Iran’s hackers are on the offensive against the US and Israel
Israeli authorities say it has launched thousands of wiper attacks on Israeli companies, successfully hitting about 50. Its operatives’ hacking of security cameras across Israel and the Gulf has helped target drone and missile strikes, said Gil Messing, at Israeli cyber security company Check Point Software.
Tehran is also aligning its cyber capabilities with its regular war effort. Its hackers showed a “new level” of “scale, effect and sophistication” by coordinating strikes with the mass text messages sent to Israeli citizens, Messing said.
But for all the noise, some analysts are surprised that Tehran has not struck more decisive strategic targets. In the past, it has attacked American and Israeli critical infrastructure, including water treatment plants, but has not struck similar blows during the current conflict.
There are a handful of possible explanations: early Israeli strikes may have weakened Iran’s capabilities; Tehran might have hobbled its own hackers by throttling its Internet for domestic censorship; and it can just take time to design the complex malware needed for big attacks.
They may also have found their way undetected into sensitive economic or military targets, squatting inside to suck up information. “They could have long-term access that they are not ready to burn,” said Andy Piazza at cyber security firm Palo Alto Networks.
But if it can get its hackers firing, US defenses are uneven, some experts say.
“If they’re given time and space to regroup, [Iran] could very well develop the capabilities to deliver something more decisive,” said Matthew Ferren at the Council on Foreign Relations.
In Israel, critical-structure cyber security is handled by the state, where in the US and Europe the private sector has to protect itself but can seek government help post-hack. And the US has structural weaknesses caused by the early Internet’s decentralized adoption and the sheer size of the country and its dispersed infrastructure.
US defensive capabilities recently began further atrophying owing to the Trump administration’s clashes with CISA, the agency tasked with protecting critical infrastructure, analysts said. CISA has not had a permanent director since January 2025 and is operating at around a third of its normal staffing.
“I am concerned,” said Emily Harding of the Center for Strategic and International Studies. “The cat is out of the bag at how weak we are defensively.”
Intesa Sanpaolo, multa da 31,8 milioni per un data breach durato oltre due anni
Un data breach protratto per più di due anni, migliaia di accessi indebiti e sistemi di controllo ritenuti inadeguati. Con queste motivazioni il Garante per la protezione dei dati personali ha sanzionato Intesa Sanpaolo con una multa da 31,8 milioni di euro, una delle più rilevanti in ambito bancario.
Accessi abusivi e controlli inefficaci
L’istruttoria dell’Autorità, avviata dopo la notifica del data breach nel luglio 2024, ha accertato che un dipendente della banca ha consultato senza alcuna giustificazione le informazioni bancarie di 3.573 clienti. Gli accessi indebiti sono stati oltre 6.600 e si sono verificati tra il 21 febbraio 2022 e il 24 aprile 2024.
Il dato più critico riguarda l’assenza di rilevazione: i sistemi interni di monitoraggio non sono stati in grado di individuare tempestivamente l’anomalia, evidenziando lacune strutturali nei meccanismi di prevenzione e controllo.
Coinvolti anche clienti ad alto rischio
Tra i soggetti interessati figurano anche clienti definiti “ad alto rischio”, inclusi individui con ruoli pubblici di rilievo. Secondo il Garante, in questi casi sarebbero stati necessari presidi di sicurezza rafforzati, che invece non risultano adeguatamente implementati.
L’episodio evidenzia un deficit nella gestione dei profili più sensibili, che richiedono livelli di protezione differenziati.
Violazioni dei principi GDPR
L’Autorità ha rilevato la violazione di principi cardine del GDPR, in particolare quelli di integrità e riservatezza dei dati, oltre al principio di accountability.
Il modello operativo adottato dalla banca, che consentiva agli operatori un accesso esteso e trasversale all’intera base clienti, non era accompagnato da controlli efficaci per prevenire o individuare utilizzi impropri. Una configurazione ritenuta non proporzionata rispetto ai rischi.
Gestione del data breach sotto accusa
Ulteriori criticità sono emerse nella gestione dell’incidente. La notifica del data breach è stata giudicata tardiva e incompleta rispetto agli obblighi normativi. Anche la comunicazione agli interessati è avvenuta in ritardo, solo dopo un intervento del Garante del 2 novembre 2024.
Secondo l’Autorità, questi ritardi hanno compromesso la possibilità di un intervento tempestivo a tutela dei diritti degli utenti coinvolti.
Sanzione e misure correttive
Nel quantificare la sanzione, il Garante ha considerato la gravità e la durata delle violazioni, il numero elevato di clienti coinvolti e la natura dei dati trattati.
È stato tuttavia valutato anche l’intervento successivo della banca, che ha introdotto misure correttive per rafforzare i sistemi di controllo interno e i presidi di sicurezza.
Nonostante ciò, la condotta complessiva è stata ritenuta illecita, portando all’applicazione della sanzione da 31,8 milioni di euro.
Il precedente Isybank: profilazione illecita su 2,4 milioni di clienti
La sanzione si inserisce in un contesto recente già critico per l’istituto. Solo due settimane fa, il Garante privacy aveva inflitto a Intesa Sanpaolo una multa da 17,6 milioni di euro per il trattamento illecito dei dati di circa 2,4 milioni di clienti coinvolti nel trasferimento verso la controllata digitale Isybank. In quel caso, l’Autorità ha accertato una profilazione effettuata senza adeguata base giuridica, utilizzata per selezionare i correntisti da migrare sulla nuova banca sulla base di criteri come età, utilizzo dei canali digitali e disponibilità finanziarie. Un provvedimento che, insieme a quello sul data breach, rafforza il quadro di attenzione del Garante sulle pratiche di gestione e utilizzo dei dati personali nel settore bancario.
Supply chain software, attacco npm PyPI: 454.000 pacchetti malevoli e il primo worm autoreplicante che ha cambiato tutto
Un attacco alla supply chain software attraverso npm e PyPI non è più un’ipotesi accademica: è il meccanismo operativo che nel 2025 ha permesso la distribuzione di oltre 454.000 nuovi pacchetti malevoli nei registri open-source globali. È una cifra che merita di essere ripetuta, perché racconta qualcosa di profondo sulla fragilità strutturale dell’ecosistema su cui poggia la quasi totalità del software moderno.
Ogni volta che uno sviluppatore esegue npm install o pip install, sta dichiarando fiducia implicita in un registro pubblico che non richiede validazione dell’identità del publisher, non verifica la corrispondenza tra nome del pacchetto e contenuto, e – aspetto decisivo – privilegia automaticamente la versione più recente di ogni dipendenza. In un ecosistema dove i download annuali hanno superato i 9,8 trilioni e i componenti open-source costituiscono l’80-90% delle applicazioni moderne, quella fiducia implicita è diventata l’arma più efficiente a disposizione degli attaccanti.
Il 2026 State of the Software Supply Chain Report di Sonatype – pubblicato il 28 gennaio 2026 e basato sull’analisi di oltre 1,233 milioni di pacchetti malevoli cumulativi – documenta un’evoluzione che non è più quantitativa ma qualitativa: il malware nella supply chain software ha adottato la stessa architettura modulare, la stessa logica di riuso e la stessa capacità di scala che rendono potente l’open-source legittimo. Non stiamo più parlando di script rudimentali nascosti in pacchetti oscuri. Stiamo parlando di campagne industrializzate, persistenti, spesso orchestrate da attori statali, che trattano npm e PyPI come canali di distribuzione a basso attrito verso macchine di sviluppo e pipeline CI/CD – ambienti che, per definizione, sono vicini ai dati sensibili e all’accesso di produzione.
Questo articolo analizza i tre eventi che, tra la fine del 2025 e l’inizio del 2026, hanno reso impossibile ignorare la portata del problema: la campagna Lazarus “Graphalgo”, l’attacco “XPACK ATTACK” e – soprattutto – il worm autoreplicante Shai-Hulud, che ha dimostrato che la propagazione autonoma nei registri open-source non è più teoria, ma realtà operativa.
L’anatomia di Graphalgo: come Lazarus ha trasformato un colloquio di lavoro in un trojan multi-stadio
Il 12 febbraio 2026, ReversingLabs ha pubblicato l’analisi dettagliata di una campagna denominata “Graphalgo” – dal nome del primo pacchetto malevolo pubblicato su npm – attribuita con grado di confidenza medio-alto al Lazarus Group nordcoreano. La campagna era attiva dal maggio 2025 e rappresenta un salto qualitativo nelle operazioni di supply chain poisoning condotte da attori statali.
Il meccanismo è sofisticato nella sua semplicità psicologica. Gli attaccanti contattano sviluppatori JavaScript e Python attraverso LinkedIn, Facebook e Reddit, proponendo opportunità lavorative presso “Veltrix Capital” – una società fittizia presentata come operatore blockchain e crypto exchange, completa di domini registrati (veltrixcap[.]org, veltrixcapital[.]ai) e organizzazioni GitHub con repository apparentemente legittimi. Ai candidati viene chiesto di completare un “coding test” come parte del processo di selezione. I repository contengono dipendenze che puntano a pacchetti compromessi su npm e PyPI.
Qui sta il genio tattico: quando la vittima esegue o fa il debug del codice di test, il package manager installa automaticamente le dipendenze malevole. I pacchetti agiscono come loader di primo stadio, scaricando un Remote Access Trojan (RAT) dall’infrastruttura C2 controllata dagli attaccanti. Il RAT è in grado di eseguire comandi arbitrari, caricare e scaricare file, elencare i processi in esecuzione e – dettaglio rivelatore – verificare la presenza dell’estensione browser MetaMask, indicando un interesse specifico per il furto di asset crittografici. Sono state identificate tre varianti del RAT, scritte in JavaScript, Python e Visual Basic Script.
ReversingLabs ha identificato complessivamente 192 pacchetti malevoli in due lotti distinti: quelli con “graph” nel nome (apparsi su npm dal 2 maggio 2025 e su PyPI dal giugno 2025, progettati per mimare librerie legittime come graphlib e networkx) e quelli con “big” nel nome (apparsi su npm dal 17 novembre 2025 e su PyPI dal 9 dicembre 2025, probabilmente collegati a una seconda campagna di facciata ancora non identificata).
L’esempio emblematico è il pacchetto npm bigmathutils: la prima versione, benigna, è stata pubblicata e ha accumulato oltre 10.000 download. Solo a quel punto – quando la fiducia era stata costruita attraverso i numeri – gli attaccanti hanno iniettato il payload malevolo nella versione 1.1.0, pubblicata poco prima dell’11 febbraio 2026. Una strategia di attivazione ritardata che sfrutta la meccanica stessa dell’ecosistema: più download ha un pacchetto, più appare legittimo, più viene installato senza scrutinio.
L’attribuzione a Lazarus si basa su pattern ricorrenti documentati in operazioni precedenti: finti colloqui di lavoro come vettore di contatto iniziale, storie a tema crypto, malware multi-stadio con offuscamento stratificato, infrastruttura C2 protetta da token e – dato forense significativo – timestamp nei commit Git allineati al fuso orario GMT+9, quello della Corea del Nord. La campagna è una ramificazione diretta di operazioni precedenti come VMConnect (PyPI e GitHub) e Contagious Interview, documentate da Socket, Unit 42, Phylum e Veracode.
Il dato strategico: il design modulare di Graphalgo consente a Lazarus di sostituire le “facciate” (Veltrix oggi, un altro nome domani) mantenendo invariata l’infrastruttura backend di payload e C2. Questo significa che altre false aziende, altri pacchetti e altri test di codifica sono non solo probabili, ma inevitabili.
XPACK ATTACK: quando l’installazione diventa estorsione
Lo stesso giorno della divulgazione di Graphalgo, The Hacker News ha riportato la scoperta di una seconda campagna, indipendente da Lazarus ma emblematica dell’evoluzione creativa del malware nella supply chain. Denominata “XPACK ATTACK” da OpenSourceMalware e registrata per la prima volta il 4 febbraio 2026, questa operazione rappresenta un modello di monetizzazione completamente inedito: l’estorsione diretta durante l’installazione del pacchetto npm.
I pacchetti, tutti caricati dall’utente “dev.chandra_bose”, abusano del codice di stato HTTP 402 (“Payment Required”) per creare quello che appare come un legittimo paywall. Come ha spiegato il ricercatore Paul McCarty, l’attacco blocca l’installazione fino a quando la vittima non paga 0,1 USDC/ETH al wallet dell’attaccante, raccogliendo nel frattempo username GitHub e fingerprint del dispositivo. Se la vittima rifiuta di pagare, l’installazione fallisce dopo oltre cinque minuti – e lo sviluppatore potrebbe non rendersi nemmeno conto di aver incontrato malware piuttosto che un legittimo sistema di licensing.
XPACK ATTACK è significativo non per la sua scala (modesta) ma per il precedente concettuale che stabilisce: la monetizzazione del malware open-source non richiede più l’esfiltrazione di credenziali, l’installazione di backdoor o il deployment di ransomware. Può avvenire direttamente nell’atto stesso dell’installazione, sfruttando un meccanismo HTTP standardizzato che conferisce un’aura di legittimità tecnica all’estorsione.
Shai-Hulud: il worm che ha dimostrato che la propagazione autonoma è possibile
Se Graphalgo rappresenta la sofisticazione dello state-sponsored supply chain attack e XPACK ATTACK l’innovazione nel modello di monetizzazione, il worm Shai-Hulud è l’evento che ha ridefinito il perimetro della minaccia. Identificato per la prima volta il 15 settembre 2025 da ReversingLabs e oggetto di un advisory dedicato della CISA, Shai-Hulud è il primo malware autoreplicante nell’ecosistema npm – un worm che si propaga sfruttando le credenziali dei maintainer compromessi per pubblicare versioni avvelenate dei pacchetti che questi mantengono, creando una catena di infezione esponenziale senza intervento umano diretto.
Il meccanismo di propagazione è elegante nella sua brutalità. Una volta installato attraverso un pacchetto compromesso, il worm esegue discovery del sistema locale utilizzando TruffleHog – un tool legittimo di scansione segreti capace di identificare oltre 800 tipi diversi di credenziali – alla ricerca di token GitHub, NPM, chiavi AWS, GCP e Azure; esfiltra le credenziali raccolte verso un endpoint controllato dall’attaccante; crea un repository pubblico GitHub denominato “Shai-Hulud” sotto l’account della vittima, pubblicando i segreti rubati; utilizza i token npm rubati per autenticarsi nel registro come lo sviluppatore compromesso; identifica gli altri pacchetti mantenuti dallo stesso sviluppatore, inietta codice malevolo e pubblica versioni compromesse – permettendo al worm di propagarsi ai downstream user di quei pacchetti.
Il “paziente zero” identificato è il pacchetto rxnt-authentication versione 0.0.3, pubblicato il 14 settembre 2025. Da quel punto, la CISA ha confermato la compromissione di oltre 500 pacchetti. Ma è la seconda ondata, denominata “Shai-Hulud 2.0” e individuata nel novembre 2025, ad aver mostrato la vera portata della minaccia: 795 pacchetti compromessi, molti dei quali ampiamente utilizzati. Il pacchetto @asyncapi/specs, ritenuto il “paziente zero” di questa seconda ondata, contava da solo oltre 100 milioni di download lifetime. Complessivamente, i pacchetti compromessi – tra cui quelli di progetti come AsyncAPI, Zapier, PostHog e Postman – totalizzavano decine di milioni di download settimanali.
Shai-Hulud 2.0 ha introdotto diverse innovazioni rispetto alla prima variante. L’esecuzione del codice malevolo avviene nella fase preinstall anziché postinstall, ampliando drammaticamente la superficie d’impatto perché il malware si attiva prima che qualsiasi test o controllo di sicurezza possa intervenire. Il worm può infettare fino a 100 pacchetti npm (contro i 20 della prima versione). E, dettaglio particolarmente aggressivo, se non riesce né a replicarsi né a esfiltrare dati, tenta di cancellare la directory home dell’utente.
La tecnica di esfiltrazione ha introdotto il concetto di “cross-victim exfiltration”, documentato da Datadog Security Labs: le credenziali di una vittima vengono pubblicate in un repository GitHub associato a una vittima diversa e non correlata. Questo significa che cercare nei propri repository potrebbe non rivelare i dati esfiltrati dal proprio ambiente. Se il malware non trova credenziali GitHub disponibili localmente, cerca proattivamente su GitHub i repository di esfiltrazione creati da altre vittime e tenta di utilizzare i token compromessi di queste ultime per continuare la propagazione.
La risposta è stata significativa. Microsoft ha pubblicato una guida dettagliata per la detection e l’investigazione, introducendo una nuova funzionalità in Microsoft Defender for Cloud basata su agentless code scanning per identificare i pacchetti Shai-Hulud 2.0 tramite SBOM. Palo Alto Networks Unit 42 ha fornito un’analisi tecnica approfondita con regole di detection. GitHub, che mantiene il registro npm, ha introdotto nuove misure di hardening: 2FA obbligatorio per tutte le pubblicazioni locali, limitazione della durata dei token a sette giorni, revoca dei classic token dal 9 dicembre 2025, e promozione del trusted publishing – un approccio pionierato da PyPI che rimuove i token API dalle pipeline di build.
La scala industriale: numeri che raccontano una mutazione
I tre eventi descritti non sono anomalie. Sono manifestazioni di una tendenza strutturale documentata dal report Sonatype 2026 con una granularità senza precedenti: 454.648 nuovi pacchetti malevoli identificati nel solo 2025, che portano il totale cumulativo a 1,233 milioni. La crescita anno su anno è del 75%.
Il dato più significativo non è la quantità ma la distribuzione: oltre il 99% del malware open-source si concentra su npm. Non è casuale. npm è il registro più grande al mondo, con il maggior volume di download, la minore frizione nella pubblicazione e – crucialmente – nessun requisito di validazione del namespace. Un attaccante può pubblicare un pacchetto con qualsiasi nome, e il tooling dell’ecosistema tende a preferire la versione più recente di ogni dipendenza. È una combinazione di fattori che rende l’avvelenamento strutturalmente facile.
Il 55,9% di tutti i pacchetti malevoli registrati nel 2025 è classificato come “repository abuse”: gli attori trattano i registri come piattaforme, automatizzando la pubblicazione e iterando rapidamente per massimizzare la copertura. Il 27,5% rientra nella categoria “Potentially Unwanted Application” – pacchetti vuoti, demo con credenziali hardcoded, framework per bot di spam su messaging app. Ma il restante è malware operativo: dropper, infostealer, RAT, cryptominer, credential harvester.
L’attore più prolifico è il Lazarus Group, che secondo Sonatype ha individuato oltre 800 pacchetti associati a Lazarus nel 2025, evolvendosi da semplici dropper e cryptominer a catene di payload a cinque stadi che combinano dropper, furto credenziali e accesso remoto persistente. Solo nel primo semestre 2025, Sonatype ha bloccato 234 pacchetti npm e PyPI malevoli attribuiti a Lazarus, stimando fino a 36.000 vittime potenziali.
La campagna IndonesianFoods, scoperta nel novembre 2025, ha aggiunto un’altra dimensione: oltre 150.000 pacchetti pubblicati da un sistema automatizzato che genera un nuovo pacchetto ogni pochi secondi. La campagna, attiva da oltre due anni prima di essere individuata, sfruttava il protocollo TEA per monetizzare attraverso token blockchain le metriche di impatto artificialmente gonfiate.
È importante precisare che, a differenza di Shai-Hulud, il meccanismo di propagazione di IndonesianFoods richiede esecuzione manuale e non costituisce un worm nel senso stretto del termine, come evidenziato da Socket.dev. Tuttavia, la scala dell’operazione resta impressionante. Come ha osservato Garrett Calpouzos di Sonatype, dopo GlassWorm e l’hijack di chalk/debug, IndonesianFoods è l’iterazione successiva dello stesso playbook: ogni ondata di attacchi trasforma l’apertura di npm in un’arma leggermente diversa.
Perché il modello di fiducia dell’open-source è strutturalmente rotto
C’è un paradosso al centro di questa crisi che merita di essere esplicitato: le stesse caratteristiche che rendono l’open-source potente – apertura, riusabilità, distribuzione frictionless – sono esattamente quelle che lo rendono vulnerabile. npm non è stato progettato come sistema di distribuzione di software con garanzie di sicurezza. È stato progettato come commons collaborativo. La fiducia non è un meccanismo di sicurezza verificabile: è un’assunzione sociale.
Il modello di minaccia tradizionale per la supply chain software presupponeva che l’attaccante dovesse compromettere un sistema di build, alterare un artefatto firmato, o sfruttare una vulnerabilità in un componente legittimo. Quello che il 2025 ha dimostrato è che nulla di tutto questo è necessario. Basta pubblicare un pacchetto con un nome plausibile, accumulare download (o acquistarli), e attendere che il tooling di milioni di sviluppatori lo installi automaticamente come dipendenza transitiva.
Il report Sonatype documenta un ulteriore livello di rischio: lo sviluppo assistito da AI amplifica il problema. Analizzando quasi 37.000 upgrade di dipendenze assistiti da LLM, Sonatype ha riscontrato che circa il 28% erano allucinazioni – versioni inesistenti di pacchetti. In alcuni casi, gli LLM hanno suggerito l’installazione di pacchetti effettivamente malevoli. Senza intelligence verificata in tempo reale, l’AI non corregge i dati cattivi: li distribuisce più velocemente.
Le contromisure: dalla fiducia implicita alla verifica operativa
La fine della fiducia implicita nei registri pubblici non è una catastrofe: è un momento di maturazione. Ma richiede un cambio di paradigma operativo che va oltre il singolo strumento. Ecco le contromisure che, sulla base dell’evidenza raccolta, hanno dimostrato efficacia concreta.
Software Bill of Materials (SBOM) come prerequisito – L’SBOM non è più un nice-to-have regolatorio: è l’unico modo per avere visibilità su cosa effettivamente risiede nell’ambiente di build. Microsoft ha introdotto la generazione SBOM agentless in Defender for Cloud specificamente per identificare i pacchetti Shai-Hulud 2.0 – dimostrando che senza un inventario delle dipendenze leggibile da macchina, la detection è cieca. Il Cyber Resilience Act europeo e l’AI Act stanno convergendo sulla richiesta di prova di provenienza, contenuto e controllo lungo l’intero ciclo di vita del software.
Repository firewall e policy di lockfile – Un repository firewall agisce come proxy tra l’ambiente di build e il registro pubblico, bloccando pacchetti noti come malevoli e applicando policy di approvazione prima che qualsiasi pacchetto entri nella pipeline. La policy di lockfile (package-lock.json per npm, Pipfile.lock per Python) impedisce che il tooling risolva automaticamente alla versione più recente, neutralizzando il vettore della delayed malicious update sfruttato da Graphalgo.
Trusted publishing e token hygiene – Dopo Shai-Hulud, GitHub ha imposto 2FA obbligatorio per le pubblicazioni npm locali, limitato la durata dei token a sette giorni e revocato i classic token dal 9 dicembre 2025. Il modello di trusted publishing, già adottato da PyPI, rimuove i token API dalle pipeline di build sostituendoli con attestazioni verificabili legate al provider CI/CD. Ogni organizzazione che pubblica pacchetti su npm dovrebbe adottare questo modello come standard minimo.
Dependency cooldown e binary analysis – I pacchetti malevoli nella supply chain software si eseguono durante l’installazione, prima ancora che il codice venga compilato o testato. Un approccio emergente, adottato da Elastic dopo l’incidente Shai-Hulud 2.0, prevede un periodo di “cooldown” (14 giorni nel caso di Elastic) durante il quale le nuove versioni dei pacchetti non vengono automaticamente adottate, permettendo alla comunità di individuare eventuali compromissioni. L’analisi binaria dei pacchetti e il monitoraggio runtime delle connessioni di rete anomale durante l’installazione sono complementi necessari allo scanning statico del codice.
Separazione degli ambienti e least privilege – Le macchine di sviluppo e gli agenti CI/CD non dovrebbero mai avere accesso diretto a credenziali di produzione, token cloud o segreti critici. Shai-Hulud ha dimostrato che un singolo pacchetto compromesso può raccogliere token GitHub, npm, AWS, GCP e Azure dalla stessa macchina. La segmentazione degli ambienti e il principio di least privilege per le pipeline di build non sono best practice opzionali: sono l’unica barriera tra un’infezione locale e una compromissione dell’infrastruttura cloud.
Il quadro normativo: NIS2, CRA e la responsabilità della supply chain
L’evoluzione normativa europea sta convergendo sulla supply chain software come area di responsabilità esplicita. La direttiva NIS2 (Direttiva UE 2022/2555) richiede alle entità essenziali e importanti di gestire i rischi della catena di approvvigionamento digitale, inclusa la verifica delle pratiche di sicurezza dei fornitori di software. Il Cyber Resilience Act (Regolamento UE 2024/2847), entrato in vigore il 10 dicembre 2024, impone ai produttori di prodotti con elementi digitali di garantire la sicurezza del software lungo l’intero ciclo di vita, incluse le dipendenze open-source. Gli obblighi principali saranno applicabili da dicembre 2027, con quelli relativi alla gestione delle vulnerabilità e alla segnalazione degli incidenti in vigore già da settembre 2026.
Questo significa che un’organizzazione europea che subisce una compromissione attraverso un pacchetto npm malevolo non può più invocare l’imprevedibilità dell’attacco come attenuante. La due diligence sulla supply chain software – SBOM, scansione delle dipendenze, policy di approvazione dei pacchetti – è diventata un obbligo di compliance, non una raccomandazione di best practice.
Prospettive: cosa aspettarsi nei prossimi 12 mesi
La traiettoria è chiara e il suo prossimo punto di accelerazione è identificabile. L’avvelenamento della supply chain software diventerà più sofisticato lungo tre direttrici convergenti.
La prima è l’integrazione con l’ingegneria sociale avanzata. Graphalgo ha dimostrato che il vettore “fake recruiter” è devastantemente efficace perché sfrutta la legittima aspirazione professionale degli sviluppatori. Varianti future sostituiranno le finte aziende crypto con finte aziende AI, finti progetti open-source alla ricerca di contributori, finte conferenze con “workshop pre-evento” che richiedono l’installazione di dipendenze compromesse.
La seconda è la propagazione autonoma. Shai-Hulud ha dimostrato il principio; le varianti successive saranno più silenziose, più selettive e più difficili da rilevare. Un primo segnale è già arrivato: il 20 febbraio 2026, Socket ha identificato SANDWORM_MODE, un nuovo worm stile Shai-Hulud che aggiunge capacità di prompt injection nei coding assistant AI, posizionandosi all’interno sia delle pipeline CI che degli strumenti di sviluppo. Un worm che compromette solo pacchetti con download settimanali superiori a una soglia, che attende settimane prima di attivare il payload, e che esfiltra attraverso canali legittimi (webhook GitHub, API cloud native) potrebbe propagarsi per mesi prima di essere individuato.
La terza è il targeting dei modelli AI e dei sistemi agentic. Sonatype documenta già la presenza di payload malevoli nascosti in modelli AI e container image su piattaforme come Hugging Face. Con l’adozione dei Model Context Protocol (MCP) server e degli agenti AI autonomi che installano dipendenze senza supervisione umana, la superficie d’attacco della supply chain software si sta espandendo verso un territorio dove la velocità dell’infezione potrebbe superare la velocità della detection.
Conclusione: la supply chain software come campo di battaglia permanente
L’attacco alla supply chain software attraverso npm e PyPI non è un’emergenza temporanea da gestire con una patch: è una condizione permanente dell’ecosistema digitale moderno. I 454.648 pacchetti malevoli del 2025, il worm autoreplicante Shai-Hulud, la campagna state-sponsored Graphalgo e l’innovazione estorsiva di XPACK ATTACK sono manifestazioni diverse dello stesso fenomeno strutturale: la fiducia implicita nei registri pubblici open-source è diventata il punto di ingresso più efficiente per gli attaccanti, dagli adolescenti opportunisti agli apparati di intelligence statali.
La risposta non può essere la rinuncia all’open-source – sarebbe come rinunciare all’elettricità perché i fulmini esistono. Ma richiede l’abbandono definitivo dell’approccio “install and trust” a favore di un modello “verify then install”: SBOM operativi, repository firewall, lockfile rigorosi, trusted publishing, segmentazione degli ambienti, monitoraggio runtime. Non come aspirazione, ma come standard operativo quotidiano.
Il report Sonatype 2026 chiude con un’osservazione che vale come monito: il pacchetto malevolo non è più l’intero attacco, ma il primo passo di un’intrusione supply chain più ampia. Per ogni organizzazione che costruisce software – cioè, nel 2026, praticamente ogni organizzazione – il rischio della supply chain software non è un rischio da delegare ai developer: è un rischio da governare al livello del board.
Users hate it, but age-check tech is coming. Here’s how it works.
That initiative, which has maintained a low profile until recently, has scored two big wins. First, Meta announced in December that it would launch age keys on Instagram this year. The Free Speech Coalition, a nonprofit trade association for the adult entertainment industry, has also endorsed age keys as a privacy-preserving way to access pornographic material without compromising identity or security.
Although Privately partners with k-ID on age checks for social and gaming platforms, Privately has not joined the OpenAge Initiative. However, other leading age-check providers have signed on, including Incode, Persona, Socure, and Veratad, as well as platform owners like Meta and game developers like Konami.
K-ID’s corporate affairs officer, Luc Delany, told Ars that age keys are stored in a password manager and are built on FIDO passkey technology that’s “as secure as the login that I use for my bank.”
For users accustomed to storing passwords, letting their devices store an age key may feel natural, especially since it doesn’t require opening an account or sharing an email address. Julian Corbett, the head of the OpenAge Initiative and a co-founder of k-ID, told Ars that some platforms have seen higher adoption of the tech than expected. On one platform that recently launched age keys, for example, about 80 percent of users chose to save them, he said.
For platforms, age keys could become a cost-effective solution. Because the only cost to the OpenAge Initiative is an encrypted handshake when the age signal is shared, platforms could perform “a million age checks using age keys for $3,000,” Delany said.
Participating platforms can set limits on which types of age estimation are accepted and how recently the age check must have been completed. Any age keys lacking the right signals will be rejected.
The OpenAge Initiative’s website provides more details, including developer guides explaining how its double-blind system is designed to protect privacy. Essentially, when someone uses an age key, the age-check service provider requests access to the platform without knowing who the user is. Meanwhile, the OpenAge Initiative knows who the user is but doesn’t know which platform is receiving the age signal. The age check provider ultimately decides “yes” or “no,” granting or denying platform access.
Data Breach sanitari: minacce informatiche e protezione dati personali nel sistema sanitario italiano
Questo articolo fa parte di una serie dedicata all’analisi approfondita della cybercriminalità nel settore sanitario italiano. In questa sezione esamineremo il fenomeno dei data breach sanitari e la loro crescente incidenza nelle strutture sanitarie, analizzando l’evoluzione del concetto di privacy dalla tradizionale riservatezza alla moderna protezione dei dati personali sotto il GDPR.
Crescente rischio dei data breach sanitari e impatto economico della cybercriminalità
Con le seguenti allarmanti parole si avvia la prefazione del tradizionale rapporto CLUSIT 2020 sulla sicurezza ICT[1] in Italia:
Nell’anno appena passato si è consolidata una discontinuità, si è oltrepassato un punto di non ritorno, tale per cui ormai ci troviamo a vivere ed operare in una dimensione differente, in una nuova epoca, in un altro mondo, del quale ancora non conosciamo bene la geografia, gli abitanti, le regole e le minacce”. La convinzione, prosegue il Rapporto, è che sia avvenuto “un vero e proprio cambiamento epocale nei livelli di cyber-insicurezza, causato dall’evoluzione rapidissima degli attori, delle modalità, della pervasività e dell’efficacia degli attacchi.[2]
Il quadro così delineato dal rapporto Clusit va a destrutturare quella convinzione di cybersecurity fin troppo spesso associata a “realtà suggestive” (o fantascientifiche), distanti dalla vita di tutti i giorni, nonché appannaggio dei soli protagonisti della governance statale ed internazionale.
In una comunicazione congiunta, del 13 Settembre 2017, al Parlamento Europeo e al Consiglio traspare, con nitidezza, come i rischi cibernetici stiano aumentando in maniera esponenziale: “Secondo alcuni studi l’impatto economico della cybercriminalità è aumentato di cinque volte tra il 2013 e il 2017 e potrebbe ancora quadruplicarsi entro il 2019. […] Se non miglioreremo sostanzialmente la nostra cybersicurezza il rischio aumenterà in funzione della trasformazione digitale.” Dunque è senza dubbio diventato fondamentale rafforzare una cyber-resilienza attraverso “un solido mercato unico, importanti progressi nella capacità tecnologica nell’Unione e un numero molto più elevato di esperti qualificati”.[3]
Allora il fine che si è indirizzati a perseguire è proprio una accettazione più ampia del fatto che la cybersicurezza rappresenti una sfida sociale comune, motivo per cui dovrebbero essere coinvolti, in ottica di risposta, molteplici livelli: dell’amministrazione pubblica, dell’economia e della società.
Ovvio è come, in tale contesto, alcuni ambiti specifici debbano affrontare altrettanto specifiche problematiche, che impongono una integrazione delle strategie di cybersecurity di carattere generale con quelle di tipo settoriale: ed uno dei settori specifici che, negli ultimi decenni, più di altri ha subito notevoli trasformazioni, con un progressivo utilizzo di nuove tecnologie è proprio quello sanitario.
Il mercato sanitario invero si figura sempre più attenzionato da parte dei c.d. Tech Giants (Google, Amazon, Walmart etc.), i quali promettono di rivoluzionarne le tradizionali modalità di assistenza sanitaria attraverso una digitalizzazione dei servizi e una disintermediazione degli stessi rispetto agli erogatori tradizionali.
Il settore sanitario è presto diventato così un banco di prova paradigmatico per nuove ed ardue questioni, poste innanzitutto ai giuristi, in ragione specialmente della straordinaria mole di dati accumulati, della articolata complessità dei rapporti giuridici che vi si instaurano, nonché della esigenza di garantire il più alto livello possibile di sicurezza e privacy.[4]
Prima di procedere alla disamina delle principali condotte di cyber-criminalità che colpiscono l’healthcare system, si vuole qui fornire una panoramica sulla gravità e pericolosità degli attacchi, in quanto impattanti su un settore altamente vulnerabile: come si può intuire infatti c’è un legame diretto tra gli attacchi informatici subiti dalle strutture sanitarie e le condizioni dei pazienti che si affidano alle loro cure.
A tal fine si richiama il recente report condotto da Ponemon Institute, una delle principali organizzazioni di ricerca sulla sicurezza informatica, in unione con Proofpoint, società leader nel settore della cybersecurity e compliance, dal titolo “Cyber Insecurity in Healthcare: The Cost and Impact on Patient Safety and Care”.[5]
Lo studio vede coinvolti 641 professionisti dell’It (Information technology) quali responsabili, nonché partecipanti all’elaborazione di strategie di sicurezza informatica sanitaria, e fin da subito pone in marcata evidenza come l’89% delle organizzazioni intervistate dichiari di aver subito una media di 43 attacchi negli ultimi 12 mesi, quasi uno a settimana.
Si continua poi andando a delineare i quattro tipi di attacchi più comuni: la compromissione del cloud, l’attacco ransomware, alla supply chain[6], ancora la compromissione delle e-mail aziendali/ spoofing[7] ed il phishing[8].
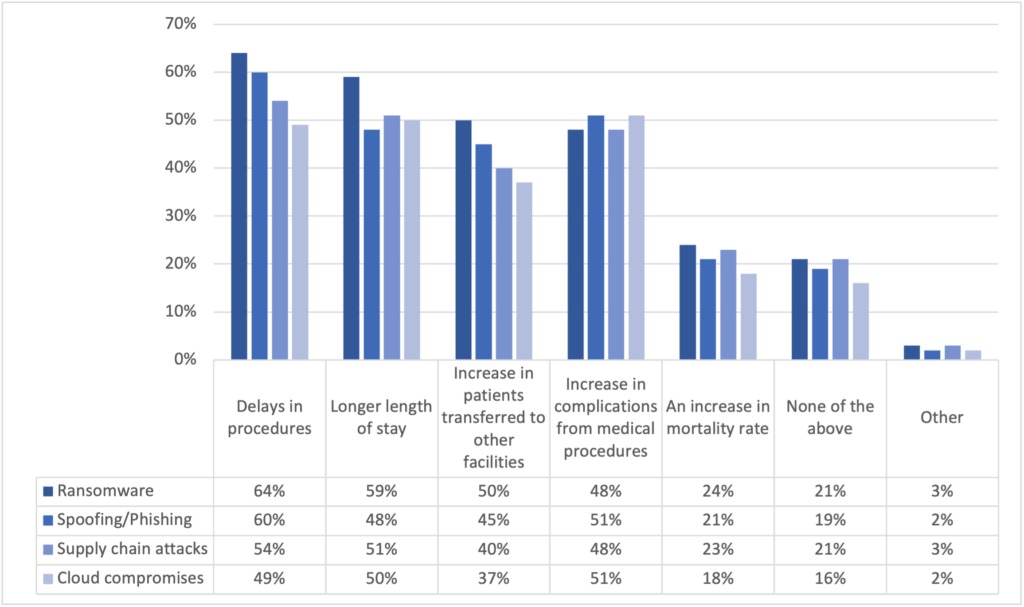
Ecco che tali attacchi vengono messi in relazione con le loro dirette conseguenze verificatesi in sanità: da ritardi nelle procedure e negli esami, alla degenza più lunga dei pazienti, ad un loro progressivo trasferimento in altre strutture sanitarie, al sorgere di maggiori complicazioni nel fornire prestazioni sanitarie, fino ad un incremento dei tassi di mortalità.[9]
Così difatti recita il quesito formulato nel report, con l’ovvia possibilità per gli intervistati di apporre più di una risposta: “Se la tua organizzazione ha subito queste tipologie di attacchi informatici, quale impatto hanno avuto sulla cura dei pazienti?”.
Fig. 4.1 Elaborazione dati Ponemon Report: cyberattacchi – conseguenze sanitarie.
Si è voluto innanzi graficamente rappresentare i dati raccolti (Figura 4.1) al fine di poter constatare come l’attacco ransomware rimanga a tutti gli effetti una sfida significativa: è difatti la tipologia di attacco informatico con la maggiore probabilità di influire sulla cura dei pazienti rispetto alle altre tipologie malevoli (il 64% delle aziende colpite da ransomware ha registrato ritardi nelle procedure mediche e quasi altrettante hanno visto prolungare le degenze dei pazienti).
Tali risultati rimarcano come le organizzazioni sanitarie dovrebbero dare maggiore priorità alla sicurezza IT, in questo senso commenta Larry Ponemon, presidente e fondatore di Ponemon Institute: “Gli attacchi che abbiamo analizzato mettono a dura prova le risorse delle organizzazioni sanitarie. Il risultato non è solo una enorme perdita economica, ma anche un impatto diretto sull’assistenza ai pazienti, che mette in allarmante pericolo la loro sicurezza e salute”.
A seguire si riportano altri risultati chiave emersi dal report:[10]
a) Dispositivi medici e mobile apps rimangono una delle principali preoccupazioni in tema di cybersicurezza. A tal proposito si usa l’espressione di Internet of Medical Things (IoMT) per indicare tutti i devices medici, di varia natura, collegati ad una struttura o ad un operatore sanitario tramite internet, in grado di generare, raccogliere, analizzare e trasmettere dati sanitari (si pensi a dispositivi indossabili, strumenti per il monitoraggio remoto dei pazienti, pompe di infusione, pacemakers).
Le organizzazioni sanitarie hanno in media più di 26.000 dispositivi connessi alla rete: sebbene il 64% degli intervistati si sia dichiarato preoccupato per la sicurezza inerente a tali devices medici, solamente il 51% di questi afferma che la propria organizzazione si sia effettivamente provvista di strategie di sicurezza informatica di prevenzione e risposta a possibili attacchi contro tali dispositivi.
b) Le organizzazioni si sentono al contempo più vulnerabili e più preparate alla compromissione del cloud: il 75% degli intervistati si dichiara difatti vulnerabile verso tali tipologie di attacchi e il 54% afferma di averne subito almeno uno negli ultimi due anni (le organizzazioni ricomprese in quest’ultimo gruppo arrivano a sostenere una media di 22 compromissioni negli ultimi due anni). Tuttavia, oltre ad essere più vulnerabili, si dichiarano anche maggiormente preparate ad affrontare tali minacce, con il 63% che dichiara di aver optato per l’adozione di misure specifiche al fine di esser preparati nel rispondere a simili cyberattacchi.
c) Il ransomware è la seconda più sentita vulnerabilità con il 72% degli intervistati che ritiene la propria organizzazione esposta a tale cyber-rischio, e con il 60% che sostiene come sia effettivamente la tipologia di attracco che desta maggiori preoccupazioni. Negli ultimi due anni le organizzazioni che sono state sottoposte ad attacchi ransomware (41% degli intervistati), hanno subito una media di tre di questi attacchi.
d) La mancanza di preparazione mette a rischio tanto le organizzazioni sanitarie quanto i pazienti stessi. Meno della metà degli intervistati dichiara di avere effettivamente una strategia documentata da seguire per gli attacchi spoofing/phishing (48%), e ugualmente per gli attacchi alla supply chain (44%).
e) I programmi di formazione e sensibilizzazione al cyber-rischio, insieme al monitoraggio dei dipendenti, rappresentano una delle principali strategie per mitigare le minacce informatiche: solo però il 59% degli intervistati ha dichiarato che la propria organizzazione stia affrontando concretamente il problema della mancanza di cyber-consapevolezza tramite o l’adozione di programmi di training per i dipendenti o monitorando il loro stesso operato.
f) La mancanza di competenze interne, fondi e risorse mettono anch’essi a dura prova la sicurezza informatica complessiva: il 53% degli intervistati sostiene di soffrire la mancanza di competenze interne specializzate e il 46% afferma come il personale lavorativo risulti insufficiente.
g) I cyberattacchi provocano enormi costi. È stato chiesto agli intervistati di stimare il singolo attacco informatico più dannoso subito negli ultimi 12 mesi: sulla base delle risposte ottenute, il costo totale medio per l’attacco informatico più dannoso è stato di 4.4 milioni di dollari, con una perdita di produttività quale conseguenza finanziaria di circa 1.1 milioni di dollari.
Da tale studio si è ricavata l’urgente necessità di investire nella cyber security: si è visto chiaramente come una scarsa protezione IT possa avere effetti assolutamente profondi e tangibili tanto sulla struttura sanitaria quanto sui pazienti. Purtroppo ancora oggi gli investimenti in termini di sicurezza vengono visti unicamente come costi e per questo spesso limitati il più possibile; se invece ci si rendesse conto che si tratta di veri e propri investimenti dotati di un loro ritorno in diminuzione dei rischi, molti incidenti potrebbero essere fortemente limitati se non evitati, assieme ad un ingente risparmio sia di tempo che di denaro.[11]
Così conclude commentando Ryan Witt, healthcare cybersecurity leader di Proofpoint: “L’assistenza sanitaria è rimasta indietro rispetto ad altri settori nell’affrontare il crescente numero di attacchi informatici, e questa immobilità impatta negativamente sulla sicurezza e sul benessere dei pazienti. […]
Finché la sicurezza informatica rimarrà una priorità di basso livello, gli operatori sanitari continueranno a mettere in pericolo i loro stessi pazienti. Per evitare conseguenze drammatiche, le organizzazioni sanitarie devono allora comprendere come la cybersecurity influisca sull’assistenza ai pazienti e mettere in atto i passi necessari per proteggere al meglio le persone e i loro dati”.
Ed è proprio di dati che nel diretto prosieguo si tratterà, o meglio, delle loro sempre più frequenti illecite violazioni, divulgazioni, perdite e compromissioni, anche conosciute col nome di Data breaches.
Data breach
Nuova frontiera della privacy: la protezione dei dati personali
La nozione di privacy trova una sua primordiale accezione nel “right to be alone”[12] teorizzato dai due giuristi statunitensi Warrein e Brandeis nel 1890, traducendosi nel diritto dei singoli alla riservatezza: uno spazio della vita, quasi fisico, da cui il soggetto aveva diritto di tenere esclusi gli altri, a loro volta doverosi di rispettarne l’individualità, una sorta di “tutela dell’intimità privata”.[13]
Sin da subito si può constatare come esso si presenti quale diritto a contenuto essenzialmente negativo, comprendente il non subire ingerenze, il non far conoscere e il mantenere riservate alcune informazioni, piuttosto che a contenuto positivo, che viceversa si avrebbe con l’esercitare un effettivo controllo sulle informazioni medesime.
La definizione di privacy innanzi prospettata appare però, oramai da qualche decennio, non più perfettamente corrispondente alle trasformazioni socio-economiche subite dalla società, soprattutto alla luce della sua preponderante digitalizzazione. Per chiarire, con l’avvento della stagione degli elaboratori elettronici e con l’introduzione della ragnatela del web, la circolazione dei dati personali è divenuta indubbiamente regola fisiologica della società: una società per l’appunto denominata “dell’informazione e della comunicazione”.
Ecco che allora la diffusione e l’utilizzo delle nuove tecnologie e delle reti informatiche hanno prodotto un mutamento semantico del concetto di tutela della privacy: nata come diritto dell’individuo borghese a escludere gli altri da ogni forma di invasione della propria sfera privata (“my home, my castle”), si è sempre più strutturata come diritto di ogni persona al mantenimento del controllo sui propri dati, ovunque essi su trovino, riflettendo così il nuovo contesto in cui ogni persona cede continuamente e nelle forme più diverse dati che la riguardano.[14]
Di qui alcuni studiosi sono arrivati a formulare il cosiddetto “privacy paradox”:[15] le condotte di condivisione di informazioni (si pensi all’uso dei social networks) non sempre implicano anche la consapevolezza da parte degli utenti della divulgazione che i propri dati possono avere. A tal proposito asserisce Antonello Soro, Presidente dell’autorità Garante per la protezione dei dati personali: “Poiché i dati rappresentano la proiezione digitale delle nostre persone, aumenta in modo esponenziale anche la nostra vulnerabilità. La libertà di ciascuno è insidiata da forme sottili e pervasive di controllo, che noi stessi, più o meno consapevolmente, alimentiamo per l’incontenibile desiderio di continua connessione e condivisione”.[16]
D’altronde mentre la violazione di altri diritti fondamentali quali libertà personale, integrità personale, libertà di parola, si risolve più frequentemente in fatti e comportamenti visibili, spesso la violazione del diritto alla riservatezza si risolve in fatti e comportamenti di più difficile percezione, ma ugualmente di estrema gravità. E tale percettibilità delle violazioni è ancora minore in Internet rispetto alla vita reale. Per esser chiari, si voglia fornire un’ esemplificazione.
Se ad un individuo che entrasse in un negozio fosse sfilato il portadocumenti al fine di copiare l’indirizzo di casa e spedire continuamente materiale pubblicitario mirato, o per controllare le ricevute della carta di credito dalle quali ricavare ciò che l’individuo ha comprato nelle settimane precedenti, o ancora per ricavare dalle diverse tessere di cui è in possesso il suo orientamento politico, sindacale ed i suoi interessi sociali, tale soggetto si sentirebbe di certo profondamente leso dall’aver subito grave abuso.
Questo ed altro avviene in rete, e non vi è reazione lontanamente avvicinabile.[17]
Ora, tornando all’evolvere del concetto di privacy, a fronte quindi di un individuo messo a nudo, nella sua intimità, da una tecnologia sempre più invasiva (che è legata al polso da un orologio smart, che entra nelle case con una televisione di ultima generazione, che segue gli spostamenti in auto attraverso l’utilizzo di sensori connessi ad internet), la privacy segue un mutamento di rotta, finendo per essere ridefinita nella più comprensiva nozione di “protezione dei dati”, concetto che va ben oltre ai problemi legati alla difesa della sfera privata, abbracciando regole generali sulla circolazione delle informazioni.[18]
Il diritto alla protezione dei dati personali può essere definito come il diritto a che le informazioni su una persona fisica individuata o individuabile siano raccolte e trattate in modo lecito: esso consiste dunque nel diritto del soggetto cui i dati si riferiscono di esercitare un controllo, anche attivo, su detti dati, che si estende dall’accesso alla loro rettifica.[19]
Si qualifica allora come un diritto proprio di ogni soggetto ad autodefinirsi e determinarsi, dal contenuto fortemente positivo, consistente nell’esercitare un controllo effettivo sul flusso delle proprie informazioni, distinguendosi dalla mera riservatezza quale libertà negativa di non subire interferenze.
Con l’entrata in vigore del GDPR, e la consequenziale modifica al Codice della Privacy intervenuta con d.lgs. 10 Agosto 2018, n. 101, ha trovato allora finalmente realizzazione nell’ordinamento italiano quel microsistema autonomo basato sul riconoscimento di un nuovo bene giuridico di settore: il trattamento dei dati personali, su cui peraltro svariati cenni sono già stati fatti nel discorrere del secondo capitolo, a cui si rimanda.
Si consideri comunque che la stessa giurisprudenza europea condivideva il bisogno di mutare l’approccio consolidatosi negli anni precedenti, basato su di una statica tutela della riservatezza. La Corte di Lussemburgo, infatti, aveva più volte evocato il concetto di “sovranità digitale”, allo scopo di indurre i legislatori nazionali a prendere in debita ed attenta considerazione l’esistenza di un nuovo ordinamento giuridico, l’ordinamento digitale, inteso come spazio immateriale in cui confluiscono e vengono trattati dati personali digitali.
Architravi della nuova disciplina risultano essere i fondamentali principi del consenso e di accountability che, si voglia ripetere anche in questa sede, consiste nella responsabilizzazione di chi è titolato a trattare i dati, cui viene imposta, tramite l’ordine di rendicontazione, una gestione idonea a garantire la piena conformità del trattamento ai principi sanciti dal Regolamento Ue e dalla legislazione interna.[20]
Pare, tuttavia, che l’evoluzione legislativa si sia qualitativamente arrestata, nonostante i proclami in materia di prossime regolamentazioni[21] e nonostante l’approvazione del GDPR: il diritto alla protezione dei dati personali, per come oggi regolamentato, si appalesa anacronistico.
Rimane infatti un diritto che affonda le proprie radici nella società degli anni Settanta, che si apprestava a diventare la Società dell’informazione, un mondo ad oggi profondamente mutato: il dato è sempre meno controllabile, fra Big Data[22] e sistemi in cloud, o comunque sostanzialmente inaccessibile a chi dovrebbe sorvegliare l’applicazione della normativa.
Se da un lato le tecnologie che plasmano la società avanzano ad un ritmo impressionante, dall’altro gli strumenti di protezione effettiva diventano sempre più obsoleti, senza tuttavia essere aggiornati o rimpiazzati, il che causerà conseguenze particolarmente gravi nei settori a maggior rischio, come quello della salute.[23]
Ai fini della trattazione, ciò che è fin qui stato detto nel discorrere di privacy dovrà essere necessariamente trasposto sul piano della sanità, per qualche considerazione.
Ormai è chiara l’evoluzione dal materiale al digitale che negli ultimi anni ha profondamente toccato il sistema sanitario italiano, evoluzione da cui emergono nuovi profili critici non soltanto per quanto riguarda l’efficienza delle cure e l’efficientamento delle strutture sanitarie, ma anche, e soprattutto, per quanto riguarda il coordinamento tra il diritto alla salute e il diritto alla protezione dei dati sanitari dei pazienti.
La nostra Carta Costituzionale all’art. 32 riconosce e tutela il diritto alla salute come diritto fondamentale dell’individuo e interesse della collettività,[24] prescrivendo altresì una riserva di legge rafforzata in forza della quale un trattamento sanitario previsto per legge “non può in nessun caso violare i limiti imposti dal rispetto della persona umana”. Formula questa complementare alla tutela della dignità, riconducibile all’art. 2 della Costituzione stessa.[25]
A sua volta, il diritto alla protezione dei dati, trova suo massimo riconoscimento nel secondo articolo costituzionale, in quanto riconducibile anch’esso all’esigenza di assicurare la dignità dell’interessato, che potrebbe essere difatti violata ogni qualvolta si verifichi un qualsivoglia vulnus nelle misure tecniche ed organizzative preposte alla tutela di tali dati.[26]
Entrambi i principi, tutela della salute e protezione dei dati personali, saranno allora meritevoli di una tutela intensa quanto dinamica, in costante adeguamento con l’evoluzione tecnologica e il progresso scientifico: sarà compito del giurista trovare il giusto equilibrio fra efficienza del sistema sanitario e delle cure e rischi per la dignità dei pazienti, derivanti dalla digitalizzazione dei dati sanitari.
Ovvio è infatti come i dati sanitari, se illecitamente trattati, siano suscettibili di esporre l’interessato a forme di discriminazioni rese per l’appunto possibili dalla conoscenza di aspetti particolarmente intimi della persona, quali quelli idonei a rivelarne lo stato di salute.
Ad enucleare le criticità di una sanità digitale si richiamino, ancora una volta, le parole di Soro:
Sotto questo profilo la strada da fare è ancora tanta: recenti ricerche hanno indicato, infatti, il settore sanitario come uno di quelli esposti ai maggiori rischi in termini di cyberattacchi perché carente di un piano organico di sicurezza e protezione, oltre che di risorse necessarie per investimenti sulle infrastrutture informative. Eppure proprio questo dovrebbe essere, invece, il settore su cui investire di più in termini di sicurezza informatica e digitale, per garantire che il processo di innovazione tecnologica sia accompagnato da misure tali da assicurare autenticazione dei dati, loro tracciabilità, accessi selettivi con credenziali univoche, cifrature, sistemi di alert, attività di auditing […] La protezione del paziente da queste vecchie e nuove vulnerabilità deve essere un obiettivo centrale per un sistema sanitario all’altezza delle sfide della società digitale, in cui parallelamente alle opportunità (di ricerca, di cura, di avanzamento delle diagnosi e delle terapie) crescono anche i rischi.[27]
Nozione di Data Breach
I dati personali conservati, trasmessi o trattati da aziende e pubbliche amministrazioni possono essere soggetti al rischio di perdita, distruzione o diffusione indebita, a seguito di attacchi informatici, accessi abusivi, incidenti o eventi avversi (si pensi ad incendi od altre calamità).
Così per data breach (o violazione dei dati personali) si intende ex art. 4 n.12 GDPR “una violazione di sicurezza che comporta, accidentalmente o in modo illecito, la distruzione, la perdita, la modifica, la divulgazione non autorizzata o l’accesso ai dati personali trasmessi, conservati o comunque trattati”.
Ecco che una violazione di tal genere non può che compromettere quella triade CIA dell’Information Security di cui già si trattava nel previo capitolo, sorretta dai pilastri della riservatezza, integrità e disponibilità.
Si vogliano qui fornire alcuni possibili esempi di condotte riconducibili a tale definizione:
L’accesso o l’acquisizione dei dati da parte di terzi non autorizzati;
Il furto o la perdita di dispositivi informatici contenenti dati personali;
La deliberata alterazione di dati personali;
L’impossibilità di accedere ai dati per cause accidentali o per attacchi esterni, virus, malware etc.;
La divulgazione non autorizzata di dati personali.
Nelle previsioni del Regolamento Ue 2016/679 viene disciplinato in dettaglio il procedimento che il titolare del trattamento[28] dovrà porre in essere nel caso in cui sia in atto una simil violazione dei dati personali.
Dall’art. 33 GDPR si ricava infatti che il titolare del trattamento (soggetto pubblico, impresa, associazione etc.) senza ingiustificato ritardo, e ove possibile, entro 72 ore dal momento in cui ne sia venuto a conoscenza, deve notificare la violazione dei dati personali all’autorità di controllo competente (si intenda ivi il Garante per la protezione dei dati personali), a meno che sia improbabile che la violazione stessa comporti un rischio per i diritti e le libertà delle persone fisiche. Qualora la notifica al Garante sia effettuata oltre il termine delle 72 ore, dovrà essere corredata dai motivi del suddetto ritardo.[29]
Da ciò si ricava come siano da notificare unicamente le violazioni di dati personali che possono avere effetti significativi sugli individui, causando danni fisici, materiali o immateriali (si pensi alla perdita del controllo sui propri dati personali, ad un danno reputazionale, una perdita finanziaria, il furto di identità, la discriminazione o il rischio frode).
Al terzo comma del medesimo articolo si specifica che tale notifica dovrà avere come contenuto minimo:
Una descrizione della natura della violazione dei dati personali che comprenda, ove possibile, le categorie e il numero approssimativo di persone interessate nonché le categorie e il numero approssimativo dei dati personali interessati;
Il nome e i riferimenti di contatto del responsabile della protezione dei dati (se designato dal titolare) o comunque di un referente competente a fornire ulteriori informazioni;
Una descrizione delle possibili conseguenze della violazione dei dati personali;
Una descrizione delle misure adottate o di cui si propone l’adozione per porre rimedio alla violazione dei dati personali, comprese, se del caso, le misure adottate per mitigare eventuali effetti negativi.
Si noti come il responsabile del trattamento[30] che viene a conoscenza di una eventuale violazione sarà tenuto ad informare tempestivamente il titolare di modo che quest’ultimo possa attivarsi di conseguenza.
Inoltre, a prescindere dalla notifica al Garante, il titolare del trattamento documenta tutte le violazioni dei dati personali, comprese le circostanze ad esse relative, le conseguenze e i provvedimenti adottati per porvi rimedio. Tale documentazione consente alla stessa autorità di controllo di effettuare eventuali verifiche sul rispetto della normativa.
All’art. 34 GDPR viene prevista poi una ulteriore importante incombenza, collegata alla precedente, e cioè la comunicazione della violazione dei dati personali a tutti gli interessati, ovvero alle persone fisiche cui si riferiscono i dati personali oggetto del trattamento. Difatti quando la violazione è suscettibile di presentare un rischio elevato per i diritti e le libertà delle persone fisiche, il titolare del trattamento dovrà necessariamente comunicarla, con linguaggio semplice e chiaro, agli interessati, senza ingiustificato ritardo.[31]
A norma del terzo comma tuttavia tale comunicazione non risulta esser dovuta unicamente nei casi in cui:
Il titolare del trattamento abbia messo in atto le misure tecniche ed organizzative adeguate di protezione e tali misure siano state applicate ai dati personali oggetto della violazione, in particolare quelle destinate a rendere i dati incomprensibili a chiunque non sia autorizzato ad accedervi (si pensi ai sistemi di cifratura);
Il titolare del trattamento abbia successivamente adottato misure atte a scongiurare il sopraggiungere di un rischio elevato per i diritti e le libertà degli interessati;
Detta comunicazione richiederebbe sforzi sproporzionati. In tal caso si proceda invece tramite una comunicazione pubblica o simile misura di analoga efficacia.
Nel caso in cui poi il titolare del trattamento non abbia ancora comunicato all’interessato la violazione dei dati personali, la stessa autorità Garante potrà richiedere, dopo aver valutato la probabilità che la violazione rappresenti un rischio elevato, che vi provveda.
Qualora sia rilevata una violazione delle disposizioni del Regolamento Ue, il Garante potrà, ex art. 58 GDPR, prescrivere diverse misure correttive, fra le quali:
Rivolgere ammonimenti ed avvertimenti al titolare o al responsabile del trattamento;
Ingiungere al titolare o al responsabile del trattamento di conformare i trattamenti stessi alle disposizioni del Regolamento, in una determinata maniera ed entro un determinato termine;
Ingiungere al titolare del trattamento di comunicare all’interessato la violazione dei dati personali;
Imporre una limitazione provvisoria o definitiva al trattamento, incluso il divieto di trattamento, nonché ordinare la rettifica o la cancellazione di dati personali;
Infliggere una sanzione amministrativa pecuniaria ai sensi dell’art. 83 GDPR, in aggiunta alle misure correttive sopradette, o in luogo di tali misure.
Si ricavi come, quando si parla di violazioni della normativa in materia di privacy, il GDPR disciplini esclusivamente le sanzioni amministrative: il regolamento europeo stabilisce infatti, all’art. 84, che spetti a ciascuno Stato membro fissare autonomamente le sanzioni penali, purché queste ultime siano effettive, proporzionate e dissuasive.
Nel nostro ordinamento, come si avrà modo di approfondire in seguito, si è scelto dunque di mantenere in vigore quanto stabilito dal Codice della Privacy, emanato nel 2003, ed in particolare dagli articoli 167 e successivi, così come riformati dal d.lgs. n.101/2018.
Come sottolineato poc’anzi il GDPR disciplina in dettaglio solamente le sanzioni amministrative, pertanto di natura pecuniaria, senza fissarne un valore minimo: all’art. 83 si dispongono molteplici criteri atti ad orientare il Garante nella quantificazione della sanzione stessa, fra cui:
La natura, la gravità ed altresì la durata della violazione, tenendo in considerazione la natura, l’oggetto o la finalità del trattamento nonché il numero di interessati lesi e il livello del danno da essi subito;
Il carattere doloro o colposo della violazione;
Le misure adottate dal titolare o dal responsabile del trattamento per attenuare il danno subito dagli interessati;
Il grado di responsabilità del titolare o del responsabile del trattamento, tenendo conto delle misure tecniche e organizzative da essi messe in atto;
Eventuali precedenti violazioni pertinenti commesse dal titolare o dal responsabile del trattamento;
Il grado di cooperazione con l’autorità di controllo al fine di porre rimedio alla violazione;
Le categorie di dati personali interessati dalla violazione;
Eventuali altri fattori aggravanti o attenuanti applicabili alle circostanze del caso (si pensi a benefici finanziari conseguiti o perdite evitate).
Ai paragrafi 4 e 5 del medesimo articolo, il GDPR specifica poi che, accertata la violazione, la sanzioni amministrative pecuniarie possano arrivare fino a:
10 milioni di euro, o per le imprese, fino al 2% del fatturato mondiale annuo dell’anno precedente, nei casi in cui, ad esempio, i dati personali vengano trattati in maniera illecita, non venga nominato il DPO (Data protection officer) o non venga comunicato un data breach all’Autorità Garante;
20 milioni di euro, o per le imprese, fino al 4% del fatturato mondiale annuo dell’anno precedente, nei casi più gravi quali l’inosservanza dei diritti degli interessati o il trasferimento illecito di dati personali ad altri Paesi.
Riassumendo, le possibili conseguenze per le organizzazioni che agiscono in violazione del GDPR comprendono sia sanzioni amministrative, che sanzioni penali, come anche condanne al risarcimento del danno ed eventuali misure correttive (si pensi al sopracitato divieto temporaneo di trattamento dei dati personali).[32]
Allora, considerate tali ripercussioni, si intuirà l’importanza di interpretare correttamente le disposizioni Regolamento ed, in particolare, il suo “DNA di fondo”, ossia il sopracitato principio di accountability (traducibile come principio di responsabilizzazione).[33]
Sulla base di tale obbligo di rendicontazione spetterà infatti al titolare del trattamento adottare (e rispettare) tutte le misure tecniche, organizzative e legali necessarie a garantire l’effettiva protezione dei dati personali, consapevole che su di lui stesso, ed in minor parte anche sul responsabile del trattamento, graverà l’onere di documentare e dimostrare ex post la conformità di ogni misura adottata alla normativa Ue.
La chiave per interpretare correttamente la disciplina europea risiede proprio nel termine “dimostrare”: un buon titolare del trattamento farà in modo che ogni misura, ogni procedura, ogni metodologia applicativa sia affidabile, credibile e giustificabile ex post.
Per far ciò risulta necessario sviluppare una forte sensibilità informatica, tecnologica e legale, imparando a valutare in modo appropriato le proprie decisioni, servendosi ad esempio di una Gap Analysis, ossia l’effettuazione di una mappatura completa dei trattamenti, confrontando le misure adottate con i principi stabiliti dal GDPR e verificando l’eventuale sussistenza di difformità , in modo tale da, eventualmente, intraprendere azioni correttive di adeguamento.
Simulazione pratica di un data breach sanitario in ospedale
Si sono definiti i data breach come eventi di violazione della sicurezza di una banca dati, che possono trovare derivazione tanto da semplici errori umani (commessi, ad esempio, nella fase di progettazione od implementazione di un software) quanto, ed è ciò che in questa sede più interessa, da sofisticati attacchi informatici ad opera di cyber criminali.
Si può parlare in tali casi di una “falla” (o per l’appunto, breccia): ossia una fessura nella quale l’hacker può insinuarsi ed avere accesso non autorizzato ai dati personali di un individuo, quali possono essere i dati sulla salute.
L’ambito sanitario infatti, formato da strutture che archiviano ed elaborano un quantitativo considerevole di informazioni sensibili sui pazienti, si presenta, ancor più di altri settori, obiettivo vulnerabile agli attacchi informatici.
Si voglia di seguito, per amor di chiarezza, presentare una simulazione, in ambito ospedaliero, di quelli che possono essere i possibili scenari scaturenti da un data breach, quali: il furto dei dati sanitari, l’eliminazione dei dati stessi e la loro alterazione.[34]
Tizio in tarda serata viene ricoverato per una colecisti, all’arrivo in ospedale viene immediatamente sottoposto a trattamenti ed esami sanitari il cui esito viene registrato in una cartella clinica a disposizione del medico che lo visiterà il giorno seguente. Durante la nottata tuttavia, un gruppo di hacker riesce a “bucare” ed intromettersi nel sistema informatico ospedaliero, grazie ad alcune chiavette USB, contrassegnate appositamente dal logo ospedaliero, precedentemente lasciate in alcune postazioni del reparto col fine di esser scoperte ed in seguito installate dal personale. Gli infermieri infatti inserendo, erroneamente, le pendrive hanno dato immediato innesco al virus informatico artefice della “breccia” nel sistema ospedaliero.[35]
Durante la notte i cybercriminali si sono dunque connessi al database, dove risiedono registrati i dati sanitari di tutti i pazienti, inclusi quelli di Tizio.
Ed ecco così delinearsi i possibili scenari, lesivi rispettivamente dei tre principi cardine della triade CIA, ossia confidenzialità, disponibilità ed integrità:
Scenario 1. La sottrazione del dato. La mattina seguente i dati di Tizio vengono trovati correttamente dal medico curante che procede così con anamnesi, diagnosi e cure appropriate. La degenza ospedaliera di Tizio viene metodicamente seguita, fino alle sue dimissioni definitive.
Tutto procede regolarmente fino a quando però il reparto ICT, dotato di un sistema di tracciamento dei dati correttamente configurato, si accorge dell’avvenuto data breach e del conseguente furto di dati perpetrato.
Ecco che, in conformità alla normativa europea sopra ricordata, verrà redatta e notificata la segnalazione al Garante Privacy contenente gli elementi essenziali richiesti ex art. 33 GDPR (natura della violazione, numero degli interessati coinvolti, le misure adottate per porvi rimedio, etc.).
Da tale momento l’Autorità garante nazionale, in base al principio di accountability, darà avvio all’iter procedurale di controllo e valutazione in merito all’accaduto, vagliando le misure tecniche ed organizzative poste in essere dal titolare del trattamento, iter che potrebbe culminare in un provvedimento amministrativo sanzionatorio, laddove si accertasse una effettiva violazione o un non adeguamento alla disciplina Ue in materia di trattamento dei dati personali.
Si noti come in tale primo scenario non vi siano conseguenze strettamente cliniche pregiudizievoli per il paziente Tizio, questi ha subito infatti unicamente un danno derivante dalla perdita del controllo sui propri dati personali, una lesione della propria riservatezza.
A tal proposito l’art 82 GDPR prevede che “chiunque subisca un danno materiale o immateriale causato da una violazione del presente regolamento ha il diritto di ottenere il risarcimento del danno dal titolare del trattamento o dal responsabile del trattamento”.
Ciò significa che il soggetto danneggiato (ossia l’interessato), a seguito di un trattamento dei propri dati in violazione della normativa GDPR, potrà ottenere il risarcimento di qualunque danno occorsogli, agendo per l’intero indifferentemente contro il titolare o il responsabile del trattamento, tenuti solidalmente al risarcimento (eventuali clausole contrattuali di ripartizione del danno varranno difatti solo nei rapporto interni tra i danneggianti stessi).
A proposito della risarcibilità del danno la Suprema Corte di Cassazione ha, in una recente pronuncia,[36] ribadito come il danno non patrimoniale, pur determinato da una lesione del diritto fondamentale alla protezione dei dati personali, tutelato dall’art. 2 Cost. e dall’art. 8 CEDU, non si sottrae alla verifica della “gravità della lesione” e della “serietà del danno”. Da una lettura congiunta allora dell’art. 82 GDPR e della pronuncia della Suprema Corte emerge con chiarezza come, ai fini della risarcibilità del suddetto danno, siano necessarie in primis l’esistenza di una violazione del Regolamento 2016/679 e a seguire la dimostrazione dell’entità del danno stesso (nei due aspetti della gravità e della serietà).
In riferimento alla risarcibilità del danno viene poi precisato nel Considerando 146 del Reg. Ue che: “Il titolare del trattamento o il responsabile del trattamento dovrebbero risarcire i danni cagionati ad un soggetto da un trattamento non conforme al presente regolamento, ma dovrebbero essere comunque esonerati da tale responsabilità se dimostrano che l’evento dannoso non sia in alcun modo ad essi imputabile”.
Si ricordi come l’art. 24 GDPR e il Considerando 74 stabiliscano che il titolare debba mettere in atto, previa valutazione della natura, ambito e finalità del trattamento nonché del grado di rischio, le misure tecniche ed organizzative adeguate, prescrivendogli inoltre di esser in grado di dimostrarne l’efficacia.
L’imputabilità del titolare allora dovrà necessariamente esser valutata alla luce dei principi di responsabilizzazione e accountability del GDPR, il titolare (o il responsabile) potrà fornire la prova che il danno si è verificato perché non poteva esser previsto, dato che esulava dalla propria possibilità di controllo (si pensi al caso fortuito o alla forza maggiore) o che sono comunque state opportunamente predisposte tutte le misure tecniche e organizzative per evitare che il danno potesse verificarsi.
Scenario 2. L’eliminazione dei dati. La mattina seguente i dati sanitari di Tizio non vengono trovati, ciò provoca un immediato allarme nel reparto e gli esami clinici vengono ripetuti con urgenza: Tizio subisce perciò un ritardo nel trattamento, ciononostante le sue condizioni mediche non sono gravi. I dati questa volta vengono ritirati “a mano” e si procede con le cure del caso. L’eliminazione dei dati allerta ad ogni modo il reparto ICT che procede ad una diagnostica da cui viene rilevata una eliminazione non autorizzata del dato sanitario: il database viene dunque scansionato ed il sistema bonificato.[37]
Si è assistito anche in tal caso ad una compromissione dei dati personali che ne ha causato una perdita della loro pronta disponibilità, per cui si vedrà ex art. 33 GDPR la stesura e la notifica al Garante privacy dell’avvenuta violazione degli stessi dati sanitari dei pazienti. Da qui prenderà avvio il regolare iter di accertamento e di valutazione da parte dell’Autorità di controllo nazionale in merito alla sicurezza del sistema informatico ospedaliero, vagliandone le misure tecnico-organizzative adottate.
In tale secondo scenario non vi sono parimenti danni seri al paziente, ma si registra comunque un discreto esborso di denaro al fine di pagare le risorse incaricate di sistemare la parte software, nonché ripristinare il corretto livello di sicurezza informatica.
Scenario 3. L’alterazione dei dati. La mattina seguente i dati di Tizio vengono letti dal medico curante che, preoccupato per i valori completamente fuori norma, suggerisce una terapia con un farmaco che peggiora le condizioni del paziente. Da questo momento la salute di Tizio si aggrava celermente, i medici comprendono che vi è una discrepanza fra i risultati riportati nel sistema e le risposte biologiche del paziente. Non trovando una corrispondenza Tizio viene sottoposto ad ulteriori esami clinici per poi, successivamente, vedersi corrisposte le corrette cure ed i trattamenti opportuni.
Rendendosi comunque conto del danno arrecatogli, dovuto ad una non corretta protezione della integrità dei propri dati sanitari da parte della struttura sanitaria, che con molta probabilità non aveva adottato tutte le adeguate misure tecnico-organizzative per prevenire il pericolo di data breach, Tizio si vede intenzionato ad agire per ottenere un risarcimento ex art. 82 GDPR.
Nel frattempo, si apre anche una fase di accertamento della sicurezza dei sistemi informativi dal lato del Garante che, accertato il data breach e il non adeguamento alla normativa europea sulla protezione dei dati, emette un immediato provvedimento con annessa sanzione amministrativo-pecuniaria. Il reparto ICT intanto effettua una riprogettazione dei sistemi di gestione del dato e della sicurezza, andando ad incidere ulteriormente sui costi da sopportare.
Ci si accorgerà di come il terzo scenario sia con probabilità quello con i costi di gestione maggiori, ma soprattutto, di come sia l’unico ad aver realmente messo a rischio la salute del paziente. L’alterazione del dato è sicuramente molto meno visibile e rilevabile rispetto alla sua cancellazione o al suo furto e questo non fa che peggiorare i ritardi nelle reazioni del reparto ICT.
A tal proposito il tempo di rilevazione di un data breach risulta di dirimente importanza: al di là invero del caso in cui sia il malintenzionato stesso a render edotte le vittime circa l’effettuata violazione dei sistemi (spesso, come si vedrà, per chiedere un riscatto al fine di ripristinarne il regolare funzionamento), i tempi generali per suddetta rilevazione risultano ad oggi comunque molto alti.
Ovvio è pertanto che riuscire a monitorare i sistemi e le attività in modo tale da avere la piena capacità di accorgersi di una violazione in atto risulta il requisito imprescindibile per arrivare a prevedere, mitigare, nonché contenere tutti i possibili rischi informatici.[38]
A questo punto della trattazione appare comprensibile incominciare a domandarsi i motivi che si celano dietro a tali cyber-condotte, per quale ragione i dati sanitari siano tanto ambiti e soprattutto che concreto valore abbiano: se questi infatti sono un obiettivo criminale, significa che esiste una domanda di tali dati, e se c’è una domanda deve esserci un ritorno sull’investimento.
Si possono richiamare a tal proposito le parole di Agostino Ghiglia, componente del Garante per la protezione dei dati personali:
Ad oggi il settore meno preparato risulta essere proprio quello sanitario che, tra l’altro, paga il prezzo di gran lunga più caro dal momento che la spesa per i data breach è notevolmente aumentata. È evidente che il comparto sanitario risulti essere il più bersagliato a causa della quantità e qualità dei dati custoditi e che, ovviamente, hanno un notevole valore economico. Gli attacchi criminali non mirano infatti solo a bloccare i sistemi dietro la richiesta di un riscatto, ma soprattutto a capitalizzare i dati sensibili. È fondamentale per questo motivo che le strutture sanitarie prevedano un piano operativo d’azione che racchiuda sia una difesa in ambito tecnologico che un piano formativo del personale dal momento che il più delle volte gli attacchi vengono veicolati con precise comunicazione e-mail.[39]
Il mercato nero della salute
Vanno moltiplicandosi gli studi e le indagini che si interrogano sul perché il rischio cyber imperversi così minacciosamente sul mondo della sanità e, in particolare, sul mercato dei dati sanitari nel dark web[40], al fine di comprendere struttura, profitto ed acquirenti di un fenomeno mondiale così in profonda crescita.
Di seguito si riportano le parole di Soro: “Si tratta del commercio di dati tra i più delicati, in quanto in grado di rivelare gli aspetti più privati della vita, ed espressivi, oltretutto di una condizione di particolare vulnerabilità quale è quella di un paziente ricoverato in ospedale. Che è dunque affidato ad una struttura pubblica, dalla quale deve potersi aspettare non soltanto attenzione e cura, ma anche un assoluto rispetto per la propria riservatezza e dignità”.[41]
Innanzitutto si premetta come il valore di tali dati sensibili sia strettamente legato alla loro stessa tipologia, essi invero possono includere: dati personali identificativi del paziente, indirizzi e-mail, numeri di tessere sanitarie, varie informazioni mediche (esami diagnostici, referti di laboratorio, prescrizioni di medicinali etc.), dati assicurativi, nonché attestati e certificati di laurea in medicina.
Risulta in questa sede opportuno rifarsi al report “Healthcare Cyber Heists” condotto dalla società statunitense di cybersicurezza Carbon Black, datato al 2019. Il rapporto si fonda su un campione di interviste, rivolte a venti manager CISOs[42], ossia soggetti responsabili del definire e sviluppare strategie di sicurezza informatica, in tal caso specificatamente nel settore sanitario.[43]
È fuor di dubbio che tale survey offra unicamente una prospettiva parziale, ma ad ogni modo rilevante per comprendere quanto siano frequenti le cyber-offensive, come vengano rubati i dati sanitari e successivamente venduti.
Si vogliano dapprima riassumere i risultati chiave scaturenti dal rapporto:
a) L’83% delle organizzazioni sanitarie intervistate ha notato un notevole aumento dei cyber attacchi nell’ultimo anno (riferendosi al 2018);
b) I tentativi di intromissione informatica sono stati, in media, 8.2 al mese per ogni endpoint, ossia non per ogni organizzazione, ma per ciascun dispositivo connesso alla Rete;
c) Il 66% delle organizzazioni ha affermato che le offensive non sono solo più numerose ma anche maggiormente sofisticate, testimoniando di esser state bersaglio sia di attacchi ransomware che island hopping[44];
d) All’interrogativo su quale sia la maggiore preoccupazione della propria organizzazione le risposte sono state: la compliance (33%), i limiti di budget e risorse (22%), la perdita dei dati sanitari (16%) la vulnerabilità dei medical devices (16%) e l’impossibilità sopraggiunta di accedere ai dati dei pazienti (13%). Da qui si ricavi forse uno dei maggiori problemi della sicurezza sanitaria: pensare che la compliance (traducibile col termine “conformità”) equivalga alla sicurezza.
Troppe organizzazioni, seppur considerate conformi agli standard generali di sicurezza, sono ad ogni modo state vittime di molteplici violazioni: la conformità a disposizioni normative, regolamenti e codici di condotta è indubbiamente un buon punto di partenza, ma ciò non basta, Troppe organizzazioni, seppur considerate conformi agli standard generali di sicurezza, sono ad ogni modo state vittime di molteplici violazioni: la conformità a disposizioni normative, regolamenti e codici di condotta è indubbiamente un buon punto di partenza, ma ciò non basta, è infatti necessario creare un programma di sicurezza atto a contemplare anche tutte le esigenze specifiche di una organizzazione.
Il rapporto prosegue poi stilando un borsino indicativo di quelle che sono le tipologie di dati sanitari maggiormente vendute sul dark web, disposte di seguito in ordine di valore:
a) I dati in assoluto più costosi, nonché di allarmante diffusione, sono i Provider Data, si possono cioè trovare online i “pacchetti Fullz” ( 4.2) contenenti tutti i documenti di cui si necessita per ricostruire il background di un medico professionista: dati personali identificativi, diplomi di laurea, licenze mediche, nonché documenti assicurativi. Il costo del “pacchetto” si aggira sui 500 dollari.
Si intuisce già la versatilità che tali dati garantiscono nel loro utilizzo: dal procurarsi farmaci soggetti a prescrizione medica (per un uso personale od altresì per rivenderli in rete), fino all’acquisire falsi documenti (passaporti, patenti di guida etc.) con cui un qualsiasi soggetto non qualificato possa porsi come medico nei confronti di organizzazioni come assicurazioni e servizi sanitari.
Ciò che accade dunque vede in primo luogo un hacker compromettere la rete di un fornitore di servizi sanitari al fine di ricavarne documenti amministrativi che possano supportare l’identità contraffatta di un medico, cosicché successivamente un qualsiasi acquirente possa, a proprio vantaggio, presentarsi con la falsa identità del medico de quo.
A seguire le parole del Professor Kevin Curran, dell’università di Ulster:
Dire che i dati dei pazienti siano dalle 10 alle 15 volte più preziosi dei dati inerenti alle carte di credito è una buona stima, dato che tali datioffrono ai criminali informazioni permanenti ed altamente fruttifere”.[45] Ovvio è che nel caso di una carta di credito rubata, questa possa essere istantaneamente disattivata e gli addebiti fraudolenti contestati. Negli ultimi anni poi le banche hanno notevolmente rafforzato la propria sicurezza online incorporando trasferimenti e transazioni più sicure. Nel mondo sanitario il tutto risulta più complesso: i dati rubati non sono facilmente recuperabili e, in verità, non si dispone nemmeno di un chiaro processo per aiutare i pazienti a fronteggiare le conseguenze del furto di identità. È pertanto indispensabile prevedere delle misure proattive al fine di ridurre le probabilità che tale dati vengano trafugati.
Fig 4.2 Annuncio di vendita su AlphaBay, avente ad oggetto un completo pacchetto Fullz “Healthcare Fraud Package”, al prezzo di 500$. Fonte: report Carbon Black, “Healthcare Cyber Heists in 2019”.
b)Altri contenuti sanitari rinvenuti nella darknet, più numerosi e meno costosi dei precedenti, sono i forgeries (o falsificazioni), venduti ad una fascia di prezzo compresa fra i 10 e i 120 dollari. Essi possono assumere la forma di tessere sanitarie contraffatte, come anche di false prescrizioni mediche ( 4.3). Ad un venditore possono difatti esser forniti tutti i dati necessari per realizzare una prescription label personalizzata per l’acquirente, con cui ad esempio possa superare i controlli (quali in aeroporto) che vietano il trasporto di alcuni farmaci senza specifica prescrizione medica.
Fig 4.3 Annuncio di vendita su AlphaBay, avente ad oggetto prescrizioni contraffatte di farmaci Walgreens, al prezzo di 60$. Fonte: report Carbon Black, “Healthcare Cyber Heists in 2019”.
c) Ancora si possono trovare insurance login information, ad un prezzo contenuto di 3.25 dollari per singola credenziale di accesso, il basso costo è dovuto alla rapidità con cui le medesime credenziali possono esser cambiate una volta che la compromissione del database viene scoperta. Comunque, una volta ottenute le informazioni di accesso, l’acquirente può ottenere illecitamente tutte le informazioni riguardanti una determinata assicurazione medica, utilizzabili a loro volta per ricevere cure mediche o medicinali sotto prescrizione.[46]
Si vogliano qui riassumere i fini a cui si può indirizzare il furto dei dati sanitari: la costruzione di false identità, la commissione di frodi ai danni dei sistemi assicurativi, la richiesta di somme di denaro come riscatto al fine di rientrare in possesso dei propri dati, la contraffazione di documenti (certificati di nascita, passaporti etc.), l’emissione di false ricette mediche, nonché l’ottenimento di determinati farmaci.
Non si può nemmeno escludere che fra gli acquirenti nel suddetto sistema di compravendita vi siano anche grandi aziende, interessate parimenti ad entrare in possesso di Big Data altrimenti irraggiungibili, si pensi a grandi imprese farmaceutiche che potrebbero sfruttare i pacchetti di dati medicali in vendita per la ricerca e lo sviluppo di nuovi farmaci, avvantaggiandosi così notevolmente sulla propria concorrenza.
Si sottolinei invero come dai dati sanitari, in una loro forma aggrega, sia possibile derivare, predittivamente, una conoscenza circa: le aspettative di vita di una popolazione, la futura necessità di cure, assistenza o medicinali, la suscettibilità di sviluppare determinate patologie, tutte informazioni altamente sfruttabili per orientare determinate politiche e scelte commerciali ad opera di grandi competitors.[47]
Chiaro è comunque come i dati sanitari protetti di ciascun individuo, quelli che identificano ogni nostra storia di salute individuale, stiano diventando ad oggi miniera d’oro per i cyber criminali.
Così Roberto Setola dell’Università Campus Bio-Medico di Roma: “I dati sanitari sono i più appetibili per i cyber criminali. Sul dark web infatti sono quelli che vengono venduti al prezzo più elevato, ciò è dovuto alla loro grande versatilità: possono infatti risultare redditizi sia vendendoli sia utilizzandoli, sempre da un punto di vista criminale, contro il soggetto a cui appartengono. […] Il problema maggiore è che i dati sanitari non sono ben protetti: il passaggio dalla carta al digitale negli ospedali e nelle strutture sanitarie non è stato accompagnato da un cambiamento culturale degli operatori della sanità esponendo così i dati ad un alto rischio di perdita, furto, nonché alterazione.” [48]
Caso: Ulss 6 Euganea di Padova
Si voglia qui brevemente ricostruire un recente caso di cronaca, al fine di comprendere quanto siano attuali gli argomenti di cui si va trattando e di che ampio raggio siano, penisola italica inclusa.
Il tutto ha inizio il giorno 3 Dicembre 2021, momento in cui cominciano a diffondersi in rete le prime notizie riguardanti un attacco informatico subito dalla Ulss 6 Euganea, ossia l’Unità locale socio sanitaria di Padova. [49]
Non tarda ad arrivare un comunicato da parte della medesima struttura: “L’Ulss 6 Euganea informa che nella notte si è verificato un attacco hacker, che ha comportato il blocco della maggior parte dei server, compromettendone la fruibilità. Stiamo intervenendo con la massima celerità con tutti i nostri tecnici informatici al fine di ripristinare il prima possibile i servizi.”
I criminali hanno agito tramite attacco ransomware, di cui si avrà modo di trattare in seguito, rendendo impossibile accedere alle banche dati ed inviare informazioni alle piattaforme sanitarie, sospendendo le nuove registrazioni dei pazienti, il sistema dei laboratori, alcuni punti tamponi e hub vaccinali.
Di qui le immediate ripercussioni: i padiglioni di tamponi e vaccini (si pensi che in quel periodo si registravano più di 800 positivi in 24 ore a Padova e provincia) hanno dovuto riprendere a lavorare in modalità cartacea, e diversi problemi sono stati riscontrati al pronto soccorso, nelle terapie intensive, nelle radiologie, nei cup e nei laboratori analisi.
Così informa l’Ulss “È in essere una collaborazione stretta con l’Azienda ospedaliera Università di Padova e con il privato accreditato, ai quali vengono convogliati i casi indifferibili. Ove non supportati da reti informatiche esterne, l’Azienda procederà provvisoriamente alla registrazione su supporto cartaceo, che potrà creare inevitabili rallentamenti.”
Inutile dire come si sono adoperati e hanno lavorato strenuamente oltre 60 tecnici del settore al fine di contrastare il blocco, di minimizzare i danni, nonché di bonificare tutte le macchine ospedaliere e certificare quelle “pulite”.
Ad una settimana dall’attacco tuttavia soltanto un terzo dei computer risulta bonificato, ed i problemi persistono: seri danni vengono riscontrati alle infrastrutture IT, non risulta possibile emettere ricette dematerializzate, non possono essere inseriti i dati relativi agli isolamenti domiciliari da Covid-19, sono stati chiusi i punti prelievo e bloccate le prenotazioni specialistiche.
Solo in data 20 Dicembre si percepisce una lenta ripresa, si hanno difatti i primi risultati positivi (quali la riapertura di alcuni punti prelievi), al contempo però cominciano a diffondersi notizie circa una colossale mole di dati sensibili e di credenziali di accesso trafugati, il cui valore di mercato risulta incalcolabile: ecco profilarsi la probabile vera finalità dell’attacco informatico.
Con l’inizio del nuovo anno, dopo circa un mese da quello che è stato uno dei più gravi attacchi alla sanità italiana, sopraggiunge così la rivendicazione dell’attacco da parte del gruppo hacker Lockbit 2.0 che, in un post, avvia una sorta di “countdown”: i dati sottratti dall’azienda sanitaria saranno resi pubblici il giorno 15 Gennaio 2022, salvo pagamento di un riscatto (la somma pareva ammontare sugli 800.000 euro in criptovalute).
Viene dunque immediatamente aperta da parte del Garante della privacy una istruttoria per il data breach, processo mirante a verificare se i dati in possesso dell’Ulss fossero adeguatamente protetti e se sia stato fatto tutto il possibile (ossia adottata ogni misura tecnico-organizzativa necessaria) per evitare che i dati venissero sequestrati ed eventualmente diffusi dai criminali informatici.
Come preannunciato, nel pomeriggio del 15 Gennaio, Lockbit pubblica i dati sanitari, e più precisamente vengono diffuse due cartelle dal nome “Ulss2” e “Ulss3” contenenti all’incirca 9.300 documenti (fra cui pdf, documenti excel, word, etc.) riportanti svariate informazioni: dati sensibili dei pazienti (referti medici, analisi, esiti di tamponi molecolari Covid, coi rispettivi dati anagrafici) tabelle illustrative di stipendi e turni ospedalieri del personale medico-sanitario, nonché informazioni sul budget dei vari reparti e tanto altro ancora.
Non è da escludere che ciò che sia stato divulgato sia solo una quota delle informazioni in possesso del gruppo hacker Lockbit, il quale potrebbe aver nel frattempo rivenduto un’altra importante porzione di dati nell’underground del web.
Da parte dell’Ulss è stato emesso di conseguenza un conclusivo comunicato ufficiale[50] in cui si legge:
Fino ad oggi non sussisteva alcuna certezza che i malviventi fossero riusciti a venire in possesso di informazioni, in che quantità e il loro genere. I criminaliavevano avanzato una richiesta di riscatto in denaro in cambio della non pubblicazione delle informazioni a loro dire sottratte all’Azienda Ulss 6. Tentativo estorsivo prontamente denunciato alle forze dell’ordine e alla Procura della Repubblica. […] La task force dell’Azienda Ulss 6, nel pieno rispetto delle indagini in corso, è al lavoro per valutare entità e tipologia dei dati pubblicati. Si ricorda che le informazioni comparse sul dark web sono altresì frutto di attività illegale e dunque chiunque intendesse consultarle o utilizzarle commetterebbe un reato […] Il confronto e lo scambio di informazioni con la Procura della Repubblica e il Garante per la protezione dei dati personali è costante, siamo a disposizione dei nostri utenti e confidiamo che le indagini di Procura e forze dell’ordine, che ringraziamo per il supporto, permettano di individuare e fermare questi criminali.
Tirando le fila di tale vicenda si può meditare sui danni che ne sono conseguiti: oltre alle perdite economiche riflesse sia a livello regionale che di sistema sanitario nazionale ed al grave danno reputazionale e d’immagine in capo all’Ulss, non si può trascurare l’offesa subita dai pazienti e dai cittadini che si sono visti negare diversi servizi sanitari (si pensi ad una visita specialistica per una malattia degenerativa) o hanno comunque subito dei rallentamenti nelle ricevere le proprie cure.
I dubbi, c’è da dire, permangono: è stato avviato un programma cyber ad hoc e sono state intraprese azioni di miglioramento per scongiurare, l’altrimenti inevitabile, ripetersi di un simile attacco?
Utili risultano, a tal proposito, le parole di Pierguido Iezzi, CEO e fondatore della cyber security company Swascan:[51] “Di base, per rendere sicura una struttura è necessario ridurne il livello di esposizione al rischio cyber. […] Quanto affermato passa per l’adozione tout court dei tre pilastri della cyber security moderna: sicurezza predittiva, preventiva, proattiva.
Bisogna implementare nel perimetro delle strutture un sistema di tecnologie e processi non solo in grado giocare “di risposta” agli attacchi, ma anche in grado di prevederli e anticiparli tramite l’utilizzo di sistemi quali la Threat Intelligence,[52] che sia associata all’expertise di un Centro operativo di sicurezza”.
Inquadramento giuridico: il reato informatico
Si è già potuto rimarcare, nello scorso capitolo, come la rivoluzione informatica abbia consentito la smaterializzazione della realtà fenomenica, con l’introduzione di oggetti privi di sostanza materiale (si pensi al semplice “dato” informatico), intangibili, componenti di una nuova e parallela realtà, quella virtuale.[53]
Tuttavia il progressivo ampliamento degli strumenti informatici e la loro capillare diffusione hanno presto, si è visto, provocato uno sviluppo patologico e distorto dei sistemi di informatizzazione, portando ad una evoluzione delle pratiche criminose: sono emerse molteplici forme delinquenziali nuove, tanto per le modalità di esecuzione, quanto per i beni materiali e giuridici coinvolti, divenendo sempre più urgente l’esigenza di sollecitare un intervento legislativo in materia di diritto penale dell’informatica.
Si avviarono di conseguenza primordiali riflessioni, ad opera di cultori del diritto, incentrate sulla possibile individuazione di nuovi beni giuridici prodotti direttamente dall’informatica, andando presto a delinearsi due orientamenti contrapposti. [54]
Secondo il primo indirizzo, assai diffuso in Europa, i nuovi delitti cibernetici non producevano inediti interessi meritevoli di tutela, bensì introducevano soltanto nuove modalità di aggressione di beni giuridici comunque preesistenti (per chiarire, secondo tale visione, la frode informatica altro non sarebbe che una truffa realizzata servendosi di un computer, e l’interesse aggredito rimarrebbe pur sempre, come per la truffa comune, il patrimonio). Tale corrente di pensiero mirava dunque a sostenere il cosiddetto “metodo evolutivo”, e cioè la necessità di introdurre singole disposizioni specifiche, riferite all’informatica, all’interno delle normative penali previgenti, impendendo così il ricorso a procedimenti interpretativi di tipo analogico, non consentiti in sede penale.
Diversamente, per il secondo indirizzo dottrinario, sviluppatosi per lo più nei Paesi anglosassoni, le nuove tecnologie determinavano il sorgere di nuovi interessi suscettibili di tutela ed era pertanto auspicato un intervento normativo ad hoc specifico e autonomo (seguendo il metodo delle cosiddetta “legge organica”), in grado di disciplinare separatamente dalle normative previgenti l’intero fenomeno criminale.[55]
Per comprendere quale indirizzo sia stato in concreto adottato nel nostro ordinamento, occorre dapprima volgere lo sguardo alla evoluzione normativa in materia di criminalità informatica, costituita da molteplici interventi legislativi fortemente condizionati da indicazioni di fonte sovranazionale.
Il legislatore italiano si è infatti mosso sulla spinta della Raccomandazione del Consiglio d’Europa del 1989 “Sur la criminalité en relation avec l’ordinateur” mirante a che i diversi Paesi instaurassero una stretta collaborazione per la repressione della criminalità informatica, in quanto sempre più contraddistinta da carattere sovranazionale. [56]
Essa proponeva inoltre alle Nazioni aderenti due liste di cybercrimes: una cosiddetta “lista minima” comprendente fattispecie la cui incriminazione, in virtù della loro diffusione e gravità era ritenuta obbligatoriamente necessaria (fra cui la frode informatica, l’accesso non autorizzato ad una rete o sistema, il danneggiamento di dati o programmi) ed una “lista facoltativa”, riguardante invece condotte punibili sulla base della discrezionalità rimessa a ciascun Paese, anche solo con strumenti di tipo amministrativo.
Il legislatore italiano ebbe così il giusto input per rivedere le proprie disposizioni penali in merito ai crimini informatici, dando forma, nello stesso anno, alla Commissione Callà, composta sia da giuristi che da esperti di informatica col fine di arrivare alla stesura di un compiuto disegno di legge, che fu approvato il 23 Dicembre 1993.
Tramite la sopradetta legge n. 547 del 1993 (“Modificazioni ed integrazioni alle norme del Codice penale e del Codice di procedura penale in tema di criminalità informatica”) si è potuto da un lato introdurre all’interno del codice penale nuove fattispecie delittuose (quali gli artt. 615-ter, quater e quinquies) e dall’altro modificare le fattispecie esistenti con il riferimento ai beni informatici (ad esempio, prevedendo che il delitto di attentato ad impianti di pubblica utilità, ex art. 420 c.p., riguardi anche l’ipotesi di danneggiamento o distruzione dei sistemi informatici o telematici di pubblica utilità o di dati in essi contenuti). [57]
Ne consegue allora come il legislatore italiano abbia optato per il metodo sopraricordato come “evolutivo”, ritenendo che le tecnologie informatiche vadano ad incidere sulle modalità di aggressione a beni giuridici o interessi che rimangono purtuttavia invariati, ossia già oggetto di tutela nelle diverse parti del codice. Rispetto dunque ad altri Paesi, quali gli Stati Uniti o la Francia, che differentemente hanno dedicato ai delitti informatici leggi ad hoc e titoli appositi all’interno dei rispettivi codici, in Italia le nuove norme sono state inserite in diverse parti del Codice penale, ciascuna vicino alla previgente norma ritenuta simile.
Da qui la distinzione dei fatti criminosi che possono essere commessi nel cyberspace in due diverse categorie: i reati informatici “in senso stretto”, che includono fattispecie che presentano espressamente, nella propria formulazione letterale, elementi descrittivi di modalità, oggetti, attività frutto della tecnologia informatica, ossia relativi a procedimenti di elaborazione automatizzata di dati (si pensi all’accesso abusivo “ad un sistema informatico o telematico”), ed i reati informatici “in senso lato”, dove vi rientrano invece fattispecie che, pur non tipizzando espressamente elementi di natura tecnico/informatica, comprendono anche i fatti criminosi commessi nel cyberspazio, costituendo essi semplici forme di aggressione a beni giuridici già tutelati da norme incriminatrici comuni (si pensi al reato di sostituzione di persona, integrato ad ogni modo qualora siano utilizzate le generalità di una diversa persona per creare un falso account tale da indurre taluno in errore).[58]
Ancora ulteriori riforme della legislazione penale sono state in seguito apportate dalla legge n. 48 del 2008, recante la “Ratifica ed esecuzione della Convenzione del Consiglio d’Europa sulla criminalità informatica, firmata a Budapest il 23 Novembre 2001 e norme di adeguamento dell’ordinamento interno”, per mezzo della quale sono state introdotte alcune modifiche allo stesso codice penale (con l’inserimento degli artt. 635-bis, 635-ter, 635-quater, 635-quinquies), al codice di procedura penale, e anche al D.Lgs n. 231/2001 prevedendo la responsabilità degli enti per un’ampia serie di reati informatici. [59]
Come evidenziato comunque nella relazione parlamentare relativa a suddetto disegno di legge “la portata dell’adeguamento normativo da realizzare nel settore del diritto penale sostanziale è risultata modesta, essendo in molti casi già in vigore una disciplina esaustiva, anzi addirittura più incisiva di quella richiesta dalle disposizioni della Convenzione di Budapest medesima”.
Si osservi in conclusione come, volendo contrastare fenomeni legati al funzionamento delle tecnologie, il legislatore debba necessariamente fare i conti con modalità, oggetti e comportamenti di natura squisitamente informatica, ossia elementi indubbiamente ardui da trasporre sul piano normativo.
Il rischio comunque è che l’individuazione di particolari modalità d’azione, volte a dar veste giuridica a determinati fatti criminosi informatici, possa risultare una tecnica di normazione inefficace: il costante aggiornamento delle tecnologie impiegate potrebbe cioè far cadere in rapida desuetudine le norme incriminatrici di settore, insuscettibili di essere aggiornate di pari passo con il celere sviluppo tecnologico.
Per tali ragioni, si è scelto di adottare una tecnica di tipizzazione che, pur impiegando nuove terminologie, non si concentra tanto sulla tecnologia utilizzata, quanto si focalizza più in generale sulle finalità perseguite, o ancora, sugli eventi realizzati. È così che lo strumentario di diritto sostanziale adottato nel nostro sistema penale sembra esser in grado di apprestare strumenti di qualificazione giuridica sempre attuali. [60]
L’accesso abusivo ad un sistema informatico o telematico
Si passi ora ad una breve rassegna delle disposizioni normative che più possono inquadrare giuridicamente le condotte di Data breach per come ivi descritte.
L’esigenza di perseguire l’accesso abusivo a sistemi informatici emerse già alla fine degli anni ’80 quando, precisamente nel 1989, suddetto reato fu inserito nella sopraricordata “lista minima” delle condotte informatiche abusive, proposta dal Consiglio d’Europa nella Raccomandazione sulla Criminalità Informatica, per poi esser così recepito nel Codice penale italiano con la legge n. 547 del 1993, seguendo l’approccio “old wine in new bottles”,[61] che contempla l’accostamento dei cybercrimes ai reati tradizionali.
Più nel dettaglio, con la legge 547/93 sono state introdotte all’interno della Sezione IV, capo III, del titolo XII del Codice penale, dedicata alla disciplina dei delitti contro l’inviolabilità del domicilio, tre disposizioni (gli artt. 615-ter, 615-quater, 615-quinquies) riguardanti, rispettivamente: l’accesso abusivo ad un sistema informatico o telematico, la detenzione e diffusione abusiva di codici di accesso a sistemi informatici o telematici, nonché la diffusione di programmi diretti a danneggiare o interrompere un sistema informatico.
Ebbene si parta dall’art 615-ter ragionando in primo luogo sulla sua collocazione normativa, ossia nella parte del codice penale per l’appunto riservata ai delitti contro la persona, ed in particolare, nella sezione dedicata alla tutela del domicilio, come a voler dire che il sistema informatico vada in qualche modo assimilato ad una privata dimora.[62]
Nella relazione accompagnante il disegno della citata legge del 1993, il legislatore riconosceva espressamente come i sistemi informatici e telematici rappresentassero ormai “una espansione ideale dell’area di rispetto pertinente al soggetto interessato” a cui, dunque, estendere la tutela della riservatezza della sfera individuale, così come garantito dall’art. 14 della Costituzione.[63]
In tal modo si sono mossi i primi passi verso la formulazione della nozione di “domicilio informatico”,[64] inteso proprio quale spazio ideale di pertinenza della persona (fisica o giuridica): i sistemi informatici e telematici, al pari del domicilio, rappresentano ambienti che devono rimanere riservati e conservati al riparo da ingerenze e intrusioni altrui, luoghi dunque inviolabili, delimitati da confini virtuali paragonabili a qualunque altro spazio privato, in cui un soggetto esplica liberamente la sua personalità in tutte le sue manifestazioni, ed esercita il proprio diritto allo ius excludendi alios.[65]
Di conseguenza l’art 615-ter (con una formulazione simmetrica rispetto all’art 614 c.p.[66]) punisce, nell’ipotesi base, con la pena della reclusione sino a tre anni, colui che si introduce abusivamente, o si mantiene contro la volontà espressa o tacita di chi ha diritto di escluderlo, in un sistema informatico o telematico protetto da misure di sicurezza.
Stando a tale disposizione risulta passibile di esser punito tanto chi senza esservi autorizzato (da qui il carattere della abusività[67]) entra nel sistema altrui, che il soggetto, pur autorizzato, il quale si mantiene nel sistema oltre i limiti temporali e le modalità consentite: si noti come in entrambi i casi si venga puniti anche se l’introduzione nel sistema non comporti danni o manomissioni, in quanto bene giuridico protetto dalla norma non pare essere l’integrità del sistema informatico o la riservatezza dei dati ivi contenuti, bensì, come poi confermato dalle pronunce dei giudici di legittimità,[68] risulta tutelato il domicilio informatico, quale luogo riservato, nonché estensione naturale del domicilio materiale. [69]
Così come avviene infatti per la violazione di domicilio, che si consuma quando un soggetto si introduce nell’abitazione altrui senza il permesso, la violazione di domicilio informatico, si realizza nel momento in cui un soggetto abusivamente acceda al sistema altrui, risultando ad ogni modo irrilevanti, ai fini della sussistenza del reato, punito a titolo di dolo generico, le finalità specifiche (quali trarre profitto dall’ottenimento di informazioni riservate, o cagionare danni) che abbiano soggettivamente motivato l’ingresso nel sistema, salvo una loro rilevanza per integrare diverse ed ulteriori fattispecie criminose.[70]
Chiaro è infatti, e lo si è potuto capire discorrendo dei casi di Data breach, come l’accesso abusivo sia solitamente prodromico alla realizzazione di reati più gravi, come il danneggiamento di sistemi informatici, nonché connesso alle ancora più frequenti richieste di pagamento di riscatti per ripristinare il sistema stesso violato.
Andando ad operare poi una analisi letterale della norma si aggiunga che una “introduzione”, penalmente rilevante, in un sistema si concretizzi mediante la lettura dei dati ivi contenuti, o eventualmente una loro copiatura:[71] tali condotte, assieme a quella del “trattenimento” nel sistema, devono avvenire invito domino, ossia contro la volontà del titolare del diritto all’esclusione.
Ancora, mentre l’art 614 c.p. consente di tutelare qualsiasi abitazione o privata dimora, l’art 615-ter tutela soltanto quei sistemi informatici o telematici che risultano “protetti da misure di sicurezza”, scelta questa non ampiamente condivisa dai commentatori, in quanto percepita da certi autori al pari di un “proteggo solo le abitazioni munite di una serratura antiscasso”, senza contare che rimangono diversi problemi interpretativi circa cosa si debba intendere per misura di sicurezza.
Parte della dottrina ritiene che non si tratti di mezzi di protezione del luogo ove trovasi il computer (si pensi a lucchetti, porte, guardiani), ossia le cosiddette misure di sicurezza fisico-materiali, bensì mezzi di protezione aventi ad oggetto direttamente ed esclusivamente il sistema informatico o telematico, ossia le cosiddette misure di sicurezza logico-tecniche (si pensi alle password, o alla cifratura dei dati)[72]. Altri, prendendo spunto dal fatto che si parli di misure di sicurezza al plurale, ritengono che una semplice parola chiave o un codice d’accesso non sarebbero sufficienti: le predette misure dovrebbero anzi essere intese come qualcosa di più complesso di una semplice password.[73]
Sembra comunque da preferire la tesi, accolta dalla giurisprudenza consolidata, secondo cui risulta sufficiente una qualunque misura di protezione, che sia anche banale e facilmente aggirabile, appunto perché la ratio sottesa all’inserimento di tale requisito è quella di richiedere un impegno effettivo, da parte dell’interessato, tenuto così a predisporre misure di sicurezza, quali elementi in grado di rendere esplicita e inequivoca all’esterno la propria volontà di riservare l’accesso solo a determinate persone.
Per quanto riguarda le non specificate nozioni di “sistema telematico ed informatico”, queste sono volutamente lasciate in forma aperta dal legislatore, affinché possano essere inquadrate di pari passo e correlatamente allo sviluppo tecnologico.[74]
Per ciò che propriamente attiene alle nozioni di tempus e locus commissi delicti, seguendo la dottrina maggioritaria, si tratterebbe di reato istantaneo, consumantesi nel momento stesso in cui l’agente non autorizzato accede al sistema (o di reato istantaneo ad effetto permanente nell’ipotesi in cui questi vi permanga), ed in quell’esatto luogo in cui è presente il cosiddetto “terminale periferico”, da cui il soggetto agente, quindi da remoto, digita le credenziali di autenticazione, esegue il login ed accede al sistema, superando le misure di sicurezza predisposte, risultando perciò assolutamente irrilevante il luogo fisico in cui si trova effettivamente il server centrale.[75]
In conclusione, si evidenzi come i commi secondo e terzo della norma in discorso contemplino alcune ipotesi aggravate, con rispettive sanzioni più severe, per quel che ivi interessa si noti come si abbia un incremento di pena qualora: dal fatto derivi la distruzione o il danneggiamento del sistema, o l’interruzione totale o parziale del suo funzionamento, ovvero la distruzione o il danneggiamento di dati, informazioni o programmi ivi contenuti; ed anche qualora i sistemi informatici o telematici in oggetto siano di interesse pubblico, quale chiaramente è il settore della sanità.[76]
La detenzione e diffusione abusiva di codici di accesso a sistemi informatici o telematici
Si è appreso come la riuscita di una intrusione in un sistema informatico dipenda in primo luogo dall’impiego di password e procedure d’accesso, passibili di essere rubate o scoperte con facilità.
Per tale ragione il legislatore è intervenuto in ottica preventiva, delineando una anticipazione della soglia della punibilità, configurando la fattispecie de quo quale reato di pericolo, ed andando così a sanzionare le condotte di detenzione e diffusione abusiva (ossia “illegittima”) di codici di accesso, quali condotte oggettivamente prodromiche ad una successiva indebita intrusione nei sistemi informatici medesimi.
L’art. 614-quater risulta di notevole ampiezza, dal momento che delinea alternativamente come illecite non solo le condotte del procurarsi, riprodurre (ossia duplicare o creare autonomamente), diffondere (divulgare in modo indifferenziato), comunicare (render noto ad un numero chiuso di soggetti), nonché consegnare codici d’accesso, ma altresì il fornire indicazioni tecniche riservate od istruzioni idonee a svelare il metodo attraverso cui si possano aggirare, neutralizzare o superare le barriere di accesso al sistema, così da coprire ogni sorta di comportamento che possa consentire a terzi di acquisire la possibilità di accedere abusivamente a sistemi informatici, anche solo implementandone il patrimonio di conoscenze.[77]
In tutti i casi delineati, ai fini della sussistenza del reato, risulta necessario che tali condotte siano rette dal dolo specifico, consistente nel fine di procurare a sé o ad altri un profitto o di arrecare ad altri un danno. Va richiamata a tal proposito la nozione ampia di “profitto”, elaborata dalla giurisprudenza per i reati contro il patrimonio, secondo cui tale vantaggio può essere anche di natura non strettamente patrimoniale (ad esempio qualora il soggetto agisca spinto da mero movente di soddisfazione morale).
Per quanto concerne poi il rapporto fra le due fattispecie incriminatrici agli art. 615-ter e 615-quater si è espressa recentemente la Corte di Cassazione, pronunciatasi per l’appunto su di un caso in materia di accesso abusivo a sistema informatico ed illecita acquisizione ed utilizzo di codici d’accesso.
Come spiegato nella pronuncia “I delitti di cui agli artt.. 615-ter e 615-quater sono posti a tutela del medesimo bene giuridico, ovvero il c.d. “domicilio informatico”, che l’art 615-quater protegge in misura meno ampia (ovvero limitatamente alla riservatezza informatica del soggetto) e l’art 615-ter più incisivamente, operando un più ampio riferimento al domicilio informatico tout court, quale spazio ideale di esclusiva pertinenza di una persona fisica o giuridica”.
La Suprema Corte ha enunciato così il principio di diritto secondo il quale, poiché il delitto di detenzione di codici d’accesso costituisce l’antecedente necessario del più grave reato di accesso abusivo a sistemi informatici, in caso di contestazione dei due delitti in riferimento al medesimo contesto spazio-temporale ed in danno dello stesso soggetto passivo, il primo reato dovrà considerarsi assorbito nella seconda e più grave fattispecie.[78]
Ancora, similmente a quanto previsto per l’accesso abusivo, anche l’art 615-quater, al suo secondo comma, prevede sanzioni più severe qualora il fatto sia posto a danno di un sistema informatico o telematico utilizzato dallo Stato, o da altro ente pubblico o da impresa esercente pubblici servizi o di pubblica necessità, oppure altresì quando venga commesso con abuso della qualità di operatore di sistema.
La ratio dietro all’ultima ipotesi aggravata sopra elencata si rinviene nel voler punire più severamente comportamenti illeciti di agevole commissione, dato che l’operatore di sistema, in ragione delle sue funzioni ed attività, si trova in una evidente posizione di vantaggio dal punto di vista attivo, avendo la possibilità di accedere al sistema, alle sue aree riservate e di controllarne le operazioni.
Si specifichi infine come vada considerato “operatore di sistema” non soltanto il tecnico che si trovi ad operare come programmatore o analista sull’hardware o sul software di un sistema informatico, ma anche qualsiasi soggetto che per le funzioni svolte si trovi ad intervenire su di questo stesso in forza di un titolo che glielo consente o glielo impone (si pensi ad un contratto per l’assistenza e/o manutenzione di un sistema informatico), volendosi sanzionare anche il tradimento della fiducia riposta dal titolare del sistema in chi professionalmente dovrebbe prendersene diligentemente cura.
La diffusione di programmi diretti a danneggiare o interrompere un sistema informatico
L’elemento soggettivo del dolo specifico e la ratio di anticipare la protezione dei sistemi informatici vanno a connotare anche la successiva norma, di cui all’art. 615-quinquies, disciplinante una delle condotte maggiormente pericolose per l’integrità dei sistemi informatici, quale è la divulgazione di programmi informatici aventi effetti distruttivi (ipotesi tipica sono i c.d. virus informatici, frequenti cause di alterazione e danneggiamento dei sistemi in cui riescono a diffondersi e riprodursi).
Si conceda una breve digressione, senza pretesa di completezza.
Il virus è un programma caratterizzato dalla possibilità di espandersi e riprodursi all’interno del software in cui è stato inserito, “infettando” altri programmi e compromettendone la funzionalità. È solitamente di dimensioni molto ridotte (da pochi byte ad alcuni kilobyte) ed è specializzato per eseguire soltanto poche e semplici operazioni impiegando il minor numero di risorse, in modo da rendersi il più possibile “invisibile”.
Un virus di per sé non è un programma eseguibile in maniera autonoma, per attivarsi invero necessita di un software ospite: il virus cioè inserisce una copia di se stesso nel file eseguibile, alterandolo, ed in questo modo quando un utente andrà a “lanciare” il programma infettato, dapprima verrà impercettibilmente eseguito il virus e poi, regolarmente, il programma stesso, e mentre dunque l’utente vedrà, ignaro, l’esecuzione del programma lanciato, non si accorgerà del fatto che il virus sia attualmente in esecuzione e stia compiendo tutte le varie operazioni contenute nel suo codice.
Programmi virus circolano in rete, come anche nei messaggi di posta elettronica, ma possono ugualmente essere contenuti in supporti esterni quali floppy disk, pen drive, cd-rom e dvd.
Sicuramente diverse possono essere le motivazioni sottostanti alla creazione e diffusione di programmi virus, dal comportamento semplicemente vandalico, a comportamenti di natura estorsiva, alla volontà di compromettere la funzionalità di sistemi informatici per ragioni concorrenziali o per interessi economici (si pensi a virus diffusi da tecnici informatici coscienti del fatto che vi sia la possibilità di esser chiamati a ripristinare l’efficienza del sistema).
Tornando alla norma de quo, anch’essa delinea una tutela preventiva, strutturandosi quale reato di pericolo astratto, dal momento che si prefigge di sanzionare condotte propriamente prodromiche rispetto ad un eventuale vero e proprio danneggiamento o malfunzionamento del sistema, che, laddove si realizzi, verrebbe tutt’al più punito ai sensi degli articoli 635-bis e seguenti.
Non vi è dubbio quindi che il reato si consumi anche se il programma nocivo non sia ancora stato inserito in alcun sistema informatico o non abbia ancora prodotto i suoi effetti, ma possieda in concreto le tipiche potenzialità distruttive, come nel caso di virus a tempo od attivazione collegata a particolari condizioni.[79] Suddetto arretramento della soglia di punibilità è determinato dal paradigma preventivo ad oggi dominante: se il fine del diritto penale è invero impedire eventi dannosi o pericolosi, è necessario anticipare la soglia della risposta punitiva allo stadio della realizzazione di atti idonei a determinare tali esiti infausti od addirittura a quella del presunto pericolo derivante da uno specifico comportamento.[80]
Altrettando ovvio è come tale operazione vada a collidere con l’assunto per il quale la sanzione maggiormente afflittiva della libertà personale dovrebbe sopraggiungere soltanto ove si accerti un fatto materiale connotato da reale disvalore e a condizione che non sia rintracciabile, nell’ordinamento giuridico nel suo complesso, un altro strumento in grado di arrecare efficace e pronta risposta al di fuori del diritto penale, dovendosi perciò tendenzialmente evitare i reati di mera disobbedienza e trovare rimedi giuridici alternativi per argine certe pratiche e comportamenti.
La disposizione in questione comunque, per come modificata ed ampliata dalla legge 48/2008, sanziona colui che abusivamente procura, detiene, produce, riproduce, importa, diffonde, comunica, consegna o in ogni altro modo mette a disposizione di altri apparecchiature, programmi, o dispositivi informatici vietati, il tutto allo scopo di danneggiare illecitamente un sistema informatico o telematico (o i dati ivi contenuti), ovvero di favorire l’interruzione, totale o parziale, od altresì l’alterazione del funzionamento del sistema medesimo.[81]
Si noti come per integrare la fattispecie criminosa possa bastare anche una consapevolezza ben minore del fine di distruzione o danneggiamento: a tal proposito infatti la Giurisprudenza di merito ha ritenuto sufficiente che vi sia l’accertata volontà dell’agente di diffondere il programma unita alla semplice consapevolezza dei suoi concreti effetti.
Opinioni discordanti in dottrina si registrano invece nei riguardi del bene giuridico protetto: secondo un primo orientamento la norma sarebbe posta a presidio del medesimo bene giuridico di cui agli artt. 615-ter e 615-quater, dotando così il domicilio informatico di una tutela rafforzata contro quelle condotte che, per la frequenza e la gravità dei danni che sono in grado di cagionare, rappresentano la minaccia maggiore alla sua integrità.[82]
Viceversa altri indirizzi di pensiero individuano il bene giuridico tutelato nella nozione di patrimonio (nella sua accezione di corretto funzionamento di un sistema informatico e di integrità dei dati ivi contenuti), in tal caso sarebbe stata allora più opportuna una collocazione sistematica della fattispecie all’interno del titolo XIII del codice penale (quale atto a disciplinare per l’appunto i delitti contro il patrimonio).[83]
In merito infine al rapporto fra l’art 615-quinquies e i reati informatici previamente trattati, si evidenzi come, in una sentenza di merito, si sia riscontrato il concorso proprio con l’art 615-ter di accesso abusivo ai sistemi informatici: il virus diffuso nel caso di specie aveva difatti consentito l’accesso ad un sistema informatico violandone le “barriere” protettive.[84]
Per quanto riguarda invece il rapporto con gli artt. 635-quater e quinquies (che verranno trattati nel dettaglio in seguito, in tema di attacchi ransomware), relativi al danneggiamento di sistemi informatici e telematici, ovvio è che vi sia una chiara interconnessione con la fattispecie de quo: in quest’ultima, quale reato di pericolo, le condotte previste verranno punite di per sé, prescindendo dalla verificazione del danno che, semmai, laddove in concreto realizzatosi verrà punito propriamente ex artt. 635- bis e 635-quater.
Si concluda sottolineando come i reati informatici sopra analizzati rientrino a tutti gli effetti fra i reati presupposto previsti dall’art 24-bis del D.lgs. del 2001 n. 231, per come modificato dalla legge 48/2008, ai fini della responsabilità penale degli enti: è stato infatti superato il principio per cui societas delinquere non potest ed è stato delineato come anche gli enti possano esser chiamati a rispondere dei reati posti in essere dai loro amministratori, dirigenti e dipendenti se realizzati nell’interesse o a vantaggio dell’ente medesimo.
All’esordio del suddetto del decreto legislativo (art. 1, comma II) si precisa tuttavia come le disposizioni in esso previste si applichino “agli enti forniti di personalità giuridica e alle società e associazioni anche prive di personalità giuridica”, precisando al terzo comma che saranno viceversa esclusi da tale disciplina “lo Stato, gli enti pubblici territoriali, gli altri enti pubblici non economici, nonché gli enti che svolgono funzioni di rilievo costituzionale”.
Di conseguenza, ed è il motivo per cui si è voluto inserire l’argomento in trattazione, la dottrina correttamente esclude dal novero dei possibili destinatari della disciplina anche altri soggetti giuridici di natura pubblica che, pur non esercitando pubblici poteri, non si ritiene opportuno possano esser destinatari delle sanzioni indicate nel decreto legislativo n. 231, fra cui si evidenziano: le Aziende ospedaliere e le Aziende sanitarie locali.[85]
Quindi sebbene il D.lgs. 231/2001 possa applicarsi a tutti i soggetti privati del comparto sanità, in quanto inevitabilmente rientranti nelle definizioni di “enti forniti di personalità giuridica/società e associazioni anche prive di personalità giuridica” (quali case di cura, cliniche private, società che gestiscono strutture ospedaliere etc.), le problematiche applicative affiorano nella disciplina relativa agli enti pubblici.
Così infatti la Corte di Cassazione, con la sentenza n. 28699/2010 ha chiarito che
Il tenore testuale della norma è inequivocabile nel senso che la natura pubblicistica di un ente è condizione necessaria, ma non sufficiente, all’esonero dalla disciplina in discorso, dovendo altresì concorrere la condizione che l’ente medesimo non svolga attività economica. [..] Ogni società, proprio in quanto tale, è costituita pur sempre per l’esercizio di un’attività economica al fine di dividerne gli utili”. Per cui, pensando alle Aziende sanitarie locali, queste ultime ai sensi dell’art 3 del D.lgs. 502/1992 risultano qualificabili come enti pubblici operanti secondo le norme del diritto privato ed agenti con il principio di pareggio di bilancio, non risultando pertanto caratterizzate da finalità lucrative dovranno ritenersi escluse dall’ambito applicativo della 231. Pur tuttavia, in ambito regionale la tendenza rimane quella di recepire la disciplina 231 in una ottica di prevenzione da reato, ed anche quale ulteriore garanzia della migliore organizzazione e trasparenza delle PA. [86]
Profili di interdisciplinarietà: il Codice Privacy
Chiaro è che, inevitabilmente, in caso di commissione di reati informatici, si vadano ad intersecare profili di interdisciplinarietà con il trattamento illecito dei dati personali, tanto che una qualsiasi organizzazione, sia essa titolare o responsabile del trattamento, davanti, ad esempio, ad un accesso abusivo al proprio sistema informatico, dovrà avviare indagini interne al fine di verificare se vi sia stata anche una effettiva compromissione dei dati personali ivi trattati ed eventualmente aprire la regolare procedura per la gestione dei casi di violazione dei dati ai sensi dei, già visti in precedenza, articoli 33 e 34 del Regolamento Ue 2016/679.
Tra le varie tipologie di attacchi informatici infatti ve ne sono diversi caratterizzati sovente da una condotta di osservazione, illecita, delle abitudini del soggetto targettizzato, volta ad acquisire il maggior numero di informazioni possibili, così difatti argomenta K. D. Mitnick, noto informatico e hacker statunitense trattando del valore nascosto delle informazioni: “qualunque tipo di informazione ha un suo valore economico, che sia poco utile o irrilevante, perché qualsiasi dato che entra in interconnessione con altri dati può consentire di risalire ad infinite informazioni sempre più importanti o significative”.[87]
È dunque naturale che, affrontando il tema dei reati informatici, vengano in rilievo anche nozioni quali la tutela e la disciplina in materia di riservatezza e protezione dei dati personali.
Si ripeta in questa sede che il Considerando 149, in combinato disposto con l’art. 84 del GDPR, sanciscano come i singoli Stati debbano stabilire le disposizioni concernenti le sanzioni penali applicabili per le violazioni del Regolamento Ue e delle norme nazionali attuative. Nel nostro ordinamento si è scelto così di mantenere in vigore quanto stabilito dal Codice della Privacy, emanato nel 2003, ed in particolare dagli articoli 167 e successivi, così come riformati dal d.lgs. n.101/2018.
Detta soluzione ha tuttavia restituito all’interprete un sistema caotico, ossia caratterizzato da continui rimandi tra normative eterogenee e da conseguenti problemi interpretativi nascenti dalla sovrapposizione di diverse fonti. Ne è scaturito cioè un corpus iuris connotato da sistemi sanzionatori disomogenei, passibili anche di entrare in conflitto fra loro, provocando un inevitabile vulnus ai principi di logicità, ragionevolezza, nonché al canone di proporzione[88]
Infatti, come si vedrà, la scelta di utilizzare norme penali in bianco per sanzionare comportamenti lesivi della privacy mal si concilia con i principi di tassatività e di determinatezza che dovrebbero invece caratterizzare i precetti penali. La tecnica del rinvio poi rischia non solo di estendere eccessivamente l’ambito di rilevanza penale a fatti che sarebbero privi di quel disvalore, ma soprattutto, porta con sé il rischio che il rimando a norme secondarie renda l’opera di interpretazione della condotta vietata di estrema difficoltà tanto per l’interprete, quanto soprattutto per il cittadino che, come noto, dovrebbe invece conoscere il precetto prima della possibile commissione del fatto di reato, con conseguenze negative in termini di certezza del diritto e della pena.[89]
Si faccia a questo punto riferimento ad una delle più importanti norme del diritto penale della privacy, ossia l’art. 167 del Codice in materia di protezione dei dati personali che al primo comma punisce colui che, titolare o responsabile del trattamento, al fine di trarre per sé o per altri profitto ovvero di arrecare danno all’interessato, “operando in violazione di quanto disposto dagli articoli 123[90], 126[91] e 130[92] o dal provvedimento di cui all’articolo 129[93] arreca nocumento[94] all’interessato”.
Ancora, ai sensi del secondo comma, è punito colui che, al fine di trarre per sé o per altri profitto ovvero arrecare danno all’interessato, “procedendo al trattamento dei dati personali di cui agli articoli 9 e 10 del Regolamento[95], in violazione delle disposizioni di cui agli articoli 2-sexies e 2-octies[96] o delle misure di garanzia di cui all’articolo 2-septies[97], arreca nocumento all’interessato”.
Come sopra anticipato, si tratta di una norma penale in bianco in quanto non contiene una descrizione esaustiva delle condotte vietate, ma anzi, per l’identificazione del precetto vietato, fa rinvio a molteplici altre norme del Codice privacy, stabilenti criteri di liceità di determinati trattamenti di dati personali, la cui violazione andrà ad integrare la fattispecie de quo.
Oltre a ciò, talvolta la condotta a cui la norma fa riferimento è addirittura contenuta in altre disposizioni di rango secondario e di futura emanazione, o in provvedimenti generali del Garante, con le evidenti conseguenze, di cui già si accennava, in termini di vulnus ai principi di tassatività e di determinatezza della fattispecie.
In conclusione si ricordi come uno dei principi cardine del diritto penale sia il ne bis in idem, ossia il divieto di esser sottoposti a processo, o di essere puniti due volte, per il medesimo fatto. Da qui discende il problema del coordinamento fra le conseguenze previste dal GDPR (ed il procedimento innanzi al Garante), con le conseguenze penali ed il relativo processo.
Tale coordinamento risulta in parte gestito proprio dai commi 4 e 5 della fattispecie in esame, i quali si preoccupano di delineare, in via generale, le modalità di collaborazione tra i due soggetti: Garante ed il Pubblico Ministero.
Si prevede infatti che sia il Pubblico Ministero, alla ricezione della notizia di reato di cui all’art. 167, ad informare senza ritardo il Garante, e che sia viceversa quest’ultimo, nell’ipotesi in cui nel corso delle proprie attività ispettive rinvenga elementi da cui si possa presumere sussistente il reato, a trasmettere la relativa documentazione raccolta al Pubblico Ministero. L’Autorità Garante comunque, in virtù dei poteri autorizzativi e di accertamento riconosciuti ex lege, potrà partecipare alle indagini della Pubblica Accusa e svolgerne delle proprie, al fine di raccogliere elementi di prova.
È come se l’Autorità assumesse il ruolo atipico di “coordinatore tecnico” delle indagini preliminari: al termine infatti della sua attività istruttoria dovrà redigere un parere motivato da indirizzare al Pubblico Ministero, la cui decisione in merito all’esercizio dell’azione penale sarà inevitabilmente influenzata. Entrambe le Autorità dovrebbero infine modulare le rispettive sanzioni, conformemente a quanto previsto dal Considerando 149 del Regolamento Ue e nel rispetto dello stesso ne bis in idem, ed in particolare al sesto comma viene prevista una riduzione della sanzione penale nel caso in cui sia già stata riscossa a carico dell’imputato una sanzione amministrativa pecuniaria.[98]
L’analisi dei data breach sanitari rivela un quadro allarmante: il settore healthcare risulta tra i più vulnerabili agli attacchi informatici, con conseguenze che vanno ben oltre il danno economico, compromettendo direttamente la sicurezza dei pazienti. Abbiamo esaminato come la protezione dei dati personali sanitari richieda un approccio integrato tra misure tecniche, organizzative e normative, evidenziando l’importanza del principio di accountability del GDPR.
Nel prossimo capitolo approfondiremo specificamente gli attacchi ransomware, la tipologia di cyberattacco più devastante per il settore sanitario, analizzando le modalità di prevenzione e risposta a queste minacce sempre più sofisticate. Per una comprensione completa del fenomeno, scarica il white paper di Maria Vittoria Zucca dal titolo “La cybercriminalità nel settore sanitario: anamnesi, diagnosi e prognosi di una ‘patologia’ informatica”.
Fonti:
[1] Per ICT (acronimo di Information ad Communications Technology) si intendono tutti i processi e le pratiche connesse alla trasmissione, ricezione ed elaborazione dei dati e delle informazioni.
[2] Per una sua approfondita analisi si rimanda al Rapporto Clusit 2020 sulla sicurezza ICT in Italia reperibile al sito internet https://clusit.it/
[4] E. Macrì, “Il quadro giuridico del cyber risk”, in Capire il rischio cyber: il nuovo orizzonte in sanità, whitepaper SHAM Italia, 2021, pp. 15 – 22.
[6] Un attacco alla supply chain (chiamato anche attacco di terze parti) avviene quando l’aggressore accede alla rete di un’azienda tramite una terza parte fornitrice. Questo tipo di attacco necessita di un software o di una singola applicazione compromessa per diffondere il malware nell’intera catena di fornitura. Di solito prende di mira il codice sorgente di un’applicazione, inserendo così il proprio codice dannoso nel sistema.
[7] Per spoofing ci si riferisce all’impersonificazione da parte di un hacker di un altro dispositivo o di un altro utente su una rete al fine di impadronirsi di dati, diffondere malware o superare dei controlli di accesso.
[8] Per phishing si intende quel tipo di attacco che consiste nell’inviare e-mail malevoli scritte appositamente con lo scopo di spingere le vittime a cadere nella trappola dei cybercriminali. Spesso lo scopo infatti è di portare gli utenti a rivelare informazioni bancarie, credenziali di accesso o altri dati sensibili.
[9] Ponemon Institute, op. citata supra a nota 117, p. 11
[10] Ponemon Institute, op. citata supra a nota 93, p. 5
[11] A. Gelpi, “La Sicurezza dei dati sanitari”, in Torino Medica. La rivista dell’ordine dei medici chirurghi e odontoiatri della provincia di Torino, anno XXXIII, numero 3-4, 2021, pp. 11-21.
[12] S. Warren, L.D. Brandeis, “The right to Privacy”, in Harvard Law Review, Vol. 4, No. 5, 1890, pp.193-220.
[13] P. Rescigno, Diritti della personalità, Enc. Giur. Treccani, Roma, 1994.
[14] S. Rodotà, Il mondo nella rete. Quali i diritti, quali i vincoli, Laterza-la Repubblica, Roma-Bari, 2014, pp. 27-32
[15] S.B. Barnes, “A privacy paradox: Social networking in the United States”, in First Monday, Issue 11/9, 2006.
[16] Intervento di A. Soro, Presidente dell’autorità Garante per la protezione dei dati personali, Big Data: La nuova geografia dei poteri, in occasione della Giornata Europea della protezione dei dati personali, 30 Gennaio 2017.
[17] Per un dettagliato approfondimento sul tema si rimanda a N. Lugaresi, Internet, privacy e i pubblici poteri negli Stati Uniti, Giuffrè editore, Milano, 2000.
[18] F. Carlino, “L’origine della privacy e l’esigenza di tutelare i dati personali”, in Iusinitinere, Rivista Semestrale di diritto, ISSN 2724-2862, 4 Luglio 2020, aggiornato 13 Luglio 2020, pp. 1-13.
[19] G. Finocchiaro, Il nuovo regolamento europeo sulla privacy e sulla protezione dei dati personali, Zanichelli editore, Bologna, 2017, p. 6.
[20] G. Fornari, Il trattamento dei dati: rischi penali e compliance dell’impresa, Fornari e Associati studio legale, Milano-Roma, Gennaio 2021, p 2-4.
[21] Si pensi, in particolare, alla proposta di Regolamento del Parlamento europeo e del Consiglio che stabilisce regole armonizzate sull’intelligenza artificiale, del 21 Aprile 2021.
[22] Con tale locuzione si indica una ingente mole di dati informatici, le cui caratteristiche sono facilmente riassumibili seguendo il modello delle tre “V”: Volume (grande quantità), Velocità (di generazione dei dati e della loro elaborazione) e Varietà (forte eterogeneità).
[23] G. Fioriglio, “La protezione dei dati sanitari nella Società algoritmica. Profili informatico-giuridici”, in Journal of Ethics and Legal Technologies, Volume 3(2), Novembre 2021, pp. 85-86.
[24] “La Repubblica tutela la salute come fondamentale diritto dell’individuo e interesse della collettività, e garantisce cure gratuite agli indigenti. Nessuno può essere obbligato a un determinato trattamento sanitario se non per disposizione di legge. La legge non può in nessun caso violare i limiti imposti dal rispetto della persona umana”.
[25] “La Repubblica riconosce e garantisce i diritti inviolabili dell’uomo, sia come singolo sia nelle formazioni sociali ove si svolge la sua personalità, e richiede l’adempimento dei doveri inderogabili di solidarietà politica, economica e sociale”.
[26] F. Carlino, “il trattamento dei dati sanitari mediante il dossier sanitario”, in Iusinitinere, Rivista Semestrale di diritto, ISSN 2724-2862, 29 Maggio 2020, pp. 1-3.
[27] Intervento di A. Soro, Presidente del Garante per la protezione dei dati personali, al convegno “La smaterializzazione dei documenti e il suo impatto sul sistema salute”, Roma 6 Maggio 2016.
[28] Ex art. 4 n.7 GDPR per titolare del trattamento di intende “la persona fisica o giuridica, l’autorità pubblica, il servizio o altro organismo che, singolarmente o insieme ad altri, determina le finalità e i mezzi del trattamento di dati personali”.
[30] Ex art. 4 n.8 GDPR per responsabile del trattamento si intende “la persona fisica o giuridica, l’autorità pubblica, il servizio o altro organismo che tratta dati personali per conto del titolare del trattamento”.
[31] L’European Data Protection Board ha fissato dei parametri per la valutazione dei fattori che determinano il rischio per le libertà e i diritti degli interessati, tra cui rientrano: il tipo di “breach”, ossia il tipo di violazione; la natura, numero e grado di sensibilità dei dati personali violati; la facilità di associare i dati violati alla persona fisica; la gravità delle conseguenze per gli interessati ed il numero degli interessati esposti al rischio.
[32] L. Smoraldi, M. Strazzullo, “Prevenire è meglio che curare: il compito dell’avvocato in caso di data breach”, in Data Protection Law: diritto delle nuove tecnologie, privacy e protezione dati personali – Rivista online Giuridica Semestrale, n. 2, 2021, p. 73.
[33] Intervento di Luca Bolognini, Presidente dell’Istituto italiano per la privacy, avvocato ICT Legal Consulting, al Convegno Privacy Unolegal , Milano, 14 Giugno 2017.
[34] E. Limone, “Sanità digitale: scenari scatenati da un data breach”, in Agendadigitale.eu, Editore ICT&Strategy, Gruppo Digital360, Milano, 1 Luglio 2019.
[35] Indipendent Security Evaluators, Securing Hospitals: a research study and blueprint, 23 February 2016, p.39
[36] Cass. Civ, sez. I, sentenza 12 Novembre – 31 Dicembre 2020, n. 29982.
37] Per bonifica informatica si intende quel procedimento tramite cui si evidenziano intromissioni illecite all’interno di un sistema informatico.
[38] C. Telmoni (intervento), al talk “Cybersecutity per la sanità digitale: conoscere per non rischiare”, andato in onda il 28 Ottobre 2021, nella prima giornata di FORUM PA Sanità, evento digitale organizzato da FPA e P4I-Partners4Innovation.
[39] Intervista a Agostino Ghiglia, componente del Garante per la protezione dei dati personali, “La sanità la più colpita. Proteggere reti e dati sensibili”, di Luigi Garofalo, 9 Novembre 2021.
[40] Il termine dark web indica un insieme di contenuti e servizi della Rete nascosti ai motori di ricerca, necessitanti di appositi programmi per essere raggiunti.
[41] Intervista ad Antonello Soro, presidente dall’Autorità Garante per la privacy dei dati personali, “Il Garante: un caso di straordinaria gravità”, riportata sul Corriere della Sera – Ed. Bergamo, 31 Ottobre 2013, di G. Ubbiali
[42] Si noti come CISO sia l’acronimo di Chief Information Security Officer.
[43] R. McElroy, T. Kellermann, Healthcare Cyber Heists in 2019: 20 leading CISOs from the healthcare industry offer their perspective on evolving cyberattacks, ransomware & the biggest concerns to their organizations, Carbon Black, June 2019.
[44] Per island hopping si intende una tecnica di attacco informativo utilizzata dagli hacker per infiltrarsi nella rete informatica di una azienda sfruttando le strutture satellite, ossia tante organizzazioni più piccole e con standard di sicurezza IT maggiormente vulnerabili rispetto all’obiettivo principale. Ecco che, bucando la rete informatica del fornitore, l’hacker riesce a risalire fino alla rete dell’azienda target principale.
[45] N. Griffin, Health correspondent, “Patient data 10-15 times more valuable than credit card data”, in Irish Examiner, May 19 2021.
[46] Per ulteriori immagini esemplificative si rimanda al report di Trend Micro, Cybercrime and Other Threats Faced by the Healthcare Industry, Mayra Rosario Fuentes Forward-Looking Threat Research (FTR) Team, 2017, pp.13-17
[47] Intervento Prof. Matteo Bonfanti, al convegno “Cybersecurity e protezione dei dati personali nella sanità: un nodo strategico per l’interesse nazionale”, Fondazione ICSA in partnership con Link Campus University, 16 Giugno 2022.
[48] V. Franzellitti, G. Cavalcanti, intervista a Roberto Setola dell’Università Campus Bio-Medico di Roma durante la seconda giornata del convegno “Big Data in Health”, riportata in Sanità Informazione, 3 Ottobre 2019.
[49] Notizia riportata sui giornali locali quali Padovaoggi, “Attacco hacker Ulss 6 Euganea, pubblicati oltre 9.300 documenti”, 16 Gennaio 2022.
[51] Intervista a Pierguido Iezzi, pubblicata il 14.05.2022, ad opera di Massimo Canorro, sul quotidiano sanitario nazionale Nurse24.
[52] Per Cyber Threat Intelligence (CTI) si intende una attività di raccolta di informazioni provenienti da varie fonti, in merito ad attacchi informatici che colpiscono o sono potenzialmente in grado di offendere la sicurezza di una organizzazione. Tale patrimonio conoscitivo acquisito viene poi utilizzato per attuare consapevolmente strategie ed azioni utili alla prevenzione, alla mitigazione e all’eradicazione della minacce, a partire da una corretta valutazione dei rischi.
[53] T. Pietrella, “Reati informatici e concorso di norme: come l’evoluzione tecnologica informa il diritto penale. Il caso delle Botnets”, in Discrimen – Rivista di diritto penale, ISSN 2704-6338, 2.12.2021, pp. 2-7.
[54] P. Galdieri, “Il reato informatico”, in G. Marotta (a cura di), Tecnologie dell’informazione e comportamenti devianti, Edizioni Universitarie di Lettere Economia Diritto, Milano, 2004 , pp. 29-74.
[55] V. Frosini, Contributi ad un diritto dell’informazione, Liguori, Napoli, 1991, pp. 165 ss.
[56] Comitato dei Ministri del Consiglio d’Europa, Raccomandazione Sur la criminalité en relation avec l’ordinateur, 13 Settembre 1989.
[58] R. Flor, D. Falcinelli, S. Marcolini, La giustizia penale nella “rete”: le nuove sfide della società dell’informazione nell’epoca di Internet, Edizioni DiPlaP, Milano, 2015, p. 101.
[60] E. Albamonte, “Il reato informatico nella prassi giudiziaria: le linee guida internazionali per il contrasto ai nuovi fenomeni criminali”, in Rivista Elettronica di Diritto, Economia, Management, n.3, 2013, p.146-157.
[61] S. Brenner, “Defining cybercrime: a review of state and federal Law”, in R.D. Clifford, Cybercrime: The investigation, prosecution of a computer-related crime, Carolina Academic Press, Durham, 2006, pp. 15-104.
[62] Il domicilio, nel diritto privato italiano, corrisponde ex art. 43 c.c al luogo in cui una persona “ha stabilito la sede principale dei suoi affari ed interessi” , per tali intendendosi tanto quelli di natura personale, quanto quelli di natura sociale, politica ed economica.
[63] Art. 14 Cost. “Il domicilio è inviolabile. Non vi si possono eseguire ispezioni o perquisizioni o sequestri, se non nei casi e modi stabiliti dalla legge secondo le garanzie prescritte per la tutela della libertà personale”.
[64] L. Levita, “La disciplina sostanziale: i reati informatici in senso stretto”, in G. D’aiuto (a cura di) I reati informatici: disciplina sostanziale e questioni processuali, Giuffrè Editore, 2012, pp. 3
[65] Cfr. Cass. Pen. Sezioni Unite, Sentenza 26 Marzo 2015, n. 17325.
[66] Art 614 c.p. “Chiunque s’introduce nell’abitazione altrui, o in un altro luogo di privata dimora, o nelle appartenenze di essi, contro la volontà espressa o tacita di chi ha il diritto di escluderlo, ovvero si introduce clandestinamente o con l’inganno, è punito con la reclusione da uno a quattro anni”.
[67] Secondo alcuni autori l’espressione in parola sarebbe del tutto superflua e non aggiungerebbe nulla sotto il profilo interpretativo, poiché utilizzata al solo fine di far virare l’attenzione sull’antigiuridicità della condotta (Cfr. C. Piergallini, “I delitti contro la riservatezza informatica” C. Piergallini, F. Viganò, M. Vizzardi, A. Verri (a cura di) in Delitti Contro la persona, CEDAM, Padova, 2015, pag. 770). La stessa Corte di Cassazione ha criticato la locuzione “abusivamente si introduce” per la sua “forte ambiguità e la conseguente possibilità d’imprevedibili e pericolose dilatazioni della fattispecie penale se non intesa in senso di accesso non autorizzato”, Cass. Sez. V 17 Gennaio 2008 n. 2534.
[68] Cfr. Cass. Sez. V, 26 Ottobre 2012, n. 42021; Sez. V, 31 Marzo 2016 n. 13057.
[69] C. Domenicali, “Tutela della persona negli spazi virtuali”, in Federalismi.it Rivista di diritto pubblico italiano, comparato, europeo, ISSN 1826-3534, n. 7, 28 Marzo 2018, pp. 10-14.
[70] Sul dolo generico richiesto si rimanda alla pronuncia della Cassazione sent. 2012, n. 4694 secondo cui integra il delitto ex art. 615-ter c.p.: “La condotta di colui che, pur essendo abilitato, acceda o si mantenga in un sistema informatico o telematico protetto, violando le condizioni e i limiti risultanti dal complesso delle prescrizioni impartite dal titolare del sistema per delimitarne oggettivamente l’accesso, rimanendo invece irrilevanti, ai fini della sussistenza del reato, gli scopi e le finalità che abbiano soggettivamente motivato l’ingresso nel sistema”.
[71] Cfr. Cass. Pen. Sez. V, 8 Luglio 2008, n. 37322, secondo cui il termine “accesso” deve intendersi non come collegamento fisico, ma logico: un superamento cioè della barriera di protezione del sistema che rende possibile il dialogo col medesimo, di modo che l’agente venga a trovarsi nella condizione di conoscere dati, informazioni e programmi.
[72] R. Borruso, “La tutela del documento e dei dati”, in R. Borruso, G. Buonomo, G. Corasaniti, G. D’Aietti (a cura di), Profili penali dell’informatica, Giuffrè Editore, Milano, 1994, p.29 ss.
[73] G. Ceccacci, Computer Crimes: la nuova disciplina dei reati informatici, FAG, Milano, 1994, pag.70.
[74] Secondo la Convenzione Europea di Budapest sulla Criminalità informatica, stipulata il 23 Novembre 2001 “computer system means any device or a group of interconnected or related devices, one or more of which, pursuant to a program, performs automatic processing of data”.
[75] Cfr. Cass. Sez. Un., sent. 26 Marzo 2015, n. 17325.
[76] Secondo la Cass. Pen. Sez. V, 21 Gennaio 2011, n. 1934 per aversi “sistema informatico di interesse pubblico” non è sufficiente la qualità di concessionario di pubblico servizio rivestita dal titolare del sistema, dovendosi accertare se il sistema stesso si riferisca ad attività direttamente rivolte al soddisfacimento di bisogni generali della collettività.
[77] G. Amato, V. Sandro Destito, G. Dezzani, C. Santoriello, I reati informatici, CEDAM, La biblioteca del penalista, Milano, 2010, pp. 89-96.
[78] Cfr. Cass., Sez. II, Sent. 14/01/2019, n. 21987: “L’art 615quater, in quanto destinato a reprimere condotte prodromiche alla possibile realizzazione del delitto di accesso abusivo ad un sistema informatico o telematico, protetto da misure di sicurezza, e, quindi, pericolose per il bene giuridico tutelato dall’art. 615ter c.p., si atteggia quale necessarioantefatto di detto reato, la cui latitudine lesiva sotto un profilo naturalistico necessariamente le presuppone e ricomprende”.
[79] L. Cuomo. R. Razzante, La nuova disciplina dei reati informatici, Giappichelli, 2009, p.129.
[80] M. Donini, Il volto attuale dell’illecito penale. La democrazia penale tra differenziazione e sussidiarietà, in A. Bernardi, M. Donini, V. Militello, M. Pasa, S. Seminara (a cura di), Collana quaderni di diritto penale comparato, Internazionale ed Europeo, Milano, Giuffrè editore, 2004, p. 104 ss.
[81] Secondo App. Bologna Sez. II, 27 Marzo 2008, sussiste il concetto di “alterazione” di un programma informatico quando lo si manipoli in maniera tale che compia azioni non volute dall’utente, ovvero si modifichino i parametri di funzionamento, anche secondo opzioni e possibilità previste nel programma stesso, contro la volontà dell’utilizzatore.
[82] P. Galdieri, Teoria e pratica nell’interpretazione del reato informatico, Giuffrè editore, Milano, 1997.
[83] G. Pica, Diritto penale delle tecnologie informatiche, UTET, Torino, 1999; F. Mantovani, Diritto penale. Parte Speciale: I, CEDAM, Torino, 2014.
[84] Trib. Bologna, Sez. I Monocratica, Sent. 21 Luglio 2005, n. 11577.
[85] C. Pecorella, “Principi generali e criteri di attribuzione della responsabilità”, In A. Alessandri & al. (a cura di), La responsabilità amministrativa degli enti. D. lgs. 8 giugno 2001 n. 231, Milano, pp. 65-89.
[86] Così ad esempio la Regione Lombardia ha inteso mutuare i principi 231 ai fini dell’introduzione del Codice Etico e dell’implementazione del Modello Organizzativo nelle Aziende Sanitarie Locale ed Ospedaliere, formulando linee guida per l’analisi del rischio.
[87] F. Peluso, La responsabilità nei nuovi reati informatici. Mezzi di ricerca e acquisizione della prova, Maggioli Editore, Gennaio 2020, p. 180.
[88] M. Solinas, “Tutela penale della privacy dopo il Gdpr: la frettolosa giustapposizione delle fonti è scaturigine di un sistema farraginoso che crea confusione, in Responsabilità Civile e Previdenza, fasc. 2, Vol. 85, 1 Gennaio 2020, pp. 663-688.
[89] P. Balboni, F. Tugnoli, “Reati informatici e tutela dei dati personali: profili di responsabilità degli enti”, in Giurisprudenza Penale, 2021/1-bis , pp. 3-8.
[90] L’art. 123 disciplina le modalità con le quali risulta lecito, secondo il codice privacy, il trattamento dei dati di traffico.
[91] L’art 126 si occupa di disciplinare il trattamento dei dati di ubicazione.
[92] L’art 130 disciplina le c.d. “comunicazioni indesiderate” (si pensi alle comunicazioni di marketing).
[93] Ex art. 129 “Il Garante individua con proprio provvedimento, […] le modalità di inserimento e di successivo utilizzo dei dati personali relativi ai contraenti negli elenchi cartacei o elettronici a disposizione del pubblico”.
[94] Secondo Cass. Sez. 3, n. 40103 del 05/02/2015, per nocumento si deve intendere “una concreta lesione della sfera personale o patrimoniale, direttamente riconducibile ad una operazione di illecito trattamento dei dati protetti”.
[95] Il riferimento è al trattamento di particolari categorie di dati personali (che rivelino ad esempio origine razziale o etnica, opinioni politiche, ma anche dati biometrici e genetici).
[96] Si riferiscono al trattamento di categorie particolari di dati personali, necessario per motivi di interesse pubblico rilevante (si pensi ai dati relativi a condanne penali e reati).
[97] Si intendono le misure di garanzia per il trattamento di dati genetici, biometrici e relativi alla salute.
[98] L. Bolognini, E. Pelino, Codice privacy: tutte le novità del D.lgs. 101/2018, Giuffrè Editore, Milano, 2019.
Profilo Autore
Maria Vittoria Zucca, laureata con lode in Giurisprudenza presso l’università degli Studi di Trento, è attualmente dottoranda nel Programma di Dottorato di Interesse Nazionale in Cybersecurity, con istituzione capofila la Scuola IMT Alti Studi di Lucca, ed è affiliata alla Scuola Superiore Sant’Anna, presso l’Istituto Dirpolis (Diritto, Politica e Sviluppo). La sua attività di ricerca si concentra sulla prevenzione, l’indagine ed il contrasto della criminalità informatica, includendo le discipline del diritto penale dell’informatica e della criminologia digitale. Su questi temi è autrice di diverse pubblicazioni scientifiche e partecipa regolarmente a conferenze nazionali e internazionali.
Il ransomware non è più il re, benvenuti nell’era del “parassita digitale”
Il Red Report 2026 di Picus Labs, pubblicato il 10 febbraio 2026, non è il solito bollettino annuale sulle minacce. È un referto autoptico su un modello di attacco che ha dominato un decennio – il ransomware distruttivo – e la certificazione della nascita di qualcosa di più insidioso: il parassita digitale.
Il dataset parla con una chiarezza che lascia poco spazio alle interpretazioni. Picus Labs ha analizzato 1.153.683 file unici, di cui il 94% classificato come malevolo, mappando oltre 15,5 milioni di azioni avversarie sul framework MITRE ATT&CK. Il risultato è una radiografia completa del comportamento offensivo nel 2025, e ciò che emerge rovescia le priorità difensive di migliaia di organizzazioni.
Il dato che definisce l’intero Red Report 2026 è questo: la tecnica “Data Encrypted for Impact” (T1486) – la firma operativa del ransomware – è crollata del 38%, passando dal 21% dei campioni nel 2024 al 12,94% nel 2025. Contemporaneamente, l’80% delle dieci tecniche MITRE ATT&CK più diffuse è ora dedicato a evasione delle difese, persistenza e comando e controllo stealth. La concentrazione più alta di tradecraft stealth mai registrata in sei edizioni del report.
Come ha sintetizzato il Dr. Süleyman Özarslan, co-fondatore e VP di Picus Labs: gli attaccanti hanno capito che è più redditizio abitare l’host che distruggerlo.
Nota metodologica: il Red Report 2026 è prodotto da Picus Security, vendor specializzato in security validation. Questo non ne diminuisce il valore analitico – il dataset di oltre un milione di campioni e la mappatura su MITRE ATT&CK rappresentano uno dei corpus empirici più ampi disponibili sul comportamento avversario – ma è un elemento che il lettore professionista deve considerare nel valutare le raccomandazioni operative, che naturalmente convergono verso l’approccio di validazione continua propugnato dall’azienda.
Dal predatore al parassita: anatomia di un cambio di paradigma
Per comprendere la portata di questo cambiamento, occorre partire da una premessa spesso dimenticata: il ransomware tradizionale – quello che cifra i file e chiede un riscatto – è sempre stato, dal punto di vista dell’attaccante, un modello ad alto rischio e rendimento decrescente.
I dati convergono da fonti indipendenti: Chainalysis ha stimato che nel 2025 solo il 28% delle vittime identificate ha pagato un riscatto, in netto calo rispetto al 62,8% del 2024 e al 78,9% del 2022. I pagamenti on-chain si sono attestati intorno a 820 milioni di dollari, in calo dell’8% rispetto all’anno precedente. Coveware, da un campione diverso e con metodologia differente, riporta percentuali ancora più basse: il 23% nel Q3 2025, con un crollo al 19% per gli incidenti di sola esfiltrazione dati senza cifratura. Le percentuali esatte variano tra le fonti perché coprono campioni e periodi diversi, ma la direzione del trend è univoca e confermata da tutti gli analisti di settore.
Il Red Report 2026 documenta la risposta strategica degli attaccanti a questa crisi di redditività: l’abbandono dell’encryption a favore di ciò che Picus Labs definisce “residenza silenziosa”. Invece di cifrare e fare rumore, il malware moderno si insedia nei sistemi, si mimetizza tra i processi legittimi e opera sotto la soglia di rilevamento per settimane o mesi. L’obiettivo non è più bloccare le operazioni della vittima, ma alimentarsi di credenziali, dati sensibili e accessi privilegiati senza essere scoperto.
È la logica del parassita biologico: l’organismo che uccide il proprio ospite ha vita breve. Quello che lo sfrutta senza ucciderlo prospera.
L’evoluzione in numeri: Red Report 2025 vs Red Report 2026
Prima di analizzare i tratti del parassita digitale, vale la pena inquadrare l’evoluzione anno su anno. Il confronto tra le due edizioni del report rivela una trasformazione accelerata.
Il Red Report 2025, basato su oltre 1 milione di campioni e 14 milioni di azioni malevole mappate su ATT&CK, aveva già identificato l’ascesa degli infostealer e delle campagne multi-stadio come tendenza dominante, con un aumento triplicato del malware mirato ai credential store (T1555 passato dall’8% al 25%). Picus Labs aveva coniato la metafora del “colpo perfetto” (The Perfect Heist) per descrivere campagne di esfiltrazione sofisticate e silenziose.
Il Red Report 2026 segna il passaggio dalla tendenza al paradigma consolidato. La T1555 si stabilizza al 23,49% – un livello ormai strutturale – mentre il calo della T1486 (encryption) dal 21% al 12,94% certifica che il furto di credenziali non è più un complemento al ransomware: lo sta sostituendo come tecnica primaria di monetizzazione. Le tecniche di evasion e persistence sono passate dall’essere “in crescita” (2025) a rappresentare l’80% della top 10 (2026), il dato più alto mai registrato.
In altri termini, ciò che nel 2024 era un segnale debole, nel 2025 era una tendenza, e nel 2026 è il modello operativo dominante. Il Red Report 2026 di Picus Labs cattura il momento in cui la curva si è piegata in modo irreversibile.
Le sei caratteristiche del parassita digitale
Il Red Report 2026 identifica sei tratti comportamentali che definiscono il malware moderno e lo distinguono dalle generazioni precedenti. Non si tratta di tendenze vaghe, ma di pattern empirici osservati su oltre un milione di campioni.
Process Injection come mimetismo molecolare
La Process Injection (T1055) si conferma per il terzo anno consecutivo la tecnica più diffusa, presente nel 30% dei campioni analizzati. Il suo scopo è elementare e devastante: iniettare codice malevolo all’interno di processi legittimi e affidabili del sistema operativo. Una volta che il codice dell’attaccante vive dentro un processo di sistema come svchost.exe o explorer.exe, distinguere l’attività malevola da quella legittima diventa un problema di analisi comportamentale che la maggior parte degli strumenti basati su firme non riesce a risolvere.
La persistenza di questa tecnica in cima alla classifica per tre anni consecutivi racconta una storia precisa: le difese non riescono a tenere il passo. Finché la process injection resta dominante, significa che funziona – e funziona perché le organizzazioni non validano abbastanza i propri controlli contro questa specifica classe di attacco.
Il malware che fa matematica
Il Red Report 2026 documenta per la prima volta un comportamento inedito: campioni di malware come LummaC2 utilizzano la trigonometria – calcolando la distanza euclidea e gli angoli dei movimenti del mouse – per distinguere un utente umano da una sandbox automatizzata. Se il mouse si muove in linea retta, tipico dell’input programmato nelle sandbox, il malware riconosce di essere osservato e rifiuta di attivarsi. Se il movimento è irregolare e curvilineo, come quello di un essere umano, il malware si innesca.
Questo è un salto qualitativo nella sofisticazione dell’evasione. Non si tratta più di controllare la presenza di file di sistema, analizzare il numero di CPU disponibili o verificare chiavi di registro associate a macchine virtuali – tecniche ormai note e spesso simulate dalle sandbox moderne. Si tratta di analizzare il comportamento fisico dell’operatore attraverso modelli geometrici, portando l’evasione a un livello che richiede sandbox con simulazione biometrica convincente per essere superato.
Sandbox Evasion al quarto posto
La tecnica di Virtualization/Sandbox Evasion (T1497) è esplosa fino alla quarta posizione nella classifica delle tecniche più diffuse, comparendo in circa il 20% degli attacchi osservati. Il fenomeno del “fingersi morto” – il malware che resta dormiente finché non è sicuro di non essere analizzato – è diventato una precondizione operativa standard per il malware moderno.
L’implicazione per i difensori è diretta: le sandbox tradizionali, pilastro dell’analisi dinamica del malware, stanno perdendo efficacia. Un campione che decide di non detonare in ambiente controllato appare benigno – e viene rilasciato negli ambienti di produzione dove poi si attiva. Questo impone una revisione delle strategie di detonazione, includendo sandbox con interazione umana simulata, analisi comportamentale post-deployment e validazione continua dei controlli di prevention.
Credenziali come chiave d’accesso permanente
Il furto di credenziali rimane centrale, ma ha cambiato forma. Le tecniche “rumorose” come il credential dumping (T1003 – OS Credential Dumping, che richiede interazione diretta con processi sensibili come LSASS e genera artefatti rilevabili) sono uscite dalla top 10. Al loro posto, Credentials from Password Stores (T1555) compare nel 23,49% degli attacchi – quasi un attacco su quattro implica l’estrazione silenziosa di password salvate nei browser, nei keychain e nei password manager.
La differenza operativa è significativa: accedere a un password store è un’operazione che può apparire legittima – dopotutto, anche i processi autorizzati leggono questi archivi. Il credential dumping da LSASS, invece, richiede privilegi elevati e genera eventi distintivi che un EDR ben configurato può intercettare. Il passaggio dall’uno all’altro riflette perfettamente la filosofia del parassita: evitare il rumore, sfruttare i canali fidati.
Living off the Cloud
Il report documenta l’emergere di tecniche C2 che sfruttano servizi cloud legittimi per comunicare con i server di comando e controllo. L’esempio più emblematico è la backdoor SesameOp, scoperta da Microsoft DART nel luglio 2025 durante l’indagine su un’intrusione protrattasi per mesi in un ambiente corporate. SesameOp instradava tutto il traffico C2 attraverso l’API Assistants di OpenAI, mascherando le comunicazioni malevole come normale attività di sviluppo AI. Nessun dominio sospetto, nessun IP anomalo – solo traffico TLS verso api.openai.com, indistinguibile da milioni di connessioni legittime.
Come ha documentato Microsoft nel suo blog post tecnico, SesameOp non utilizzava alcun SDK o funzionalità AI di OpenAI: sfruttava l’API esclusivamente come canale di relay, usando i campi “description” degli Assistants come flag di comando (SLEEP, Payload, Result) e i messaggi come veicolo per payload cifrati con layer AES e RSA. L’obiettivo dell’attacco è stato determinato come persistenza a lungo termine per finalità di spionaggio – il profilo perfetto del parassita digitale.
Parallelamente, il Red Report 2026 di Picus documenta il gruppo Storm-0501, osservato da Microsoft mentre interrogava direttamente servizi di gestione dei segreti cloud (come AWS Secrets Manager) via API nativa per raccogliere credenziali, evitando completamente il rilevamento endpoint. Il parassita digitale non ha bisogno di forzare le porte: semplicemente, effettua il login.
Complessità crescente per campione
Ogni campione di malware esegue in media 14 azioni malevole e implementa 12 tecniche ATT&CK distinte. Non si tratta più di un singolo payload con una funzione. Il malware moderno è un organismo multi-funzionale che combina evasione, persistenza, furto credenziali, comunicazione C2 e preparazione all’esfiltrazione in un unico pacchetto coordinato. Questo livello di sofisticazione per singolo campione significa che affrontare una sola tecnica alla volta – l’approccio a “silos” tipico di molte architetture difensive – è strutturalmente inadeguato.
Il gap dell’invisibilità: quando le difese sono cieche
Il Red Report 2026 acquista la sua piena dimensione strategica se letto insieme al Blue Report 2025 di Picus Security, basato su oltre 160 milioni di simulazioni di attacco condotte in ambienti di produzione reali tra gennaio e giugno 2025. I due report, insieme, raccontano una storia preoccupante di perfetto allineamento tra capacità offensive e debolezze difensive.
Il dato che sintetizza tutto: il 54% dell’attività degli attaccanti viene registrata nei log, ma solo il 14% genera un alert. Le organizzazioni rilevano solo un attacco simulato su sette. Questo significa che le tecniche di persistenza e evasione a basso rumore operano regolarmente sotto le soglie di detection, nello spazio tra attività e consapevolezza dove il parassita digitale prospera.
Ancora più critico è il collasso delle difese contro l’esfiltrazione dati. Secondo il Blue Report 2025, la prevenzione dell’esfiltrazione è crollata dal 9% al 3%, confermandosi il vettore d’attacco meno contrastato per il terzo anno consecutivo. In un contesto in cui gli attaccanti stanno migrando dall’encryption all’esfiltrazione silenziosa, questo dato rappresenta una vulnerabilità sistemica: le organizzazioni hanno investito massicciamente nella resilienza anti-ransomware (backup, disaster recovery), ma hanno trascurato la protezione contro il furto graduale dei dati.
L’identità è il territorio dove il gap è più ampio. Il Blue Report 2025 ha rilevato che gli attacchi basati su credenziali valide (T1078 – Valid Accounts) hanno avuto successo nel 98% degli ambienti testati. Il cracking delle password è riuscito nel 46% degli ambienti, raddoppiando rispetto al 25% dell’anno precedente. L’efficacia complessiva della prevenzione è scesa dal 69% al 62%, invertendo i guadagni dell’anno precedente. Una volta che l’attaccante supera il confine dell’identità, l’attività malevola si confonde con le operazioni normali, rendendo il rilevamento una sfida di analisi comportamentale che la maggior parte dei SOC non è attrezzata ad affrontare.
Le cause di questo fallimento difensivo sono documentate nel Blue Report con precisione chirurgica: il 50% dei fallimenti nelle regole di detection è dovuto a problemi di raccolta log, il 24% a colli di bottiglia nelle performance, il 13% a misconfigurazioni. Non sono problemi di tecnologia mancante – sono problemi di manutenzione e validazione di tecnologia già presente.
Il paradosso del ransomware 2026: più attacchi, meno incassi
Il Red Report 2026 fornisce la spiegazione empirica di un paradosso che ha dominato il dibattito di settore nell’ultimo anno: come è possibile che gli attacchi ransomware aumentino mentre i pagamenti diminuiscono?
I numeri sono eloquenti. BlackFog ha registrato un aumento del 49% anno su anno negli attacchi ransomware dichiarati pubblicamente nel 2025, con un totale record di 1.174 incidenti e 130 gruppi attivi. Cyble ha registrato 6.604 attacchi ransomware a livello globale nel 2025, in aumento del 52% rispetto ai 4.346 del 2024, con gli Stati Uniti che hanno rappresentato il 55% degli attacchi totali.
Il Red Report 2026 offre la chiave interpretativa: il calo dell’encryption non è una ritirata, è una migrazione strategica. Gli attaccanti non stanno smettendo di monetizzare – stanno cambiando il modello di business. L’esfiltrazione silenziosa sostituisce la cifratura perché offre opzioni di monetizzazione multiple e prolungate nel tempo: estorsione graduale, rivendita dell’accesso persistente a terzi (initial access broker), intelligence gathering per insider trading, raccolta continuativa di credenziali da rivendere nei marketplace del dark web. Un singolo accesso persistente può essere monetizzato ripetutamente, mentre un’operazione di encryption ha un unico momento di leva – che sempre più spesso viene rifiutato dalla vittima.
Integrity360 conferma questa lettura nel suo report 2026: il 42% delle organizzazioni compromesse ha subito tattiche di doppia o tripla estorsione, dove il furto di dati e la pressione secondaria vengono utilizzati insieme o al posto dell’encryption. Ma l’estorsione basata sul solo furto dati sta paradossalmente perdendo efficacia: le organizzazioni hanno compreso che pagare non elimina gli obblighi legali di notifica, non garantisce la cancellazione dei dati e non impedisce la ri-estorsione. Coveware ha documentato come anche il solo negoziare con i criminali rappresenti un rischio crescente, con attori malevoli che non esitano a ricorrere allo SWATting – l’invio di squadre d’intervento armato ai domicili dei dirigenti – per forzare il pagamento.
La risposta degli attaccanti al calo dei pagamenti è la diversificazione: DDoS combinato con ransomware, reclutamento di insider aziendali, minacce reputazionali, pressioni su clienti e partner della vittima. Il parassita digitale descritto nel Red Report 2026 è la forma più sofisticata di questa diversificazione: invece di un singolo tentativo di estorsione ad alto rischio, l’attaccante mantiene un accesso persistente e a basso profilo che può essere sfruttato in modi multipli e su orizzonti temporali estesi.
Cosa cambia per chi difende: dalla detection dell’encryption alla caccia al parassita
Se il modello offensivo è cambiato, il modello difensivo deve seguire. E questo è, probabilmente, l’aspetto più doloroso del Red Report 2026: la maggior parte delle architetture di sicurezza è ancora ottimizzata per rilevare il ransomware tradizionale, non il parassita digitale.
Metriche di detection da ripensare
Il “time to detect encryption” era la metrica regina quando il ransomware cifrava i file entro ore dall’intrusione iniziale. In un modello parassitario, la metrica critica diventa il “time to detect data exfiltration” – e il Blue Report 2025 ci dice che questa capacità è al 3%. Il dwell time medio si allunga significativamente quando l’attaccante non ha alcun incentivo a fare rumore: la backdoor SesameOp ha operato per mesi prima di essere scoperta.
Le organizzazioni devono ripensare il proprio framework di metriche: non più solo MTTD (Mean Time to Detect) e MTTR (Mean Time to Respond) basati su alert di encryption, ma indicatori di compromissione comportamentali – anomalie nei pattern di accesso, volumi insoliti di query a password store, traffico outbound verso servizi cloud legittimi che eccede le baseline storiche.
Threat hunting: dalla ricerca di lateral movement alla low-and-slow exfiltration
Il threat hunting tradizionale si concentra sul rilevamento di lateral movement e privilege escalation – fasi che, nel modello tradizionale, precedono l’encryption. Il parassita digitale opera diversamente: una volta ottenuto l’accesso tramite credenziali valide, non ha bisogno di muoversi lateralmente in modo aggressivo. Può limitarsi a interrogare i password store e i servizi cloud utilizzando le stesse API e gli stessi strumenti degli amministratori legittimi.
I team di threat hunting devono sviluppare capacità di rilevamento “low-and-slow”: esfiltrazione di piccoli volumi distribuiti nel tempo, accesso a risorse sensibili da account validi ma in orari o con pattern anomali, query ai servizi di gestione dei segreti che non corrispondono ai workflow operativi documentati.
Architetture di sicurezza: dall’anti-ransomware al monitoraggio continuo
L’investimento in backup e disaster recovery resta essenziale, ma non è più sufficiente come strategia primaria. Il parassita digitale non distrugge i backup perché non ha bisogno di farlo: il suo obiettivo è l’esfiltrazione, non la cifratura.
Le architetture devono incorporare: Identity Threat Detection and Response (ITDR), per monitorare come le credenziali vengono utilizzate oltre a verificare che siano corrette; Data Loss Prevention di nuova generazione, basato su baseline comportamentali e anomaly detection anziché su regole statiche e pattern matching; microsegmentazione Zero Trust, per limitare il blast radius di ogni compromissione quando l’attaccante è già dentro con credenziali valide; e validazione continua dei controlli di sicurezza, perché il Blue Report 2025 dimostra che l’efficacia si degrada rapidamente senza testing costante.
Indicazioni operative per il SOC: come rilevare il parassita digitale
Alla luce dei dati del Red Report 2026, i team SOC devono aggiornare le proprie capacità di rilevamento per intercettare i comportamenti specifici del parassita digitale. Ecco le aree prioritarie su cui concentrare gli sforzi, mappate sulle tecniche ATT&CK documentate nel report.
Monitoraggio degli accessi ai password store (T1555). L’accesso ai credential store dei browser (Chrome Login Data, Firefox logins.json) e ai keychain di sistema da parte di processi non autorizzati è il segnale più affidabile. È necessario monitorare gli accessi in lettura a questi file e generare alert quando il processo richiedente non è il browser stesso o un password manager legittimo. Le regole Sigma per T1555 sono disponibili nel repository pubblico SigmaHQ e devono essere testate – non solo deployate – contro il comportamento reale dell’ambiente.
Detection della process injection (T1055). Monitorare le chiamate API di Windows associate all’injection: CreateRemoteThread, NtMapViewOfSection, QueueUserAPC, e le varianti di VirtualAllocEx + WriteProcessMemory. La chiave è correlare queste chiamate con il processo sorgente: se un processo utente non privilegiato invoca CreateRemoteThread su un processo di sistema, l’alert ha alta probabilità di essere significativo.
Traffico outbound verso servizi cloud legittimi. Il caso SesameOp dimostra che il C2 può transitare interamente su API cloud. È necessario stabilire baseline del traffico verso endpoint come api.openai.com, management.azure.com, secretsmanager.amazonaws.com, e generare alert su deviazioni significative, in particolare quando il traffico proviene da processi o utenti che non hanno giustificazione operativa per interrogare questi servizi.
Rilevamento della sandbox evasion (T1497). Monitorare le query WMI relative a informazioni hardware (Win32_ComputerSystem, Win32_BIOS), le interrogazioni sulle configurazioni di rete con pattern riconducibili a fingerprinting di ambienti virtualizzati, e l’enumerazione di processi associati a strumenti di analisi (procexp, wireshark, x64dbg). Se un campione esegue queste query nelle prime fasi di esecuzione e poi diventa silente, il pattern è coerente con sandbox evasion.
Validazione delle regole di detection esistenti. Il Blue Report 2025 rivela che il 50% dei fallimenti di detection è causato da problemi nella raccolta log, non da assenza di regole. Prima di scrivere nuove regole, verificare che quelle esistenti funzionino: che i log arrivino effettivamente al SIEM, che le regole si attivino sui dati reali e che gli alert risultanti siano azionabili. Un’attività di detection rule validation anche trimestrale può colmare una parte significativa del gap documentato nel report.
Implicazioni normative: NIS2, DORA e il parassita digitale
Il passaggio dal ransomware distruttivo alla residenza silenziosa ha implicazioni dirette per il framework normativo europeo, e in particolare per gli obblighi di notifica che dal 15 gennaio 2026 sono pienamente operativi in Italia.
La Direttiva NIS2 (Direttiva UE 2022/2555), recepita in Italia con il D.Lgs. 138/2024, definisce all’articolo 23 (articolo 25 del decreto di recepimento) gli obblighi di notifica per gli incidenti “significativi”. Un incidente è significativo quando ha causato o è in grado di causare una grave perturbazione operativa dei servizi o perdite finanziarie per il soggetto interessato, oppure quando ha provocato o può provocare ripercussioni su altre persone fisiche o giuridiche causando perdite materiali o immateriali considerevoli. La procedura prevede una pre-notifica al CSIRT Italia entro 24 ore e una notifica dettagliata entro 72 ore dall’evidenza dell’incidente.
Il problema è che il parassita digitale è progettato per non generare mai un “incidente significativo” visibile. Se l’attaccante non cifra i file, non interrompe le operazioni e non lascia tracce evidenti, quando scatta l’obbligo di notifica? L’ACN, con la Determinazione 379907 del 19 dicembre 2025, ha definito categorie di incidenti significativi di base (IS-1 per perdita di riservatezza, IS-2 per perdita di integrità, IS-3 per perdita di disponibilità) – ma l’esfiltrazione silenziosa e graduale può sfuggire a queste categorie finché non viene scoperta, momento in cui il danno è già consolidato e la finestra di notifica può essere tecnicamente scaduta.
Il Regolamento di esecuzione della Commissione Europea specifica che un incidente è significativo anche quando ha causato o è in grado di causare l’esfiltrazione di segreti commerciali. Questo criterio è direttamente rilevante per il modello del parassita digitale, ma presuppone che l’organizzazione sia consapevole dell’esfiltrazione – una consapevolezza che, con un tasso di prevenzione dell’esfiltrazione al 3% e alert generati solo sul 14% dell’attività malevola, è tutt’altro che garantita.
Per le istituzioni finanziarie soggette al Regolamento DORA (Regolamento UE 2022/2554), il problema è ancora più acuto. DORA richiede capacità di rilevamento, risposta e reporting su incidenti ICT dimostrabili e verificabili (Capitolo III, articoli 17-23), con obblighi di classificazione degli incidenti e notifica alle autorità competenti. Il Blue Report 2025, nella sua analisi settoriale BFSI, ha rilevato che nonostante una copertura di log superiore alla media (67%), solo il 13% degli attacchi simulati nel settore finanziario genera un alert – quasi 7 attacchi su 8 passano inosservati. In un contesto regolamentare che richiede capacità di detection dimostrabili e resilienza operativa verificata, questo gap rappresenta un’esposizione sia operativa sia sanzionatoria.
Il rischio concreto è duplice: da un lato, le organizzazioni potrebbero essere in stato di compromissione prolungata senza saperlo e, di conseguenza, in violazione degli obblighi di notifica tempestiva; dall’altro, le autorità di vigilanza potrebbero valutare ex post che un incidente avrebbe dovuto essere notificato prima, con conseguenze sanzionatorie significative. L’ACN ha chiarito che anche la mancata notifica di un incidente che l’autorità ritiene a posteriori significativo costituisce una violazione della normativa.
L’AI nel Red Report 2026: meno hype, più tradecraft
Un aspetto del Red Report 2026 che merita attenzione è ciò che il report non ha trovato. Nonostante le aspettative diffuse, Picus Labs non ha osservato alcun aumento significativo di tecniche d’attacco genuinamente guidate dall’intelligenza artificiale. Il successo degli attaccanti continua a basarsi su tradecraft consolidato: Process Injection e Command and Scripting Interpreter rimangono tra le tecniche più osservate.
Dove l’AI compare, il suo ruolo resta circoscritto. Il malware LameHug, documentato nel Red Report 2026, interagisce con API di large language model solo per recuperare comandi predefiniti. Non è stato osservato alcun ragionamento autonomo o decision-making adattivo – si tratta di integrazione superficiale, non di un cambiamento strutturale nella meccanica degli attacchi. La backdoor SesameOp, pur sfruttando l’infrastruttura OpenAI, non utilizza alcuna capacità AI: impiega l’API come semplice canale di comunicazione.
Questo non significa che l’AI non rappresenti un rischio futuro – e altre fonti, come il caso documentato da Darktrace di malware generato da LLM osservato nella rete di honeypot CloudyPots con attività rilevata a partire da novembre 2025, suggeriscono che la convergenza è in atto. Significa però che, oggi, le organizzazioni che si concentrano ossessivamente sull’AI-powered malware trascurando le difese contro credential theft e persistence stanno combattendo la guerra sbagliata. Il parassita digitale non ha bisogno di intelligenza artificiale per restare invisibile: gli basta sfruttare il gap tra logging e alerting che già esiste nella maggior parte degli ambienti enterprise.
Prospettive: il 2026 come anno della validazione continua
Il Red Report 2026 non è un documento pessimistico. È un documento che impone una ricalibratura. Il messaggio strategico è chiaro: le organizzazioni hanno costretto gli avversari a evolversi, rendendo il ransomware tradizionale meno redditizio. Ma l’evoluzione risultante – il parassita digitale – richiede una risposta difensiva altrettanto sofisticata.
La direzione è inequivocabile: le valutazioni statiche e la copertura basata su assunzioni lasciano punti ciechi quando le minacce sono progettate per restare silenziose. La protezione delle organizzazioni richiede la validazione continua dei controlli di sicurezza contro il comportamento avversario reale – non contro scenari teorici, ma contro le tecniche documentate empiricamente in report come questo.
Questo si traduce in azioni concrete. Testare i controlli di detection contro le tecniche della top 10 ATT&CK del Red Report 2026. Verificare che le regole SIEM si attivino effettivamente su T1055, T1555, T1497. Simulare esfiltrazione dati low-and-slow e misurare se viene rilevata. Stabilire baseline comportamentali per l’accesso ai credential store e ai servizi cloud. Integrare l’approccio CTEM (Continuous Threat Exposure Management) nelle operazioni quotidiane, non come progetto una tantum ma come processo continuo.
Per i professionisti della sicurezza, il Red Report 2026 di Picus è un invito a guardare oltre l’alert. Il parassita digitale non bussa alla porta: è già dentro, silenzioso, paziente, e si nutre di ogni credenziale non protetta, di ogni policy di accesso non verificata, di ogni gap tra ciò che viene registrato e ciò che viene effettivamente analizzato.
Il ransomware come lo conoscevamo sta cedendo il trono. E il suo successore è molto più difficile da trovare.
QR Code Phishing Ledger: lettere truffa con codici QR colpiscono i possessori di crypto wallet
Il QR code phishing contro i possessori di hardware wallet Ledger rappresenta una delle convergenze più significative emerse nel panorama del cybercrime nel 2026: l’uso della posta tradizionale – il vettore di comunicazione più antico e apparentemente innocuo – per colpire i detentori di dispositivi crittografici, il target più tecnologicamente avanzato dell’ecosistema finanziario digitale.
A partire da febbraio 2026, possessori di dispositivi Ledger e Trezor hanno iniziato a ricevere lettere cartacee (scam letters) che riproducono fedelmente la comunicazione ufficiale dei due produttori, complete di loghi, ologrammi, intestazioni corporate e persino firme attribuite ai rispettivi dirigenti. Le lettere contengono un QR code e un messaggio urgente: completare un “Authentication Check” o un “Transaction Check” obbligatorio entro una data precisa, pena la perdita delle funzionalità del dispositivo.
Non si tratta di un fenomeno isolato o marginale. Questa campagna rappresenta un salto qualitativo nell’evoluzione del quishing – un attacco che aggira per design ogni filtro anti-spam, ogni sandbox, ogni sistema di rilevamento automatizzato, perché non transita attraverso alcun canale digitale. La domanda che pone ai professionisti della sicurezza è radicale: come si difende un perimetro che non esiste più?
Anatomia dell’attacco: dalla lettera alla seed phrase rubata
Il meccanismo operativo della campagna è tanto semplice quanto efficace, e merita un’analisi dettagliata perché rivela una sofisticazione psicologica notevole, anche in assenza di complessità tecnica.
La vittima riceve una lettera cartacea recapitata al proprio indirizzo di residenza. La lettera è stampata su carta intestata che replica fedelmente il branding ufficiale di Ledger o Trezor. Nel caso delle lettere a tema Trezor, il documento reca la firma del CEO Matěj Žák, sebbene in almeno un esemplare documentato il nome compaia erroneamente come “Ledger CEO” – un indizio di produzione massiva con controllo qualità approssimativo che, paradossalmente, molte vittime non notano. Le scam letters includono ologrammi apparentemente autentici e un QR code stampato in posizione prominente.
Il testo della comunicazione è costruito secondo i principi classici dell’ingegneria sociale. Un esemplare analizzato da BleepingComputer invitava l’utente a completare l’Authentication Check entro il 15 febbraio 2026, scansionando il QR code con il proprio dispositivo mobile e seguendo le istruzioni sul sito web indicato. Il messaggio presenta tre elementi chiave: un’azione apparentemente ragionevole (verifica di sicurezza), una deadline precisa (che genera urgenza) e una conseguenza negativa in caso di mancata azione (perdita di accesso). Una variante destinata agli utenti Ledger richiede di completare un “Transaction Check” con scadenza al 15 ottobre 2025 e include l’avvertimento di non condividere la seed phrase online – un dettaglio che costruisce falsa credibilità prima di reindirizzare la vittima esattamente verso quella trappola.
La scansione del QR code conduce a siti web che replicano con precisione le interfacce ufficiali di configurazione dei dispositivi, ospitati su domini come “trezor.authentication-check.io” o “ledger.setuptransactioncheck.com”. Il percorso di navigazione è progettato per simulare un processo di verifica plausibile: una landing page che spiega la necessità dell’”Authentication Check”, un pulsante “Get Started”, una serie di avvertenze su possibili malfunzionamenti in caso di mancata verifica (errori nella firma delle transazioni, incompatibilità con futuri aggiornamenti firmware) e infine la pagina critica che richiede l’inserimento della recovery phrase da 12, 20 o 24 parole.
La recovery phrase – o seed phrase – è la rappresentazione testuale della chiave privata che controlla l’accesso a un wallet crittografico. Chi la possiede può ripristinare il wallet su qualsiasi dispositivo compatibile e trasferire tutti i fondi. L’inserimento della seed phrase su un sito controllato dagli attaccanti equivale alla consegna totale e irreversibile di tutti gli asset custoditi nel wallet. I fondi vengono tipicamente drenati nel giro di minuti.
La supply chain delle informazioni: da dove vengono gli indirizzi
Ogni campagna di QR code phishing mirato richiede dati di targeting. Nella fattispecie, gli attaccanti necessitano di un dato particolarmente sensibile: l’indirizzo fisico di residenza di persone che possiedono un hardware wallet crittografico. Questo dato non è banale da ottenere, e la sua disponibilità è direttamente riconducibile a una catena di data breach che coinvolge Ledger da quasi sei anni.
La breach del 2020: il peccato originale
Nel giugno 2020, un attaccante ha sfruttato una chiave API mal configurata per accedere al database e-commerce e marketing di Ledger. L’incidente, inizialmente sottostimato, si è rivelato devastante: quando il contenuto integrale dei database rubati è stato pubblicato su un forum nel dicembre 2020, è emerso che oltre un milione di indirizzi email erano stati esposti e, dato cruciale, circa 272.000 record contenenti nomi completi, numeri di telefono e indirizzi postali dei clienti. Come documentato da Have I Been Pwned, i dati sono stati inizialmente venduti e poi resi integralmente di pubblico dominio.
A questa breach si è aggiunto un secondo incidente legato a Shopify: dipendenti infedeli del partner e-commerce di Ledger hanno esfiltrato record di clienti in due episodi distinti, ad aprile e giugno 2020. Secondo le indagini forensi condotte da Ledger con Orange Cyberdefense, la breach Shopify ha coinvolto complessivamente circa 292.000 record, di cui circa 20.000 erano nuovi record non compresi nella breach precedente, contenenti email, nomi, indirizzi postali, prodotti ordinati e numeri di telefono. Il risultato complessivo è stato un database di centinaia di migliaia di individui identificabili come acquirenti di hardware wallet, con tanto di indirizzo di casa.
La breach Trezor del 2024
Nel gennaio 2024, Trezor ha reso noto che un accesso non autorizzato al portale di supporto gestito da un provider terzo aveva potenzialmente esposto i dati di contatto di circa 66.000 utenti – email e nomi/nickname – che avevano interagito con il supporto dal dicembre 2021. Sebbene in questo caso non risultino compromessi indirizzi postali, l’incidente ha fornito un ulteriore set di dati per la correlazione e il targeting.
La breach Global-e del gennaio 2026: l’ultima goccia
Il 5 gennaio 2026, come riportato da CoinDesk e confermato da The Register, Ledger ha informato i propri clienti di un nuovo incidente di esposizione dati, riconducibile a Global-e, il processore di pagamenti utilizzato per gli ordini internazionali su Ledger.com. Un soggetto non autorizzato ha ottenuto accesso a un sistema cloud di Global-e contenente dati ordine di clienti di diversi brand, incluso Ledger. I dati esposti comprendono nomi, informazioni di contatto e dettagli degli ordini (prodotti acquistati e prezzi), sebbene non risultino compromesse informazioni di pagamento o credenziali.
Ledger ha specificato in una comunicazione a BleepingComputer che l’incidente non ha riguardato la piattaforma, l’hardware o il software Ledger, e che Global-e non ha accesso alle 24 parole della recovery phrase, ai saldi blockchain o ad alcun segreto relativo agli asset digitali. Tuttavia, il valore operativo di questa breach non risiede nell’accesso a chiavi crittografiche, bensì nella possibilità di costruire un profilo di targeting preciso: questa persona ha acquistato un dispositivo Ledger, risiede a questo indirizzo, e il suo ordine è datato.
La cronologia è significativa: la breach Global-e viene resa nota il 5 gennaio 2026, le prime scam letters con QR code phishing iniziano a circolare nelle settimane successive. Sebbene non sia possibile stabilire con certezza un collegamento causale diretto – gli attaccanti potrebbero utilizzare anche i dati del 2020, ampiamente disponibili – la coincidenza temporale suggerisce quantomeno che i dati freschi abbiano alimentato o ampliato la campagna.
Il pattern ricorrente: Ledger e il debito di fiducia sulla supply chain commerciale
L’analisi più rilevante per un professionista della sicurezza non riguarda la singola campagna di crypto scams, ma il pattern strutturale che la rende possibile.
Ledger produce un dispositivo la cui ragion d’essere è la sicurezza: un hardware wallet che custodisce chiavi private in un elemento sicuro isolato, offline, inaccessibile da remoto. Il paradosso è che il dispositivo stesso non è mai stato compromesso. In nessuno degli incidenti documentati gli attaccanti hanno violato il secure element, estratto chiavi private o bypassato le protezioni crittografiche. Ciò che viene compromesso, sistematicamente e ripetutamente, è l’infrastruttura commerciale attorno al prodotto: il database e-commerce (2020), il partner logistico Shopify (2020), il processore di pagamenti Global-e (2026).
Questo schema solleva una questione strategica che trascende il caso specifico: il modello di self-custody promette di eliminare i trusted third party dalla custodia degli asset digitali, ma non può eliminare i trusted third party dal processo di acquisto e distribuzione del dispositivo fisico che rende possibile la self-custody stessa.
Ogni acquisto online genera una traccia di dati personali – nome, indirizzo, email, dati ordine – che transita attraverso una catena di fornitori terzi (piattaforme e-commerce, processori di pagamento, provider logistici, servizi di localizzazione valutaria). Ciascuno di questi anelli rappresenta una superficie d’attacco. E nel caso specifico dei clienti di hardware wallet, quei dati identificano con certezza una persona come detentore di criptovalute – un’informazione che ha valore sia per i phisher digitali sia per i criminali nel mondo fisico.
La psicologia della lettera: perché il cartaceo funziona
La domanda che ogni CISO dovrebbe porsi è: perché una lettera cartacea è più efficace di un’email di phishing?
La risposta risiede in un’asimmetria cognitiva che vent’anni di cybersecurity awareness non hanno affrontato. L’intera infrastruttura di formazione anti-phishing è costruita attorno ai canali digitali: non cliccare su link sospetti, verificare l’indirizzo del mittente, diffidare delle email con senso di urgenza. Secondo Keepnet Labs, il 12% di tutti gli attacchi phishing nel 2025 conteneva un QR code, e i dirigenti C-level risultano 40 volte più esposti al quishing rispetto ai dipendenti ordinari. Ma queste statistiche si riferiscono al quishing digitale. La variante fisica opera in un territorio cognitivo sostanzialmente non presidiato.
Una lettera cartacea attiva almeno tre bias cognitivi che l’email non può replicare con la stessa intensità. Il primo è l’autorità percepita del medium fisico: nella percezione comune, la posta cartacea è associata a comunicazioni ufficiali, istituzionali, importanti – banche, enti pubblici, studi legali. Il secondo è l’assenza di sospetto contestuale: abbiamo interiorizzato che le minacce informatiche arrivano attraverso schermi, non attraverso la cassetta delle lettere. Il terzo è l’investimento percepito: una lettera stampata su carta intestata con ologrammo comunica un impegno di risorse che un’email di massa non trasmette, generando una credibilità implicita.
A questi si aggiunge un fattore tecnico determinante: il QR code phishing fisico bypassa per design l’intero stack di sicurezza digitale. Non transita attraverso gateway email che possono intercettare link malevoli. Non viene analizzato da sandbox o filtri anti-phishing. Il QR code non è ispezionabile prima della scansione (a meno di non utilizzare scanner con funzione di anteprima dell’URL, ancora poco diffusi). Il passaggio dal mondo fisico a quello digitale avviene nel momento in cui la vittima punta la fotocamera del proprio smartphone personale – un dispositivo che tipicamente non è protetto con la stessa profondità di un endpoint aziendale.
Dal phishing fisico al wrench attack: la catena che arriva al corpo
Il QR code phishing contro i possessori di wallet Ledger non può essere analizzato come fenomeno isolato. Si inscrive in un trend più ampio e più grave: la convergenza tra cybercrime e crimine fisico.
Il caso più emblematico è quello di David Balland, cofondatore di Ledger, rapito insieme alla compagna nel gennaio 2025 dalla propria abitazione a Méreau, nel centro della Francia. Come riportato da Fortune, CoinDesk e France 24, i rapitori hanno tenuto i coniugi separati in due località diverse, hanno contattato un altro cofondatore di Ledger chiedendo un riscatto in criptovalute e hanno amputato un dito a Balland per forzare il pagamento. L’unità d’élite GIGN della Gendarmerie nazionale è intervenuta liberando Balland mercoledì notte, mentre la compagna è stata ritrovata giovedì legata in un veicolo nella zona di Essonne. Dieci persone, di età compresa tra i 20 e i 40 anni, sono state arrestate, come confermato dalla procura di Parigi.
Il caso Balland non è isolato. Nel novembre 2024, Dean Skurka, CEO della più grande crypto company canadese WonderFi, è stato sequestrato a Toronto da criminali che chiedevano un riscatto di un milione di dollari canadesi. L’escalation è documentata e sistematica: i dati digitali rubati nelle breach – indirizzi, abitudini di acquisto, patrimoni stimabili – forniscono l’intelligence necessaria per identificare e localizzare fisicamente i target.
In questo contesto, il QR code phishing fisico via posta rappresenta il livello iniziale di una scala di rischio che può arrivare fino alla violenza fisica. La lettera con QR code è l’equivalente di un probe: testa la reattività della vittima, raccoglie la seed phrase se va a buon fine, e in ogni caso conferma che a quell’indirizzo risiede effettivamente un possessore di crypto wallet. Come ha osservato DL News, il confine tra rischio online e rischio nel mondo reale è più sottile di quanto la maggior parte delle persone voglia ammettere.
Il quishing nel 2025-2026: un trend in esplosione
Le scam letters con QR code ai possessori di wallet sono un sottoinsieme di un fenomeno molto più ampio: l’esplosione del quishing (QR code phishing) a livello globale.
I dati raccolti da Keepnet Labs tratteggiano un quadro allarmante: gli attacchi phishing basati su QR code sono aumentati di cinque volte nel 2025. Le email di quishing sono passate da circa 47.000 nel mese di agosto a oltre 249.000 a novembre 2025. Il 68% degli attacchi quishing ha preso di mira specificamente utenti mobile. Secondo Abnormal Security, gli attacchi basati su QR code sono cresciuti del 400% tra il 2023 e il 2025, con energia, sanità e manifattura tra i settori più colpiti.
La ragione di questa esplosione è strutturale: i QR code rappresentano un punto cieco per le difese tradizionali. Un QR code in un’email è un’immagine, non un link testuale, e molti sistemi di filtraggio non lo decodificano. Nel contesto fisico – cartelli, parchimetri, volantini, lettere – non esiste alcun livello di protezione automatizzato. L’utente è completamente solo nella decisione di scansionare o meno.
Tra le autorità che hanno già riconosciuto la gravità del fenomeno, lo United States Postal Inspection Service (USPIS) ha pubblicato advisory specifici sul quishing postale, mentre la Federal Trade Commission (FTC) ha emesso alert dedicati ai QR code contenuti in pacchi non richiesti. Nel Regno Unito, tra aprile 2024 e aprile 2025, Action Fraud ha registrato 784 segnalazioni di quishing con perdite prossime a 3,5 milioni di sterline, un dato citato anche nell’analisi annuale di CloudSEK sulle tendenze phishing 2026.
Contromisure: cosa può fare concretamente un’organizzazione
Il QR code phishing fisico pone sfide di difesa non convenzionali. Le contromisure tradizionali – filtri email, sandbox, DNS sinkholing – sono strutturalmente irrilevanti. La risposta deve operare su tre livelli: consapevolezza, procedura e architettura.
Consapevolezza: estendere la formazione al mondo fisico
I programmi di security awareness devono essere aggiornati per includere esplicitamente il phishing fisico come vettore di attacco. Il messaggio chiave è semplice ma ancora poco diffuso: nessun produttore di hardware wallet chiederà mai di inserire la seed phrase su un sito web, tramite QR code, o in qualsiasi contesto diverso dal dispositivo fisico stesso. Come ribadisce Ledger nella propria pagina dedicata alle campagne di phishing: non esiste mai un motivo legittimo per digitare la propria recovery phrase su un computer. Questa regola è assoluta e non ammette eccezioni, indipendentemente dal canale di comunicazione.
Procedura: verificare sempre attraverso canali ufficiali
Qualsiasi comunicazione che richieda azioni urgenti relative a dispositivi di sicurezza – sia essa digitale o cartacea – deve essere verificata attraverso i canali ufficiali del produttore, navigando manualmente verso il sito web noto (non attraverso link o QR code forniti nella comunicazione). Per gli utenti Ledger, la pagina di stato delle campagne phishing e il supporto ufficiale sulla truffa postale elencano le varianti note, inclusa espressamente la variante postale. Per gli utenti Trezor, il blog ufficiale e i canali di supporto verificati sono gli unici punti di riferimento attendibili.
Architettura: minimizzare l’esposizione dei dati personali
Per chi deve ancora acquistare un hardware wallet, la contromisura più efficace è la minimizzazione dei dati personali ceduti durante l’acquisto. Questo include l’utilizzo di indirizzi di consegna alternativi (ufficio postale, punto di ritiro, indirizzo aziendale), email dedicate non collegate all’identità principale e, dove possibile, metodi di pagamento che non richiedano la divulgazione di dati anagrafici completi.
Per i possessori attuali i cui dati sono già potenzialmente esposti, le azioni prioritarie includono: monitoraggio attivo dell’attività del proprio wallet, valutazione della migrazione a un wallet con nuova seed phrase non correlata alle informazioni compromesse, adozione di configurazioni multi-signature che distribuiscano il rischio e implementazione di setup air-gapped che eliminino la connettività di rete dal processo di firma delle transazioni.
Per le organizzazioni: non sottovalutare il phishing fisico come vettore
Per i CISO e i responsabili della sicurezza aziendale, questa campagna di crypto scams ha implicazioni che vanno oltre il mondo crypto. Se il QR code phishing fisico funziona per i wallet crittografici, quanto tempo prima che venga adottato sistematicamente per il CEO fraud, l’ingegneria sociale aziendale o gli attacchi alle infrastrutture critiche? I settori dove la corrispondenza cartacea è la norma – bancario, assicurativo, sanitario, legale, fiscale – sono naturalmente esposti. Le policy di sicurezza devono prevedere procedure di verifica anche per le comunicazioni ricevute su canale fisico, specialmente quando richiedono azioni digitali come la scansione di QR code.
La questione strutturale: i dati personali come arma persistente
Il QR code phishing contro i clienti Ledger illumina una verità scomoda che l’industria della cybersecurity non ha ancora pienamente metabolizzato: i dati personali rubati in una breach non perdono valore con il tempo. Anzi, il loro valore come strumento di targeting può aumentare man mano che vengono correlati, arricchiti e combinati con dati provenienti da breach successive.
I 272.000 indirizzi rubati nel 2020 sono stati utilizzati per campagne di phishing via email nel 2020-2021, per l’invio di dispositivi Ledger contraffatti nel 2021, e ora per scam letters con QR code nel 2025-2026. I dati della breach Global-e del 2026 non fanno che aggiornare e arricchire un database di targeting già esistente. Ogni nuova breach nella supply chain commerciale di Ledger non è un incidente isolato: è un aggiornamento dell’infrastruttura di intelligence a disposizione degli attaccanti.
Questo ha implicazioni profonde per il framework normativo. Il GDPR impone la minimizzazione dei dati e la limitazione della conservazione, ma non può impedire che dati già esfiltrati continuino a circolare e a essere sfruttati per anni. La Direttiva NIS2 richiede la gestione del rischio supply chain, ma la catena di fornitori e-commerce di un produttore di hardware raramente rientra nel perimetro delle valutazioni di sicurezza tradizionali.
Prospettive: il QR code phishing fisico è qui per restare
L’evoluzione del quishing fisico nel 2025-2026 suggerisce che non si tratta di un episodio estemporaneo ma di un nuovo vettore stabile nel repertorio del cybercrime. Le ragioni sono tre.
La prima è economica: il costo di produzione e spedizione di lettere cartacee è sceso drasticamente, e il ritorno potenziale per lettera (l’intero contenuto di un crypto wallet) giustifica ampiamente l’investimento. La seconda è tattica: il QR code phishing fisico aggira le difese digitali per design, e l’infrastruttura di consapevolezza e prevenzione è ancora inadeguata. La terza è strategica: le breach passate e presenti hanno creato un bacino permanente di dati di targeting che non può essere bonificato.
Come osservato da Secrets of Privacy, il pattern che rende possibile questa campagna – un settore dove la corrispondenza fisica è consueta, dove esiste urgenza reale, e dove una breach ha già messo gli indirizzi di casa nel dominio pubblico – descrive la maggior parte della vita moderna. I criminali hanno dimostrato il modello sui possessori di crypto perché il ritorno giustificava l’investimento. La fase successiva sarà la scalabilità: volumi più alti, valori unitari più bassi, settori più ampi.
Il QR code phishing fisico contro i clienti Ledger non è solo una notizia di cybersecurity. È un segnale che la separazione tra mondo digitale e mondo fisico – sulla quale è costruita gran parte della nostra architettura di sicurezza – si sta dissolvendo. E chi non aggiorna le proprie difese per riflettere questa realtà rischia di trovarsi esposto su un fronte che non sapeva nemmeno di dover presidiare.
L’analisi ASviS. Quando le app diventano armi di guerra
BadeSaba Calendar è un’app molto diffusa in Iran. Serve a mostrare gli orari di preghiera per i credenti, il calendario religioso e le notifiche dell’Adhan, la chiamata islamica fatta di norma dal muezzin. Solo su Android ha avuto cinque milioni di download. Quando il 28 febbraio sono iniziati i bombardamenti di Stati Uniti e Israele contro l’Iran, BadeSaba è stata oggetto di un’operazione cyber parallela. Milioni di utenti iraniani, a Teheran e in altre città, hanno ricevuto notifiche politiche al posto dei normali avvisi religiosi. I messaggi, scritti in farsi, dicevano frasi come “I soccorsi sono arrivati” o “È arrivato il momento della resa dei conti”, con l’invito ai militari a deporre le armi o unirsi alle “forze di liberazione”. Un segnale che l’operazione non è stata improvvisata, ma probabilmente preparata mesi o anni prima, come spesso accade nelle cyber operazioni moderne.
Nessuno ha rivendicato ufficialmente l’attacco, ma diversi analisti citati da Politico ritengono probabile il coinvolgimento di Israele. Perché scegliere un’app religiosa per un’operazione di questo tipo? Certamente BadeSaba è considerata molto affidabile in Iran (non è un social occidentale) e passa facilmente attraverso la censura internet iraniana.
Secondo Nicholas Reese, ex responsabile delle tecnologie emergenti del Dipartimento della sicurezza interna Usa, le app sono un bersaglio sempre più interessante per le operazioni cyber. Non tutti gli sviluppatori, infatti, applicano gli stessi livelli di sicurezza, aspetto che rende alcune piattaforme più vulnerabili rispetto ai grandi servizi cloud.
In Ucraina ogni sei mesi un’arma diventa obsoleta. Droni, sensori e micro-unità cambiano tattiche e logistica. Ma la Nato e l’Europa faticano a tenere il passo.
C’è poi un altro elemento. Gli smartphone contengono una quantità enorme di informazioni personali: contatti, posizione, fotografie, messaggi, cronologia degli spostamenti. Penetrare un telefono significa spesso accedere a gran parte della vita digitale di una persona. Anche dal punto di vista della propaganda le app hanno un vantaggio importante. “Hai due opzioni: contattare qualcuno tramite un’app, oppure tramite una telefonata o un messaggio di testo”, ha spiegato a PoliticoHerb Lin, ex membro della Commissione statunitense per il miglioramento della sicurezza informatica. Nel primo caso si può raggiungere una platea molto più ampia con una sola operazione.
Per questo negli ultimi anni gli eserciti hanno iniziato a considerare le app come strumenti operativi. Le forze armate israeliane, ad esempio, qualche anno fa hanno accusato Hamas di aver cercato di attirare soldati su false applicazioni di incontri, infestate da malware. Una volta installate, permettevano agli hacker di accedere alle fotocamere e ai dati dei dispositivi.
Anche gli Stati Uniti hanno utilizzato indirettamente i dati provenienti dalle app. Un’inchiesta del Wall Street Journalha rivelato che il Pentagono ha acquistato dati di geolocalizzazione raccolti da alcune app di preghiera musulmane molto diffuse. I dati permettevano di analizzare gli spostamenti degli utenti in diverse regioni del Medio Oriente.
Secondo Wes Bryant, ex analista politico del Pentagono, ricevere un messaggio di propaganda direttamente sul proprio telefono è molto più pervasivo rispetto ai metodi tradizionali. Ma lo stesso Bryant ha osservato che colpire un’app usata per la preghiera può generare rabbia nella popolazione. Interferire con attività religiose, anche digitali, può essere percepito infatti come una forma di invasione.
Nel settembre 2024 migliaia di cercapersone utilizzati da Hezbollah in Libano esplosero quasi simultaneamente in un’operazione attribuita a Israele. L’attacco causò decine di morti e migliaia di feriti ed è stato citato dagli analisti come uno dei primi esempi di operazione “cyber-fisica”, in cui un dispositivo elettronico viene trasformato in arma. Il caso di BadeSaba segna però un passo ulteriore: l’uso delle app come potenziali strumenti di guerra su larga scala. Episodi simili, in futuro, potrebbero diventare sempre più comuni.
Fastweb+Vodafone, il cybercrime in Italia: attacchi più mirati, phishing più sofisticato e crescita attacchi “zero day”
Anche per l’anno 2025 Fastweb + Vodafone ha contribuito a fotografare la situazione del cyber crime in Italia sulla base dei dati del proprio Security Operations Center (SOC), attivo 24 ore su 24 e dai propri centri di competenza di sicurezza informatica, tramite 7Layers, la società di cybersecurity del gruppo.
Attività sospette su rete Fastweb +26% nel 2025
Dall’analisi effettuata sull’infrastruttura di rete di Fastweb, costituita da oltre 7 milioni di indirizzi IP pubblici, su ognuno dei quali possono comunicare centinaia di dispositivi e server, sono stati registrati nel 2025 oltre 87 milioni di eventi di sicurezza – ovvero attività sospette o potenzialmente malevole rilevate sulla rete – in aumento del 26% rispetto al 2024.
PA e servizi settori più colpiti
I settori più colpiti vedono al primo posto la Pubblica amministrazione (36% del totale) e al secondo posto quello dei servizi (oltre il 14% del totale).
Superficie di attacco sempre più ampia
Un elemento particolarmente rilevante è il forte aumento dei dispositivi compromessi: il numero di indirizzi IP unici infetti è più che raddoppiato rispetto al 2024, indicando che la superficie di attacco continua ad ampliarsi.
Varianti malware diminuite
Allo stesso tempo si osserva un cambiamento nelle strategie dei cyber criminali. Il numero di varianti di malware identificate è leggermente diminuito (da 160 a 154), segno che gli attaccanti tendono a concentrarsi su un numero più ristretto di strumenti, ma più efficaci, spesso supportati anche da tecniche di automazione e intelligenza artificiale.
Attacchi DDoS in aumento del 26% nel 2025
In crescita anche gli attacchi DDoS, utilizzati per sovraccaricare siti e servizi online fino a renderli inutilizzabili: nel 2025 ne sono stati registrati quasi 6.000, con un aumento del 26% rispetto all’anno precedente.
Le analisi dei sistemi di sicurezza di 7Layers, società di cybersecurity del gruppo Fastweb + Vodafone, indicano che le modalità di attacco restano nel complesso simili a quelle osservate negli anni precedenti. Nella maggior parte dei casi gli attacchi vengono intercettati nella fase di “execution”, cioè nel momento in cui il software malevolo tenta di avviarsi all’interno dei sistemi compromessi: questa tipologia rappresenta circa il 38% delle attività malevole rilevate.
Phishing, crescente sofisticazione degli attacchi
Si osserva inoltre una crescente sofisticazione delle campagne di phishing, utilizzate per indurre utenti e dipendenti a fornire credenziali o ad aprire contenuti malevoli, e un aumento degli attacchi che sfruttano vulnerabilità informatiche appena scoperte e non ancora corrette dai produttori dei software (cosiddette “zero-day”). In questi casi i cyber criminali riescono a colpire sistemi e organizzazioni prima che siano disponibili aggiornamenti o contromisure di sicurezza, aumentando così l’efficacia degli attacchi.
Estensioni Chrome AI malevole: oltre 260.000 utenti trasformati in fonti di intelligence per il cybercrime
Le estensioni Chrome AI malevole stanno emergendo come uno dei vettori di compromissione più insidiosi nell’ecosistema enterprise, accanto al phishing tradizionale e alle tecniche di social engineering come ClickFix. La settimana tra l’11 e il 16 febbraio 2026 ha reso questa realtà difficile da contestare: in soli cinque giorni, tre campagne distinte e indipendenti hanno dimostrato che il browser non è più un semplice strumento di navigazione, ma un ambiente di esecuzione ad alto privilegio che gli attaccanti stanno imparando a sfruttare con precisione industriale.
Il 12 febbraio, i ricercatori di LayerX hanno rivelato la campagna AiFrame: almeno 30 estensioni Chrome mascherate da assistenti AI – con nomi come “Gemini AI Sidebar”, “AI Assistant”, “ChatGPT Translate” – che hanno compromesso oltre 260.000 utenti (con alcune testate che riportano cifre fino a 300.000), sottraendo credenziali, contenuto delle email e cronologia di navigazione. L’11 febbraio, Koi Security aveva documentato il primo add-in Outlook malevolo mai rilevato in natura – AgreeTo, un tool di scheduling abbandonato dal suo sviluppatore e rilevato da un attaccante che ne ha preso il controllo per rubare oltre 4.000 credenziali Microsoft. E nella stessa settimana, Koi Security ha smascherato anche VK Styles, una rete di cinque estensioni che aveva silenziosamente dirottato oltre 500.000 account VKontakte.
Tre campagne. Due ecosistemi diversi – Chrome e Outlook. Un unico pattern strutturale: la fiducia implicita che utenti e organizzazioni ripongono nei marketplace ufficiali è diventata l’arma principale degli attaccanti.
Questo articolo non è un bollettino di sicurezza. È l’analisi di come il modello di distribuzione delle estensioni browser sia diventato strutturalmente vulnerabile e di cosa questo significhi per chi difende reti aziendali nel 2026.
Il browser come superficie d’attacco privilegiata: perché le estensioni Chrome AI malevole funzionano
Per comprendere la gravità di quanto accaduto, occorre partire da un dato architetturale che la maggior parte dei professionisti della sicurezza conosce in teoria ma sottovaluta in pratica: le estensioni browser operano con privilegi che pochi altri componenti software possono vantare.
Un’estensione Chrome con i permessi giusti può leggere e modificare il contenuto di qualsiasi pagina web visitata dall’utente, accedere ai cookie di sessione, intercettare le richieste di rete, catturare il contenuto degli appunti e persino registrare audio attraverso l’API Web Speech. Il tutto in background, senza che l’utente noti nulla di anomalo. E la portata del fenomeno è tutt’altro che marginale: secondo il LayerX Enterprise Browser Extension Security Report 2025, il 99% dei dipendenti enterprise ha almeno un’estensione browser installata, il che rende questa superficie d’attacco virtualmente universale negli ambienti aziendali.
Nel framework MITRE ATT&CK, le tecniche sfruttate dalle campagne di febbraio 2026 si mappano con precisione: T1176 – Browser Extensions per l’installazione del componente malevolo, T1539 – Steal Web Session Cookie per l’esfiltrazione dei cookie di sessione, T1185 – Browser Session Hijacking per l’intercettazione in tempo reale del contenuto delle pagine autenticate, e T1557 – Adversary-in-the-Middle per l’architettura iframe che si interpone tra utente e servizio. Comprendere questa mappatura è essenziale per i SOC analyst che devono tradurre l’intelligence sulle minacce in regole di detection operative.
Secondo una ricerca di Cybernews, 86 delle 100 estensioni Chrome analizzate (selezionate tra le più diffuse e raccomandate) richiedono permessi classificabili come ad alto rischio al momento dell’installazione: scripting, accesso esteso agli host, monitoraggio delle tab. Un’analisi condotta da Incogni nel gennaio 2026 su 442 estensioni AI ha rilevato che il 52% raccoglie almeno un tipo di dato utente e il 29% raccoglie informazioni personali identificabili.
Il problema non risiede nei permessi in sé – molte estensioni legittime ne necessitano di ampi per funzionare correttamente. Il problema è che il modello di sicurezza del Chrome Web Store si basa su una revisione che avviene al momento della pubblicazione, non durante l’esecuzione. Ciò che viene ispezionato al momento dell’approvazione non corrisponde necessariamente a ciò che viene eseguito successivamente sul dispositivo dell’utente. Ed è esattamente questa asimmetria che la campagna AiFrame ha sfruttato con efficacia chirurgica.
AiFrame: l’architettura di una campagna coordinata
La campagna AiFrame scoperta da LayerX non è l’opera di un dilettante opportunista. È un’operazione coordinata, industriale nella sua organizzazione, che ha impiegato la tecnica dell’extension spraying – la pubblicazione simultanea di decine di estensioni con nomi e branding diversi ma con identica infrastruttura backend – per massimizzare la superficie di distribuzione e garantire la resilienza contro i takedown.
Tutte le estensioni identificate condividevano lo stesso codebase JavaScript, gli stessi permessi e comunicavano con un’unica infrastruttura backend ospitata sotto il dominio tapnetic[.]pro. L’estensione più diffusa, Gemini AI Sidebar, aveva raggiunto 80.000 installazioni prima della rimozione dal Chrome Web Store. Altre estensioni di rilievo includevano AI Sidebar (70.000 utenti), AI Assistant (60.000 utenti) e ChatGPT Translate (30.000 utenti).
Ma il dettaglio tecnico più rilevante riguarda l’architettura di esecuzione. Le estensioni non implementavano localmente alcuna funzionalità AI. Al loro posto, caricavano un iframe a schermo intero puntato verso sottodomini remoti dell’infrastruttura dell’attaccante – come claude[.]tapnetic[.]pro – che sovrapponeva una finta interfaccia alla pagina web corrente. Per l’utente, l’esperienza appariva identica a quella di un assistente AI legittimo. In realtà, l’intera interfaccia era controllata dall’attaccante, che poteva modificarne il comportamento in qualsiasi momento senza dover sottoporre aggiornamenti al Chrome Web Store.
Questa architettura è particolarmente insidiosa perché sfrutta un punto cieco fondamentale del processo di revisione: Google verifica il codice al momento della pubblicazione, ma il contenuto servito dagli iframe remoti può cambiare liberamente in qualsiasi momento successivo.
Come ha dichiarato la ricercatrice Natalie Zargarov di LayerX a eSecurity Planet, la campagna sfrutta la natura conversazionale delle interazioni con gli assistenti AI, che ha condizionato gli utenti a condividere informazioni dettagliate e sensibili in modo naturale. L’iframe malevolo intercettava questi dati prima ancora che raggiungessero qualsiasi servizio AI legittimo, creando di fatto un attacco man-in-the-middle invisibile tra l’utente e l’interfaccia che credeva autentica.
Cosa rubavano le estensioni Chrome AI malevole: un’analisi dei vettori di esfiltrazione
L’arsenale di raccolta dati della campagna AiFrame operava su quattro livelli distinti, ciascuno con obiettivi specifici.
Il primo livello riguardava l’estrazione del contenuto delle pagine. Le estensioni utilizzavano la libreria Readability di Mozilla per estrarre titoli, testo e metadati da qualsiasi sito visitato dall’utente, incluse pagine autenticate come home banking, pannelli di amministrazione cloud e piattaforme SaaS aziendali. Il contenuto estratto veniva trasmesso all’infrastruttura backend controllata dall’operatore della campagna.
Il secondo livello, forse il più dannoso dal punto di vista enterprise, era dedicato specificamente alla compromissione di Gmail. Quindici delle 30 estensioni includevano uno script di contenuto dedicato che si attivava su mail.google.com al caricamento del documento, iniettava elementi nell’interfaccia utente e utilizzava un MutationObserver per mantenere la persistenza e catturare continuamente il testo dei thread email. Persino le bozze non inviate potevano essere intercettate.
Il terzo livello coinvolgeva un meccanismo di riconoscimento vocale attivabile da remoto. Quando abilitato dall’operatore, questo modulo utilizzava l’API Web Speech del browser per registrare conversazioni reali dall’ambiente fisico dell’utente e generare trascrizioni, trasformando il computer compromesso in un dispositivo di sorveglianza ambientale.
Il quarto livello era la raccolta passiva e continua di credenziali, cookie di sessione e cronologia di navigazione, destinata ad alimentare il mercato degli infostealer e dei credential marketplace nel dark web.
Il risultato complessivo è che queste estensioni funzionavano come broker di accesso generalisti, capaci di raccogliere dati, monitorare il comportamento degli utenti ed evolvere silenziosamente nel tempo – esattamente la definizione che LayerX ha utilizzato nel proprio report.
AgreeToSteal: il primo add-in Outlook malevolo e il problema delle dipendenze dinamiche abbandonate
Se la campagna AiFrame ha dimostrato il rischio delle estensioni Chrome AI malevole distribuite attraverso marketplace ufficiali, il caso AgreeToSteal scoperto da Koi Security ha rivelato un rischio parallelo e forse ancora più subdolo: quello delle dipendenze dinamiche abbandonate.
AgreeTo era un add-in di scheduling per Outlook perfettamente legittimo, sviluppato da un programmatore indipendente e pubblicato nel Microsoft Office Add-in Store nel dicembre 2022. L’add-in funzionava, aveva buone recensioni e puntava a un URL ospitato su Vercel (outlook-one.vercel[.]app) da cui caricava la propria interfaccia. Quando lo sviluppatore ha abbandonato il progetto, l’URL su Vercel è diventato rivendicabile. Un attaccante lo ha rivendicato, vi ha installato un kit di phishing, e l’infrastruttura di Microsoft ha iniziato a servire la pagina malevola direttamente nella barra laterale di Outlook a chiunque avesse ancora l’add-in installato.
Gli add-in di Office non sono software scaricabili nel senso tradizionale. Sono essenzialmente URL che puntano a contenuti caricati nel prodotto Microsoft dal server dello sviluppatore. Questo significa che, come ha dichiarato Idan Dardikman, cofondatore e CTO di Koi Security, a The Hacker News, un add-in che è sicuro il lunedì può servire una pagina di phishing il martedì – o, come in questo caso, anni dopo. Microsoft verifica il manifest XML al momento della sottomissione, ma il contenuto effettivo può cambiare in qualsiasi momento senza ulteriore revisione.
Accedendo al canale di esfiltrazione dell’attaccante – un bot Telegram – i ricercatori di Koi hanno recuperato l’intera portata dell’operazione: oltre 4.000 credenziali Microsoft rubate, numeri di carte di credito e risposte a domande di sicurezza bancaria. L’attaccante stava attivamente testando le credenziali rubate nel momento in cui è stato scoperto e gestiva almeno una dozzina di kit di phishing aggiuntivi destinati a banche e provider di webmail.
Ciò che rende questo caso particolarmente significativo è che la vulnerabilità sfruttata non è tecnica in senso stretto: è architetturale. MDSec aveva identificato gli add-in di Office come superficie d’attacco già nel 2019, concludendo il proprio post con un avvertimento esplicito sulla possibilità che gli sviluppatori potessero distribuire add-in attraverso lo store ufficiale e sulle implicazioni di sicurezza di questa architettura. Sette anni dopo, AgreeTo è esattamente lo scenario che avevano previsto.
VK Styles e il pattern emergente: quando l’estensione diventa un’infrastruttura di comando
La terza campagna della “settimana nera” delle estensioni browser – VK Styles, scoperta sempre da Koi Security – aggiunge un ulteriore livello di complessità al quadro. Cinque estensioni Chrome mascherate da strumenti di personalizzazione per VKontakte (il social network russo da oltre 650 milioni di utenti) avevano silenziosamente dirottato oltre 500.000 account, mantenendo il controllo persistente per oltre sette mesi, da giugno 2025 a gennaio 2026.
La sofisticazione di questa campagna risiede nella sua architettura di command-and-control. Invece di comunicare con server esterni facilmente bloccabili, il malware utilizzava i tag metadata HTML di un profilo VKontakte come dead drop resolver – una tecnica mutuata dall’intelligence tradizionale in cui un punto di scambio apparentemente innocuo viene utilizzato come intermediario per nascondere le comunicazioni operative – celando gli URL dei payload di secondo stadio all’interno di contenuti che, per qualsiasi sistema di sicurezza, apparivano come normali metadati di un profilo social. Il codice malevolo era ospitato in un repository GitHub pubblico associato all’utente 2vk, con 17 commit documentati che mostravano un’evoluzione deliberata e sistematica delle funzionalità.
Come riportato nell’analisi di Koi Security, questa non è opera approssimativa: è un progetto software mantenuto con controllo di versione, testing e miglioramenti iterativi. Ogni aggiornamento ampliava le capacità del malware: manipolazione dei cookie CSRF per bypassare le protezioni di sicurezza di VK, iscrizione automatica delle vittime a gruppi controllati dall’attaccante (con probabilità del 75% a ogni sessione), reset forzato delle impostazioni dell’account ogni 30 giorni e tracciamento delle donazioni tramite l’API VK Donut per monetizzare direttamente le vittime.
Il contesto strutturale: un problema che non riguarda solo febbraio 2026
La concentrazione di eventi della seconda settimana di febbraio 2026 potrebbe dare l’impressione di un picco anomalo. In realtà, è la manifestazione visibile di un trend strutturale in accelerazione.
A dicembre 2024, un attacco alla supply chain aveva compromesso l’estensione Chrome di Cyberhaven, un’azienda di cybersecurity specializzata in data loss prevention. Un attacco di phishing aveva indotto uno sviluppatore a concedere l’accesso a un’applicazione OAuth malevola denominata “Privacy Policy Extension” – senza che le credenziali Google dello sviluppatore fossero effettivamente compromesse -, consentendo agli attaccanti di pubblicare una versione malevola dell’estensione che esfiltrò cookie e sessioni autenticate per circa 24 ore. L’incidente faceva parte di una campagna più ampia che aveva compromesso almeno 35 estensioni Chrome, esponendo oltre 2,6 milioni di utenti, come documentato dai ricercatori di Hunters Security e Sekoia.
A febbraio 2026, il ricercatore indipendente Q Continuum ha pubblicato un’analisi sistematica che ha identificato 287 estensioni Chrome coinvolte nell’esfiltrazione della cronologia di navigazione verso data broker, per un totale di 37,4 milioni di installazioni – circa l’1% dell’intera base utenti globale di Chrome. Le entità coinvolte nella raccolta dei dati spaziavano da Similarweb ad Alibaba Group, da ByteDance a numerosi broker di dati minori.
Secondo un’analisi di Barracuda Networks pubblicata il 25 febbraio 2026, le estensioni browser non sono più minacce marginali o fastidi di basso livello: sono ora un vettore di attacco scalabile, furtivo e capace di condurre sorveglianza su milioni di utenti, rubare dati sensibili e compromettere silenziosamente la sicurezza organizzativa. Uno studio condotto dalla Stanford University e dal CISPA Helmholtz Center for Information Security aveva già identificato migliaia di estensioni classificabili come security-noteworthy – contenenti malware, violazioni delle policy sulla privacy o vulnerabilità note – che rimanevano disponibili per anni, accumulando milioni di installazioni.
Estensioni Chrome AI malevole: perché il brand “intelligenza artificiale” è il cavallo di Troia perfetto
C’è un motivo specifico per cui la campagna AiFrame ha scelto di mascherarsi da assistente AI, e non è casuale. L’adozione massiva di strumenti come ChatGPT, Claude, Gemini e Grok ha creato un fenomeno comportamentale senza precedenti: gli utenti sono disposti a installare qualsiasi cosa prometta funzionalità AI, con una soglia di verifica significativamente più bassa rispetto ad altri tipi di software.
L’analisi di Incogni del gennaio 2026 su 442 estensioni AI nel Chrome Web Store ha documentato che il 42% utilizza il permesso di scripting – potenzialmente in grado di influenzare 92 milioni di utenti – e il 31,4% raccoglie contenuti dei siti web visitati. Tra le estensioni con oltre 2 milioni di download, anche strumenti legittimi e noti come Grammarly e QuillBot sono stati classificati come potenzialmente ad alto impatto sulla privacy, per la combinazione di dati raccolti e permessi richiesti – pur presentando, come nota Incogni, una bassa probabilità di utilizzo malevolo.
Il brand AI funziona come leva di fiducia perché opera su tre livelli psicologici simultanei. Il primo è l’urgenza dell’adozione: in un contesto lavorativo dove l’AI è percepita come vantaggio competitivo, il ritardo nell’adozione viene vissuto come rischio professionale. Il secondo è la normalizzazione della condivisione: le interfacce conversazionali addestrano gli utenti a condividere informazioni dettagliate – codice proprietario, documenti riservati, credenziali – come parte naturale del flusso di lavoro.
Il terzo è la fiducia nel marketplace: la presenza sul Chrome Web Store, con badge “Featured” e migliaia di recensioni, crea un’apparenza di legittimità che pochi utenti contestano. Alcune delle estensioni AiFrame erano addirittura contrassegnate come “Featured” dallo store, come evidenziato sia da LayerX che da Infosecurity Magazine, aumentando ulteriormente la fiducia degli utenti e accelerandone l’adozione.
Il modello di sicurezza rotto: “approva una volta, fidati per sempre”
Il filo rosso che collega AiFrame, AgreeToSteal e VK Styles non è il tipo di dati rubati o il vettore di distribuzione specifico. È un difetto architetturale comune a tutti i marketplace di estensioni e add-in: il modello “approva una volta, fidati per sempre”.
Google verifica il codice di un’estensione al momento della pubblicazione. Microsoft verifica il manifest XML di un add-in al momento della sottomissione. Ma nessuno dei due verifica sistematicamente che cosa viene effettivamente eseguito in seguito. Nel caso di AiFrame, il codice approvato era tecnicamente benigno: caricava un iframe. Il contenuto dell’iframe, controllato dall’attaccante, poteva cambiare in qualsiasi momento. Nel caso di AgreeToSteal, il manifest dell’add-in non era mai cambiato: era l’URL di destinazione a essere stato dirottato. Nel caso di VK Styles, i payload malevoli erano ospitati su un profilo VKontakte e un repository GitHub, completamente al di fuori del perimetro di monitoraggio del Chrome Web Store.
Come ha dichiarato Dardikman di Koi Security a The Hacker News, il problema strutturale è identico in tutti i marketplace che ospitano dipendenze remote dinamiche: approvazione una tantum e fiducia perenne. I dettagli specifici variano per piattaforma, ma il gap fondamentale che ha reso possibile AgreeToSteal esiste ovunque un marketplace verifichi un manifest al momento della sottomissione senza monitorare ciò che gli URL referenziati servono effettivamente in seguito.
Vale la pena osservare che Google non è rimasta inerte. La transizione da Manifest V2 a Manifest V3, avviata nel 2023 e progressivamente imposta nel Chrome Web Store, ha introdotto restrizioni significative: i background script persistenti sono stati sostituiti da service worker con ciclo di vita limitato, i permessi devono essere dichiarati esplicitamente e le capacità di intercettazione delle richieste di rete sono state ridotte.
In teoria, MV3 avrebbe dovuto ridurre drasticamente la superficie d’attacco delle estensioni. In pratica, la campagna AiFrame dimostra i limiti di questo approccio: spostando l’intera logica malevola in un iframe remoto caricato dal server dell’attaccante, l’estensione opera in un territorio che MV3 non è progettato per governare. Il codice esaminabile al momento della pubblicazione è minimo e tecnicamente benigno; è il contenuto servito a runtime dall’infrastruttura esterna che compie le azioni malevole. MV3 ha alzato l’asticella, ma non ha risolto il problema fondamentale delle dipendenze dinamiche non monitorate.
Questo non è un bug. È un difetto di progettazione che trasforma ogni estensione browser e ogni add-in Office in una potenziale backdoor dormiente, attivabile dall’attaccante nel momento che ritiene più opportuno.
Implicazioni operative per i professionisti della sicurezza
La domanda che ogni CISO dovrebbe porsi dopo la settimana dell’11-16 febbraio 2026 non è “come impedisco agli utenti di installare estensioni malevole” – una battaglia persa in partenza. La domanda corretta è: “tratto il browser come parte della superficie d’attacco enterprise con la stessa governance che applico agli endpoint e ai servizi cloud?”.
Le contromisure efficaci operano su diversi piani complementari.
Sul piano della governance delle estensioni, le organizzazioni devono implementare policy di allowlisting che consentano l’installazione solo di estensioni specificamente approvate. Chrome Enterprise offre controlli gestiti che permettono agli amministratori IT di curare liste di estensioni sicure, bloccare minacce note e rimuovere add-on compromessi. La revisione deve essere un processo continuo, non un’approvazione una tantum: ogni aggiornamento di un’estensione autorizzata dovrebbe innescare una nuova valutazione.
Sul piano del monitoraggio comportamentale, è necessario implementare soluzioni che osservino il comportamento delle estensioni in tempo reale – trasferimenti di dati anomali, comunicazioni frequenti con server esterni, alterazione delle impostazioni del browser – piuttosto che affidarsi esclusivamente alla reputazione al momento dell’installazione. Le estensioni vanno trattate come componenti software privilegiati che richiedono sorveglianza continua.
Sul piano della detection operativa, i SOC analyst dovrebbero implementare regole specifiche per identificare i pattern documentati in queste campagne. Per la campagna AiFrame, gli indicatori critici includono: connessioni in uscita verso il dominio tapnetic[.]pro e relativi sottodomini, la presenza di iframe full-screen iniettati da estensioni che sovrappongono contenuti remoti alle pagine web attive, e l’attivazione non autorizzata dell’API Web Speech da processi collegati a estensioni.
Per AgreeToSteal, l’indicatore principale è l’add-in con ID WA200004949 e connessioni verso outlook-one.vercel[.]app. Le regole Sigma per la detection di esfiltrazione via estensioni browser dovrebbero monitorare volumi anomali di traffico HTTPS in uscita correlati ai processi del browser, in particolare verso domini registrati di recente o con bassa reputazione, e l’accesso programmatico ai contenuti di Gmail (letture DOM ripetute su mail.google.com con pattern temporali regolari). La lista completa degli indicatori di compromissione per la campagna AiFrame è disponibile nel report tecnico di LayerX.
Sul piano della riduzione della superficie d’attacco, occorre valutare criticamente i permessi richiesti da ogni estensione. Un’estensione di presa appunti che richiede accesso a tutti i dati su tutti i siti web è un segnale d’allarme. Le wildcard nei permessi host dovrebbero essere bloccate salvo giustificazione documentata. L’accesso alle API sensibili come Web Speech, clipboard e storage dovrebbe essere limitato al minimo indispensabile.
Sul piano della protezione dell’identità, il caso AiFrame dimostra che i cookie di sessione rubati tramite estensioni malevole alimentano direttamente la catena infostealer – credential marketplace – attacco ransomware. L’adozione di autenticazione FIDO2/WebAuthn, la revoca automatica delle sessioni e il monitoraggio continuo delle sessioni attive diventano essenziali quando il browser è un vettore di compromissione primario.
Sul piano della gestione degli add-in Office, il caso AgreeToSteal impone un audit sistematico di tutti gli add-in installati in ambiente Microsoft 365, con attenzione particolare a quelli non più mantenuti dallo sviluppatore originale. Gli add-in abbandonati con URL potenzialmente rivendicabili rappresentano un rischio specifico che richiede inventariazione e bonifica proattiva.
La dimensione normativa: NIS2, DORA e la responsabilità dell’organizzazione
Le implicazioni di quanto documentato non sono esclusivamente tecniche. La direttiva NIS2, in vigore nell’Unione Europea, impone alle entità essenziali e importanti l’adozione di misure di gestione del rischio cybersecurity che comprendano la sicurezza della supply chain, inclusa la gestione delle vulnerabilità nei componenti software forniti da terze parti. Le estensioni browser installate sui dispositivi aziendali rientrano pienamente in questa definizione.
Il Regolamento DORA (Digital Operational Resilience Act), applicabile al settore finanziario europeo, richiede esplicitamente la gestione del rischio ICT legato a fornitori terzi e la verifica continua della resilienza operativa digitale. Un’estensione Chrome che esfiltra il contenuto delle email aziendali e le credenziali di accesso ai servizi cloud rappresenta un incidente che rientra negli obblighi di segnalazione previsti dal regolamento.
Per le organizzazioni soggette al GDPR, la raccolta non autorizzata di email, credenziali e cronologia di navigazione attraverso estensioni malevole costituisce una violazione dei dati personali che richiede notifica all’autorità di controllo entro 72 ore dalla scoperta. Il fatto che la compromissione sia avvenuta attraverso un componente software installato dall’utente non esime l’organizzazione dalla responsabilità: la mancata governance delle estensioni browser sui dispositivi aziendali può essere contestata come inadeguatezza delle misure tecniche e organizzative previste dall’articolo 32.
Prospettive e scenari evolutivi
La traiettoria delle estensioni Chrome AI malevole nel 2026 suggerisce tre sviluppi che i professionisti della sicurezza dovrebbero anticipare.
Il primo è la convergenza tra estensioni malevole e agenti AI. Con l’adozione crescente di agenti AI che operano attraverso il browser – navigando siti, compilando moduli, interagendo con servizi web – le estensioni malevole possono intercettare, manipolare o reindirizzare le azioni degli agenti. Un’estensione che modifica silenziosamente il contenuto di una pagina prima che un agente AI lo processi può avvelenare le decisioni a valle senza lasciare tracce visibili.
Il secondo è la weaponization dei marketplace come canale di distribuzione. Il modello AiFrame dimostra che i marketplace ufficiali possono essere utilizzati come infrastruttura di distribuzione affidabile per campagne malevole su larga scala. La combinazione di extension spraying, iframe remoti e aggiornamenti server-side crea un modello di attacco altamente resiliente che le attuali policy di revisione degli store non sono in grado di contrastare efficacemente.
Il terzo è l’estensione del pattern ad altri ecosistemi. AgreeToSteal ha dimostrato che il medesimo modello di attacco – dipendenze remote dinamiche il cui contenuto può cambiare dopo l’approvazione – si applica agli add-in di Microsoft Office, ai plugin degli IDE come Visual Studio Code e potenzialmente a qualsiasi piattaforma che distribuisca componenti con dipendenze esterne non monitorate.
Conclusione: il browser non è più un’applicazione – è un perimetro
La settimana dell’11-16 febbraio 2026 ha reso evidente ciò che molti professionisti della sicurezza sospettavano da tempo: il browser è diventato un ambiente di esecuzione ad alto privilegio che opera al di fuori della governance tradizionale di endpoint e rete. Le estensioni Chrome AI malevole della campagna AiFrame, il dirottamento dell’add-in Outlook AgreeToSteal e la compromissione di massa di VK Styles non sono incidenti isolati. Sono manifestazioni di un problema architetturale che riguarda l’intero ecosistema dei marketplace software: il modello “approva una volta, fidati per sempre” è strutturalmente incompatibile con un panorama di minacce in cui gli attaccanti possono modificare il comportamento di un componente approvato in qualsiasi momento successivo alla revisione.
Per i CISO e i responsabili della sicurezza, la lezione operativa è chiara: il browser va trattato come parte integrante della superficie d’attacco enterprise, con governance, visibilità e capacità di risposta equivalenti a quelle applicate agli endpoint e ai servizi cloud. Senza questo cambio di paradigma, strumenti apparentemente innocui di produttività e personalizzazione continueranno a trasformarsi in canali di compromissione persistente che operano in piena vista.
Le estensioni Chrome AI malevole non sono una minaccia emergente. Sono una minaccia strutturale che richiede una risposta strutturale.