I’ve been extremely antsy to publish this study. Consider it the AIO Usability study 1.5, with new insights. You also want to stay tuned for our first AI Mode usability study! It’s coming in a few weeks (make sure to subscribe not to miss it).
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Since March, everyone’s been asking the same question: “Are AI Overviews killing our conversions?”
Our 2025 usability study gives a clearer answer than the hot takes you’ll see on LinkedIn and X (Twitter).
In May 2025, I published significant findings from the first comprehensive UX study of AI Overviews (AIOs). Today, I’m presenting you with new insights from that study based on a cutting-edge RAG system that analyzed over 100,000 words of transcription.
The most significant, stand-out finding from that study: People use AI Overviews to get oriented and save time.
Then, for any search that involves a transaction or high-stakes decision-making, searchers validate outside Google, usually with trusted brands or authority domains.
Net-net: AIO is a preview layer. Blue links still close. Before we dive in, you need to hear these insights from Garrett French, CEO of Xofu, who financed this study:
“What lit me up most from this latest work from Kevin: We have direct insight now into an “anchor pattern” of AIO behavior.
In this usability study, we discovered that users rarely voice distrust of AI Overviews directly – instead they hesitate, refine, or click out.
Therefore, hesitation itself is the loudest signal to us.
We see the same in complex, transition-enabling purchase-committee buying (B2B and B2C): Procurement stalls without lifecycle clarity, engineer stall without specs, IT stalls without validation.
These aren’t complaints. They’re unresolved, unanswered, and even unknown questions that have NEVER shown themselves in KW demand.
As content marketers, we have never held ourselves systematically accountable to answering them.
Customer service logs – as an example of one surface for discovering friction – expose the same hesitations in traceable form through repeated chats, escalations, deployment blocks, etc.
Customer service logs are one surface; AIOs are another.
But the real source of truth is always contextual audience friction.
Answering these “friction-inducing, unasked latent questions give us a way to read those signals and design content that truly moves decisions forward.
What The Study Actually Found:
- Organic results are the most trusted and most consistently successful destination across tasks.
- Sponsored results are noticed but actively skipped due to low trust.
- In-SERP answers quickly resolved roughly 85% of straightforward factual questions.
- Users often use AIO as a preview or shortcut, then click out to finish or validate (on brand sites, YouTube, coupon portals, and the like).
- Shopping carousels aid discovery more than closure. Expect reassessment clicks.
- Trust splits by stakes: Low-stakes search journeys often end in the AIO, while finance or health pushes people to known authorities like PayPal, NIH, or Mayo Clinic.
- Age and device matter. Younger users, especially on smartphones, accept AIOs faster; older cohorts favor blue links and authority domains.
- When the AIO is wrong or feels generic, people bail. We logged 12 unique “AIO is misleading/wrong” flags in higher-stakes contexts.
(Interested in diving deeper into the first findings from this study or need a refresher? Read the first full iteration of the UX study of AIOs.)
Why This Matters For The Bottom Line
In my earlier analysis, I argued that top-of-funnel visibility had more downstream impact than our marketing analytics ever credited. I also argued that demand doesn’t just disappear because clicks shrink.
This study’s behavior patterns support that: AIO satisfies quick lookup intent, but purchase intent still routes through external validation and brand trust – aka clicks. Participants in this study shared thoughts aloud, like:
- “There’s the AI results, but I’d rather go straight to PayPal’s own site.”
- “Mayo Clinic at the top of results, that’s where I’d go. I trust Mayo Clinic more than an AI summary.”
And that preserves downstream conversions (when you show up in the right places and have earned authority).
 Image Credit: Kevin Indig
Image Credit: Kevin IndigDeeper Insights: Secondary Findings You Need To See
Recently, I worked with Eric Van Buskirk (the research director of the study) and his team over at Clickstream Solutions to do a deeper analysis of the May 2025 findings.
Using an advanced RAG-driven AI system, we analyzed all 91,559 (!) words of the transcripts from recorded user sessions across 275 task instances.
This is important to understand: We were able to find new insights from this study because Eric has built cutting-edge technology.
Our new RAG system analyzes structured fields like SERP Features, AIO satisfaction, or user reactions from transcriptions and annotations. It creates a retrieval layer and uses ChatGPT-5 for semantic search.
The result is faster, more rigorous, and more transparent research. Every claim can be traced to data rows and transcript quotes, patterns are checked across the full dataset, and visual evidence is a query away.
(To sum that all up in plain language: Eric’s custom-built advanced RAG-driven AI system is wildly cool and extremely effective.)
Practical benefits:
- Auditable insights: Conclusions map back to exact data slices.
- Speed: Test a hypothesis in minutes instead of re-reading sessions.
- Scale: Triangulate transcripts, coded fields, and outcomes across all participants.
- Fit for the AI era: Clean structure and trustworthy signals mirror how retrieval systems pick sources, which aligns with our broader stance on visibility and trust.
Here’s what we found:
- The data verified four distinct AIO Intent Patterns.
- Key SERP features drove more engagement than others.
- Core brands shape trust in AIOs.
About The New RAG System
We rebuilt the analysis on a retrieval-augmented system so answers come from the study data, not model guesswork. The backbone lives on structured fields with full transcripts and annotations, indexed in a lightweight database and paired with bucketed data for cohort filtering and cross-checks.
Core components:
- Dataset ingestion and cleaning.
- Retrieval layer based on hybrid keyword + semantic search.
- Auto-coded sentiment to turn speech into consistent, queryable signals.
- Validation loop to minimize hallucination.
The result is faster, more rigorous, and more transparent research. Every claim can be traced to rows and quotes, patterns are checked across the full dataset, and visual evidence is a query away.
Practical benefits:
- Map conclusions back to exact data slices.
- Test a hypothesis in minutes.
- Triangulate transcripts, coded fields, and outcomes across all participants.
- Clean structure and trustworthy signals.
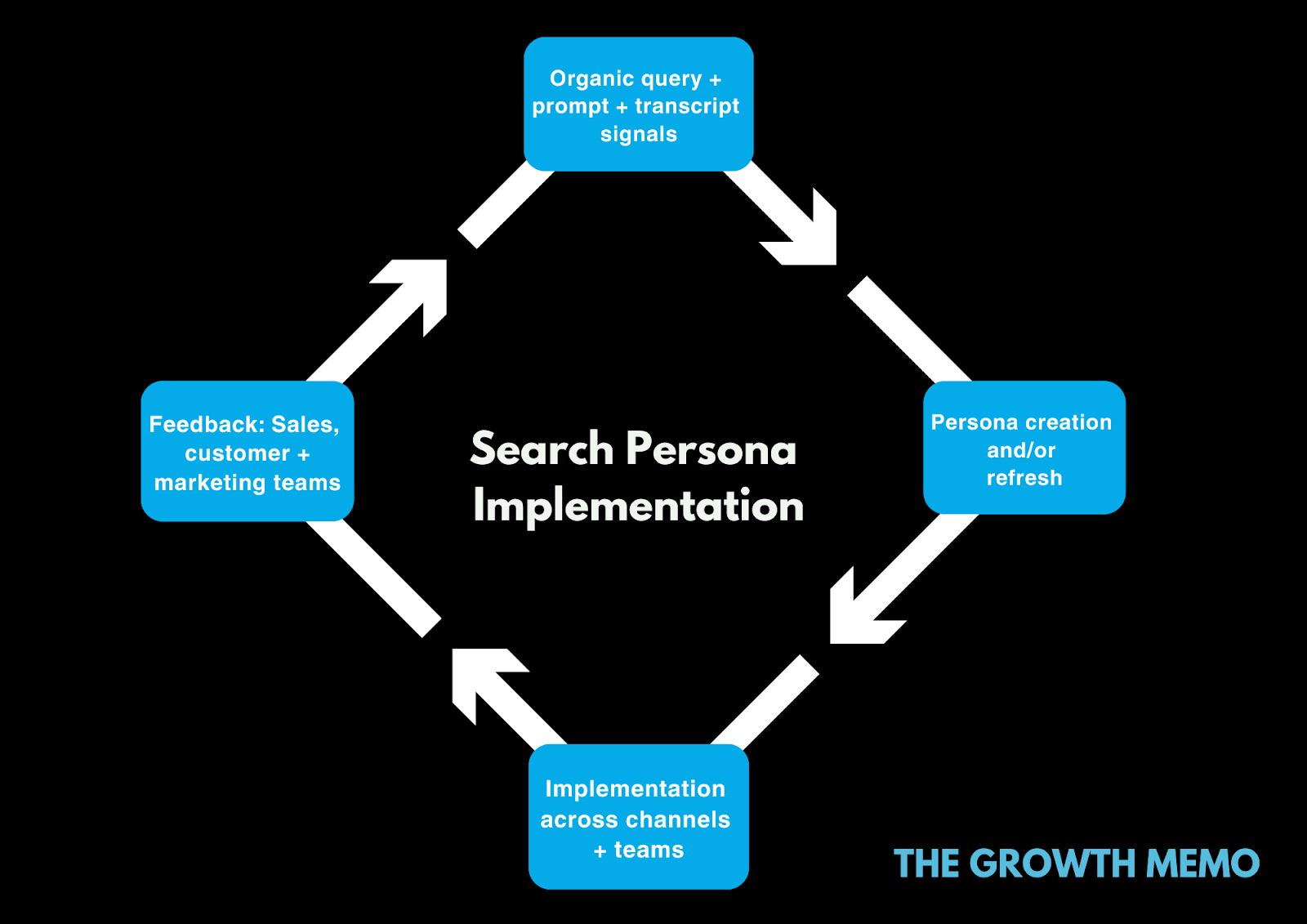
Which AIO Intent Patterns Were Verified Through The Data
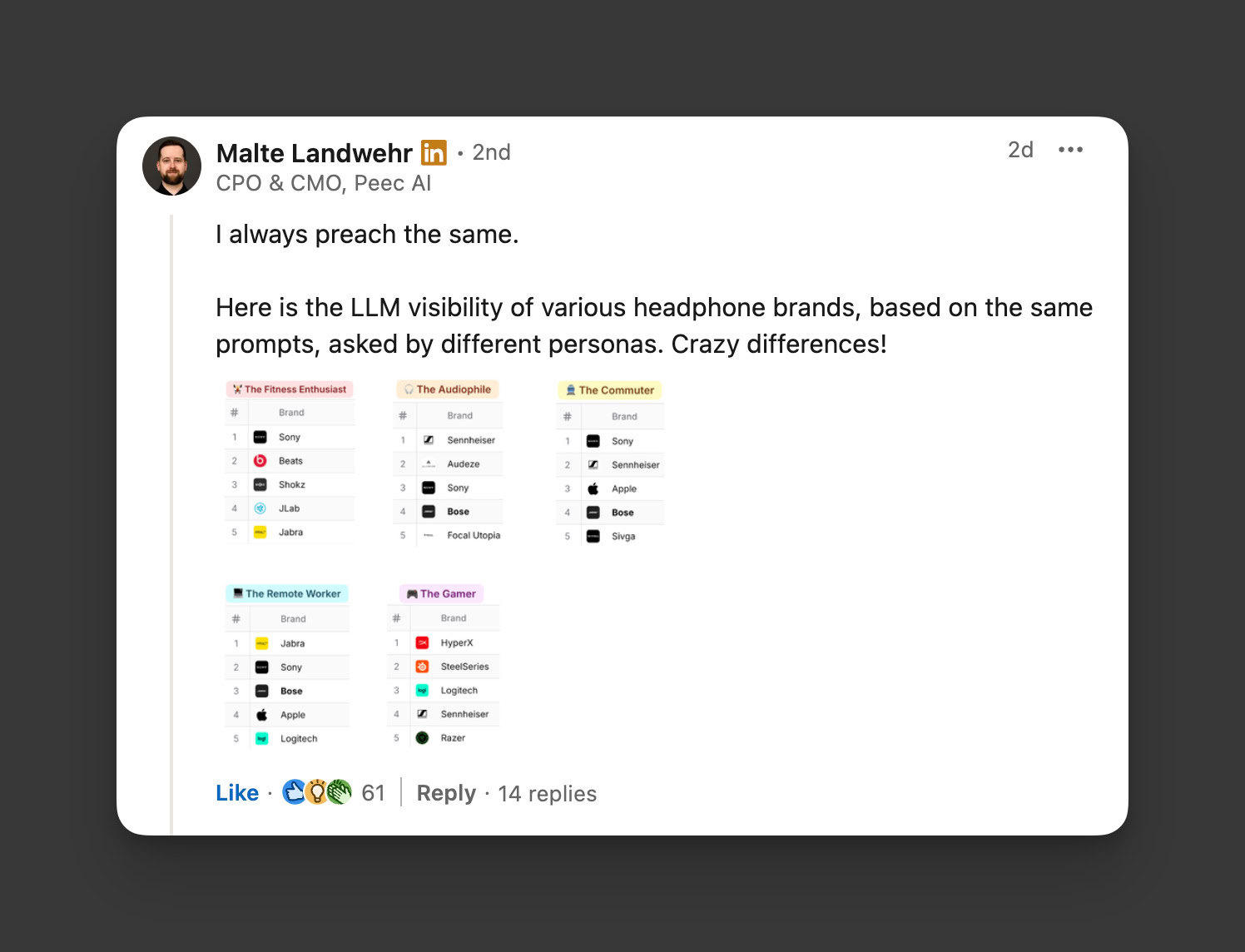
One of the biggest secondary findings from the AIO usability study is that the AIO Intent Patterns aren’t just “gut feelings” anymore – they’re statistically validated, built from measurable behavior.
Before some of you roll your eyes and annoyingly declare “here’s yet another newly created SEO/marketing buzzword,” the patterns we discovered in the data weren’t exactly search personas, and they weren’t exactly search intents, either.
Therefore, we’re using the phrase “AIO Intent Pattern” to distinguish these concepts from one another.
Here’s how I define AIO Intent Patterns: AIO Intent Patterns represent statistically validated clusters of user behavior – like dwell, scroll, refinements, and sentiment – that define how people respond to AIOs. They’re recurring, measurable behaviors that describe how people interact with AI Overviews, whether they accept, validate, compare, or reject them.
And, again, these patterns aren’t exactly search intents or queries, but they’re not exactly user profiles either.
Instead, these patterns represent a set of behaviors (that appeared throughout our data) carried out by users to validate AIOs in different and distinct ways. So that’s why we’ve called the individual behavioral patterns “validations” below.
By running a RAG-driven coding pass across 250+ task instances, we were able to quantify four different behavioral patterns of engagement with AIOs:
- Efficiency-first validations that reward clean, extractable facts (accepting of AIOs).
- Trust-driven validations that convert only with credibility (validate AIOs).
- Comparative validations that use AIOs but compare with multiple sources.
- Skeptical rejections that automatically distrust AIOs for high-stakes queries.
What matters most here is that these aren’t arbitrary labels.
Statistical tests showed the differences in dwell time, scrolling, and refinements between the four groups were far too large to be random.
To put it plainly: These are real AIO use behavioral segments or AIO use intents you can plan for.
Let’s look at each one.
1. Efficiency-First Validations
These are validations where users intend to seek a shortcut. Users dip into AIOs for fast fact lookups, skim for one answer, and move on.
Efficiency-driven validations thrive on content that’s concise, scannable, and fact-rich. Typical queries that are resolved directly in the AIO include:
- “1 cup in ml”
- “how to take a screenshot on Mac”
- “UTC to CET converter”
- “what is robots.txt”
- “email regex example”
Below, you can check out two examples of “efficiency-first validation” task actions from the study.
“Okay, so I like the summary at the top. And I would go ahead and follow these instructions and only come back to a search if they didn’t work.”
“I just had to go straight to the AI overview… and I liked that answer. It gave me the information I needed, organized and clear. Found it.”
Our data shows an average dwell time of just 14 seconds for this group overall, with almost no scrolling or refinements.
Users that have an efficiency-first intent for their queries have a neutral to positive sentiment toward AIOs – with no hesitation flags – because AIOs scratch the efficiency-intent itch quickly.
For this behavioral pattern, the AIO often is the final answer – especially on mobile – and if they do click, it’s usually the first clear, extractable source.
👉 Optimization tips for this validation group:
- Compress key facts into crisp TLDRs, FAQs, and schema so AIO can surface them.
- Place definitions, checklists, and example blocks near the top of your page.
- Use simple tables and step lists that can be lifted cleanly.
- Ensure brand mentions and key facts appear high on the page for visibility.
2. Trust-Driven Validations
These validations are full of caution. Users with trust-driven intents engage with AIOs but rarely stop there.
They’ll skim the overview, hesitate, and then click out to an authority domain to validate what they saw, like in this example below:
The user shares that “…at the top, it gave me a really good description on how to transfer money. But I still clicked the PayPal link because it was directly from the official site. That’s what I went with – I trust that information to be more accurate.”
Typical queries that trigger this validation pattern include:
- “PayPal buyer protection rules”
- “Mayo Clinic strep symptoms”
- “Is creatine safe long term”
- “Stripe refund timeline”
- “GDPR consent requirements example”
And our data from the study verifies users scroll more (2.7x on average), dwell longer (~57s), and often flag uncertainty in trust-driven mode. What they want is authority.
These users have a high rate of hesitation flags in their search experiments. Their sentiment is mixed – often neutral, sometimes anxious or frustrated – and their confidence is only medium to low.
For these searches, the AIO is a starting point, not the destination. They’ll click out to Mayo Clinic, PayPal, Stripe, or other trusted domains to validate.
👉 Optimization tips for this validation group:
- Reinforce trust scaffolding on your landing pages: expert reviewers, citations, and last-reviewed dates.
- Mirror official terminology and link to primary sources.
- Add “What to do next” boxes that align with authority guidance.
- Build strong E-E-A-T signals since credibility is the conversion lever here.
3. Comparative Validations
This search intent actively leans into the AIO for classic comparative queries (think “Ahrefs vs Semrush for content teams”) to fulfill their search intent OR to compare informational resources to get clarity on the “best” of something; they expand, scroll, refine, and use interactive features – but they don’t stop there.
Instead, they explore across multiple sources, hopping to YouTube reviews, Reddit threads, and vendor sites before making a decision.
Example queries that reveal AIO comparative validation behavior:
- “Notion vs Obsidian for teams”
- “Best mirrorless camera under 1000”
- “How to change a bike tire”
- “Standing desk benefits vs risks”
- “Programmatic SEO examples B2B”
- “How to install a nest thermostat”
Here’s an example using a “how to” search, where the user is comparing sources for the best way to receive the most accurate information:
“The AI Overview gave me clear step-by-step instructions that matched what I expected. But since it was a physical DIY task, I still preferred to branch out to watch a video for confirmation.”
On average, searchers looking for comparative validations in the AIO dwell for 45+ seconds, scroll 4-5 times, and often open multiple tabs.
Their AIO sentiment is positive, and their confidence is high, but they still want to compare.
If this feels familiar – like classic transactional or commercial search intents – it’s because it is related.
If you’ve been doing SEO for any time, it’s likely you’ve created some of these “versus” or “comparison” pages. You also have likely created “how to” content with step-by-step how-to guidance, like how to install a flatscreen TV on your wall.
Before AIOs, your target users would find themselves there if you ranked well in search.
But now, the AIO frames the landscape first, and the decision comes after weighing pros and cons across information sources to find the best solution.
👉 Optimization tips for this validation group:
- Publish structured comparison pages with decision tables and use-case breakdowns.
- Pair each page with short demo videos, social proof, and credible community posts to echo your takeaways.
- Include “Who it is for” and “Who it isn’t for” sections to reduce ambiguity.
- Seed content in YouTube and forums that AIOs (and users) can pick up.
4. Skeptical Rejections
Searchers with a make-or-break intent? They’re the outright AIO skeptical rejectors.
When stakes are high – health, finance, or legal … the typical YMYL (Your Money, Your Life) stuff – they don’t trust AIO to get it right.
Users may scan the summary briefly, but they quickly move to authoritative sources like government sites, hospitals, or financial institutions.
Common queries where this rejection pattern shows up:
- “Metformin dosage for PCOS”
- “How to file taxes as a freelancer in Germany”
- “Credit card chargeback rights EU”
- “Infant fever when to go to ER”
- “LLC vs GmbH legal liability”
For this search intent, the dwell time in an AIO is short or nonexistent, and their sentiment often skews negative.
They show determination to bypass the AI layer in favor of direct authority validation.
👉 Optimization tips for this validation group:
- Prioritize citations and mentions from highly trusted domains so AIOs lean on you indirectly.
- Align your pages with the language and categories used by official sources.
- Add explicit disclaimers and clear subheadings to strengthen authority signals.
- For YMYL topics, focus on being cited rather than surfaced as the final answer.
SERP Features That Drove Engagement
Our RAG AI-driven system of the usability data verified that not all SERP features are created equal.
When we cut the data down to only features with meaningful engagement – which our study defined as ≥5 seconds of dwell time across at least 10 instances – only four SERP features findings stood out.
(I’ll give you a moment to take a few wild guesses regarding the outcomes … and then you’ll see if you’re right.)
Drumroll please. 🥁🥁🥁
(Okay, moment over. Here we go.)
1. Organic Results Are Still The Backbone
Whenever our study participants gave the classic blue links more than a passing glance, they almost always found success.
Transcripts from the study make it explicit: Users trusted official sites, government domains, and familiar authority brands, as one participant’s quote demonstrates:
“Mayo Clinic at the top of results, that’s where I’d go. I trust Mayo Clinic more than an AI summary.”
What about social or community sites that showed up in the organic blue-link results?
Reddit and YouTube were the social or community platforms found in the SERP that were mentioned most by study participants.
Reddit had 45 unique mentions across the entire study. Overall, seeing a Reddit result in organic results produces a user sentiment that is mostly positive, with some users feeling neutral toward the inclusion of Reddit in search, and very few negative comments about Reddit results.
YouTube had 20 unique mentions across the entire study. The sentiment toward YouTube inclusion in SERP results was overwhelmingly positive (19 out of 20 of those instances had a positive user sentiment). The emotions flagged from the study participants around YouTube results included happy/satisfied or curious/exploring.
There was a very clear theme across the study that appeared when social or community sites popped up in organic results:
- Reddit was invoked when participants wanted community perspective, usually in comparison tasks. Confidence was high because Reddit validated nuance, but AIO trust was weak (users bypassed AIOs to Reddit instead).
- YouTube was used as a visual validator, especially in product or technical comparison tasks. Users expressed positive sentiment and high satisfaction, even when explicit trust wasn’t verbalized. They treated YouTube as a natural step after the AIOs/organic SERP results.
2. Sponsored Results Barely Register
People saw them, but rarely acted on them. “I don’t like going to sponsored sites” was a common refrain.
High visibility, but low trust.
3. Shopping Carousels Aid Discovery But Not Closure.
Participants clicked into Shopping carousels for product ideas, but often bounced back out to reassess with external sites.
The carousel works as a catalog – not a closer.
4. Featured Snippets Continue To Punch Above Their Weight
For straightforward factual lookups, Snippets had an ~85% success rate of engagement.
They were efficient and final for fact-based queries like [example] and [example].
⚠️ Important note: Even though Google is replacing Featured Snippets with AIOs, it’s clear that this method of receiving information within the SERP has a high engagement. While the SERP feature may be in the process of being discontinued, the data shows users like engaging with snippets. The takeaway here is that if you were often appearing for featured snippets and you’re now often appearing for AIO citations, keep up the good work to continue earning visibility there, because it still matters.
SERP Features x AIO Intent Patterns
When you keep the intent pattern layers in mind with different persona groups, it makes the search behaviors sharper:
- Younger users on mobile leaned heavily on AIO and snippets, often stopping there if the stakes were low. → That’s the hallmark of efficiency-first validations (quick fact lookups) and comparative validations (scrolling, refining, and treating AIO as the main lens).
- Older users consistently bypassed AI elements in favor of organic authority results. → This is classic behavior for trust-driven validations, when users click out to brands like PayPal or the Mayo Clinic, and skeptical rejections, when users distrust AIO altogether for high-stakes tasks.
- Transactional queries – money, health, booking – nearly always pushed people toward trusted brands, regardless of what AIO or ads surfaced. → This connects directly to trust-driven validations (users who need authority reinforcement to fulfill their search intent) and skeptical rejections (users who reject AIO in YMYL contexts because AIOs don’t meet the intent behind the behavior).
What this shows is that, for SEOs, the priority isn’t about chasing every feature and “winning them all.”
Take this as an example:
“The AI overview didn’t pop up, so I used the search results. These were mostly weird websites, but CNBC looked trustworthy. They had a comparison of different platforms like CardCash and GCX, so I went with CNBC because they’re a trusted source.”
Your job is to match intent (as always):
- Earn extractable presence in AIOs for quick facts,
- Reinforce trust scaffolding on authority-driven organic pages, and
- Treat Shopping and Sponsored slots as visibility and awareness plays rather than conversion levers.
Which Brands Shaped Trust In AIOs
AIOs don’t stand on their own; they borrow credibility from the brands they surface – whether you like it or not.
(Google truly seems to be cannibalizing itself while devouring all of us, too.)
When participants validated or rejected an AI answer, it often hinged on whether a familiar or authoritative brand was mentioned.
Our RAG-coded study data surfaced clear winners:
- Institutional authorities like PayPal, NIH, and government sites consistently shaped trust, even without clicks.
- Ecommerce and retail giants (Amazon, Walmart, Groupon) carried positive associations from brand familiarity.
- Financial and tax prep services (H&R Block, Jackson Hewitt, CPA mentions) were trusted anchors in transactional searches.
- Car rental brands (Budget, Avis, Dollar, Kayak, Zipcar, Turo) dominated travel-related tasks.
- Emerging platforms (Raise, CardCash, GameFlip, Kade Pay) gained traction primarily because an AIO surfaced them, not because of prior awareness.
👉 Why it matters: Brand trust is the glue between AIO exposure and user action.
Here’s a quick paraphrase of this user’s exploration: We’re looking for places to sell gift cards for instant payment. Platforms like Raise, Gift Card Granny, or CardCash come up. On CardCash, I tried a $10 7-Eleven card, and the offer was $8.30. So they ‘tax’ you for selling. That’s good to know – but it shows you can sell gift cards for cash, and CardCash is one option.
In this instance, the AIO surfaced CardCash. The user didn’t know about it before this search. They explored it in detail, but trust friction (“they tax you”) shaped whether they’d actually use it.
For SEOs, this means three plays running in tandem:
- Win mentions in AIOs by ensuring your content is structured, scannable, and extractable.
- Strengthen authority off-site so when users validate (or reject the AIO), they land on your pages with confidence.
- Build topical authority in your niche through comprehensive persona-based topic coverage and valuable information gain across your topics. (This can be a powerful entry point or opportunity for teams competing against larger brands.)
What does this all mean for your own tactical optimizations?
But here’s the most crucial thing to take away from this analysis today:
With this information in mind, you can now go to your stakeholders and guide them to look at all your prompts, queries, and topics with fresh eyes.
You need to determine:
- Which of the target queries/topics are quick answers?
- Which of the target queries/topics are instances where people need more trust and assurance?
- When do your ideal users expect to explore more, based on the target queries/topics?
This will help you set expectations accordingly and measure success over time.
Featured Image: Paulo Bobita/Search Engine Journal
https://www.searchenginejournal.com/trust-still-lives-in-blue-links/555592/