«Breaking TCAS»: vulnerabilità e attacchi nella sicurezza aerea
Alla 14ª edizione della Cyber Crime Conference, ospitata a Roma il 6 e 7 maggio 2026 nell’Auditorium della Tecnica, il Prof. Alessio Merlo, Direttore del Centro Alti Studi per la Difesa (CASD, Scuola Superiore Universitaria), ha presentato i risultati di una ricerca condotta dal CASD insieme all’Università di Genova sulle vulnerabilità del Traffic Collision Avoidance System (TCAS), il sistema anticollisione obbligatorio sugli aerei di linea.
L’intervento, intitolato «Breaking TCAS: vulnerabilità e attacchi nella sicurezza aerea», si è mosso su due piani: da un lato l’illustrazione di due distinte vulnerabilità del protocollo TCAS, dall’altro la formulazione di un’ipotesi tecnicamente motivata per spiegare l’incidente avvenuto il 1° marzo 2025 lungo la traiettoria di avvicinamento all’Aeroporto Ronald Reagan di Washington (DCA).

Il contesto: ATC, radar secondario e TCAS
Il controllo del traffico aereo poggia sulla torre di controllo (Air Traffic Control, ATC), che gestisce gli atterraggi tramite il radar primario. Quando un aereo si trova lontano dall’aeroporto, entra in gioco un secondo livello di sorveglianza: il radar secondario, basato sullo scambio di segnali radio in radiofrequenza fra aeromobili. Misurando il tempo di risposta in funzione della velocità della luce, ogni velivolo stima la distanza e la posizione degli altri aerei nelle vicinanze.
Al di sopra del radar secondario opera il TCAS, introdotto circa quarant’anni fa e considerato l’ultima barriera per la prevenzione delle collisioni. Funziona in modo autonomo e genera due tipologie di allerta:
- Traffic Advisory (TA): avviso visivo al pilota della presenza di un altro aereo, con l’indicazione della posizione e dell’altitudine.
- Resolution Advisory (RA): manovra evasiva automatica e coordinata fra due velivoli in rotta di collisione (uno sale, l’altro scende).
Come ha sottolineato Merlo, il protocollo TCAS è stato progettato in un’epoca in cui la cybersecurity non era una priorità di design: non prevede autenticazione, né controllo di integrità, né cifratura.
Iniettare aerei falsi: la prima vulnerabilità
Nel 2023 il gruppo di ricerca del CASD e dell’Università di Genova ha cominciato a studiare la possibilità di iniettare contatti aerei falsi sul radar di un velivolo bersaglio, fino a indurlo a generare TA e RA reali.
L’unica protezione fisica del protocollo era il ritardo fisso di 128 microsecondi previsto dalla modalità Modo S: per far comparire un aeromobile a una distanza più prossima all’aereo sotto attacco rispetto alla posizione reale dell’attaccante, quest’ultimo avrebbe dovuto rispondere a un’interrogazione in tempi più brevi di tale ritardo, anticipando di fatto la risposta legittima. Storicamente, questa barriera temporale aveva reso l’attacco irrealizzabile con hardware comune.
I ricercatori hanno dimostrato che l’evoluzione dell’hardware Software Defined Radio (SDR) ha riscritto lo scenario: oggi l’attacco è realizzabile con apparati dal costo di circa 10.000 euro e funziona fino a 5 chilometri di distanza dall’aereo bersaglio, una portata particolarmente critica nelle fasi di atterraggio.
Disabilitare le RA: l’exploit del Sensitivity Level
La seconda vulnerabilità individuata riguarda il Sensitivity Level (SL), il parametro che regola la soglia di attivazione delle Resolution Advisory. Lo standard prevede che il valore di SL possa essere modificato dalle stazioni di terra in scenari operativi complessi, come gli avvicinamenti in aree congestionate.
Un attaccante può falsificare il comando di terra e impostare SL=0, disabilitando completamente la generazione di RA: il TCAS continua a emettere TA, ma non produce più la manovra evasiva automatica. Il ripristino richiede il riavvio del sistema, un’operazione tutt’altro che banale in volo.
La timeline della responsible disclosure
La scoperta delle vulnerabilità ha innescato un articolato iter di responsible disclosure, che ha coinvolto le United Nations (UN), l’European Union Aviation Safety Agency (EASA), la Federal Aviation Administration (FAA), l’Ente Nazionale per l’Aviazione Civile (ENAC), l’Agenzia per la Cybersicurezza Nazionale (ACN) e il Comando per le Operazioni in Rete (COR).
Le tappe principali:
- Giugno 2023: scoperta delle vulnerabilità.
- Febbraio 2024: sottomissione dell’articolo scientifico.
- Maggio 2024: accettazione del paper.
- Agosto 2024: presentazione a USENIX Security 2024 (Longo, Strohmeier, Russo, Merlo, Lenders, «On a Collision Course: Unveiling Wireless Attacks to the Aircraft Traffic Collision Avoidance System»).
- Gennaio 2025: pubblicazione dell’ICS Advisory CISA, con assegnazione di due CVE.
- Aprile 2025: comunicato stampa e diffusione mediatica, con oltre 60 apparizioni su testate nazionali, regionali e locali.
L’advisory CISA e la valutazione del rischio
Il bollettino ICS della CISA, pubblicato a gennaio 2025, ha ufficializzato le due vulnerabilità:
- CVE-2024-11166 (Sensitivity Level): mitigabile aggiornando gli apparati alla versione ACAS X o il transponder allo standard RTCA DO-181F.
- CVE-2024-9310 (protocollo TCAS): nessuna mitigazione disponibile.
Il documento accompagnava la pubblicazione con una valutazione del rischio improntata alla prudenza: «These vulnerabilities in the TCAS II standard are exploitable in a lab environment. However, they require very specific conditions to be met and are unlikely to be exploited outside of a lab setting». La storia, come si vedrà, ha messo in discussione questa rassicurazione nel giro di poche settimane.
1° marzo 2025: l’incidente di Washington DCA
Il 1° marzo 2025, in una mattinata di buona visibilità, lungo la traiettoria di avvicinamento alla pista 19 dell’Aeroporto Ronald Reagan di Washington sono state registrate numerose segnalazioni di TCAS TA e RA. Gli eventi si sono susseguiti per circa tre ore, dalle 11:10 alle 14:10 UTC.
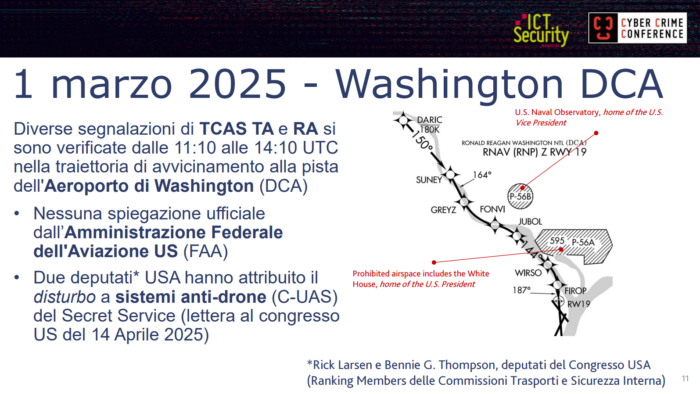
A oggi la Federal Aviation Administration non ha fornito alcuna spiegazione ufficiale. Le uniche risposte istituzionali sono arrivate da due deputati USA, Rick Larsen e Bennie G. Thompson, Ranking Members delle Commissioni Trasporti e Sicurezza Interna: in una lettera al Congresso del 14 aprile 2025, i due hanno attribuito il «disturbo» a sistemi anti-drone (C-UAS) del Secret Service. L’ipotesi presenta tuttavia un’incongruenza tecnica evidente: i droni non sono dotati di TCAS, e un sistema anti-drone non dovrebbe pertanto interferire con il protocollo TCAS degli aerei di linea.
L’analisi da fonti aperte
Incrociando annunci di posizione, annunci RA e comunicazioni radio reperibili in fonti aperte, il team di Merlo ha ricostruito gli elementi quantitativi dell’evento:
- 10 aerei coinvolti, di cui 8 con RA e 3 con go-around (atterraggio abortito).
- 5 km di visibilità orizzontale.
- Singolo intruso a quota fissa di circa 700 metri, non rilevato né dall’ATC né visivamente dai piloti.
- Trasmissione in Modo C (tecnologia legacy rispetto al Modo S), che riporta solo la quota e non la posizione.
- Distanza media indicata dagli annunci RA: circa 400 metri.
- Direzione: tra 315° e 345°, corrispondente a «ore 11» rispetto ai velivoli coinvolti.
L’analisi geometrica delle distanze restituisce un esito controintuitivo: ogni aereo sembra avere il proprio intruso che si muove insieme a esso. Un oggetto in volo con tali caratteristiche sarebbe stato impossibile da non rilevare, sia strumentalmente sia visivamente. L’ipotesi più plausibile resta quindi quella di un trasmettitore fisso a terra che inietta contatti falsi tramite il Modo C.
Replicare l’attacco sul Modo C
Per verificare la fattibilità tecnica dell’ipotesi, i ricercatori hanno replicato l’attacco di iniezione sul Modo C, dove il ritardo fisso di riferimento scende a soli 3 microsecondi, contro i 128 del Modo S. Il modello SDR da 10.000 euro a quel punto non è più sufficiente: serve un’implementazione su RFSoC (FPGA, front end RF e CPU ARM/Linux), con un costo dell’ordine di 80.000-90.000 euro.
L’attacco è stato validato fino a una distanza massima di circa 2 chilometri e certificato con il test set avionico Aeroflex IFR6000, utilizzato in ambito industriale per la verifica dei TCAS reali.
Geolocalizzare il trasmettitore: il metodo Sequential Monte Carlo
Dimostrata la fattibilità tecnica, restava da capire se i dati pubblici dell’incidente DCA fossero compatibili con un trasmettitore fisso a terra e, in tal caso, dove fosse collocato.
I ricercatori hanno sviluppato un metodo probabilistico basato su Sequential Monte Carlo per stimare la posizione di un trasmettitore fisso a partire dalle osservazioni registrate. Il metodo è stato validato preventivamente su 300.000 scenari sintetici comparabili o superiori al caso DCA, con i seguenti risultati:
- Identificazione corretta della sorgente fissa nel 95% dei casi.
- Errore medio di circa 855 metri.
- Tempo di esecuzione medio di circa 8 secondi.
- Comportamento differenziale: se il trasmettitore è mobile, la distribuzione di probabilità non converge.
Il risultato sul caso DCA
Applicato ai dati reali dell’incidente del 1° marzo 2025, il metodo ha prodotto una distribuzione di probabilità stabile e coerente con l’ipotesi di una sorgente fissa a terra:
- Stima della sorgente a circa 890 metri dal centro dell’area ristretta P-56B.
- Probabilità del 94% che il trasmettitore si trovi all’interno dell’area ristretta.
- In 40 minuti, dopo due incontri, l’algoritmo avrebbe ristretto la sorgente a un’area di circa 4 km².
L’area P-56B coincide con lo U.S. Naval Observatory, residenza ufficiale del Vicepresidente degli Stati Uniti. Il risultato è pubblicato in Longo, Ratto, Merlo, Russo, «Unknown Target: Uncovering and Detecting Novel In-Flight Attacks to Collision Avoidance (TCAS)», nei proceedings del Network and Distributed System Security (NDSS) Symposium 2026.
Su questo punto Merlo è stato esplicito: «il rilevamento non equivale all’attestazione». I numeri pubblici indicano la compatibilità tecnica di un’origine fissa in una zona precisa, ma non costituiscono, di per sé, un’attribuzione formale dell’identità degli attaccanti.
Takeaway
L’intervento si è chiuso con alcune considerazioni di carattere sistemico sulla sicurezza dei sistemi cyber-fisici:
- L’isolamento dei sistemi critici, pur necessario, non è sufficiente a preservarli dagli attacchi cyber, soprattutto quando l’hardware d’attacco diventa accessibile a budget contenuti.
- La debolezza intrinseca di molti sistemi avionici e industriali deriva da norme e standard storicamente progettati senza integrare la cybersecurity.
- I cyber range e l’approccio multidisciplinare alla ricerca sono ormai imprescindibili per il cybersecurity testing di sistemi cyber-fisici, in cui la sperimentazione su asset reali è eticamente e operativamente impraticabile.
- Le implicazioni geopolitiche della detection vanno affrontate con cautela metodologica.
- Esiste un nodo irrisolto fra security e safety: a differenza di un attacco a un server, un attacco a un aereo in volo introduce un rischio diretto per le vite umane.
- I sistemi cyber-fisici poggiano su protocolli legacy: la protezione fisica non basta più, rendere «smart» un sistema spesso lo rende meno sicuro, e riprogettare tutto da zero non è un’opzione realistica.
Al di là del suo valore tecnico, il caso TCAS è un richiamo alla necessità di integrare la cybersecurity nei processi di standardizzazione internazionale, di investire in cyber range avionici e di formare giovani ricercatori capaci di operare alla frontiera fra security, safety e implicazioni geopolitiche. Come ha ricordato Merlo, la distanza fra un attacco a un server e un attacco a un aereo in volo non si misura più in termini di disponibilità di un servizio, ma in vite umane. Una soglia che impone a ricerca, industria e regolatori di muoversi insieme, e in fretta.
https://www.ictsecuritymagazine.com/articoli/breaking-tcas-sicurezza-aerea/


 La fine della copia integrale e del sequestro a “strascico”: Cass. Pen. Sez. VI n. 543 dep. 8 gennaio 2026
La fine della copia integrale e del sequestro a “strascico”: Cass. Pen. Sez. VI n. 543 dep. 8 gennaio 2026






