Google is clarifying its Smart Bidding update after advertisers questioned how budget-limited campaigns will behave beginning August 17.
The original announcement around Smart Bidding changes was June 22. The update essentially changes how Target CPA and Target ROAS campaigns behave when they’re limited by budget.
Today, many budget-limited campaigns outperform their bidding targets. Smart Bidding often enters only the auctions most likely to convert efficiently, producing stronger-than-expected CPA or ROAS.
Google says that wasn’t the intended behavior.
Instead, Smart Bidding will optimize more closely toward the Target CPA or Target ROAS advertisers actually set. Campaigns that currently outperform those targets may move closer to them after the update.
The announcement immediately raised questions across the PPC industry. Advertisers wanted to know why Google would reduce efficiency in campaigns that were already exceeding expectations.
Google’s follow-up comments answer many of those questions. They also explain why the company believes the change will make campaign scaling more predictable.
What’s Changing On August 17?
The update affects campaigns using Target CPA or Target ROAS that are limited by budget.
Historically, those campaigns often outperformed their bidding targets. A campaign with a $50 Target CPA, for example, might consistently generate conversions at $35.
Beginning August 17, Google will optimize those campaigns more closely toward the Target CPA or Target ROAS advertisers set. The company says this should create more predictable performance when advertisers adjust campaign budgets.
Google also clarified several points after announcing the update:
- Budgets will not automatically increase
- Google won’t automatically change Target CPA or Target ROAS settings
- Advertisers who want to maintain current performance may need to lower their bidding targets before the rollout
- Google is rolling out account notifications and a Bid Target Adjustment Tool to identify affected campaigns
Those clarifications addressed some of the initial confusion. They also sparked a broader discussion about how the update could affect campaign performance in practice.
The Biggest Concern: Is Google Becoming Less Efficient?
One question surfaced repeatedly as advertisers discussed the update: Is Google making Smart Bidding less efficient?
Kirk Williams summed up that concern in a LinkedIn post.
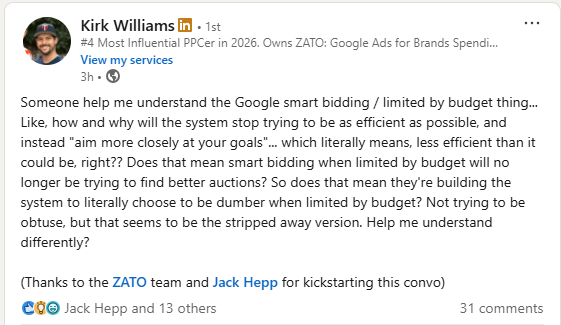
He wrote:
…How and why will the system stop trying to be as efficient as possible… Does that mean smart bidding when limited by budget will no longer be trying to find better auctions?… So does that mean they’re building the system to literally choose to be dumber when limited by budget?
Williams questioned why Google would move campaigns closer to their stated targets if Smart Bidding could already deliver stronger performance.
Mike Ryan offered one of the most detailed explanations in the comments.
Ryan argued that Google isn’t making Smart Bidding less intelligent. Instead, he believes the system has become too conservative in budget-limited campaigns.
According to Ryan, Smart Bidding has favored exploitation over exploration. Rather than entering more auctions that still satisfy an advertiser’s target, the system has focused on the safest opportunities. That produced stronger-than-expected efficiency. It also meant campaigns didn’t consistently optimize toward the Target CPA or Target ROAS advertisers actually set.
Ryan believes the updated system will follow those bidding targets more closely. That may reduce the overperformance many advertisers have seen in budget-limited campaigns, but it also aligns with Google’s stated goal of making bidding targets behave more predictably.
Predictable Scaling vs. Peak Efficiency
Aaron Levy focused on a different part of the update: campaign scaling.
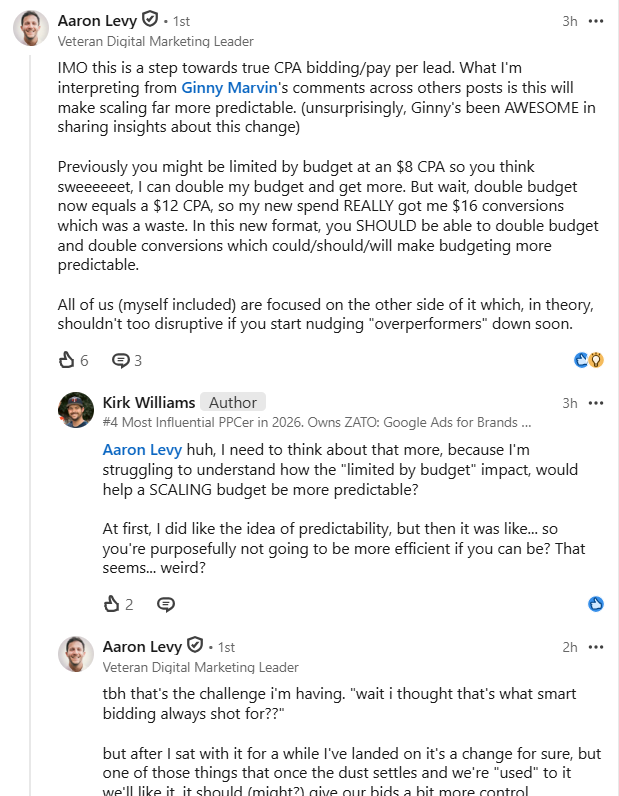
He described a campaign with an $8 CPA and a $12 Target CPA. If an advertiser doubled the budget today, the CPA might unexpectedly climb to $16 instead of remaining near the target.
Levy believes the update should make that behavior more predictable. Rather than introducing large swings in efficiency, Smart Bidding should continue optimizing toward the advertiser’s Target CPA as budgets change.
Kirk Williams questioned whether that tradeoff benefits advertisers. If Smart Bidding can already outperform a target, he argued, some advertisers may prefer that extra efficiency over more predictable budget increases.
Google has consistently framed the update around predictability. They say campaigns should optimize toward the targets advertisers actually set, making budget changes easier to manage and forecast.
Whether advertisers agree with that tradeoff will likely depend on how their campaigns perform after the rollout.
Google Clarifies Several Misconceptions
Google Ads Liaison Ginny Marvin responded directly to several concerns advertisers raised after the announcement.
One of the biggest misconceptions was that Google was encouraging advertisers to simply spend more money.
Responding to Barry Schwartz, Marvin wrote:
To be clear, this won’t result in campaign spend changes… Our guidance for those with budget-constrained campaigns currently over-performing on their target is to ensure the targets are in line with your goals.
She also emphasized that advertisers will only spend more if they choose to raise their campaign budgets. The update itself does not change campaign budgets or automatically adjust bidding targets.

Jack Carr raised a similar concern, arguing that budget constraints have historically acted as an efficiency lever and that Google’s recommendation effectively removes that advantage.
Marvin responded with a longer explanation:
Our advice is not to ‘let the system spend more money’… this change won’t result in spend changes on a campaign already budget constrained.
She also explained why Google is making the change.
Performance has often fluctuated unexpectedly… especially with budget changes. That’s not been a great experience for advertisers & made it challenging to scale campaigns with confidence.
According to Google, the backend update will make Smart Bidding optimize more consistently toward the Target CPA or Target ROAS advertisers actually set, even when campaigns are limited by budget.
Kristen Kelleher questioned whether the change would simply push campaigns into lower-quality traffic.
Marvin pushed back on that assumption as well.
The system sets bids to find as many conversions as possible at the ROAS/CPA target you set… With this update, advertisers can also expect this same behavior in budget-constrained campaigns with targets.
She added that advertisers who want to maintain today’s stronger-than-target performance should consider updating their Target CPA or Target ROAS before the rollout.
Google’s position has remained consistent throughout the discussion. The company says the update changes how closely Smart Bidding follows bidding targets. It doesn’t change campaign budgets or automatically modify campaign settings.
What This Means For Advertisers
Not every advertiser will need to make changes before August 17.
Campaigns already hitting their intended Target CPA or Target ROAS may continue operating much as they do today. The biggest impact will likely fall on budget-limited campaigns that have consistently outperformed their bidding targets.
For example, if a campaign has averaged a $20 CPA against a $35 Target CPA, Google says advertisers should consider whether $20 is now the more appropriate target. Leaving the original target unchanged could allow performance to move closer to $35 after the update.
Before the rollout, review any budget-limited campaigns that consistently outperform their Target CPA or Target ROAS. Compare current performance against your configured targets and decide whether those targets still reflect your business goals.
The update also changes how advertisers should think about bidding controls. Many advertisers have treated limited budgets as an efficiency lever because campaigns often outperformed their targets. Google has made it clear that budgets and bidding targets serve different purposes. Budgets control spend. Target CPA and Target ROAS control efficiency.
If Google’s explanation plays out as expected, advertisers who keep bidding targets aligned with actual performance should see fewer surprises when adjusting campaign budgets after August 17.
What Happens Next
Google has explained how Smart Bidding should behave after August 17. The remaining question is how closely those expectations match real-world campaign performance.
Advertisers with budget-limited Target CPA or Target ROAS campaigns will likely be watching those accounts closely after the rollout. Campaigns that have consistently outperformed their bidding targets may provide the clearest indication of how much the update changes day-to-day performance.
Google has also encouraged advertisers to review bidding targets before the rollout if current performance already aligns with their business goals. As more accounts transition to the updated bidding behavior, advertisers should have a better understanding of how the change affects campaign efficiency and budget management in practice.
Featured image: Roman Samborskyi / Shutterstock
https://www.searchenginejournal.com/google-clarifies-smart-bidding-update-after-advertiser-concerns/581804/