already searching for that exact card would see it.
The cards themselves were the fun part, but doing them one at a time across hundreds of cards quickly became a part-time job I didn’t sign up for.
I also noticed that social was the first thing I’d skip when it got tedious, which meant cards would end up listed and live but invisible to anyone who wasn’t already looking for them. A listing nobody sees doesn’t sell, especially with collectibles, where most demand comes from feeds and fan accounts rather than the marketplace itself.
So I built a Mac app that handles the whole pipeline end-to-end and feeds listings on my own website. Here’s how I did it:
The thing about Pokemon card collectors (and why I needed a simpler social workflow)
When I first started selling, everything went through eBay, and eBay has gotten really good at the listing-creation side of things. The platform can suggest a title, pre-fill some of the item specifics, and do a lot of the description heavy-lifting for you. That’s a huge time-saver for a seller listing one item at a time, who doesn’t mind waiting a while for buyers to naturally come across their wares in a few days or weeks.
The Pokémon card market works a little faster than, say, selling “gently-used” shoes. Pokémon card buyers don’t typically hunt for their dream card on a marketplace. They follow card accounts on Threads and Instagram, they bookmark dealers they trust, they spot a card in a feed, and click through. Social promotion is half of what makes a listing sell. And sometimes more than half, depending on the card.
Of course, there’s a lot of work that goes into manually sharing one card on social — never mind 1,000. I found myself craving a way to simplify that admin, like a built-in connection between the listing and social post processes. This turned out to be the perfect use case for the new Buffer API I’d been working on.
The Buffer API was the missing piece that turned this from a tool to just create listings into a tool that sells cards.
With this system, each listing (and its promotion) lives in one flow. Scheduling matters as much as posting. Buffer drops the posts when my audience is actually online (based on our own Best Time to Post data, which you can now find right in your publish dashboard), rather than at 11 pm on a Sunday when I happened to finish photographing a stack.
Here’s a closer look at how I closed the gap between the listings and sales.
How the app works
The (as yet nameless) app lives on my Mac, and the whole flow starts with a drag-and-drop. Here’s what a typical session looks like.
A zip of photos goes in
Originally, I built this to handle one card at a time. I’d chuck a front photo and a back photo into the app, Claude would do its thing, and I’d publish from there. It worked fine, but working through a pile this size one pair at a time was almost as tedious as listing them manually, so I added zip-file support.
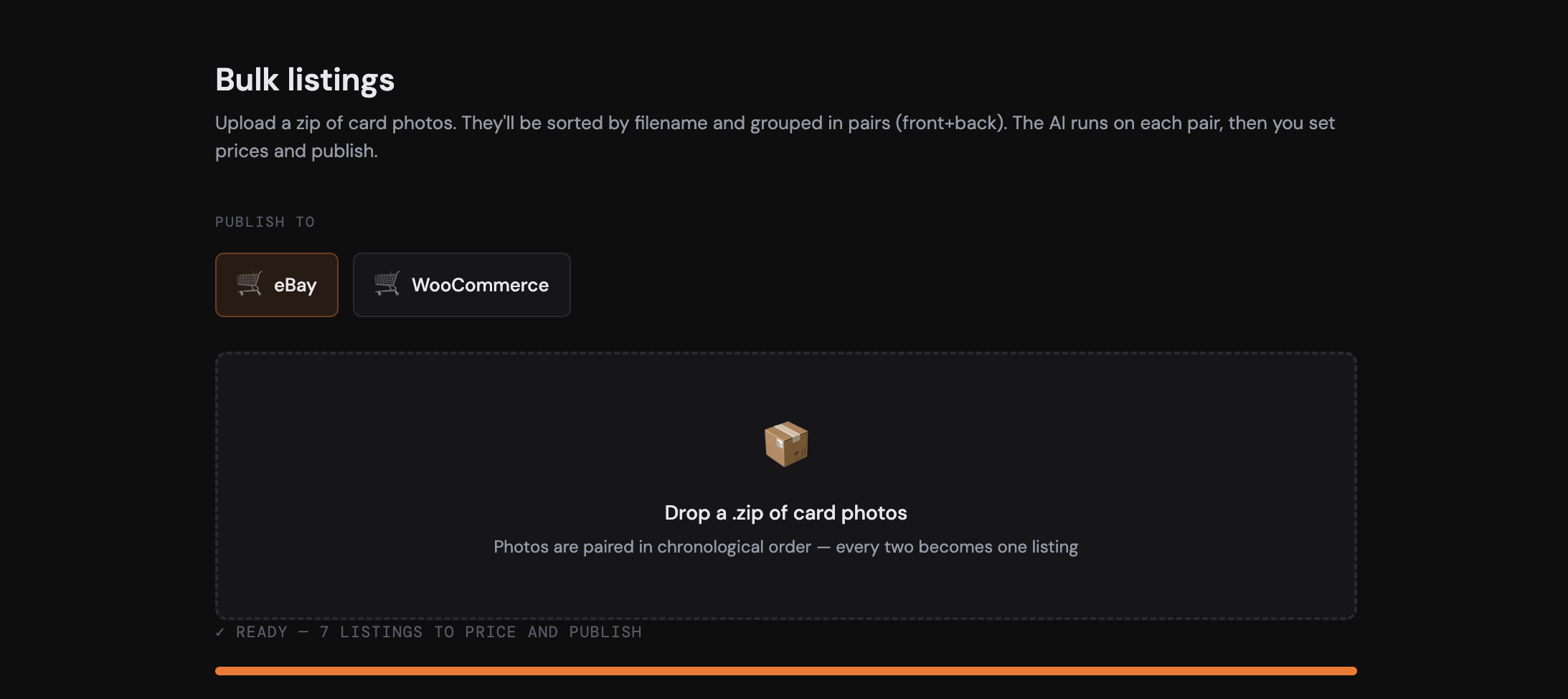
Now I shoot the cards in my little lightbox in batches, pair the photos so each card has a front shot and a back shot, zip the whole lot up, and drag the zip into the app. The app sorts the photos by filename and automatically groups them into pairs.
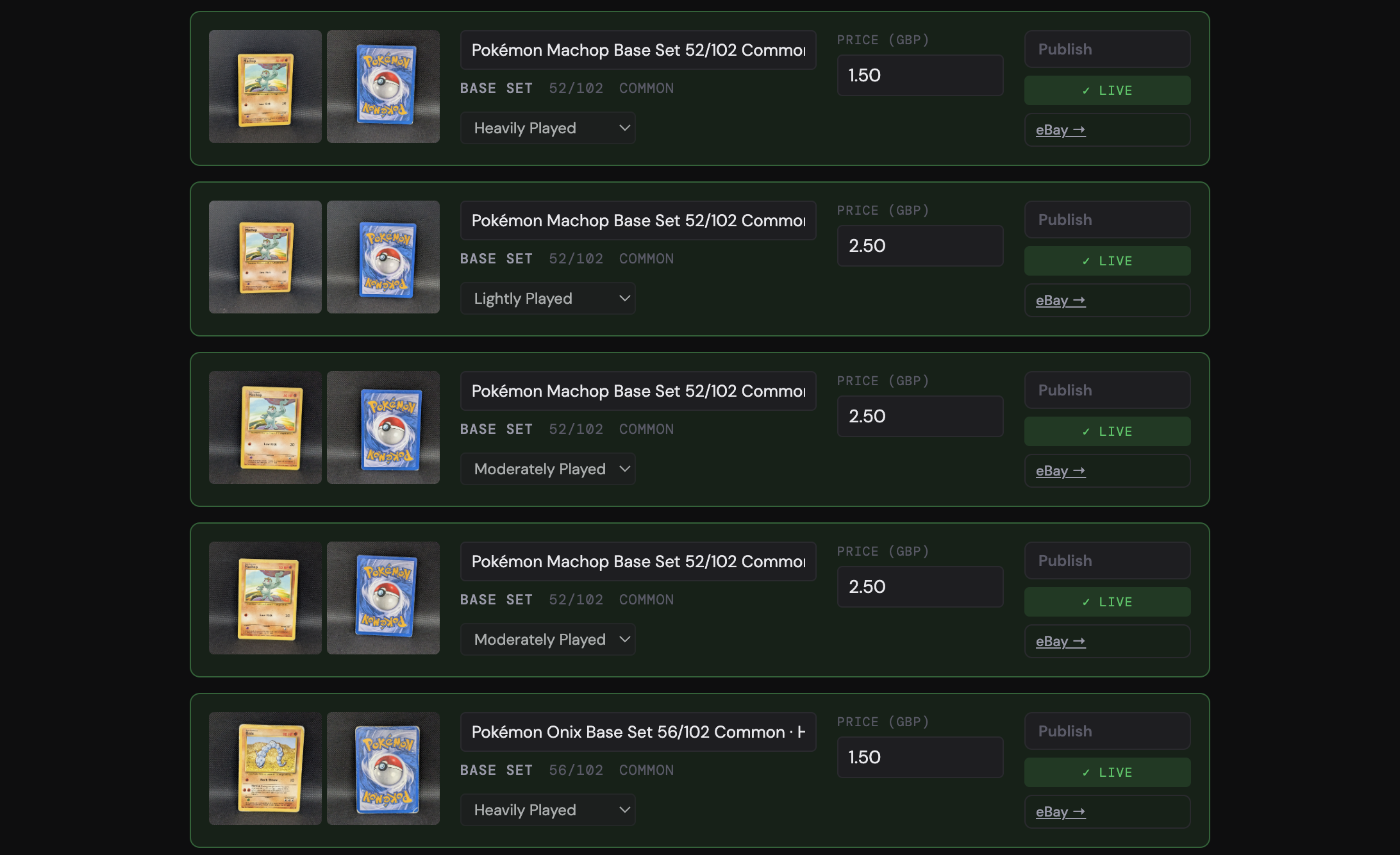
The upload screen also has a newer addition: a selector for where the batch should publish. When I first built the app, everything went to eBay; now I can choose eBay, WooCommerce, or both at once. It’s quite modular, so if I added another provider in the future, like Shopify, it would just be another option in the list.
In practice, I tend to do batches of around 50 cards at a time. It takes a little while for the AI to work through, but that’s fine.
With this system, I can drop the zip folder in, walk away, and come back once it’s done.
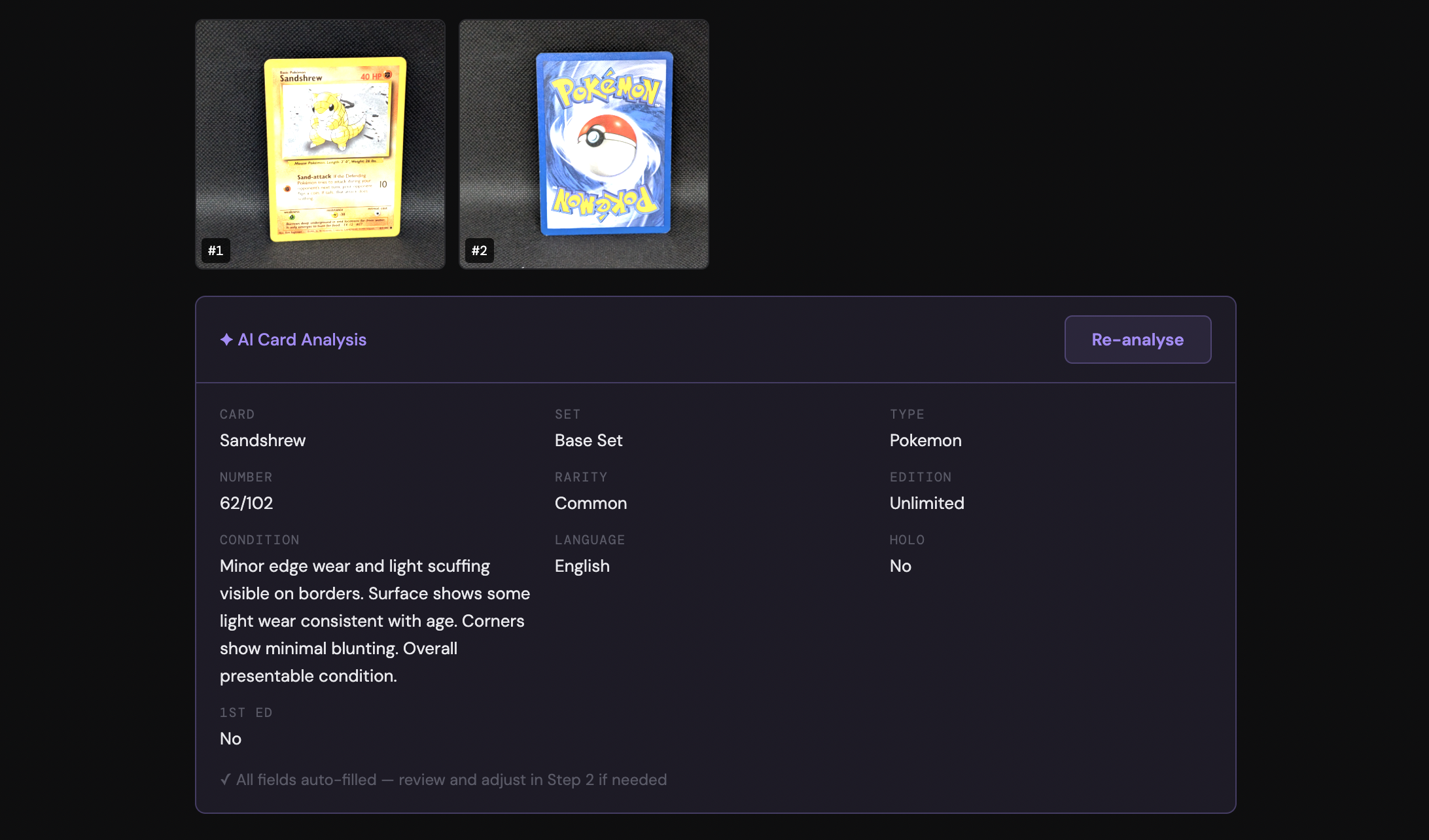
Claude reads each card
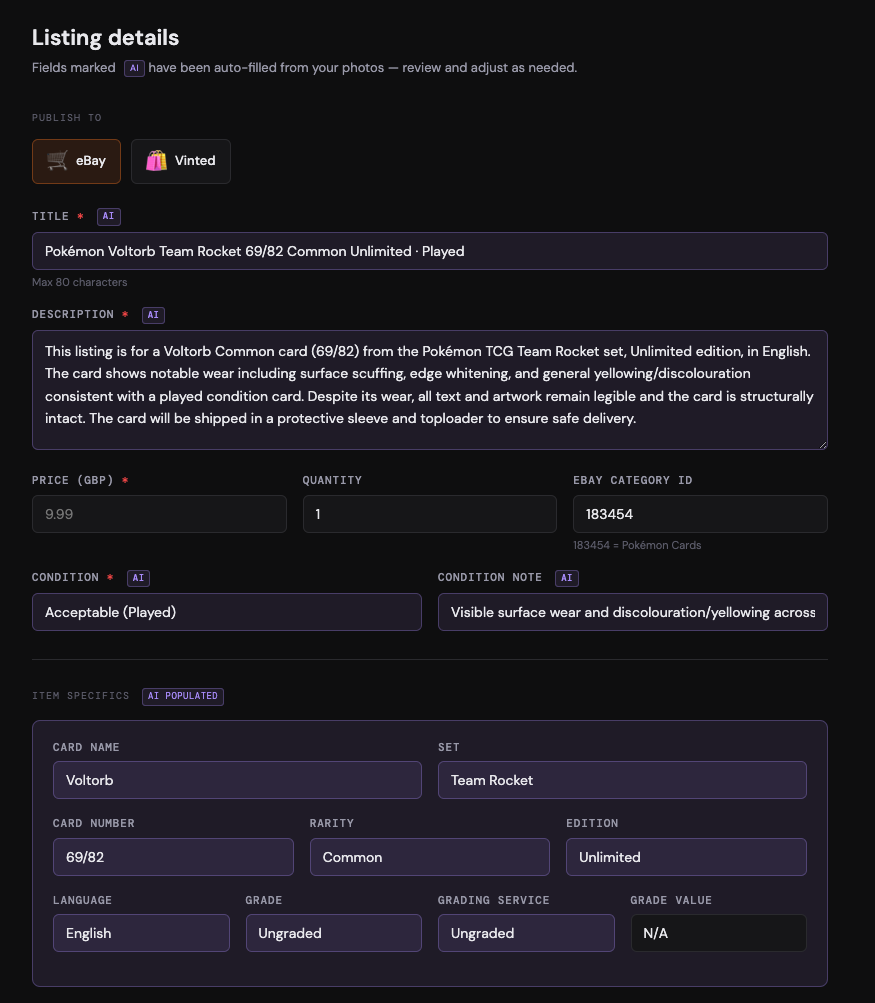
This is the slowest part of the flow, but easily the most useful one. The app sends each pair of photos to Claude, which pulls out the structured details I need for the listing: card name, set, card number, rarity, edition, language, holo or non-holo, and condition.
Condition is the field I cared about most. I used to have to spend the longest part of a listing session just squinting at corners and edges, trying to weigh up whether a card was Lightly Played or Heavily Played. Now Claude makes the call, and I just confirm whether it’s accurate or not.
Sometimes the condition isn’t quite right, and the ratings need to be nudged up or down because my photo isn’t great or the lighting in my lightbox fooled it. I’ll change that before approving the listing, but it’s usually accurate enough that I’ve stopped manually reviewing every single field. I trust Claude on the easy stuff and only look closely at the calls I’d second-guess anyway.
The listing details fill themselves in
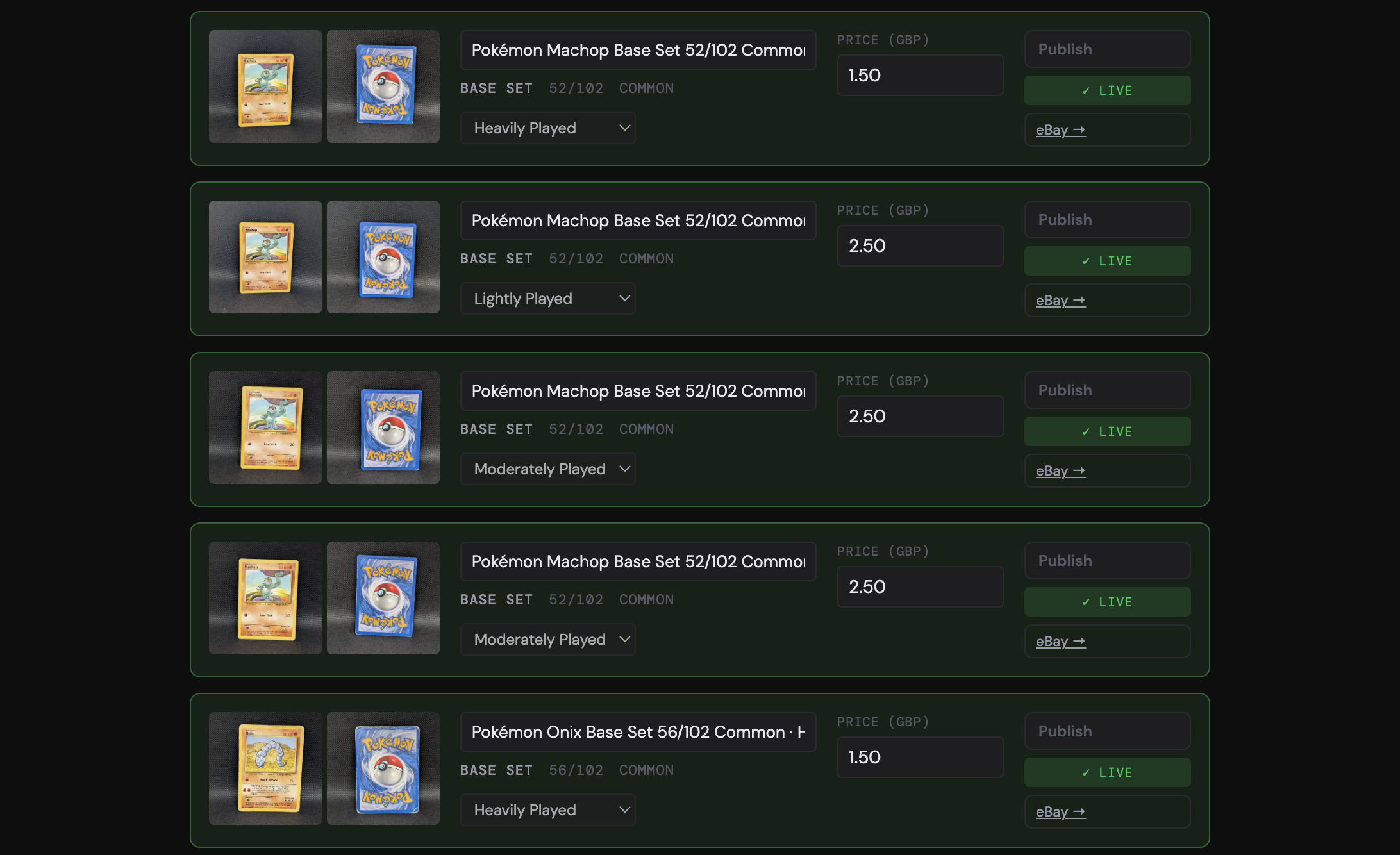
Once Claude has done its pass, every field on the listing form is already populated: title, description, condition note, item specifics, set, number, rarity, and language. The little “AI” badge next to each field is the only visual reminder that I didn’t type any of this.
The only thing I set manually at this point is the price. I’ve been looking at card market data APIs like TCGdex that could pull recent sold prices and active listings for the same card, with the goal of suggesting a number based on actual market data rather than my best guess. I haven’t found one I’m happy with yet, so for now, the price stays the one piece of human judgment in the flow.
Publish in a specific order
When the prices are in, I hit “publish all priced ones,” and two things happen in sequence.
First, the app creates the product in my store through the WooCommerce API (when I started, this step created an eBay listing instead). That has to go first, because the next step needs the live product URL.
Then the app builds a social post with the
card name,
set,
condition note,
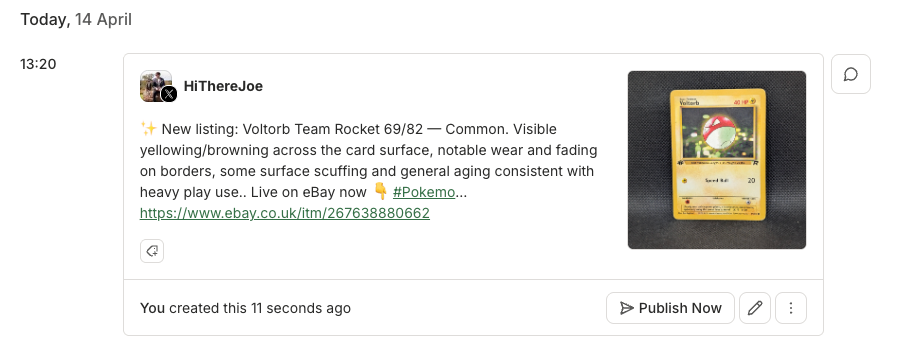
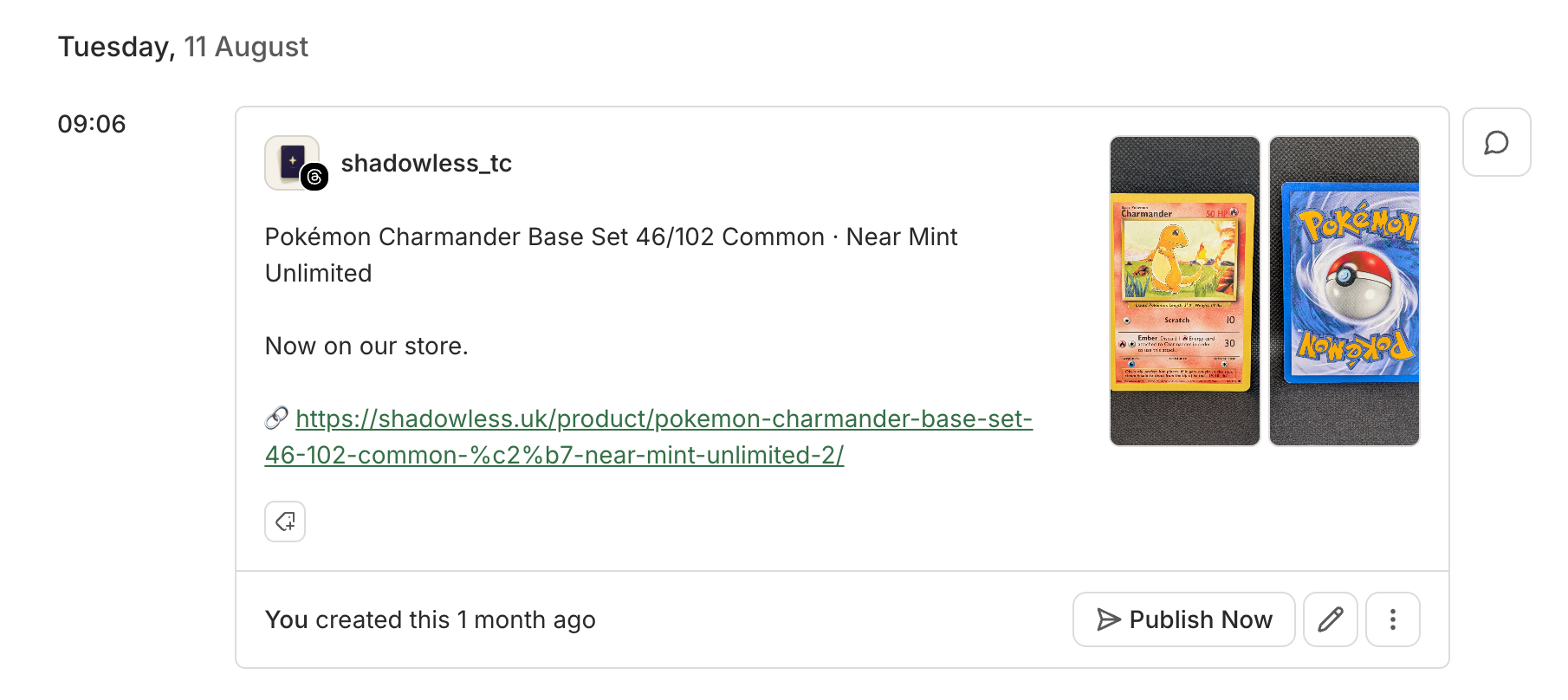
the front and back photos
Then, it queues the post through the Buffer API across whichever channels I’ve selected. Threads gets a direct link to the listing in the post — the newer ones read “now on our store” and link straight to the product page. Instagram, where you can’t drop a clickable link in the body of a post, points to the link in bio instead.
The workflow that used to live across three apps: the marketplace, my photos folder, and a separate mental note to post on Threads later, now lives in one approval.
⚡One thing I purposely kept in the workflow is a single-card mode. If a card is rare or valuable, I don’t want to bulk-publish it alongside fifty Common cards from a Base Set. I want to look at the photos and read Claude’s description closely, set the price more thoughtfully, and then run it through. Full automation is the right default for the bulk of what I’m selling, but it’s not always what you want.
What started on eBay has grown into a store of its own
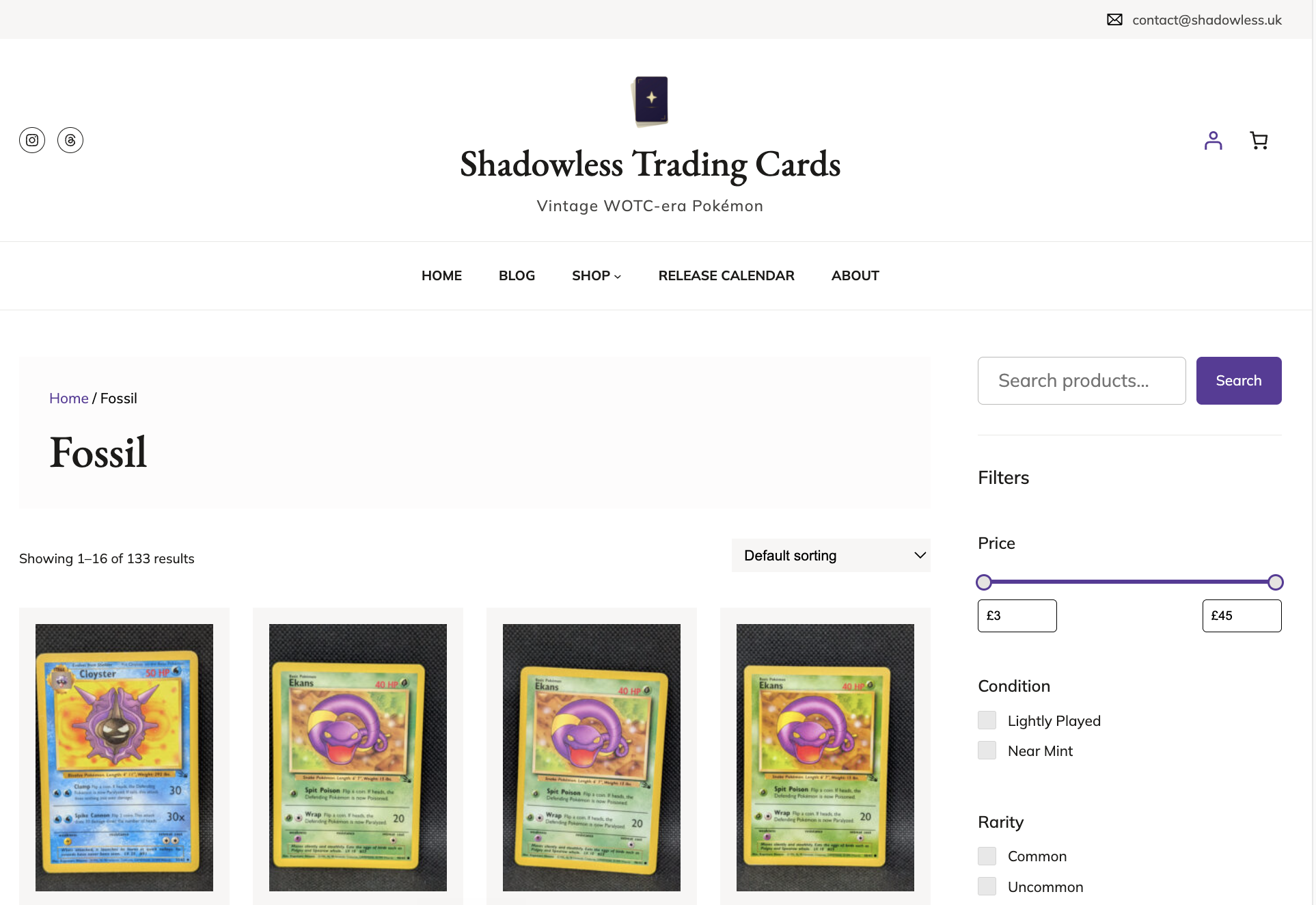
I sold through eBay for the first stretch of this project, and it served me well. The older posts in my Buffer queue still point to live eBay listings, and I’ve kept those products up for that reason. But it felt important to me to have my own brand and my own space to experiment, so I set up Shadowless, a WooCommerce store, and pointed the app at it. Because the publish step was already modular, WooCommerce support was about half a day of work on top of the eBay version.
I’m most pleased with what happens to all those details Claude pulls from the photos. Every field — set, card number, rarity, edition, language — becomes a filterable attribute on the store. A buyer who only collects Rare cards from the Fossil set can filter down to exactly those cards, which is the kind of browsing experience I’d always wanted to offer buyers and could now actually build. Those attributes would have taken me ages to fill in manually, and they’re what makes the store feel like a card shop rather than a long list.
Running my own store does mean the marketing is on me too. I’m still building up traffic, and that’s a whole other project, but the listings and the social promotion were already handled the day the store went live, because the app didn’t have to change.
And then I leave it alone
The process I’ve settled goes something like this: I photograph a stack of cards on a Sunday afternoon, drop the zip into the app, set the prices when Claude finishes its pass, hit publish, and walk away. The listings go live on the store, the Buffer posts go into the queue at the times I’ve already set up — two a day to Threads and Instagram — and I get on with my evening.
My Buffer queue is sitting at over 1,000 posts now, so I’m not losing my streak any time soon. And for all the Claude image analysis behind the 1,310 products in the store (so far), I’ve spent maybe $15 to $20 in total.
The parts I’m still working on
The pricing step is the next thing I want to crack, which is the main reason I’ve been digging into card market APIs. The market moves constantly, and I don’t want to be overcharging anyone, so I’d rather keep this step manual than get it wrong. Once a data source I’m happy with is in, the last manual step in the bulk flow is gone.
The other wrinkle is stock. Some cards have started selling before their scheduled posts go out, which means a post can point to a card that’s no longer available. I’m thinking about a script that watches for stock changes and tracks down the corresponding Buffer post, but there are some complexities there I haven’t worked out yet.
Takeaways for selling anything physical
The Pokémon card-angle is my version of this story, but you can think of this flow beyond cards. It’s how any small seller can make more of their work automatic. Here are four things you can do.
Pull structured details from your photos with AI vision. Whether it’s Claude, GPT-4, or Gemini, pick whichever vision model you trust. The key is asking for structured output (for example, a JSON object with the fields you actually need) rather than a short description. Structured output is what lets the next step in the pipeline consume it without you having to parse anything by hand.
Connect to your marketplace’s API. Most of the platforms a small seller might use (eBay, Etsy, Shopify, Mercari, WooCommerce) have one. The docs are usually rougher than you might hope for, and the listing-creation endpoint is the part that takes the longest to get right, but it’s the only endpoint you really need. And if you choose to build the publish step yourself, adding a second destination is cheap. WooCommerce took me about half a day on top of the eBay version, and that same half day is what now runs my own store.
Close the loop with the Buffer API. Once the marketplace listing is live, use the listing URL to automatically generate a social post with an image, a short caption, and the link. Then queue it through Buffer across whichever channels are right for what you sell. This is the step that’s easiest to skip when you’re building, and it’s the one that turns a listing into a sale.
Keep a manual override. Full automation is the right default for the bulk of items, but add in a single-item review mode for the cases that warrant it. A high-ticket item still needs human eyes.
Listing a product and promoting it should be the same action rather than two separate workflows. Once you wire those together, the time you spend per item drops to seconds, and your products (cards in my case) stop sitting in a box in the corner of your room.
Ready to build?
If you’re taking Buffer’s API for a spin, we’ve got resources to get you moving. Our developer docs cover the GraphQL schema, auth flow, and quick-start examples. The Buffer MCP server docs walk through plugging it into Claude or any MCP-compatible AI agent.
We’d love to hear about what you make. Find us in our Discord server, or @buffer on all major social channels.
https://buffer.com/resources/pokemon-cards/
Indipendenza digitale, la proposta della Commissione scontenta tutti. Critiche incrociate da Europarlamento e Big Tech Usa
Il pacchetto di provvedimenti annunciato dalla Commissione Ue per spingere l’uso di tecnologie europee e allentare la dipendenza dal tech made in Usa, che pesa per l’80% sul totale del parco tecnologico nel Vecchio Continente, è stato accolto da forti critiche interne (da parte dell’Europarlamento) ed esterne (le Big Tech americane, bersaglio per quanto mascherato dell’offensiva).
Le due proposte legislative, una dedicata alla produzione di microprocessori (Chips Act 2.0) e l’atro con l’obiettivo di sviluppare l’AI per il Cloud a livello europeo (CADA, Cloud and AI Development Act) ha sollevato non poche rimostranze, a partire dall’Europarlamento. Del pacchetto fanno parte anche misure open source, ma anche di efficienza energetica.
Il piano dell’esecutivo UE, ad ogni modo, dovrà incassare il sostegno dei 27 paesi del blocco e del Parlamento europeo nei prossimi mesi.
Pacchetto per favorire digitale made in Europe
Henna Virkkunen, commissaria europea alla Sovranità Digitale, ha presentato il pacchetto che esclude i giganti statunitensi come Amazon, Microsoft e Google dalle gare d’appalto cloud più sensibili, incoraggiando al contempo una rapida realizzazione di data center che utilizzino almeno in parte hardware o software europei. Per quanto riguarda i chip, il piano non si concentra tanto sull’attrarre impianti all’avanguardia, quanto sul sostenere i punti di forza esistenti del principale produttore di apparecchiature per chip ASML, dai materiali al packaging avanzato, sfruttando la domanda pubblica per aiutare le startup a crescere.
Ma con pochi campioni europeo, ridurre la dipendenza non sarà facile. Il blocco non ha una versione europea di Nvidia per la progettazione di chip per l’intelligenza artificiale, nessun concorrente della taiwanese TSMC per la loro produzione, e nessun gigante del software paragonabile ai grandi hyperscaler in grado di guidare la domanda attraverso vaste piattaforme Cloud.
Requisiti di sovranità in settori sensibili come banche, energia e sanità
La spinta verso requisiti di sovranità in settori sensibili come quello bancario, energetico e sanitario è motivata dalle preoccupazioni per il dominio dei giganti tecnologici statunitensi, nonché da timori relativi a leggi come il Cloud Act, che obbliga i fornitori con sede negli Stati Uniti a concedere alle autorità l’accesso ai dati anche se archiviati all’estero.
Criteri di sovranità negli appalti pubblici
La proposta dell’UE, finora inedita e che potrebbe subire modifiche dell’ultimo minuto, introduce anche criteri “non di prezzo” obbligatori per gli appalti pubblici, inclusi requisiti per software e hardware sviluppati all’interno dell’UE, il che svantaggerebbe le grandi aziende tecnologiche statunitensi.
Proposta troppo morbida per l’Europarlamento
La proposta è carente, dice Kim van Sparrentak, eurodeputato dei Verdi, che non considera abbastanza severo il provvedimento per assicurare l’indipendenza digitale dell’Europa a lungo termine.
Secondo i detrattori, scrive Politico.eu, la proposta della Commissione è forte nelle intenzioni ma debole nel confronto diretto con el big tech come Google, Microsoft e Amazon.
“La proposta resta troppo permissiva”, dice Christophe Grudler, europarlamentare centrista già in prima linea nella battaglia contro Starlink e l’invadenza extra Ue nel settore satellitare. Per Grudler il pacchetto lascerebbe ancora spazio alle aziende estere per offrire servizi a fette molto delicate e sensibili dell’economia europea.
L’Europarlamento ha così già manifestato apertamente l’intenzione di tentare di rimodellare la proposta.
Il CADA cuore del pacchetto
Il Cloud and AI Development Act (CADA), che rappresenta di fatto il cuore del pacchetto presentato nell’independence Day, introduce una certificazione su quattro livelli che le autorità pubbliche dovrebbero utilizzare per valutare strumenti digitali in base alla loro vulnerabilità a interferenze straniere. In alcuni casi, gli enti pubblici potrebbero essere costretti a sostituire servizi stranieri con alternative europee nel nome del principio del “Buy European”.
Ma larghe fasce del mercato europeo potrebbero comunque restare aperte ai giganti americani. Anche perché il fatto di bloccarli dipenderebbe dalla volontà dei singoli paesi europei di fare arrabbiare Trump.
“Avrei voluto sentire più chiaramente dalla Commissione che gli Stati Uniti non sono più un partner affidabile per il settore pubblico europeo, così come non lo è la Cina”, ha detto Aura Salla, membro del Parlamento europeo di centro-destra, alla commissaria europea per la tecnologia, Henna Virkkunen, durante un’audizione in commissione dopo la presentazione del pacchetto.
Big Tech sulle barricate: un danno per le organizzazioni Ue
Sul fronte opposto delle Big Tech è già partita la protesta, nonostante il tentativo di Bruxelles di depurare al massimo l’idea che il pacchetto sia specificamente anti-americano.
“L’attenzione della proposta su criteri geografici e di nazionalità non favorisce risultati efficaci in termini di sovranità”, ha detto Guido Lobrano, direttore generale per l’Europa dell’Information Technology Industry Council, un’associazione di categoria che annovera tra i suoi membri Amazon, Meta, Google e Microsoft.
Lobrano è stato raggiunto dalle parole di Harry Staight, portavoce di Amazon: “Le organizzazioni europee meritano di avere accesso alla migliore tecnologia disponibile da fornitori affidabili, scelti in base a sicurezza, prestazioni, controlli verificabili e rapporto qualità-prezzo”.
Insomma, il tentativo di Henna Virkkunen, commissario Ue alla Sovranità Digitale, di togliere l’etichetta di protezionismo anti-americano al pacchetto appena predentato è fallito sul nascere.
Mentre Virkkunen presentava il piano mercoledì, racconta Politico che gli ambasciatori dell’UE, riuniti dall’altra parte della strada, stavano approvando una proposta della Commissione per l’adesione dell’UE a Pax Silica, un nuovo club guidato dagli Stati Uniti volto a garantire le catene di approvvigionamento dell’intelligenza artificiale in chiave anti cinese.
CCIA attacca: “Carta bianca alle capitali Ue per escludere le Big Tech”
Daniel Friedlaender, responsabile della sede di Bruxelles del gruppo di pressione tecnologico CCIA, tra i cui membri figurano Google, Meta, Uber e Airbnb, ha affermato che la proposta “di fatto concede alle capitali nazionali carta bianca per escludere fornitori globali affidabili provenienti da tutti i principali paesi produttori di tecnologia al di fuori dell’Unione”.
Se la legge diventerà uno strumento per estromettere i giganti tecnologici statunitensi o un trampolino di lancio per i campioni europei dipenderà da quanto Bruxelles e le capitali dell’UE saranno disposte a spingersi oltre i propri poteri. Tuttavia, il percorso attraverso i negoziati tra il Parlamento e i governi nazionali dell’UE potrebbe essere lungo e accidentato.
I ministri del digitale dell’UE dovrebbero esprimere il loro parere durante il loro incontro in Lussemburgo la prossima settimana, e potrebbero reagire negativamente a una proposta che potrebbero considerare un’ingerenza nei loro poteri decisionali e nelle prerogative nazionali.
Bitcom (Confindustria digitale tedesca), passare dalle parole ai fatti
“È fondamentale che questi sforzi non si fermino a semplici annunci. L’Europa deve agire rapidamente”, sostiene dal canto suo Bitcom, la Confindustria digitale tedesca. Henna Virkkunen, commissaria europea per la tecnologia, ha presentato il pacchetto che esclude i giganti statunitensi come Amazon, Microsoft e Google dalle gare d’appalto cloud più sensibili, incoraggiando al contempo una rapida realizzazione di data center che utilizzino almeno in parte hardware o software europei. Per quanto riguarda i chip, il piano non si concentra tanto sull’attrarre impianti all’avanguardia, quanto sul sostenere i punti di forza esistenti del principale produttore di apparecchiature per chip ASML, dai materiali al packaging avanzato, sfruttando la domanda pubblica per aiutare le startup a crescere.
Ma con pochi campioni regionali, ridurre la dipendenza non avverrà rapidamente. Il blocco non ha una versione europea di Nvidia per la progettazione di chip per l’intelligenza artificiale, nessun concorrente della taiwanese TSMC per la loro produzione, e nessun gigante del software paragonabile alle grandi aziende statunitensi in grado di guidare la domanda attraverso vaste piattaforme cloud.
Indipendenza digitale, come creare il Fondo europeo per partire
Cloud e AI, la strategia europea c’è. Ma ora Bruxelles deve trovare i soldi
La Commissione europea ha presentato la sua strategia per rafforzare la sovranità tecnologica dell’Unione nel cloud e nell’intelligenza artificiale (AI). L’obiettivo politico è chiaro: ridurre la dipendenza da un numero ristretto di fornitori extraeuropei (in particolare quelli americani) e costruire capacità proprie in infrastrutture, calcolo, data center e servizi AI. La vera questione, adesso, è come finanziare questa ambizione.
Qualcosa su questo si trova nei documenti allegati alla proposta di Cloud and AI Development Act, o CADA, in cui Bruxelles non propone un fondo sovrano già pronto all’uso, perchè non c’è e va costruito. Disegna invece un modello di finanziamento ibrido da cui partire, che combina programmi europei esistenti, contributi degli Stati membri e investimenti privati, rinviando la piena scala industriale al prossimo quadro finanziario pluriennale. E qui si giocherà la vera partita della futura autonomia finanziaria dell’istituzione europea.
Il regolamento è esplicito: le iniziative per il cloud e l’AI “may be supported by funding from Union programmes and other instruments”, in particolare Horizon Europe, il Digital Europe Programme e InvestEU. La Commissione aggiunge che le stesse iniziative “may be supported by Member States” e anche da “private-sector investments”. In altre parole, non un unico fondo centrale, per il momento, ma una costruzione graduale di risorse pubbliche e private coordinate tra loro.
Virkkunen (Ue): “Creare capacità di investimento europea per sostenere le nostre migliori imprese nella competizione globale”
Il percorso l’ha ben illustrato la Vicepresidente esecutiva per la Sovranità tecnologica, la sicurezza e la democrazia, Henna Virkkunen, nel suo discorso in occasione della presentazione della strategia europea: “L’Europa sta perdendo terreno nella corsa tecnologica globale perché ha bisogno di più investimenti ad alto rischio nel settore dell’innovazione. Mentre i principali competitor internazionali stanno mobilitando ingenti capitali, il continente si trova ad affrontare un crescente deficit di investimenti strategici. I finanziamenti pubblici rappresentano un punto di partenza importante, ma non possono essere i contribuenti a sostenere da soli questo sforzo. Se l’Europa vuole rafforzare la propria sovranità tecnologica e mantenere il controllo del proprio futuro digitale, è indispensabile che anche il capitale privato aumenti il proprio impegno, sostenendo i progetti più ambiziosi e strategici”.
“Per colmare questo divario, la Commissione europea avvierà con effetto immediato una consultazione con gli Stati membri, il Gruppo Banca europea per gli investimenti (BEI) e i principali attori del settore finanziario. L’obiettivo è chiaro: creare una capacità europea di investimento in capitale di rischio su larga scala, in grado di garantire alle migliori imprese tecnologiche europee le risorse necessarie per competere e affermarsi sui mercati globali”, ha sottolineato la Vicepresidente della Commissione.
È qui che molti hanno letto tra le righe il richiamo ad un “fondo sovrano europeo” che poi sarebbe chiamato ad investire direttamente nelle società tecnologiche (ma anche energetiche e di altri settori strategici) con maggiori possibilità di competere a livello globale. Una sfida significativa, ma che probabilmente è nelle corde della Commissione e dell’Unione tutta.
Un modello ‘ibrido’ a tre livelli
Tornando al modello di finanziamento ibrido al momento individuato dalla Commissione, c’è già un primo livello di risorse europee disponibili. La Commissione punta su programmi esistentiper finanziare ricerca, sviluppo, infrastrutture e prima adozione industriale delle tecnologie cloud e AI. È un passaggio importante, perché mostra che Bruxelles non parte da zero, ma prova a riallocare strumenti già in essere verso gli obiettivi di sovranità tecnologica.
Il secondo livello è quello nazionale. Il testo prevede che gli Stati membri possano sostenere la strategia con misure di ricerca, sviluppo e innovazione, nel rispetto delle regole sugli aiuti di Stato. Questo significa che la Commissione immagina un cofinanziamento pubblico distribuito, in cui i governi nazionali restano parte attiva del processo, soprattutto nei progetti infrastrutturali e nei poli strategici.
Il terzo livello è quello del capitale privato. La Commissione chiede agli operatori industriali e finanziari di tenere conto della strategia nelle loro decisioni di investimento. Qui il messaggio è chiaro: l’obiettivo non è soltanto attrarre capitali, ma orientarli dentro un quadro coerente con le priorità europee, evitando frammentazione e duplicazioni.
Il ruolo del futuro fondo sovrano e un meccanismo di priorità nei finanziamenti
La parte più interessante del testo è però quella che collega la strategia al futuro European Competitiveness Fund. Nel considerando 43 si legge che i “data centre strategic projects” dovrebbero ricevere sostegno da programmi, fondi e strumenti finanziari dell’Unione, in linea con gli obiettivi dei singoli strumenti e senza pregiudicare il prossimo bilancio pluriennale 2028-2034.
Il passaggio più rilevante è quello in cui si afferma che questi progetti dovrebbero ottenere il “competitiveness seal” se soddisfano le condizioni previste dal futuro European Competitiveness Fund, cioè se sono considerati progetti di alta qualità che contribuiscono agli obiettivi del fondo. Di fatto, si sta ragionando su un marchio di qualità da attribuire a progetti considerati validi e strategici, così da facilitarne il finanziamento con altre risorse pubbliche o private anche se non (ri)entrano direttamente nel programma UE originario.
In sostanza, la Commissione sta creando un meccanismo di priorità per far entrare i progetti cloud e data center nel perimetro dei futuri finanziamenti europei.
Questo non significa che il fondo sovrano esista già in forma pienamente operativa. Significa però che la Commissione ne sta preparando la funzione: selezionare, premiare e indirizzare i progetti industriali ritenuti strategici per la competitività europea. È un tassello fondamentale della strategia, perché lega la sovranità tecnologica non solo alla regolazione, ma anche alla futura architettura finanziaria dell’Unione.
Una strategia ancora da finanziare
Il punto politico resta lo stesso: la Commissione ha definito l’orizzonte, ma non ha ancora chiuso il capitolo delle risorse. Il documento mostra una scelta precisa: utilizzare i fondi UE esistenti nel breve periodo, coinvolgere gli Stati membri e il capitale privato nel medio periodo, e agganciare la piena scala industriale al prossimo quadro finanziario pluriennale.
È una costruzione pragmatica, ma anche una prova di forza. Perché la sovranità tecnologica non dipende solo dagli obiettivi industriali o dalle regole sul mercato, ma dalla capacità di mettere insieme risorse sufficienti per sostenere data center, cloud e infrastrutture AI su scala continentale.
In questo senso, il Cloud and AI Development Act è insieme una strategia industriale e una promessa finanziaria ancora da completare, che peraltro dovrà fare i conti con le solite divergenze interne ai 27 Stati dell’Unione. Accetteranno di contribuire a livello finanziario? Condivideranno l’impostazione generale di questa architettura finanziaria? Saranno favorevoli ad aumentare la dote finanziaria dell’Unione? C’è anche da chiedersi se condividono a pieno gli obiettivi della strategia. La Commissione ha aperto il cantiere; ora deve trovare il modo di finanziarlo davvero e di convincere tutti e 27 a mettersi a lavorare.
Google ordered to put clearer links in AI search and let UK publishers opt out
UK regulators today ordered Google to put clearer attributions and links to publishers’ content in its AI-generated search features. The UK’s Competition and Markets Authority (CMA) also said Google must give publishers a way to opt out of AI features in search.
“In a world first, publishers will now have effective tools to prevent their content being used to power AI features in search, such as AI Overviews,” the CMA said today. “This will put publishers, like news organizations, in a stronger position to negotiate content deals with Google. To boost consumer trust, Google is also now required to make sure that publisher content is properly attributed, using clear links, in AI‑generated search results.”
The CMA ruled that Google may not penalize publishers for opting out of AI, meaning that Google can’t downrank opted-out publishers in general search results. The CMA said Google will have nine months to comply with all requirements but that the agency “expects important parts of the controls to become available to publishers well before that deadline. Google will also be required to submit and publish compliance reports, supported by key data and metrics, explaining changes it has made and how it has complied.”
Google’s AI Overviews tend to give confident-sounding responses to search queries, but the links to sources in the AI Overviews may or may not support those confident responses. Clearer attribution and links could make it easier for searchers to determine the accuracy of AI Overview summaries.
The CMA applied the rules to Google after determining that it has “strategic market status” in general search services, and has ongoing investigations into Apple and Microsoft. Google today said it will comply with the CMA decision.
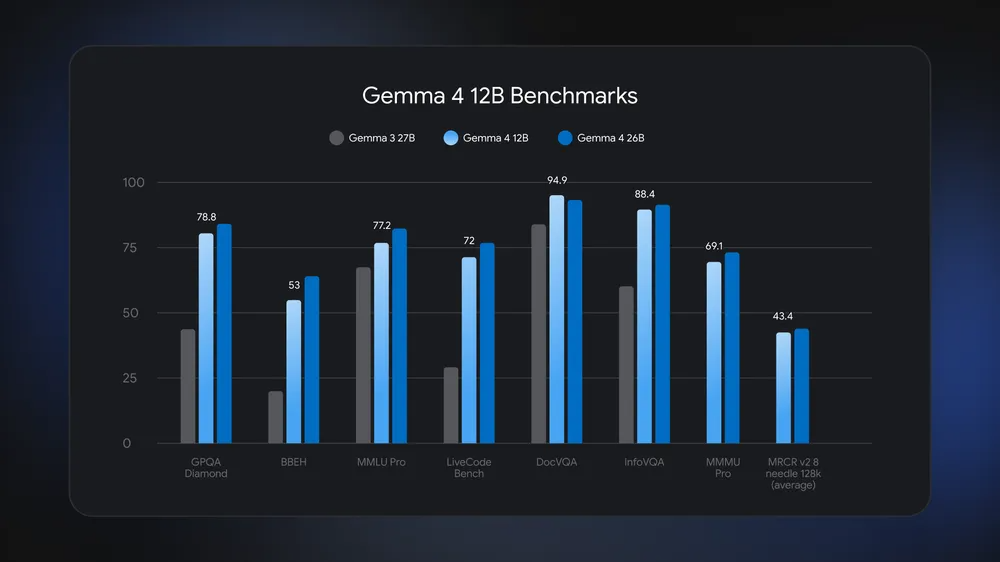
Google’s new Gemma 4 12B model is designed to run on any laptop with 16GB of RAM
Gemma 4 12B is almost as capable as the version with 26 billion parameters.
Credit: Google
Gemma 4 12B is almost as capable as the version with 26 billion parameters. Credit: Google
Google says the new model is capable of complex multistep reasoning and agentic workflows that previously required the larger Gemma variants. Despite the smaller parameter count, Gemma 4 12B comes with the newly devised Multi-Token Prediction (MTP) drafters, which take advantage of unused processing cycles to calculate possible future tokens. The result is greater speed and efficiency. Google has released optional MTP versions of the other Gemma 4 models, but this is the first one to have MTP out of the box.
Gemma 4 12B is also more efficient thanks to a new approach to multimodality. The Gemma 4 family is natively multimodal, accepting text, audio, or images as inputs. Most gen AI models—including the other Gemma 4 variants—use dedicated encoders to process non-text inputs and pass that data to the LLM. This works well enough, but it increases latency and memory usage.
With the new mid-weight model, Google has implemented a streamlined embedding module for vision, featuring single-matrix multiplication and positional embedding, which allows the data to pass to the LLM with proper spatial awareness. This eliminates the need for a bulky middleman encoder. For audio, there’s no encoding at all. The developers worked out a method of projecting the raw audio signal into the same vectors used for text tokens.
[embedded content]
Gemma 4 12B Demo
If you want to check out the new Gemma 4 model, it’s accessible without a download via tools like LM Studio, Google AI Edge Gallery, and more. But the whole idea with Gemma 4 12B is that you can run it locally and on your own terms. If you’ve got the RAM, the model weights are available for download immediately on Kaggle and Hugging Face. It’s just shy of 18GB.
Trump plan to test AI models has a problem—US security teams were gutted by DOGE
Once covered models are defined, Nguyen then warned that the effectiveness of the safety testing will likely depend on whether AI firms are fully transparent and treat the process as a “genuine collaboration.”
“Underneath the definitional problem sits an observability problem,” Nguyen wrote. “The government cannot assess what it cannot see, and frontier capabilities are visible only to the labs that build them.”
Ferren suggested that “the window for erecting proper cyber defenses to new AI models may also close quickly,” and that even a well-designed government program may struggle to properly vet frontier models in such a short timeframe. “Even when well implemented, pre-deployment testing has limits,” Ferren said, noting that Google’s threat intelligence team has found state-aligned actors using frontier models to automate cyberattacks and “researchers have shown that Mythos-style vulnerability reasoning can be reproduced with open-weight systems.”
So while AI may voluntarily submit to testing, they may be financially motivated to seek a rubber-stamp, rather than work with the government to test known frontier capabilities to their fullest extent.
“It will likely prove difficult to develop models that are incapable of malicious hacking yet remain commercially compelling,” Ferren said.
He concluded that the EO “may yield short-term cybersecurity benefits,” but the “long-term effect” remains “unclear.”
Nguyen suggested the EO takes necessary steps to create “classified cyber benchmarking, voluntary prerelease evaluation, and coordinated vulnerability scanning” that “the national security community will need for decades” to “continuously evaluate systems that are probabilistic rather than deterministic, autonomous rather than directed, and whose capabilities change with every update.”
But the safety testing will have to evolve as fast as the technology does, Nguyen said, otherwise we risk assessing emerging models against “yesterday’s risks.”
That’s why, at its core, the process will depend on an honest exchange between stakeholders with deep technical expertise and confidential national security insights. It’s the only way to ensure the US focuses its energies on protecting the public from the most credible and consequential AI risks, rather than just providing “performative reassurances,” Nguyen wrote.
Several people said Wang had also advocated placing greater emphasis on proprietary models over Meta’s longstanding open source approach.
Wang has tried to build support for his vision by cultivating a non-hierarchical start-up culture inside TBD. On a recent podcast, he argued that “the very small team where everyone is ‘cracked’ is always going to move faster than the large org where responsibility is distributed,” using gamer slang to describe highly talented engineers.
He also hosts regular boba tea-fuelled happy hours to foster camaraderie inside the secretive group, according to insiders.
Meta’s broader workforce has experienced a less convivial period. Wang’s first year has coincided with restructurings and rounds of layoffs across the company, seeking to offset the cost of its AI spending spree.
Some employees have also protested company plans to install tracking software that would capture their computer usage in order to train AI models. Meta on Tuesday told staff in a memo, seen by the FT, that it would roll back parts of the plan following the backlash.
Muse Spark has also been deployed primarily inside Meta’s own products, making it difficult for outsiders to assess. Wang had indicated that some external companies would receive access through a private API, but that rollout has been limited.
The model was trained using some third-party open-source models, including Chinese ones. Some insiders have compared aspects of the system with DeepSeek’s latest model, although the extent of any similarities remains disputed.
Muse Spark has been praised for visual understanding, but Wang has acknowledged it trails rivals in coding. Several employees said staff asked to test the model for software development tasks continued to prefer Anthropic’s Claude.
Future Meta models are expected to focus on coding, completing agentic tasks, and more advanced multimodal capabilities, including video generation.
“It was a rough start for him to find his power at the company,” said one associate. “But he’s found his groove.”
Indipendenza digitale europea, la Commissione presenta 4 misure. Von der Leyen: “Non possiamo dipendere da altri”
Von der Leyen (Ue): “Non possiamo permetterci di dipendere da altri”. Il pacchetto per la sovranità tecnologica
Presentato il tanto atteso pacchetto europeo sulla sovranità tecnologica, con le misure volte a rafforzare la capacità dell’Unione europea in materia di semiconduttori, intelligenza artificiale (AI), cloud e open source, ma anche di efficienza energetica.
“Non possiamo permetterci di dipendere da altri per le tecnologie che mantengono in funzione i nostri ospedali, le nostre reti energetiche stabili e i nostri servizi sicuri. Si tratta di proteggere i nostri cittadini, difendere i nostri interessi e fare le nostre scelte. L’Europa ha il talento, l’eccellenza della ricerca, la base industriale e il mercato unico. Insieme, dobbiamo trasformare questi punti di forza in sovranità tecnologica”. Ha dichiarato la Presidente della Commissione europea, Ursula von der Leyen.
I punti chiave del pacchetto comprendono: la legge sui chip 2.0 e la legge sullo sviluppo del cloud e dell’IA, la strategia open source e una tabella di marcia strategica per la digitalizzazione e l’AI nel settore dell’energia.
Il cloud computing è uno dei settori in cui la dipendenza europea è più evidente. Attualmente, le piattaforme statunitensi dominano il mercato. I tre principali fornitori (Microsoft, Amazon Web Services e Google) detengono circa il 70% del mercato europeo. Secondo un rapporto del 2025 della società di consulenza francese Asteres, l’Unione europea spende circa 264 miliardi di euro all’anno per l’acquisto di software per il cloud computing che è sviluppato negli Stati Uniti.
Si rilancia e si torna di fatto il tema ineludibile dell’indipendenza digitale. Come ha spiegato il nostro direttore Luigi Garofalo nei giorni scorsi: “La Commissione Europea ha capito che dal punto di vista dell’innovazione tecnologica l’Europa deve iniziare ad agire in modo autonomo. Non più solo a normare, ma a fare innovazione – oggi dipende dal punto di vista digitale per l’80% da fornitori extra-UE – e a creare un’offerta tecnologica “made in Europe”, facendo crescere, allo stesso tempo, la domanda di Pubbliche Amministrazioni e aziende verso “uno stack tecnologico europeo completo”, con servizi e infrastrutture realizzati da aziende europee“.
Chip 2.0, serve una produzione made in Eu
Oggi, ha precisato Ursula von der Leyen, “per oltre l’80% dei nostri prodotti, servizi e infrastrutture digitali, ci affidiamo a fornitori extra-UE“. “Chi promuove l’innovazione tecnologica plasmerà il futuro, e noi dobbiamo garantire che l’Europa svolga un ruolo di primo piano in questo processo. La sovranità tecnologica non significa protezionismo. L’Europa rimane fondata sui principi di apertura, partenariato e concorrenza leale – ha aggiunto la Presidente della Commissione – ma vogliamo essere in grado di fare le nostre scelte, evitando di dipendere da fornitori unici e dominanti, soprattutto provenienti da paesi che non condividono la sua stessa visione“.
“Il pacchetto odierno ha tre obiettivi fondamentali: trasformare la nostra economia promuovendo l’adozione di nuove tecnologie e dell’intelligenza artificiale; rafforzare la resilienza delle nostre catene di approvvigionamento; promuovere il modello europeo di sovranità tecnologica“, ha precisato von der Leyen.
Obiettivi saranno raggiunti attraverso quattro azioni contenute nel pacchetto sulla sovranità tecnologica: la legge Chips 2.0; la legge sullo sviluppo del cloud e dell’intelligenza artificiale; una strategia europea per l’open source; una tabella di marcia strategica per la digitalizzazione e l’intelligenza artificiale nel settore energetico.
La normativa sui semiconduttori o Chips Act 2.0 è finalizzata a rispondere prontamente alle vulnerabilità critiche nella catena di approvvigionamento globale dei semiconduttori, dato che l’Europa dipende ancora fortemente dai paesi terzi per la produzione avanzata e la progettazione di chip.
Con la legge Chip 2.0 l’Ue intende accelerare le procedure di autorizzazione, approfondire la cooperazione con i partner che condividono gli stessi principi e introdurre un nuovo marchio di eccellenza per le regioni europee dei semiconduttori.
I chip sono anche un’industria globale cruciale per la crescita in Europa. Sono il terzo prodotto più commercializzato al mondo, subito dopo petrolio e veicoli. Nel 2025 il mercato è stato valutato circa 595 miliardi di euro e si prevede che continuerà a crescere, superando la soglia dei trilioni di euro entro il 2030, con componenti legati all’AI che rappresentano oltre il 70 % del mercato globale dei semiconduttori.
L’intento della Commissione è sia avvicinare i produttori di chip europei ai loro clienti, a partire dalla domanda dei settori in crescita, come i data center, i fornitori di cloud e le Gigafactory di IA, sia sostenere gli investimenti e i progetti strategici, affrontando così le vulnerabilità che potrebbero mettere a rischio l’approvvigionamento.
Promuovere lo sviluppo dell’AI e del cloud
L’obiettivo annunciato oggi è triplicare la capacità dei data center in Europa nei prossimi cinque-sette anni e rafforzare il ruolo della strategia Apply AI per promuoverne l’adozione.
Per fare questo è necessario però tenere alto il principio della sostenibilità e quindi rispettare la tabella della transizione energetica: “bilanciando nel contempo le ambizioni in materia di AI con gli impegni in materia di clima”.
La legge sullo sviluppo dell’AI e il cloud l’introduzione di un quadro unico a livello “la sovranità del cloud e dell’AI”, mantenendo comunque “un mercato aperto ai partner che condividono gli stessi principi”. Viene da chiedersi, tra questi ci saranno o no le Big Tech?
“Viviamo in un mondo in cui geopolitica e tecnologia sono inseparabili. Coloro che promuovono l’innovazione tecnologica daranno forma al futuro e dobbiamo garantire che l’Europa svolga un ruolo guida in questo senso. Il pacchetto odierno segna un importante cambiamento nel modo in cui l’Europa si avvicina alla sovranità tecnologica. È tempo che l’Europa abbia il controllo dei suoi dati, delle sue catene di approvvigionamento e del suo futuro in modo pulito e sostenibile. Stiamo rafforzando l’autonomia e la resilienza digitali dell’Europa, mantenendo nel contempo la nostra economia aperta ai partner di tutto il mondo”, ha commentato Henna Virkkunen, Vicepresidente esecutiva per la Sovranità tecnologica, la sicurezza e la democrazia.
Henna Virkkunen
Il mercato europeo del cloud e dell’AI sta crescendo rapidamente, passando da 70 miliardi di euro nel 2022 a 200 miliardi previsti entro il 2028. Queste tecnologie aumentano la produttività, migliorano i servizi pubblici e cambiano la vita quotidiana. Ad oggi, però, il loro pieno potenziale non è ancora pienamente realizzato in Europa.
La sovranità tecnologica passa per l’open source
Il pacchetto punta dritto all’open source per rafforzare l’autonomia digitale del continente: “Abbiamo oltre tre milioni di contributor open source. Forniscono soluzioni digitali realizzate in Europa, per l’Europa, sulla base di principi e valori europei”.
Seguendo questo principio, si capisce che l’Europa porterà avanti una strategia mirata a sviluppare e sostenere alternative open source in settori prioritari quali il cloud, l’AI, le tecnologie internet, la cibersicurezza e i semiconduttori.
Per ottenere un ecosistema open source più forte bisogna investire nelle competenze, sostenendo le startup open source e migliorando la manutenzione e la sicurezza a lungo termine dell’infrastruttura digitale open source europea. Altro punto chiave è il maggiore utilizzo dell’open source nelle pubbliche amministrazioni, da promuovere secondo quanto riportato nel documento ufficiale attraverso orientamenti chiari e più specifici in materia di appalti e best practice.
Dan Jørgensen
Jørgensen (Ue): “Non può esserci sovranità digitale senza sovranità energetica“
Altro problema non da poco, come abbiamo sperimentato sulla nostra pelle da qualche anno a questa parte è l’elevato costo dell’energia. Qui la Commissione vede come unica strada maestra la digitalizzazione del settore energetico dell’Unione.
Le guerre e le tensioni geopolitiche sempre più profonde ci obbligano ad agire con fermezza e rapidità, anche in considerazione dell’aumento della domanda di energia legato all’esplosione delle infrastrutture digitali necessarie a cloud e AI.
La strategia presentata oggi, è spiegato nel comunicato, stabilisce in che modo l’AI e altre soluzioni digitali possono garantire l’integrazione sostenibile dell’infrastruttura digitale critica nel nostro sistema energetico, contribuendo nel contempo a rendere più efficiente il sistema energetico dell’Unione.
“Dobbiamo integrare le infrastrutture digitali nel nostro sistema energetico in modo sostenibile. Perché non può esserci sovranità digitale senza sovranità energetica“, ha dichiarato secco Dan Jørgensen, Commissario per l’Energia e l’edilizia abitativa.
“La digitalizzazione del sistema energetico è la possibilità per l’Europa di ottenere di più dalle stesse infrastrutture di cui disponiamo e di ridurre le bollette per i consumatori. Questo pacchetto coglie questa opportunità e garantisce che la crescente domanda dei centri dati funzioni con la rete, non contro di essa, quindi l’ambizione digitale dell’Europa alimenta la transizione energetica piuttosto che competere con essa”, ha affermato Teresa Ribera, Vicepresidente esecutiva per una Transizione pulita, giusta e competitiva.
A tal fine, la tabella di marcia dovrebbe garantire che i data center siano integrati nel nostro sistema energetico “in modo sostenibile e trasparente”. Nel 2024, i data center europei hanno consumato energia elettrica sufficiente ad alimentare quasi 20 milioni di famiglie. Entro il 2030, l’Ue stima che questa domanda raddoppierà.
“Introdurremo a breve un sistema di classificazione europeo per i data center. Promuoveremo inoltre un modello di accordo tra autorità pubbliche, gestori di data center e operatori del settore energetico. La nostra attenzione si concentrerà sull’integrazione nella rete elettrica, sulla fornitura di energia pulita, sulla flessibilità e sull’efficienza energetica, unitamente alla tutela delle risorse idriche e al rispetto degli standard ambientali“, ha aggiunto il Commissario per l’Energia.
La Commissione, di suo, lavorerà per facilitare “la cooperazione tra i settori dell’energia e del digitale” per garantire l’integrazione efficiente nella rete di queste infrastrutture e il necessario approvvigionamento di energia pulita per aliimentarle, salvaguardando nel contempo le risorse idriche ed energetiche.
Come più volte è stato detto, le stesse tecnologie digitali, in primis l’AI, saranno fondamentali per migliorare i livelli di efficienza energetica in generale e di efficienza della rete elettrica europea. A tal fine è considerata di primaria importanza la diffusione dei contatori di nuova generazione per il migliore controllo sui consumi dell’energia e quindi sui costi in bolletta.
In ultima analisi, la digitalizzazione dell’energia contribuirà a costruire modelli AI sovrani e sicuri per il settore energetico, formati sui dati europei e sviluppati dalle imprese europee: “Vogliamo creare un nuovo modello di intelligenza artificiale per il settore energetico, addestrato su dati europei e sviluppato da aziende europee. Si tratta di una questione di sovranità tecnologica europea e di autonomia strategica. Per questo motivo, svilupperemo modelli di intelligenza artificiale lungo tutta la catena del valore e istituiremo un quadro normativo a livello UE per semplificare lo scambio transfrontaliero di dati energetici“.
“Stiamo vivendo una rivoluzione digitale globale e una corsa mondiale per plasmare il futuro dell’intelligenza artificiale. Queste tecnologie stanno trasformando il nostro modo di vivere, lavorare e alimentare le nostre economie. L’Europa non deve semplicemente partecipare a questa trasformazione, deve guidarla. Ma leadership significa farlo in un modo che rifletta i nostri valori: responsabile, sostenibile e a beneficio di tutti i consumatori e di tutti i settori. Il nostro compito è chiaro: gestire le crescenti esigenze energetiche della digitalizzazione, liberando nel contempo le immense opportunità che l’innovazione pone alla nostra portata”, ha spiegato Jørgensen.
Da migliorare, infine, la sicurezza informatica dei dispositivi critici, come gli impianti solari, contestualmente ad un utilizzo più sicuro dell’intelligenza artificiale.
In arrivo il bando per le gigafactory AI
A questo punto si attende per luglio l’invito a presentare proposte per la rete di gigafactory AI europee.
La Commissione avvierà inoltre una consultazione con gli Stati membri, la Banca europea per gli investimenti e altre parti interessate per raccogliere le risorse necessarie a finanziare le ambizioni europee in materia di sovranità tecnologica.
Tutte le proposte legislative presentate oggi dovranno comunque essere negoziate dal Parlamento europeo e dal Consiglio dell’Unione europea nelle prossime settimane.