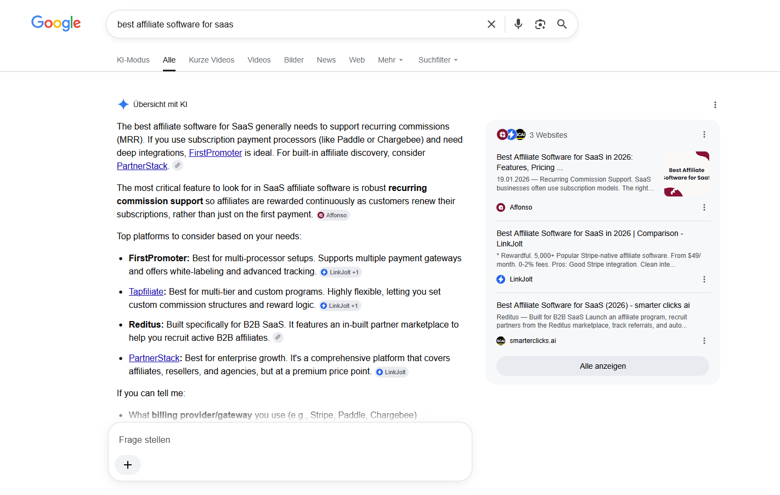
You Can’t See How AI Ranks You, So Build What It Can Read via @sejournal, @slobodanmanic
Web strategy in the AI era has a strange shape. You spend your days optimizing for systems nobody will let you look inside. You publish, you watch the traffic move, and when an AI answer surfaces a competitor instead of you, there is no panel that explains why. So when a regulator forces one of these systems to show its work, the question gets concrete: What actually changes for the people who build websites? After reading the order, the honest answer is two things at once. The recourse is real and worth taking seriously. The work it points to is not new.
A Regulator Is Forcing Google To Explain How It Ranks
On June 17, the UK Competition and Markets Authority used Google’s Strategic Market Status designation, granted last October on the basis that Google handles more than 90% of UK search, to impose two binding rules. The first matters to anyone with a website. Google has to rank organic results by “objective and non-discriminatory criteria,” and the regulator wrote that this applies inside AI Overviews, not only the 10 blue links. Google also has to give businesses real transparency into how ranking works, advance notice before major changes to its ranking systems, and a documented process to raise complaints. It has six months. “Step by step, we’re ensuring that Google’s search services work better for businesses and consumers across the UK,” said Will Hayter, the CMA’s executive director for digital markets.
For 25 years, the ranking system was something you inferred from the outside, never something you could question from the inside. Advance notice of changes and a real complaints process is recourse web professionals have never had, and “objective criteria” is a promise that the unexplained demotion has to end. It is UK-only for now, Google will contest it, and nothing is live for six months. But rules like this rarely stay in one country, and the direction is not ambiguous. The layer that decides whether your website is seen might end up being exposed.
Opening The Box Would Change Less Than You Hope
Now run the thought experiment all the way. Say the order goes further than anyone expects, and you could read the exact criteria that decide what gets surfaced and cited, across every engine, not only Google. What would you actually do differently?
You would probably change less than the excitement suggests. Transparency would settle many arguments, sure. It would end the seasonal debate over whether llms.txt does anything (the latest large-scale data says it does not), whether schema markup is a citation cheat code (a controlled study says it is not), whether stuffing a page with “best in class” claims earns the recommendation (it earns the citation and loses the recommendation to the competitors you named). Seeing the rubric would kill the folklore. It would not change the work. A system reading your website still has to find the answer, parse it cleanly, and have some reason to trust it. Whether you can see the criteria or not, the page either presents its substance in a form a machine can extract, or it hides it behind something the machine never runs.
That through-line sits under every one of these stories. A court in Munich ruled in May that Google’s AI Overview is Google’s own speech, which Google can be held liable for. The AI answer is being treated as a product with an owner and rules. None of that touches the one input you fully control, which is whether your content is legible to the thing doing the answering.
Audit What A Machine Can Read On Your Website Today
Waiting for the box to open is the wrong instinct. That is someone else’s six-month timeline, in one country. The right move now is to audit what a machine can already read on your website, and fix what it cannot.
Run three checks, in order.
Rendering First: Does your meaningful content exist in the HTML a system receives, or does it depend on client-side JavaScript that most AI fetchers never run? Load your most important page with JavaScript disabled and see what is left.
Verifiability Last: Are the facts that define you, who you are, what you sell, what is true about it, stated plainly and consistently across your website, or does the machine have to take your word for claims it cannot confirm anywhere else?
That is machine-first work, and it is the same work whether Google is forced to publish its criteria or not. It’s upstream of every ruling, which is why it will survive all of them. A website a machine can read, parse, and verify wins in the opaque version of this world and in the transparent one. The only thing transparency would add is proof you were right.
So, when that black box opens is not on your roadmap. A regulator or a court could force that, in their country, on their clock. What should be on your roadmap is whether the answer to a real question about your business sits in your HTML right now, in a form a machine can lift out and trust. You don’t need anyone’s permission to do that.
AI Search: Is Your Content Strategy Accidentally Recommending Your Competitors?
This post was sponsored by FirstPromoter. The opinions expressed in this article are the sponsor’s own.
For years, software companies have published pages that rank the best tools in a category and place their own product at the top. The tactic was cheap and easy to scale, and for a long time it helped shape what buyers saw.
In AI search, comparison listicles backfire. Google’s AI Overview quotes the listicle as a source, then recommends a competitor from your own cited list.
Your content only gets the citation. Meanwhile, your competitor gets the recommendation and the click. Your competitor gets the sale.
What makes your cited content recommend competitors?
Lily Ray quantified how often a brand’s own listicle earns the citation but loses the recommendation to a competitor.
In research published in June 2026, she analyzed 100 B2B “best [category] software” queries in Google’s AI Overviews and checked the same queries three times between April and June.
The Results
Across the 80 queries that produced an AI Overview, self-ranked listicles were cited 323 times. In 224 of those cases, Google named a brand’s own page, then recommended a rival ranked inside it.
In other words, when a brand’s own listicle was cited, that brand was left out of the recommendation 69% of the time.
What’s the Difference Between Being Cited & Being Recommended in AI Search?
AI search produces two separate outcomes, and only one of them drives sales.
A citation means the engine named a page as one of the sources behind its answer.
A recommendation means the answer told the reader which product to choose.
The recommendation is what buyers act on.
A citation is easy to mistake for progress, because the brand still appears on the screen.
What an engine cites depends on the content of the page. What it recommends depends on what the rest of the web says about a brand: how many independent sites mention it, link to it, and review it.
Why Does Self-Promotional Content Backfire in AI Search?
Google now treats self-ranked pages differently in its AI answers, Ray found.
The brands that win recommendations are the established names the web already covers.
Recommended brands had far more referring domains, and far more mentions across AI Overviews and ChatGPT, than brands that were cited and passed over.
On-page changes can’t fix this. The gap isn’t on the page; the citation-recommendation gap lies within how often the rest of the web covers the brand.
How to Measure Whether AI Search Recommends Your Brand
You can run this check for any category without special tools. Because citations and recommendations carry different intent, the goal is to separate two figures that usually get combined:
How often your brand is cited (informational intent).
How often it is recommended (transactional intent).
Step 1: Build Your Query List
Start with the questions a buyer would type, such as “best project management software,” “Notion alternatives,” or “best [category] software.”
Step 2: Record Citations & Recommendations Separately
Run each one in Google and record two things: the pages Google cites as sources, and the products it recommends in the answer.
Step 3: Repeat Each Query
Run each query more than once, since AI answers shift from session to session.
Step 4: Score Your Share of Voice
Then score the share of recommendations won, rather than the number of citations earned.
Step 5: Extend the Audit Beyond Google
The pattern is documented for Google’s AI Overviews, so begin there. Run the same queries through ChatGPT and Perplexity to map which publishers those engines surface for your category.
Ray’s research shows what the exercise produces. For “best LMS for selling courses,” Google cited Oasis LMS repeatedly, in the body of the answer and in the sidebar. Oasis ranks itself number one in that article. Google recommended Kajabi, Thinkific, LearnWorlds, and Teachable instead, each of them named inside the Oasis piece.
Ray found the same split across categories, from CRM to help desk to SEO software.
Finding 2: Do AI Recommendations Come From Coverage You Don’t Publish? Yes.
Ray’s data shows where AI recommendations originate. Google leans heavily on third-party and user sites, with Reddit, Forbes, and YouTube among the most-cited domains. Content independent from the brand earns a recommendation: reviews, comparisons, and walkthroughs published by someone other than the vendor.
How Do You Get More Independent Brand Mentions That Win AI Recommendations?
Each of these should be published by third parties. Not one placement at a time, but as ongoing output.
How Do You Do This Quickly?
Give creators a financial reason to publish. When a creator earns money each time their coverage converts a customer, they keep writing reviews, updating comparisons, and publishing walkthroughs, without you commissioning each piece.
You can start with a handful of creators and a revenue-share agreement. What that produces is coverage. What it does not produce, on its own, is consistency.
How Do You Keep A Consistent Flow Of Mentions?
Run an always-on channel: an affiliate program. Paying creators piece by piece gets you a review here and a comparison there. Mention velocity stays flat because every new URL requires new outreach. Consistent output takes structure: recruiting good partners, tracking what each one produces, rewarding the ones who perform, and paying them on time. An affiliate program is that structure.
Affiliates are third parties who earn a commission when a customer they refer makes a purchase. They include niche site owners, YouTube reviewers, newsletter writers, and media publishers. To earn it, they write reviews, record walkthroughs, and publish side-by-side comparisons on their own sites and channels. That content is what Google draws from when answering a “best [category] software” query.
Proof of Concept: The Brands That Dominate AI Answers Already Run Programs At This Scale.
Run any “best [category] software” query and the same names recur. Behind them sit networks of third-party sites reviewing and comparing those products, earning a commission on the customers they refer. Their referring domain counts keep climbing because the program funds new coverage continuously.
Programs built for editorial output win; programs built for referral volume don’t. A program aimed at raw referral volume tends to attract coupon and deal sites, which drive clicks but rarely publish the editorial content AI Overviews cite. A program aimed at AI recommendations recruits partners who write and review for a living, and favors partners with real audiences over partners who only distribute discount codes.
Telling a strong partner from a weak one takes judgment. The signals worth checking are long-term organic search performance, credible mentions on sites the partner doesn’t control, and a presence across more than one platform. Partners who rank well in AI Overviews usually have that track record already.
“Affiliates are one of the biggest sources of AI citations right now, and yet most brands don’t even think about it. A citation in an AI Overview today doesn’t mean much on its own, because we’re seeing AI-generated sites get cited for a few weeks and then disappear once Google catches up to them. So check the organic history behind it first, look at the fluctuations, scroll through the content. And do that for every partner type, not just websites. A YouTube channel or an influencer can end up in an AI answer too, and they need the same check.” – Tautvydas Vasiliauskas
A referring domain earned this quarter doesn’t keep earning on its own. The brands that hold AI recommendations are the ones whose third-party coverage keeps growing, and that output depends on partners staying active.
Partners stay active when the program is run well. Each task involved is simple. Done by hand, together they consume the hours the program was supposed to save.
Time is not the only thing at stake. AI systems draw recommendations from the pool of referring domains that mention a brand. Low-quality affiliates and self-referrals pollute that pool., and when they do, the citations a program earned stop counting in the brand’s favor.
Keeping the pool clean requires detecting fraud, vetting partners, and blocking self-referrals, continuously, not as a one-time cleanup.
This is the operational work FirstPromoter handles. It tracks each partner’s performance and ties it to revenue, so you can see which partners produce sales, and which produce the coverage AI Overviews cite. It keeps partners motivated with contests, performance tiers that pay higher commissions, one-time placement fees, and target bonuses. Payouts run on a scale from do-it-yourself to fully managed, and setup requires little to no developer resource.
The software won’t choose partners or brief them; that judgment stays with you. It handles the operations, so the coverage keeps compounding without constant hands-on work.
Stop Building Content That Benefits Your Competitors. Start Building Connections That Reinforce Your Brand.
The self-ranked listicle had a good run, and that run is ending. In AI search, Google gives the recommendation to the brands the wider web already trusts, and it builds that trust out of independent content.
An affiliate program is one of the most direct ways to produce content that gets you brand recommendations, and you pay for it based on results rather than adding headcount. It’s worth considering whether you’re starting a program or already run one. FirstPromoter offers a free trial to test the approach.
62% Of AI Brand Recommendations Vanish After One Buyer Question – New Clovion Data via @sejournal, @gregjarboe
Zahir Hasan didn’t have to tell me his company’s numbers were wrong.
I’d sent Hasan, COO of the Oslo-based research firm Clovion AI, a list of methodology questions about “Surviving the AI Funnel,” Clovion’s new study of how Claude, ChatGPT, and Gemini recommend brands across a conversation. Question ten was routine, the kind of thing you ask every research team. The report says the three AI assistants flatly contradict each other on brand facts 15% of the time, based on 33 verified contradictions. Was 33 really enough to support a claim about which model tends to undersell a brand’s features and which tends to oversell them?
Hasan’s answer wasn’t a defense of the number. It was a correction. “The real number is 330,” he wrote back. “A designer dropped a zero in layout.” The same slipped decimal, he said, had also turned 2,040 brands into “204” on page seven of the PDF that I’d been sent in advance of its publication. A revised version is coming out this week. So, I got the corrected figures first.
That’s a strange way to start a column about an AI research report, admitting before anything else that the draft report had an error in it. But it’s the most honest way in, because the correction says something the study’s headline stats never could. Reading AI answers correctly, whether you’re a marketer trying to figure out if ChatGPT is recommending your product or a researcher building a study about it, comes down to catching the decimal point before you build a strategy on it.
The Funnel, Recapped
Set the typo aside for a moment and the underlying research holds up. Clovion ran 69,120 multi-turn conversations across the three assistants in 36 B2B software and fintech categories, asking an opening question like “best CRM tools?” and then a single realistic follow-up. Re-asking the same question kept 90% of the recommended list intact. Adding one ordinary buyer detail, something as plain as “for a small team,” kept only 28%. Sixty-two percent of the brands that made the first answer were gone by the second one.
I asked Hasan whether “small team” was cherry-picked to produce that drop. It wasn’t. His team also tested “for a large enterprise” and got almost identical churn, around 72% either way, against roughly 10% when the question was simply repeated. The list isn’t unstable. It’s responsive, and mostly to whether the model has decided who a brand is actually for.
That’s the part worth sitting with if you do SEO or brand strategy for a living. Being named in an AI answer is not the same thing as being trusted by it. A model that puts you in its first CRM list can still cut you the moment a buyer gets specific, and Clovion’s data says that happens most of the time, not some of the time.
The Correction Changes the Shape of the Smallest, Most-Cited Number
Here’s where the fixed decimal actually matters for how you should read this study. The old figure, 33 verified contradictions, was small enough that any per-model claim built on it was standing on thin ice. Corrected, it’s 330, and the per-model breakdown Hasan shared is far more telling than the aggregate 15% figure the draft report leads with: Claude underclaims a brand’s own features 160 times against 10 overclaims. ChatGPT underclaims 70 times and never overclaims. Gemini runs the other way, overclaiming 80 times against 30 underclaims.
Hasan’s working theory, drawn from a separate, not-yet-published Clovion study on where each model sources its answers, is that Gemini leans more heavily on marketing material and video, so it tends to credit a brand with whatever it’s hyping. Claude and ChatGPT lean more on documentation and product pages, describe the core product accurately, and hedge toward “doesn’t have it” when a newer feature isn’t well documented. If that holds up under the study Clovion hasn’t released yet, it means the direction of an AI assistant’s error about your product is a function of what kind of content you’ve put in front of it, and where that content lives.
I’ve spent more than 20 years telling clients that ranking well and being described accurately are two different problems. This is the clearest evidence I’ve seen that they’re now the same problem, playing out inside a single conversation, and that the fix depends on which assistant is doing the misdescribing.
Why Nobody Catches the Missing Zero
Frederick Vallaeys has a story in his book “The AI-Amplified Marketer” that explains exactly why a dropped decimal survives all the way to publication. An automated report once flagged “great performance” on a keyword because its cost per acquisition was running much higher than the target. Somewhere in the system, high had gotten swapped for good, when a high CPA is bad news, not good news. Anyone skimming the summary would have nodded along, because the sentence read smoothly even though its meaning had flipped.
Vallaeys ties this to research on predictive processing, the idea that fluent readers aren’t decoding every word, they’re predicting what comes next based on context and moving on. That’s how “teh” reads as “the” and a missing “not” slides right past you. As Vallaeys puts it, our mental model of the sentence overrules the text in front of us. A confident, well-formatted PDF is the easiest place in the world for that to happen, and a dropped zero in a layout file is a much smaller, much more forgivable version of the same failure.
It’s also why the fix isn’t “trust the report less.” It’s “keep a human pilot in the loop who checks the number instead of the vibe of the paragraph around it.” Thirty-three contradictions and 330 contradictions don’t just differ by a factor of ten. They support entirely different confidence levels about whether a per-model pattern is real. Two hundred four brands and 2,040 brands aren’t the same study. If Clovion hadn’t caught it, and if I hadn’t asked, the smaller, shakier numbers would have kept circulating as fact, cited by exactly the kind of trade press that’s supposed to catch this.
What Clovion Isn’t Claiming, and Why That’s the Honest Part
The report is careful to say the link between how a model perceives your fit and whether it recommends you is “a strong, consistent coupling, not a proven causal law.” I pushed Hasan on what a real causal test would look like. His answer: change one thing, a brand’s public positioning content, leave everything else alone, and see whether the models’ behavior moves relative to brands nobody touched. Clovion hasn’t run that test yet. He also conceded the more uncomfortable possibility directly, that a brand’s actual real-world positioning is probably driving both how the model describes it and whether it gets recommended, which would make positioning the real lever and the model’s “perception” just a symptom, not a cause.
That’s an unusually candid answer from a company selling AI visibility monitoring, and it’s exactly why I trust the rest of what Hasan told me. He also had no data on how fast an AI’s perception of a brand shifts after that brand changes its own content. “We didn’t do a before-and-after test,” he said. “Treat it as worth testing, not guaranteed in X weeks.” Anyone telling you they can promise a specific timeline for moving Claude’s or Gemini’s opinion of your brand is guessing, by Clovion’s own admission.
What To Actually Do About It
There are three things that you should do, based on what Hasan told me and what the corrected data supports.
First, track the whole conversation, not the first answer. If you’re monitoring AI visibility with a single-prompt check, you’re measuring the top of a funnel that loses 62% of its contents one sentence later. Build your monitoring around the follow-up questions your real buyers actually ask.
Second, fix the assistants one at a time, in order. Hasan was direct that a single content change won’t move all three models at once, because they pull from different sources. His suggested order: correct flat factual errors first, since those are cheap wins, then go after the segment-fit combinations that matter most to your pipeline, checking each assistant across several runs rather than trusting any single answer.
Third, don’t cite a stat you haven’t traced to its source, including this one. Clovion’s own report needed a correction on its most technical, most citable number. Before you build a column, a client deck, or a content brief around any AI research percentage, ask where the underlying count came from and whether anyone’s checked the math since it left the design software.
I’ve watched SEO go through a few of these moments, from Panda to mobile-first indexing to the slow bleed of zero-click search. Each one rewarded the practitioners who checked the primary source instead of repeating the headline number. AI visibility is shaping up the same way. The brands that win the disappearing act Clovion documented won’t be the ones with the best press release about their AI Overviews strategy. They’ll be the ones who read the report closely enough to ask what a “33” really meant, and who keep asking that question after this one.
Zahir Hasan is COO of Clovion AI, based in Oslo, Norway. Clovion’s corrected version of “Surviving the AI Funnel,” reflecting the figures in this column, is expected this week.
Google On Using Markdown For AI SEO via @sejournal, @martinibuster
Google’s John Mueller responded to a post on Bluesky that lamented all the effort being wasted on AI agent accessibility instead of focusing on the more productive activity of making sites accessible for humans.
Tactical SEO
One of the consistent aspects of the history of SEO is that practitioners tend to follow tactical trends if it’s apparent that everyone else is doing it. I guess it’s human nature.
Back in the early days there was a guy who built a directory and purchased enough high PageRank links to the home page to get it to about a PageRank of 7 (on a scale of 1-10). SEOs were practically pushing each other out of the way to hand this guy their money. He sold thousands of links from his directory, and nobody thought to check if any of the links actually made a ranking difference. It was easy to check, but nobody did.
The latest tactic is LLMs.txt and creating markdown pages for AI agent consumption. Cloudflare announced in February that their infrastructure can automatically create markdown files, largely as a way for developers to save LLM token consumption. Their announcement stated that OAI-SearchBot, OpenAI’s search crawler, was consuming markdown pages.
OpenAI’s official documentation explicitly positions its OAI-SearchBot as crawling websites and does not mention or recommend markdown files.
“OAI-SearchBot is for search. OAI-SearchBot is used to surface websites in search results in ChatGPT’s search features. Sites that are opted out of OAI-SearchBot will not be shown in ChatGPT search answers, though can still appear as navigational links. To help ensure your site appears in search results, we recommend allowing OAI-SearchBot in your site’s robots.txt file and allowing requests from our published IP ranges below.”
Yes, it can crawl markdown if it’s pointed to it but that’s not what it’s out there for.
“Sad truth: we are making the web accessible for AIs, not for people. Some sites now offer a text version for LLMs, but still skip real accessibility needs like proper heading structure, landmarks that screen reader users need.”
“A properly made website works well for AI agents … and search engines, and LLMs, and above all, for actual people.
If you’re trying to fix accessibility issues by making a separate “agent-friendly” version, you are just building technical debt. You’ll have to redo it multiple times. Just fix it.”
AI Agents Crawl HTML
It’s a relatively trivial thing to crawl HTML. Search engines have been doing it for over thirty years. Making sites accessible for everyone makes sense, especially since it’s user behavior signals that have always driven search engine rankings. From links to users searching with a brand name, Google has consistently used user signals for ranking purposes.
So, from the perspective of SEO, it makes a load of sense to make websites accessible for everyone.
Meanwhile, every SEO LinkedIn feed is lit up with someone either declaring markdown the future of the web or explaining why you should ignore all of it.
The truth, as per usual, sits somewhere more interesting than either camp.
The web is developing a parallel machine-readable infrastructure (MCP/WebMCP, OKF, ARD, LLMs.txt…) and SEOs who understand what each layer actually does, rather than treating it all as “AI SEO” or a silver bullet, will make better decisions about where to spend their time.
First: The Layer Cake
There are at least six distinct things being discussed under the umbrella of “making your site AI-ready.” They sit at different layers and serve different purposes:
Crawlable HTML Pages: Still the foundation. Nothing has changed here. Everything else sits on top.
Schema.org/Structured Data: Semantic hints baked into HTML that tell machines explicitly what a page is about. It is, in essence, a vocabulary.
LLMs.txt: Essentially a navigation file. Its purpose is to essentially tell an AI agent that’s already on your site which pages matter. But as John Mueller puts it on the Search Off the Record podcast:
“If someone is already on your website, maybe some kind of automated system is helpful. Where if it goes, I want to go to Martin’s Splitt and buy a photograph, then the LLM system can go to your website and can look around, like, how do you buy a photograph? Maybe he has some guidelines for me as an agent for buying photographs. That kind of makes sense.”
MCP/WebMCP: Before ARD came into play, we were presented with another solution for the challenge of interoperability. An MCP, in its simplest explanation, is a standardized way for an AI to connect to your services to extract knowledge or take action. WebMCP, as the name itself suggests, gives websites a way to engage with agents directly. WebMCP is for live browser interactions on a webpage; MCP is for tools and services beyond the page.
Open Knowledge Format (OKF): A bundle of markdown files with YAML frontmatter.
Agentic Resource Discovery (ARD): A new open spec for how agents find and verify tools, skills, and other agents across the web. Here, the focus is not your content; it’s your capabilities.
The format itself is almost disarmingly simple: a directory of markdown files, each with a small YAML header declaring a type, title, description, resource, and some tags. The files link to each other like any markdown document would. That’s it.
As Google’s own blog puts it, OKF is “just markdown, just files, just YAML frontmatter.”
SEO Suganthan Mohanadasan has a clear breakdown of this. He describes OKF as one floor in a stack that now includes sitemap.xml (which URLs exist), LLMs.txt (which pages you most want read), and OKF (the library itself). They stack rather than compete.
The confusion sets in not when you look at what OKF is, but what it does and in which layer of the agentic and search mayhem it sits.
In my mind, OKF is not a retrieval system. It doesn’t replace crawling. And, personally, I do not see a future where AI systems no longer ingest massive amounts of HTML or where search and RAG are not a multistep complex pipeline that consists of self-reported and “unbased” signals.
Any self-reported system can and will be gamed. So thinking you can just slam a bunch of markdown files on your site and be THE preferred choice in retrieval and discovery is far-fetched.
OKF is a higher-signal source among many. It may reduce parsing cost and improve signal quality, but it doesn’t replace existing pipelines.
It’s also worth being honest here: OKF was built for data teams, not marketing sites.
It arrived as a way to share internal knowledge, i.e., table schemas, runbooks, metric definitions, between AI agents inside organizations. Pointing it at a public website to me seems a bit like we are yet again repurposing.
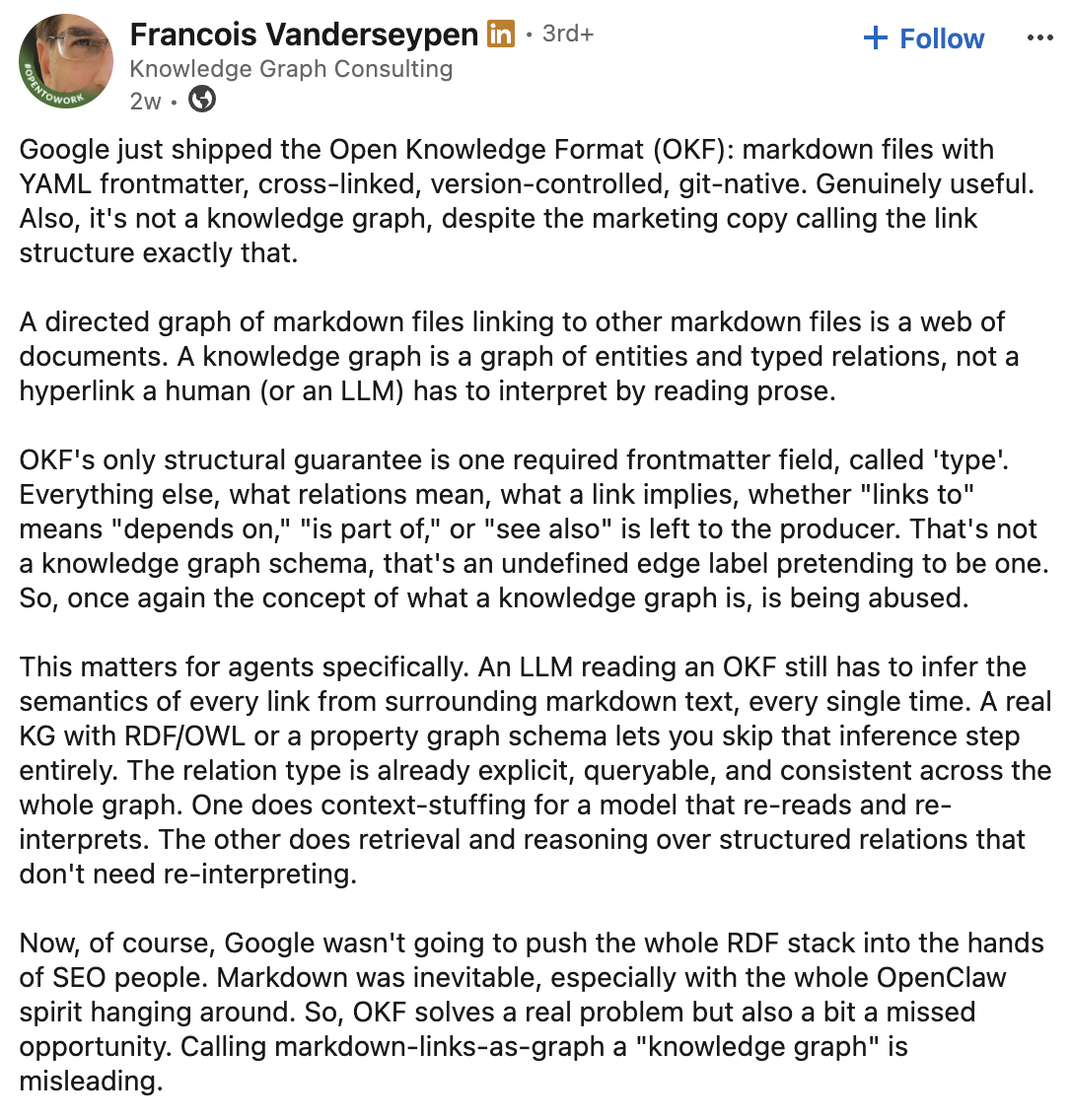
Francois Vanderseypen makes the most precise point about what OKF actually is and isn’t: a directed graph of markdown files is a web of documents, not a knowledge graph (at least not in its purest sense). A real KG has explicit, queryable, typed relations. OKF leaves what a link implies entirely up to the producer, and an LLM still has to infer the semantics every single time it reads it.
Screenshot from LinkedIn, July 2026
For me, this points to the crux of how I understand the web and what we do as SEOs. OKF doesn’t change the stack. It adds one more input into it.
It’s not a shortcut. There are no shortcuts.
The Schema.org Parallel, And Why It Matters
One of the patterns to understand here is the one Schema.org already went through.
Structured data followed a predictable arc:
Adoption – ranking boost – widespread use (and gaming) – platform learning – reduced dependency as a ranking signal.
FAQ schema had a moment in SERPs, then Google discontinued the FAQ rich result. The platforms learn from the signals, fold the lessons into the algorithm, and the explicit markup becomes less necessary.
OKF and LLMs.txt may follow the same path. They’re most valuable early, as clear signals in a world where AI systems are still learning to parse the web.
Over time, if the formats work, the systems learn. Explicit markup becomes redundant or remains a verification layer. For example, in ecommerce, in particular, schema and feed alignment has become more and more important. Another notch in the call for co-ownership of the product feed between SEO and paid teams!
There’s also a subtler point worth making here about the relationship between schema.org and discovery. Jarno van Driel’s deep dive on product variants in Search Engine Journal illustrates this well: For years, Google Search and Google Merchant Center had conflicting structured data requirements, forcing publishers to duplicate markup. Schema.org evolves to close gaps, but it’s slow, it’s complex, and implementation is still often a mess.
Structured data has never been a plug-and-play ranking lever. OKF won’t be either.
Should You Convert Your Site To Markdown?
It’s a big fat no from me. That doesn’t mean I won’t test it and apply carefully!
“When it comes to things like a search engine or probably also in generic LLM system, having a website that uses normal HTML for the pages is critical. Because a search engine or crawler can just go to that page. It can recognise all of the other links that are within the website.”
The structural information in HTML – nav links, footers, header hierarchies, internal links – is how crawlers understand your site’s shape. Markdown files strip all of that out. You’d be breaking discovery in order to marginally improve machine readability of individual pages.
Recently, on LinkedIn, I even saw a piece of research showing how “Your navigation might be eating your LLM (it’s ChatGPT Deep Research in fact) reading budget.” Interesting findings, but please don’t remove your navigation to “save some tokens”!
Screenshot from LinkedIn, July 2026
Jono Alderson makes this point brilliantly: “A page is not just a container for words. It’s an editorial artifact.” Hierarchy, emphasis, placement, what comes first, what’s prominent, what’s tucked in a footnote … these aren’t pretty decorations for humans. “They are signals about meaning.”
“When you flatten a page into markdown, you don’t just remove clutter. You remove judgment, and you remove context.” And the moment you publish a machine-only representation, you’ve created a second candidate version of reality.
The boring fix still works: Semantic HTML, clear structure, sensible hierarchy, content that exists when the page loads.
John Mueller covers the markdown debate extensively in the podcast: The parallel versions problem, the dynamic rendering lessons we already learned the hard way, and why maintaining a shadow version of your site for AI doubles your maintenance burden and creates a debugging nightmare nobody will tell you about.
The one exception Mueller carves out is developer documentation:
“If you have something like developer documentation, where, again, if the agent or the LLM system already knows about your website and the user says, how do I usethis API? Then if you give the LLM system a Markdown file, it’s a lot easier for it to understand.”
Now, I can definitely see a straightforward use case there.
What ARD Is Actually Doing
The Agentic Resource Discovery specification, announced by Google on June 17, 2026, is a different beast entirely. It arrived only a couple of days behind OKF, not a coincidence, and is already making huge waves.
The problem ARD solves is a coordination one. Right now, an agent has to be wired to each tool, MCP server, or API it uses before it can do anything with it.
That works when you’re connecting a handful of known services. It stops scaling the moment the number of available capabilities grows beyond what any team can pre-configure by hand.
ARD moves that discovery out of setup and into runtime. The agent finds what it needs when it needs it, rather than only knowing what it was told about in advance.
It’s built on two primitives:
Catalogs: An ai-catalog.json file hosted on your domain, describing your available capabilities (MCP servers, A2A agents, OpenAPI tools). Ownership of the domain acts as the cryptographic foundation for identity and trust.
Registries: Search engines for the agentic web. They crawl catalogs, index them, and return matching capabilities with the metadata needed to verify the publisher before connecting.
If OKF is about packaging knowledge for consumption, ARD is about advertising capabilities for connection.
These are parallel efforts at different layers of the emerging agentic stack. Both shipped within inches of each other and now adopted with the speed of light by some very big players in the game, i.e., Hugging Face and their Discover Tool.
It’s possibly a more pragmatic bet than the formal logic layer that came before it and never reached web scale. Time will tell.
A Gap Worth Watching
Within days of both specs shipping, a contributor opened companion issues on the ARD and OKF repos pointing out something basic was missing: There’s no agreed media type for an OKF bundle, so a catalog can list one but can’t actually recognize it as OKF without sniffing the contents.
In the meantime, publishers are already advertising bundles in production using their own interim types, which, as the issue itself notes, won’t agree with each other.
On the face of it, this looks like a small ask, just a request for a shared label.
After a bit of a dive into this particular rabbit hole, it turns out that’s quite normal practice. Waiting for full agreement before anyone ships anything is exactly how a spec dies in committee, and shipping fast and patching as real adoption surfaces is an age-old strategy.
Application/json itself wasn’t formally registered until 2006, roughly five years after JSON was already in wide, informal use. Nobody worried about that, because the cost of the label being unsettled was low: A parser might reject something or fall back ungracefully.
But OKF is different, because what happens after the fetch is different. The artifact behind the label is a bundle an autonomous agent is meant to ingest, verify, and potentially act on, inside a discovery system built specifically for agent-to-agent and agent-to-tool connection. Get the type wrong here, or leave an agent to infer it, and the risk isn’t a parse error; it’s a system acting on something it shouldn’t have trusted, with no one checking the result first.
I wonder about the risk involved in settling this later rather than sooner in this case. I guess it depends on how fast it gets resolved relative to how fast adoption runs ahead of it.
What This Means If You’re An SEO
A few honest conclusions and my current thinking:
For most marketing and content sites, not much has changed. HTML, well-structured for humans, is still the right foundation. A contact-us form and a clean site architecture will serve you better than any OKF bundle ever will. Discovery still depends on links, authority, user signals … and indexing.
LLMs.txt is a signpost, not an SEO tool. It’s useful for helping an agent navigate within your site once it’s already there. It very likely doesn’t make a big difference in how agents find you in the first place. And, probably never will.
MCP/WebMCP. Neither is urgent for most marketing sites today, but if you’re building anything with programmatic interfaces or ecommerce flows you want agents to navigate, this is the direction the infrastructure is heading.
OKF makes a lot of sense if you’re sitting on structured internal knowledge, i.e., documentation, API references, product specs … and you want to make it easier for agents to consume. The free OKF generator Suganthan built will produce a bundle and give you a graph view of your internal link structure as a side benefit. The structural audit alone seems worth it. But I will be running it on my website first, not on my client’s website.
ARD is worth watching if you’re building services with programmatic interfaces. If you have tools, agents, or APIs you want discoverable by other agents, ARD is the emerging standard for how that gets done. Just know the identity layer underneath it, what an agent is actually looking at when it finds your catalog entry, is still being settled in real time, so I’d treat this as infrastructure to watch closely rather than build critical paths on just yet.
The schema adoption cycle might repeat. These formats are most valuable now, as early signals. Implement them if you can do it cheaply. Don’t build your strategy around them holding value forever and don’t bank on them as a silver bullet.
Ultimately, be aware of the shiny things – if your company has bigger fish to fry, i.e., a terrible website, a brand no one knows or cares for, an audience you don’t understand … then deal with this first before you get caught up in any of these new shiny things.
The Underlying Shift
What all of this points to is a web that’s genuinely growing a second layer or a third head, one written for machines alongside the one written for browsers and humans.
Sitemap.xml told crawlers which URLs existed. Robots.txt told them where not to go. LLMs.txt, OKF, and ARD are similar infrastructure for agentic systems: navigation hints, content packaging, and capability discovery.
None of it is mandatory today. None of it replaces solid HTML, authoritative content, sensible structure, or the thing that actually sits underneath all of it: a brand worth finding.
But the SEOs who understand what each layer actually does, rather than treating it as a single undifferentiated “AI SEO” category, will make better bets on where to spend their time.
My money is on the second layer, a parallel infrastructure written for machines, not a replacement for what already exists.
The third head scenario, where agentic systems fully diverge from the human web, would require a different set of bets than any of us are currently making.
Big thanks to Jarno van Driel, Jono Alderson, Chris Green, Suganthan Mohanadasan, Kristine Schachinger, Gianluca Fiorelli, Victor Pan, Renee Bigelow (and anyone else I’ve missed) for some brilliant discussions on this topic over the last few weeks.
Search And Agents Are One Product. You Only Need One Playbook via @sejournal, @slobodanmanic
Google Search is becoming an agent manager. Sundar Pichai said it plainly across two interviews this spring:
“A lot of what are information-seeking queries will be agentic in Search. You’ll be completing tasks. You’ll have many threads running.”
One week later, at Google Marketing Live 2026, Nick Fox, the SVP who oversees Search, Ads, and Commerce, said the corollary:
“The way to optimize for AI search is the same way to optimize for search. Create great content.”
When the CEO describes a product direction and the SVP confirms the optimization path, treating search and agents as two separate disciplines means running two playbooks for one product.
That surface is already live. AI Mode is in the Chrome address bar. Search agentsrun in the background on queries too long for a single click. Chrome auto-browse fills forms and completes bookings on behalf of users with OS-level permissions. These are not separate products with separate optimization playbooks. They all inherit the same web.
What Pichai Actually Said
Pichai gave two interviews this spring that together draw the clearest picture of where Google Search is headed. On the Cheeky Pint podcast in April 2026, he described the trajectory: “If I fast-forward, a lot of what are just information-seeking queries will be agentic in Search. You’ll be completing tasks. You’ll have many threads running.” He called it “Search as an agent manager” and framed it as already happening in AI Mode, where users run deep research queries that do not fit the classical keyword model.
Then, on Decoder with Nilay Patel after I/O 2026, he did something more revealing. Patel showed him a live AI Overview result on his phone for “best Chromebook.” Pichai looked at it and said: “It’s probably more opinionated than it should be for the particular query you showed me.”
That admission matters more than the convergence statement. He is not pretending the product is finished. He called it scope for improvement in a fast-evolving space. In the same interview, he also said Google is committed to sending traffic to the web: “Everything we do across all, you will see us five years from now sending a lot of traffic out to the web. I think that’s the product direction we are committed to.”
Both claims sit next to each other in the same interviews. The product direction is convergence: search queries become agentic, tasks get completed inside Search, agents browse on behalf of users. The promise is continuity: traffic will still flow to websites. Hold both in your head at the same time, because that gap between the direction and the promise is where your risk lives.
Nick Fox Said The Same Thing From A Different Angle
At Google Marketing Live 2026, Nick Fox sat down with Semafor’s Ben Smith and addressed the optimization question directly. Fox is Google’s SVP of Knowledge and Information, the person who oversees Search, Ads, and Commerce. His statement: “The way to optimize for AI search is the same way to optimize for search. Create great content.”
He added one qualifier: “Go beyond the surface level.” His reasoning is that AI handles first-level responses, so the content that performs in AI search is content that goes deeper than the summary the model already produces. “If you’re looking to buy something, you don’t want to hear what the AI says. You want to hear someone that’s used it.” This is the commodity-vs-non-commodity content distinction Google has been circling for a while now: if the AI can produce the answer itself, your content needs to offer something the AI cannot.
This is also what No Hacks guest Jono Alderson has been saying for over a year. The content that AI ignores is the content that restates what the model already knows. The content that gets cited is the content that carries something the model has to retrieve because it cannot generate it: original data, first-person experience, named-entity specificity, a take the model is not confident enough to produce on its own.
When the CEO says the products are merging and the SVP says the optimization is the same, the implication lands: one strategy, not two. The separate “AEO strategy” or “GEO strategy” that consultants have been selling as a new discipline collapses when the vendor itself says it is one playbook. The r/TechSEO community arrived at the same conclusion this week when Google published its official AI optimization guide: “It’s basically just. SEO.”
What This Means For The Website You Are Building
The website that works for classical search is the same website that works for agents. Server-rendered HTML so the content is visible without JavaScript hydration. A study I published this week measured 274 fintech companies and found 36% are partially invisible to AI crawlers because they depend on JavaScript to render core content. 17% deliver zero content without JS execution. The fix is not complicated. 99% of those same websites deliver full content once rendered. The gap is the default: raw HTML first, not JS-rendered-eventually. Semantic markup so the agent knows what each element is. Structured data so the identity is machine-readable. Fast delivery so neither the crawler nor the agent times out. Internal linking so both the index and the agent can navigate the full surface.
The companies that treated agent-readiness and search optimization as the same discipline were accurate. They were not early. The vendor confirmed what the practice already showed: the audit is the same audit applied to a visitor class that now includes both humans on Google Search and agents in AI Mode. Build for one playbook: machine-readable identity, extractable content, discoverable actions, server-rendered and semantic and structured and fast and well-linked. That description fits classical search and the agentic web and the product Pichai is describing, which is both at once.
Pichai admitted the product is not finished. “More opinionated than it should be” is a refreshingly honest read of a product in motion. The gap between where AI Overviews are today and where search-as-agent-manager is going is your window. The direction is set. Build for one playbook now, and you are building for the product Google is becoming.
Google Says AI Visibility Hinges On Content People Actually Want To Read via @sejournal, @martinibuster
Google’s VP of Search, Liz Reid, sat down for an interview where she talked about the relationship between Google and publishers. When asked what the new rules are for showing up in AI search, she said that publishers need to publish content that people actually want to read.
Google Says Publisher Traffic Loss Is Not Just AI
One of the points that Reid stressed is that publisher traffic loss is not just about AI. She put part of the blame on people seeking out non-textual content. Her answer was in the context of what she would “say to publishers about the reality of this new time.”
Reid answered:
“I think to start with, there are, first of all, multiple things going on besides AI, right? One of the things that we see is that people are often going for new formats, right? They want to see videos, not just text. They’re often going to social media for content.
There was a recent study from Reuters around this, really just talking about how people are shifting, and so one of the things I would generally tell publishers is make sure you’re innovating with what users want and how they want, right?”
Google Says Publishers Must Make Content People Want To Read
The next part of her answer to the question of what publishers need to know about the “reality of this new time” is that if publishers want to be seen on AI search, they need to not make the kind of slop content that is the “1,000th copy” of everything else. She put the burden on publishers to step up and make better content that people actually want to read.
She explained:
“I think the second thing that is really important is that people, to the extent that you produce really interesting expertise content, we still see that people are interested in that, right?
…And so the more that publishers produce content that is really where they shine, what they bring to the table, that it’s unique, it’s not the 1000th copy of the same story, but it’s something that has an interesting take on it. The more I think we’ll see that people will continue to click through and read that.”
What Publishers Can Do To Be More Visible In AI
The interview hosts circled back to what publishers can do to make content more visible in AI. They tried to elicit an answer that addressed the “new direction” that AI search is headed in, noting that publishers are concerned.
They asked:
“What can, what can publishers do or creators do to make their content more visible to AI? If this is something, if this is kind of the new direction that all of this is headed, which it clearly is, and publishers are concerned about getting the right eyeballs on their content.
How can they work with the system to ensure that they’re kind of playing by the new set of rules and getting their content maximized in front of the right places at the right time?”
Liz Reid answered that the way to be seen is to make content that people want to read.
She explained:
“Yeah, I mean, I think I would probably put it in two buckets. The first is make sure we can access your content. Like if you block the content, that will not work. If it makes it hard to discover, then that’s difficult. We have various tools in webmaster console that give you controls so that publishers can choose. But making it easier for us to access is certainly the first step.
But we’ve also published an updated set of guidelines around for website owners and publishers to think about how they make great content in this day. At the heart of it is really this continuation of, if you want people to click through, then implicit in there is you want people to read your content.
That means you need to make content that people want to read, right? So the more you build the content that your audience will love, the more it will work. The more you build content that you think is just designed for the search engine, but not for the audience, then people will learn that over time.
So the more it brings in your expertise, that is sort of fresh and relevant content of what people are curious about, that it brings in that sort of experience, that detail and richness, that’s really great.”
Takeaways
Liz Reid’s comments show that Google is increasingly viewing publisher success in AI Search as dependent on two conditions:
Let Google crawl everything.
Create content that people actually want to read.
That kind of approach ignores the Google Zero fears that haunt even big-brand sites that are experiencing declines in search referrals. If the big-brand sites are having a freakout about declining search referrals, where does that leave small-brand publishers who write recipe blogs, product reviews, travel guides, advice, and news?
Google’s Spam Update Now Reaches AI Answers. Enforcement Is Hard via @sejournal, @MattGSouthern
Google started rolling out the June spam update, the second of the year. It enforces documented spam policies, and one of those policies now covers more ground than it once did.
Google’s spam rules treat attempts to “manipulate generative AI responses” in Search as a violation, and that’s one of the policies the update is enforcing.
A Cornell Tech preprint picked up by 404 Media gets at why the policy is harder to enforce than its wording implies. The community pages that AI research agents lean on can also carry third-party comments, and a comment can plant a recommendation that the author never wrote.
What Google labels spam, therefore, travels through the very retrieval that these agents rely on. And research finds that the obvious defenses all come with drawbacks.
For anyone trying to push a brand into AI-generated answers, know that the line between optimization and spam is getting redrawn.
The Stakes
SE Ranking’s tracking of AI Mode found Google increasingly pointing to its own properties, with self-citations up to roughly a fifth of AI Mode citations in its latest report.
With more citations pointing to Google and fewer to external websites, the pull to manufacture one rises accordingly.
A gray market has already begun to form, and the Cornell authors point out that marketers are busy testing ways to nudge AI-generated answers.
Businesses, meanwhile, don’t have the data they need to see what’s happening. As our earlier coverage of agentic search laid out, no dashboard tells a site whether it landed in an AI answer, got cited in a generated report, or was passed over.
The result is a violation Google can name but the site involved often can’t see.
Analysis revealed the same community pages surfacing repeatedly in those sub-queries. Inside a single topic cluster, one user-generated page turned up in as many as 48% of queries, and user-generated platforms made up 17% to 23% of every URL retrieved. Alter one of those recurring pages, and the change can ripple into the reports for a whole topic.
The authors found that roughly 13 words of planted text on a recurring page were enough to insert an attacker’s chosen entity into the finished report in 38% to 51% of sessions that retrieved the page.
Scatter the same text across a handful of pages, and the figure climbed to 42% to 62%. Even buried inside a full page, where it made up under 4% of what the agent read, the planted text still surfaced in 30% to 53% of sessions.
Three open-source research agents took the tests, STORM, Co-STORM, and OmniThink, all run in a simulation so that nothing on the live web was touched.
Where Enforcement Is Hard
Google can label AI-answer manipulation as spam and act on what it catches. Catching it is the hard part. The planted text reads like real advice, and it sits on the same pages the tools were always going to read, so telling it apart from a normal post is the main problem.
The research team looked for a defense against planted text but didn’t find one. They tried cutting user-generated sources out, screening them with a language model before use, and combing the finished report for claims that didn’t hold up.
None of the three stopped the attack without making the results worse for the user. Drop the user-generated sources, and you lose the community detail that makes AI search tools worth using.
The tools most people use sit outside that test. ChatGPT Deep Research and Gemini Deep Research run retrieval the researchers couldn’t poison without crossing an ethical line, so they only measured citation habits. Gemini leaned on user-generated content 12.1% of the time, which the authors call a hint of exposure, not a tested result. OpenAI’s tool reached for it far less.
Why This Matters For Search Professionals
The moves that can help lift a brand into AI answers are similar to the manipulation tactics Google calls “spam,” such as planting mentions across the sites these tools read. We don’t know where Google’s line falls between earning a mention and engineering one.
For ecommerce and local brands, the danger comes from the other direction.
The test cases were the ordinary things people ask, such as which service to call, which product to buy, and where to eat. A rival or a scammer can slip an unfamiliar name into those answers, right next to the legitimate options, and the brand being edged out would never know it.
For news publishers and bigger brands, the worry is trust in the answer their name lands in. A citation from an AI tool is seen as a win, but a citation only reflects what the tool pulled, not whether that page was right, and the answer can be steered by content the brand never wrote.
There’s no tidy fix to all this. AI visibility has become a surface you actively monitor, not just a channel you passively optimize for.
Looking Ahead
The authors called user-generated manipulation an open problem that no single platform can fix on its own. Reddit has flagged its long-running fight against coordinated manipulation, and Google has bolted context labels onto some Reddit-sourced material in AI Overviews. Neither one touches the retrieval concentration the paper points to.
Google hasn’t indicated how it intends to enforce generative-AI manipulation, whether through a dedicated update or through its SpamBrain system and manual reviews it relies on for most violations.
For now, the policy calls the behavior out of bounds, and vetting AI responses still rests with whoever is reading them.
Bruce Clay, One of the Founding Figures of SEO, Has Died via @sejournal, @martinibuster
Bruce Clay, one of the first generation of search engine optimization experts, has passed away. Much of the terminology that he coined and many of the concepts that he pioneered continue to be used today.
Thirty Years Of SEO
Clay was among the cohort of SEOs who were learning and applying the art of optimization in the mid-nineteen nineties. While the SEO industry itself has a history of being divided by various practices and forums they belonged to, Bruce Clay always stood apart, not really belonging to one group or another but rather as his own person.
One of the approaches to SEO he is most remembered for is the concept of siloing content. If you’re one of the SEOs who organizes content in topic silos, you have Bruce to thank for that terminology.
Bruce Clay The Person
Bruce Clay was to many people someone whose articles taught them about SEO, a person to catch up with at search conferences, and to many a friend.
Photo Of Bruce Clay And Ash Nallwalla At A Conference
Image by Brendan O’Connell
Michael Bonfils (LinkedIn profile) shared his personal experience:
“There are three people who I learned SEO from back in the mid 90s, that was Danny Sullivan, Bruce Clay and Stephen Mahaney. Each offered me viewpoints that I’d consider valid or invalid. I wouldn’t have had a career without them. Although I personally know Danny, and indirectly corresponded with Stephen, Bruce was actually my friend.
So from a career perspective, I can’t say enough about his solid determination, the care he put into his work, the sheer amount of people who he taught and those who went off to teach others. This guy was the Yoda of search. He was who us OGs relied on.
From a personal perspective, he was my friend. I’m broken hearted. He wasn’t a stranger to me, it was: “Hey Hey Michael!” and a hug. Then a laugh about either something I said to him or something he said to me. So as a friend who just lost a friend. I’m sad. May he rest in peace, legend.”
“I lost a friend. I’ve been sitting with this news, trying to figure out how to put into words what Bruce meant to me, to the people who worked with him, and to an entire industry that many people don’t realize he helped build from the ground up.”
He listed all the contributions to the search marketing community, among them having coined the phrase that is central to it:
“Bruce is credited with being the first person to use the term “search engine optimization.” Danny Sullivan himself confirmed that. Think about that for a moment. The very phrase that defines what thousands of professionals do every day — Bruce Clay coined it.”
“I first met Bruce in 2003 at an SES conference in California. When he learned it was my first time speaking at a conference, he went out of his way to introduce me to people and say hello between sessions. It was a kindness I long remembered.
To this day, when I hear the word “silos”, I think of Bruce. I bet Jill, Bill and Eric are in SEO heaven arguing with him over that one. RIP Bruce.”
For me, Bruce Clay’s innovation was to stand apart as an individual with original ideas, freely shared. I met him countless times at search conferences and our interactions were always warm and pleasant. Connecting people’s faces with names is not easy when one meets hundreds of people at search conferences, but he always seemed to remember mine over the course of twenty-plus years. He also had a knack for making people feel at the center of a conversation. There was no ego or overblown self-regard to him. He was just Bruce Clay, and if he was speaking to you, then you were the most important person in that room.
Books Authored By Clay
There are currently two physical books for sale that he has authored:
Search Engine Optimization All-in-One For Dummies
Content Marketing Strategies for Professionals: How to Use Content Marketing and SEO to Communicate with Impact, Generate Sales and Get Found by Search Engines
And he has published many digital books and guides as well:
Declaration of SEO: 6 Fundamental Truths To Live By
Google Analytics 4: What It Is and How To Get Started
Google’s Page Experience Update: A Complete Guide
SEO Siloing: How To Create a Relevant Website
The Guide to SEO for CMOs: Key Strategies for 2021
The New Link Building Manifesto: How To Earn Links That Count
Bruce Clay Will Be Missed
Many in the search marketing community are mourning his loss, but his spirit will live on in many of the approaches to SEO that remain relevant today.
A Third Of Fintech Is Invisible To AI Agents via @sejournal, @slobodanmanic
A third of the top fintech websites in the world deliver less than 80% of their homepage content in raw HTML. That is the version of the page an AI agent gets when it visits, before it decides whether to spend the compute on a full browser render. Most of them do not.
The Structure pillar of Machine-First Architecture says critical information must not depend on client-side JavaScript. Rendering independence. Until last month, this was a design principle. Now it is a number, and the number is uncomfortable.
On May 25, I measured 274 fintech homepages from the CNBC World’s Top Fintech Companies 2025 list. I made two sequential measurements on each one: a raw HTTP fetch with no JavaScript execution, and a full browser render with Playwright. The gap between the two readings is the gap an AI agent has to close on its own. 36% of these websites force it to do that work for the most important page on the property. The full study is published on Web Performance Tools.
Most AI Visibility Coverage Skips The Rendering Step
Most AI visibility coverage focuses on schema markup, structured content, brand authority signals, and optimization for AI Overviews, ChatGPT search, Perplexity citations, and Gemini’s grounding pipeline. The advice stacks up fast.
All of that assumes the agent saw your content in the first place.
Most AI crawlers do not render JavaScript. GPTBot, ClaudeBot, PerplexityBot, the AI user-agent landscape feeding the models you are trying to be cited by, they make HTTP fetches and walk away. They are not browsers. Running a real Chromium instance per page costs compute that multiplies across the millions of pages these systems want to read. So they don’t, by default. They take what comes back in the raw HTTP response and move on.
There are exceptions. Google’s crawler runs a deferred rendering pipeline for some pages. Some AI systems will render for high-value targets, or render selectively when the raw response looks empty. The pattern is not absolute. But the production default for the crawlers that feed the largest AI systems on the web today is raw HTTP fetch, no JavaScript, take what is there.
This creates a gap that users do not see. A real visitor opens your website in a browser. JavaScript runs. The page assembles in the viewport. Content loads, layout settles, the hero image arrives. The visitor sees what you built. The AI agent fetches the response before any of that happens. Whatever does not show up in the first HTML response is, for that agent, not there.
This is what the Structure pillar of Machine-First Architecture is about. Critical information must not depend on client-side JavaScript. The page must be parseable from the raw HTTP response, not from the browser-rendered view five seconds later. This is not a performance preference dressed up as architecture. It is a visibility requirement for the AI agents that now read the web on behalf of users.
Until recently, the rendering-independence requirement was an argument. You could read the spec, look at the crawler behaviors, draw the conclusion, and still disagree about how much of a problem it is in practice. There was no number you could point to.
The fintech data gives you the number.
Two Reads On The Same Page: Raw HTML, Then Browser Render
The test on each of the 274 fintech homepages was simple: two sequential measurements, run on May 25, 2026, from Portugal. The first was a raw HTTP fetch against the canonical homepage, no JavaScript executed, whatever bytes came back in the response. The second was a full browser render using Playwright 1.60.0 with Chromium 148.0.7778.96 in non-headless mode, capturing the page at five seconds post-TTFB and again at network idle. All measurements ran from Portugal on May 25, 2026, on residential broadband, viewport 1280 by 800, no network throttling.
For each website, content was extracted from the <main>, <article>, or <body> element and converted to Markdown to preserve structural elements. The raw-fetch text was measured as a percentage of the network-idle text. If the raw fetch returned 80% or more of what the browser eventually rendered, the website passed at full visibility. Between 60% and 79% was partial. Between 30% and 59% was low. Below 30% was near-zero.
Three reads on the same page, in the same session, separated by what the browser had to do to make the page complete: raw fetch, five-second render, network idle.
The interesting part of the curve is not the network-idle reading at the end. Almost every website in the sample resolves to full content by network idle. The interesting part is the raw-fetch reading at the start, because the raw fetch is the read most AI crawlers actually take.
36% Deliver Less Than 80% Of Their Content Without JavaScript
Out of 274 fintech homepages measured, 99 returned less than 80% of their final content from the raw HTTP fetch. That is the headline number. Thirty-six percent.
Inside that 99, the distribution is steep. Fifty-five websites (20% of the full sample) returned less than 30% of their content without JavaScript. Forty-seven of those websites returned zero. The HTML response carried a shell, the layout scaffolding, some inline scripts, no readable content. Whatever the homepage was meant to communicate required a JavaScript runtime to communicate it.
The 47 zero-content websites include major exchanges, well-known neobanks, large lending platforms, several public companies, and brands a person in finance would recognize without prompting. I am not going to call them out individually. Naming the websites would distract from the architectural observation underneath. Whether your homepage shows up to an AI agent at all is currently a function of decisions that nobody on the team was thinking about in those terms when they were made.
The 24 websites in the 60-to-79 partial-visibility band have a different problem. They show up to the agent, but not all the way. The agent gets a hero headline, maybe the primary navigation, maybe a value proposition. It does not get the product descriptions, the trust signals, the calls to action, the third-party logos. Whatever was decided to render on the client side is the part the agent does not see, and that part tends to be the part that was made dynamic because someone wanted it to feel interactive.
There is a recovery curve, and the recovery curve is where the story sharpens. Of the 274 websites, 273 reach 80%-plus visibility once a real browser renders the page for five seconds. Ninety-nine percent. The content exists. The websites are not broken. They are gated behind a runtime that the production AI crawlers do not pay for.
The median website in the sample takes 21 times longer to reach network idle than to return its raw HTTP fetch. Thirty-four websites (12%) do not reach network idle at all within the 30-second cap. That is a separate problem, but it points to the same root cause. The cost gap between fetching a website and reading it is widening, and the crawlers cannot keep absorbing the difference.
Stripe, Adyen, And Plaid Prove The Stack Is Not The Problem
One hundred and one websites in the sample returned 100% of their homepage content in the raw HTTP fetch. Full visibility before any JavaScript ran. The list includes Stripe, Plaid, Adyen, Marqeta, Remitly, Starling Bank, Neo Financial, Backbase, Thought Machine, and 92 others.
Fiserv returned a complete homepage in 58 milliseconds. Acorns in 76. Trustly in 89. Ledger in 100. Look at what those websites actually are. Fiserv is a payments-and-banking infrastructure company at a $60 billion scale. Acorns runs a consumer app. Ledger is a hardware-wallet vendor with a product catalog. They are using modern stacks, content management systems, regional CDNs, the works. They have decided that the content the homepage exists to communicate will be there in the raw response, and they have not let the framework choice override that decision.
This is the answer to the obvious pushback. The pushback is that a modern stack requires client-side rendering, that single-page applications are how the web is built now, that asking for server-rendered HTML is asking engineering to step back five years. The fintech sample disproves that on its own. The websites running the fastest raw responses took the rendering-independence requirement seriously when they made architectural choices, or rebuilt to take it seriously after the fact.
There are exceptions to this read inside the sample. Three websites underperformed at the five-second render window, even though they eventually completed. All three are Asian companies measured from Portugal, and the latency penalty likely accounts for the curves rather than the architecture.
The Web Performance Tools study tested homepages only, from one geographic origin, on one day, with one measurement per website. It did not measure interior pages. It did not test multiple regions. It did not test content gated behind scroll or click. The picture this dataset gives you is the homepage of the biggest fintech companies in the world, on a single day in May, fetched from Western Europe. That is a slice. A useful slice for the load-bearing question this article is about, but a slice.
The load-bearing question is whether the rendering-independence requirement holds at scale across a large, modern, well-resourced commercial cohort. The fintech sample answers it. Most of the cohort gets it right. A third gets it wrong, and the third that gets it wrong includes brands big enough that the architectural decisions almost certainly passed through several rounds of senior engineering review without anyone naming AI visibility as a constraint.
Fintech Is Where The Homepage Is The Trust Signal
Most categories can afford some of their homepage to be invisible. A consumer SaaS company can lose a hero subhead, and most of its visitors will not feel the difference. A media website can carry the masthead through schema and still rank for the topics the body covers. Fintech is not most categories.
For a fintech, the homepage is where regulated disclosures live. The licensing footnote. The deposit insurance language. The bank-partner attribution. The security certifications. The country availability matrix. The risk warning under the rate quote. These are the elements that turn a brand from “an interesting product” into “a thing I would actually put money into.” A reader scanning the homepage is looking for them. So is an AI agent answering a question about which provider to trust for a specific use case.
When 17% of the cohort returns zero content in the raw response, what disappears is the regulatory and trust layer of the brand. The agent does not see the bank partner. It does not see the deposit insurance. It does not see the security certifications. It sees a shell.
The category compounds the problem in a second way. Fintech buying decisions are research-heavy. A person opening a savings account, picking a payment processor, deciding which broker to fund, evaluating a wallet, they go through several rounds of comparison before they act. That comparison loop is the part of the funnel that has migrated into AI surfaces the fastest. Eric van Buskirk’s clickstream study of 846,000 Google sessions showed AI Mode users close their loops inside the AI 64% of the time, never clicking through.
The fintech research loop is increasingly happening inside an AI surface, and the agent doing the work for the user is choosing from a candidate set assembled out of the raw HTML it could fetch. If a fintech homepage returns zero content in the raw response, the brand never enters the candidate set the agent is choosing from. It is absent before the comparison begins.
This is what the Structure pillar of Machine-First Architecture exists for. The pillar is the upstream requirement that makes every downstream AI visibility strategy possible. Schema markup does not help when the agent cannot read the page. Citation strategy does not help when the model never saw the content to cite. Brand authority signals do not help when the homepage that carries them returns empty bytes to GPTBot. Structure is the floor. Everything else stacks on it.
The fintech sample shows the floor is broken for one in three of the biggest brands in the category. The sample is a snapshot. Tomorrow, some of those websites will be different, and some of the websites that scored well today will have drifted in the wrong direction. The 36% will move. What matters is that until last month, there was no number at all, and now the conversation about AI visibility for this category has a load-bearing measurement attached to it.
Run The Audit On Your Own Homepage
Open Chrome. Open DevTools. Hit Cmd+Shift+P on Mac or Ctrl+Shift+P on Windows. Type “Disable JavaScript” and hit enter. Reload your homepage.
What you see is what the agent sees. If your hero, your value proposition, your product description, your trust signals, your CTAs, and your regulatory disclosures are all visible, your homepage is passing the Structure pillar. If the hero is there but the body is gone, you are in the partial-visibility band, somewhere between 60% and 79% of your final content. If the page is blank or close to it, you are in the same tier as the 47 zero-content websites in the fintech sample.
This is the cheapest audit in the AI visibility category. It takes 30 seconds. No log-file analysis, no paid tools, no meeting with engineering. The result is binary enough that you do not need to argue about methodology. Either the agent can read your homepage, or it cannot.
If the audit fails, the fix paths are framework-specific but well-known. Next.js has server-side rendering and static generation, both of which return content in the raw HTTP response. Astro and SvelteKit ship server-rendered by default. React applications can be prerendered route by route using tools like Prerender.io or Cloudflare Pages’ prerendering layer, which serve a snapshot of the rendered page to crawlers without changing the runtime architecture for users. Vue and Angular have equivalent patterns.
The choice between these paths is an architecture conversation, not a content conversation. Most teams do not need to rebuild. They need to add a server-rendering layer for a specific set of routes: homepage, pricing, product pages, blog index, anything the brand depends on for first-impression or trust signals. The architectural change does not have to ripple through the entire application.
Stripe, Adyen, Plaid, Marqeta, and the 97 other websites in the 100%-raw-visibility list of the fintech sample did not pick simpler stacks. They picked architectures that respected the rendering-independence requirement and shipped the content in the raw response. The pushback that the Structure pillar requires going back to server-rendered PHP from 2009 is the wrong shape of pushback. The pillar requires the content to be there at the HTTP response layer. How you get it there is up to the stack you already have.
What This Sample Does Not Tell You
The study measured 274 homepages on one day from one origin. Interior pages were out of scope, which means a website with a good homepage and weak product pages would pass the test and still have the visibility problem on the routes that drive conversion. Geographic variation was out of scope. Per-crawler behavior was inferred from the raw-versus-render gap rather than probed directly. Content gated behind scroll or click is its own category of agent visibility failure, and the study did not test it.
A question this dataset cannot answer is whether AI crawlers will start rendering more pages as compute costs come down. They might. Some already do for high-value targets. If they all did, the entire framing of this piece changes. The 36% would still be invisible at the raw-fetch layer, but would be readable at the rendered layer, and the urgency of the rendering-independence requirement would soften. I do not think that is going to happen at scale soon, but I am watching for it.
Rendering Independence Was Always Real. Now It Has A Number
A third of the top fintech websites in the world are partially invisible to AI agents. Rendering independence is no longer a design principle to argue about. It has a number.
The agent will be back tomorrow. The crawl will be the same crawl. The HTML will be the same HTML. If your homepage does not return its content in the raw response, the agent that fetched it will be working from a shell, and the answer it gives the user who asked about your category will be assembled from the websites that did return their content.
Open DevTools. Disable JavaScript. Reload your homepage. The page that loads is the page the agent saw.