The biggest mystery of Google’s algorithm: Everything ever said about clicks, CTR and bounce rate
It’s the biggest mystery and controversy of Google’s search ranking algorithm. For a long time, the SEO community has debated: is the click-through rate (“CTR”) of search results listings a ranking factor? Or the closely related “bounce rate” and “dwell time”?
I present to you everything Google has ever said about this, along with some observations and opinions.
Clicks, CTR, bounce rate and dwell time
If you are newer to SEO, the concept of clicks or click-through rate (“CTR”) being ranking factors is simple to explain. Once a user performs a keyword search, they can then click on a listing on Google’s search results page. Google could count those clicks as a type of vote for the content in the results and lend more ranking ability to those listings that draw more clicks for the keyword in question.
Similarly, “dwell time” would be counting how long one stays on a webpage after clicking through to a page from the search results.
A “bounce” happens when one clicks through to a webpage and leaves without navigating to another page. The assumption is that if a bounce happens too rapidly, the user may have found the page’s content unsatisfactory for their query.
“Dwell time” is also how long the user may linger on the webpage before clicking elsewhere or back to the search results. All of these signals center upon the click to listings in the search results.

The mystery: Are CTR and bounce rate ranking factors?
Despite many of my colleagues believing Google’s official line about CTR or bounce rates not being ranking factors, I will confess that I have long wavered on the question, and I have often suspected it indeed could be a ranking factor. In a recent poll I took on Twitter, CTR was voted the most controversial of all ranking factors.
However, there are a lot of good reasons to believe Googlers when they tell you what does or does not influence search rankings. I have worked in information retrieval myself, and I have known and conversed with a number of official Google evangelists in person or via chats, emails, etc. – and they uniformly give great advice and all seem to be highly honest and generally good people.
But…
…there have been those moments when something rises and sticks in rankings that do not seem like it should, based on all the classic ranking factors that we know.
I have long worked in online reputation management where SEO is leveraged heavily to try to improve how a person or organization appears in search when their name is queried.
There have been these weird instances where a nasty blog post or article with few or no major external links will abruptly pop up in the rankings – and, it just stays.
In contrast, other content that has been around longer and has stronger links just cannot gain traction against the nasty-gram item.
You cannot help but notice the difference when these reputation-damaging items arise on the scene. Such pages often have scandalous and intriguing titles, while all the other pages about a subject have more normal, conservative titles.
When you search for a name, and you see some title referencing them along with the word “lawsuit”, “indictment”, “exposed”, “arrested”, “scam”, etc., you are immediately curious, and you will want to click to hear what it is all about.
I have sometimes described this as “rubbernecking on the information super-highway” because it is like how people are drawn to slow down and look when they see a terrible wreck on the road. You see the scandalous title in the search results, and the impulse is to click it.
It has often seemed like the scandalous headlines keep drawing clicks, and this activity seems to buoy the content into appearing high in the rankings on Google’s Page 1.
I have even engineered more scandalous headlines on positive pages to draw attention for a client. Once that engineered content is getting most of the attention, the original negative item starts to subside in the results. When this happens, it seems like users’ clicks are to blame.
But, is the dynamic just coincidental correlation? Or is it exactly what it appears it could be – an outcome based, in part, on quantities of relative click-through numbers?
Get the daily newsletter search marketers rely on.
Reasons to suspect Google uses CTR as a ranking factor
Beyond my anecdotal examples, there are a number of good reasons to suspect that Google could use clicks of links in the search results as a ranking factor. Here are a few:
1. Google has long tracked clicks on its links
If this is unused data, why track the clicks? I tried to recall when I first glanced at Google results’ HTML and saw that the links were being tracked. It might be sometime in the early 2000s.
What do they do with all that data? After the advent of the inclusion of search analytics in Google’s Webmaster Tools (later renamed to Google Search Console), this click data was at least used in webmaster reports.
But, it was collected by Google well before the search analytics report.
2. Google tracks clicks on ads
Click data affects rankings within the paid ads section. So, why wouldn’t they do the same in organic?
It would not be a surprise if Google used a similar method in organic that they use in paid search, because they essentially have done that with their Quality Score.
Over 15 years ago, Google rolled out its Quality Score, which affects ad rankings – and there is now ample evidence of Google using quality criteria in organic rankings.
While different parts of Google – such as keyword search versus Maps – use different ranking methods and criteria, Google sometimes cross-pollinate methods.
3. Google disclosed in 2009 that clicks on search results affect rankings under personalized search
If it is used or has been used in the past for personalized search results, it clearly can be used for regular results, too.
4. An independent researcher examined click-throughs as a ranking factor and found it to be a potentially valuable method
Dr. Thorsten Joachims examined click-throughs as a ranking factor and found it to be a potentially valuable method. Notably, he found:
- “The theoretical results are verified in a controlled experiment. It shows that the method can effectively adapt the retrieval function of a meta-search engine to a particular group of users, outperforming Google in terms of retrieval quality after only a couple of hundred training examples.”
Thus, in a limited study, it was found to be effective. Considering this, why wouldn’t Google use it? Of course, his definitions for “outperforming Google” and determining usefulness likely differ from the criteria used by Google.
5. Bing uses click-throughs and bounce rate as ranking factors
Microsoft Bing search engine confirmed that they use click-throughs and bounce rate as ranking factors. However, they mentioned caveats around it, so some other user engagement context is also used for evaluation.
Search engines certainly use different signals and methods to rank content in search results. But, it is an interesting counterpoint to rhetoric that it is “too noisy” of a signal to be useful. If one search engine can use the signal, the potential is there for another.
6. If Google convinces people that CTR is not a ranking factor, then it reduces Google search as a target for artificial click activity
This makes it seem like there could be a substantial motive to downplay and disavow click activities as ranking factors. A parallel for this is Autocomplete functionality, where users’ searches, and potentially also click activity, used to be very prone to bot manipulation.
Google has long disliked artificial activity, like automated requests made by rank-checking software, and has evolved to detect and discount such activities.
However, bot activity in search results targeting ranking improvement through artificial clicks would likely quickly become more significant than they already handle. This can potentially create a negative impact on services similar to DDoS attacks.
Despite the years and years of stating that CTR is not a ranking factor, I have seen many jobs posted over time on microtask platforms for people to perform keyword searches and click upon specific listings. The statements may not have accomplished deterrence, and Google may already be effectively discounting such manipulation attempts (or they are hopefully keeping some of that artificial activity out of Analytics data).
7. Google AI systems could potentially use CTR and Googlers would not know if or when it was impacting rankings
Three years ago, when I wrote about how Google could be using machine learning to assess quality of webpages, I strongly suggested that user interactions, such as click-through rate, could be incorporated into the machine learning models generated for a quality scoring system.
An aspect of that idea could potentially happen, depending upon how Google builds its ML systems. All potential data points about websites and webpages could be poured into the algorithm. The system could select ranking factors and weight them according to what matches up with human quality rater assessments of search results.
With such massive processing power to assess ranking factors, an algorithm could theoretically decide if CTR was or was not a useful predictor of quality for a particular type of webpage and/or website.
This could produce ranking models for many thousands of different kinds of webpage and search query combinations. In such a system, CTR might be incorporated for ranking scientific papers but not for Viagra product pages, for instance.
The mystery remains
You might think that that third point would essentially set the record straight as Google flat out stated the ranking factor for personalization. But the mystery and controversy remain as the question centers upon overall rankings in a broader sense beyond just personalized results. The controversy surrounds whether CTR is used as a core ranking signal. The blog post disclosing clicks as a personalized ranking factor was from 2009 – when personalization effects seemed a little more overt in search.
Because there is some reasonable basis for thinking Google could use CTR as a ranking factor more broadly beyond limited effect in personalization, it creates the groundwork for many SEOs to easily believe that it is indeed a major ranking factor.
Of course, one of the biggest reasons people in SEO have come to think CTR is a ranking factor is because it naturally has a high correlation with rankings.
This is the high-tech version of the age-old question: which came first – the chicken or the egg?
The links on the first page of search results have the vast majority of clicks for any given query, and on the first page of search results, the higher ranking listings typically receive more clicks than those that are lower. This makes CTR as a ranking factor seductive.
The obvious question is: Is this coincidental correlation or is it evidence of causation?
Where cause and effect are so closely intertwined, the prospect of confirmation bias is very easy – and this is why one should be extremely careful.
This leads us to what Google has said over time about CTR as a ranking factor.
Everything Google has ever said about CTR as a ranking factor
2008
Former Googler Matt Cutts commented that bounce rate was not a ranking factor, stating that it would be spammable and noisy (meaning it would contain a lot of irrelevant data that is unhelpful to ranking determinations).

2009
In a Google Search Central video, Cutts was asked, “Are title and description tags helpful to increase the organic CTR – clicks generated from organic (unpaid) search – which in turn will help in better ranking with a personalized search perspective?”
He only answered a part of the question, saying that “…so many people think about rankings, and stop right there…”, advising the person to improve their page title, URL and snippet text to help their CTR.
He avoided answering whether CTR could affect rankings. Of course, this question was specific to personalized search.
Nine months later, Bryan Horling, a Google Software Engineer, and Matthew Kulick, a Google Product Manager, disclosed that clicks on listings were used in rankings in personalized search, as I noted above.
2012
An FTC Google Probe document (regarding an antitrust evaluation) was leaked to the Wall Street Journal. It recorded a statement from Google’s former chief of search, Udi Manber, saying:
- “The ranking itself is affected by the click data. If we discover that, for a particular query, hypothetically, 80 percent of people click on Result No. 2 and only 10 percent click on Result No. 1, after a while we figure out, well, probably Result 2 is the one people want. So we’ll switch it.”
The document further reported that:
- “Testimony from Sergey Brin and Eric Schmidt confirms that click data is important for many purposes, including, most importantly, providing ‘feedback’ on whether Google’s search algorithms are offering its users high quality results.”
A bit of the context is missing in this document because the segment about rankings and click data comes directly after a missing page – it appears that all the odd pages from the document are missing.

Danny Sullivan, former Editor-in-Chief of Search Engine Land, and current Search Liaison at Google, tweeted about the leaked document’s reference to rankings being affected by click data, stating:
In the comments, he further stated, “I asked again a few months ago :) no answer.”
It seemed mysterious that Google declined to answer one way or the other, and some interpreted this to mean that they indeed did use clicks as a ranking factor.
Or, perhaps the reason was that clicks are used only in certain, limited contexts rather than broadly as an across-the-board ranking factor.
2014
Rand Fishkin performed a test by watching the ranking of one of his blog posts. He called on his social media followers to conduct searches for it and then click on the listing in the search results. The page’s listing climbed to the top ranking position. This is worth mentioning in the timeline because Googlers appear to have become irritated at Fishkin’s publicized test and the conclusions.
Fishkin acknowledged that the test did not eliminate the possibility that other ranking factors might have caused the ranking improvement, such as links produced by the social media post. But, the sequence of events showed apparently considerable correlation between the clicks and the ranking change.
A 2015 post on the topic of CTR as a ranking factor by the late Bill Slawski with feedback from Fishkin, suggested that some thresholds of clicks would need to be reached for the listing before CTR begins to play a role in rankings.
Slawski’s blog post examined a Google patent that had been recently granted that described “user feedback,” which could potentially be clicks in search results, as a ranking factor.
The patent was: “Modifying search result ranking based on a temporal element of user feedback.” Notably, the patent’s description specifically mentions factors that can affect the appearance of materials in search, such as recency and trends.
One interpretation of Fishkin’s test results could be that items like news articles and blog posts may achieve higher than typical rankings after their introduction, combined with click-through rate data, as part of Google’s freshness or recency algorithms. (Eric Enge similarly theorized this in a 2016 blog post.)
Thus, topics spiking up in popularity shortly after introduction, like blog posts and news articles, might be able to appear higher as part of Universal Search for brief periods. Such ranking ability might not last, however, and arguably might not be deemed ranking factors in the broad sense that affects keyword search rankings over the longer term.
2015
At the SMX Advanced conference, Jennifer Slegg reported that Gary Illyes from Google stated that they “see those trying to induce noise into clicks,” and for that reason, they know that using those types of clicks for ranking purposes would not be good.
This speaks directly to the idea that Google would claim not to use it to reduce the likelihood that people would attempt to manipulate the signal.
The statement here asserts that Google is already seeing artificially influenced clicks in search results and because they already see such click campaigns going on, they are not using the signal.
Illyes went on to essentially confirm the earlier 2009 disclosure that Google uses clicks in a limited way to feature previously-visited search results higher for individuals through personalization. He also stated that clicks in search results were used for evaluation, such as checking whether algorithm changes or UI changes had impacted the overall usefulness of search results.
In a Google Search Central hangout, John Mueller states that click-through rate is used to check algorithms at a high level after making changes to see if people are still finding what they’re looking for.
- “That’s something that on a very aggregated level makes sense for us to use, but on a very detailed site or page-wide level it’s a very, very noisy signal, so I don’t think that would really make sense as something kind of to use as a ranking factor there.”
While the wording of the statement seems a bit ambiguous, Mueller seems to be trying to persuade the audience that it would not make sense for Google to use the signal because it is noisy. Thus, no one should worry about it as a ranking factor.
Nearly a month later, in another hangout, Mueller refers to “CTR manipulation, dwell time manipulation,” saying, “these things may not even work,” which is, again, a little ambiguous.
But, much later in 2015, Mueller states more absolutely in regards to bounce rate:
- “So we don’t use anything from Analytics as a ranking factor in search. So from that point of view, that’s something that you can kind of skip over. We do sometimes use some information about clicks from search when it comes to analyzing algorithms. So when we try to figure out which of these algorithms are working better, which ones are causing problems, which ones are causing problems, which ones are causing improvements in the search results, that’s where we would look into that. But it’s not something that you would see on a per-site or per-page basis.”
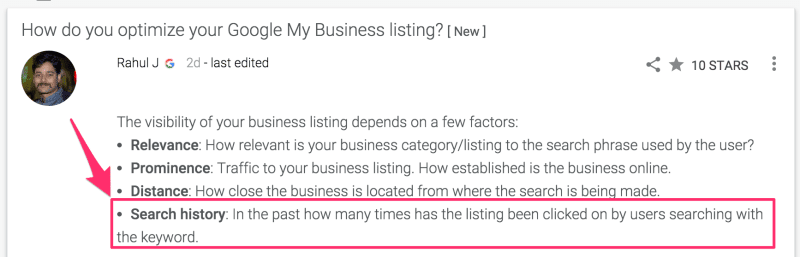
In late 2015, a Googler posted in the Google My Business help forums (Google My Business has since been renamed “Google Business Profile”) that one of the main types of factors they use for ranking local business listings is:
- “Search history: In the past how many times has the listing been clicked on by users searching with the keyword.”
Naturally, this excited some commentary and attention. Google rapidly edited the part within a couple of days of its publication to remove the mention of clicks, restating it to read:
- “Search history: The number of times it has been useful historically on the basis of relevance, prominence and distance.”
Interestingly, I was told by a Googler in the past that local listings used “listing engagement” as a ranking factor.
In Google Maps search results, or those same local listings embedded within regular keyword search results (Google pulls local search listings into the keyword search results under Universal Search for appropriate queries), the listing engagement factor is some combined metric of all interactions with local listings and not just limited to clicks on the link to the website.
It can include clicks to get Driving Directions, clicks to call the phone number, clicks to copy the address, clicks to share the listing, etc.
The Googler’s accidental disclosure of listing clicks as a ranking factor would seem to confirm what I was told about listing engagement.
As Barry Schwartz conjectured, the sequence of events implied that the Googler made a mistake about what he wrote or accidentally posted accurate information that Google does not want SEOs to know.
Google would not confirm or deny that clicks are a ranking factor. Again, while Google can and does cross-pollinate some methods from one vertical to another, the ranking factor post was very specifically about Maps and local search listings rankings and not about core rankings of webpages.
2016
At the SMX Conference in San Jose, Google engineer Paul Haar provided an overview presentation on how Google develops its search rankings.
In the slideshow presentation, two of his slides spoke about using click statistics to evaluate changes to the algorithm.
One item they look at when they test algorithm updates is “changes in click patterns,” which in the presentation included the caveat, “Harder to understand than you might expect” (which Haar did not mention verbally).
It was clear that the click data, as he described it, was only used to evaluate changes to the algorithm versus being used as core ranking signals. But, some attendees used the click references in the presentation as proof positive that Google uses CTR for rankings.

2018
Google’s Gary Illyes did an AMA on Reddit where Darth_Autocrat asked him:
- “Rank Brain: Lots of people keep saying that part of the RB system includes UX signals, including Dwell Time, Bounce Rate, Click Through Rate etc. As I understood it, RB was about trying to fathom what results to serve for unrecognised searches. Can you please confirm/deny whether RB uses UX signals of any kind?”
Illyes answered:
- “No. RankBrain is a PR-sexy machine learning ranking component that uses historical search data to predict what would a user most likely click on for a previously unseen query. It is a really cool piece of engineering that saved our butts countless times whenever traditional algos were like, e.g. “oh look a “not” in the query string! let’s ignore the hell out of it!”, but it’s generally just relying on (sometimes) months old data about what happened on the results page itself, not on the landing page. Dwell time, CTR, whatever Fishkin’s new theory is, those are generally made up crap. Search is much more simple than people think.”
Illyes displayed some clear irritation with Fishkin’s prior experiments/statements around CTR as a ranking factor in denying user experience (“UX”) signals as ranking factors.
The harsh mention directed at someone specific is very unusual in my experience with the typically polite, friendly and patient Googlers, so this denouncement attracted a lot of attention.
The vehemence, characterizing CTR as “made up crap,” and laying responsibility for CTR as a rank element theory at Fishkin’s feet seemed very oddly out of proportion – especially as you add the various other information around click-throughs-as-ranking-factors I have cited herein.
So, was Illyes’ irritation caused by having to answer questions about a bogus ranking factor repeatedly, or because Fishkin showed some real effects that called into question Google’s insistence that CTR does not affect core rankings?
2019
Moz’s then-Senior SEO Scientist Britney Muller pointed out Google Cloud documentation that implied that CTR was a ranking factor. The document said:
- “When you click a link in Google Search, Google considers your click when ranking that search result in future queries.”
However, Barry Schwartz reminded everyone that this document appeared to quote from the 2009 blog post establishing that clicks were used in personalized search.
2020
At the U.S. House of Representatives Subcommittee Antitrust Hearing examining big tech companies, Google provided very interesting text about how it uses “long clicks” versus “short clicks” in determining whether:
- Users who clicked through to ad links may have found value in the page associated with the ad.
- Changes to the search results presentation of ads may have negatively impacted the quality of paid or organic content or increased the time it takes for users to click on the search results.
The text Google provided reads:
- “Changes to the presentation of search ads are rigorously tested across a wide variety of metrics, including impact on users and advertisers. For example, a proposed change may lead to more “short clicks” (where users quickly hit the back button on their browser to return to the Google SERP) and fewer “long clicks” (where users stay on the advertiser’s landing page for a relatively long time, suggesting that they found the ad and corresponding website useful). Or, a proposed change may affect the amount of time it takes users to decide on what to click (known as “time to first click”) or adversely affect quality trade-offs between paid and organic content (known as “whole-page metrics”).”
The verbiage involving “short clicks” and “long clicks” is a description of bounce rate and dwell time for ads. The parenthetical aside about how long clicks can indicate the users found the ad and corresponding website useful seems a bit out of place within this text, which is otherwise a description of how Google assesses overall changes impacting the search results page.
What is interesting about this is that Google apparently finds bounce rate to be useful in some contexts. If useful for assessing an ad’s effectiveness, why not a search result listing?
But, it is also clear that this refers specifically to assessing the impact of overall search results presentation and/or algorithmic changes – it is not stating that it impacts rankings.
It is further notable that this is the very way that Google has stated it uses click-through data in search results – as a means of assessing the overall impact of changes to the search results.
In a Google Search Central video titled “Google and the SEO community: SEO Mythbusting,” Schwartz asked Google’s Martin Splitt about whether search engined used user data from Chrome and Android, mentioning how the Direct Hit search engine years ago had used click data for rankings and it got compromised by people clicking to manipulate the results.
Splitt responded:
- “It is very noisy as a data source. It’s so noisy… when I say, ‘no we’re not using it for ranking,’ then I mean exactly that. And we might use it for A/B testing of different ways of presenting things in the front end, or we might be using it for I don’t know what. But, people tend to only hear the bits they want to hear, and then you get misrepresented, and then we have to clean up that rather than doing other good things for the community.”
2021
An SEO professional tweeted the question to Mueller, “Is CTR a ranking factor?”
Mueller tweeted the reply:
- “If CTR were what drove search rankings, the results would be all click-bait. I don’t see that happening.”
So, what is the takeaway after reviewing some of the most prominent Google mentions about CTR as a ranking factor over time? Definitively, is it, or isn’t it a ranking factor?
There really is no mystery about click-through rate as a ranking factor
Google has been pretty consistent across time in its communications about how it uses clicks in search results. Sometimes the language is ambiguous where it should not be. Other times, they’ve been uncoordinated in messaging around the topic.
Considering the company’s large size, relatively few employees know the specifics of the ranking system. Unsurprisingly, some flubs have occurred around this.
But, a large part of the issue has been caused by some degree of semantics and miscommunications about what people mean when they discuss “ranking factors.” It seems very clear in retrospect that when Googlers say that CTR is not a ranking factor, they mean it is not a “core ranking factor” applicable to all webpages.
This reminds me of how Google Maps / Google Local personnel used to state that “review rating scores are not a ranking factor.” But after some years, they moved away from that language.
The reason is that while business rating numbers do not help rankings of listings in general, there are search interfaces where users are allowed to filter the search results based on ratings – making it a de facto ranking factor in those instances.
Unfortunately, CTR appears to be in a similar category: It actually is a ranking factor in some limited contexts.
3 instances where click-throughs are likely ranking factors in Google
1. Personalized search
Google records your historical search keywords and the results listings you clicked upon.
This history of search can cause previously visited pages to rank higher in your search results for the same keyword next time. This one is confirmed by Google.
2. Recency and trending topics
Google can temporarily enhance rankings of listings when there has been a surge in searches and clicks to specific webpages. It ought to be noted that there is some likelihood that the clicks on listings alone are likely not the only signal incorporated, however.
Google may detect an increase of mentions in social media and other sources in tandem with the item. Research has indicated that a minimum threshold of searches and clicks must be reached before the ranking enhancement occurs. Also, there is some likelihood that the ranking benefit may evaporate after a while.
3. Local search and maps
Google slipped up when they disclosed this and then “corrected” their statement. However, the revised text did not remove the possibility they use listing engagement data – since the “number of times it has been useful historically” would only be assessed through usage of the listing.
User interactions with business listings verify searcher interest after seeing the listing in the search results.
Users can click upon several potential elements in local listings, including clicking to call, getting directions, saving the listing, sharing the listing, viewing photos, and more.
Using clicks in local/maps is likely less noisy, as the interfaces may be less prone to bot activity. It may not be feasible to have cheap labor conducting the engagement activities with contextual tech factors verifying real usage.
CTR data matters
The above are cases where Google apparently uses click-through data to affect rankings. They have confirmed the first instance, which can only affect individuals’ search results.
Various research cases, such as ones conducted by Fishkin, suggest the second instance also occurs, but it is also pretty limited in scope.
It would also explain some of the content rankings I have seen anecdotally in reputation management cases involving news articles or blog posts that rank against stronger materials. This is not entirely certain, because some of these items may be ranked due more to mentions, links and references via social media.
The third instance seems highly likely due to the sequence involved with the unintentional disclosure in Google Business Profile forums. It is also supported by some anecdotal evidence and industry analysis of usage data.
Compared to the broader rankings of all webpages, these three instances where clicks are likely incorporated are practically edge cases. Technically, these ranking processes do not comprise evidence of CTR as a core ranking factor.
I believe Google’s multiple personnel have consistently been forthright over time in representing that CTR is not a core ranking factor.
They do not use it generally to determine rankings of webpages, but they do use it in aggregate to assess the impact of changes made to the search results – either changes to the user interface of the results or the overall rankings.
Google’s overall guidance on this has been pretty consistent over time in denying CTR as a core ranking factor.
Inconsistency in terminology confuses the question of CTR as a ‘ranking factor’
There has been inconsistency in definitions when talking about this. The fact that CTR affects rankings of pages under personalized search means that CTR is indeed a “ranking factor,” period, full-stop.
It is a game of semantics to say that it affects some personalized rankings, but it is not a ranking factor. Several of Google’s ranking factors are contextual or specific to particular topics or search verticals.
Google’s algorithm is also a hybrid of multiple algorithms. For instance, for local searches, some Maps listing rankings are replicated in the keyword search results. For current event topics, some News rankings get embedded in the keyword search results.
The likelihood is that ranking factors, the weighting of them, and ranking assessment algorithms are becoming more individualized by types of queries over time – and this is likely to continue.
Google has chosen not to use CTR as a core ranking factor because it is prone to manipulation through bots and cheap labor.
They have called the signal too “noisy” because of this, and perhaps also because users click in and out of pages at many speeds and for many reasons.
But, Googlers have said it was “noisy” for at least 14 years, which now seems odd.
The company that has so effectively fought webspam is unable to filter out artificial click influence?
A top black hat SEO wizard confided in me a few years ago that he had discontinued doing black hat work because it had just gotten so progressively hard that he sought a different means of income. So, Google is not an easy target for artificial manipulation. At this point, black hat SEO is unstable.
Google polices its ad clicks for exactly this type of fraudulent manipulation. So, the “noisy” excuse seems a bit worn out, doesn’t it?
However, I believe Matt Cutts, Gary Illyes, John Mueller and Martin Splitt when they say that Google does not use it as a core ranking signal.
Mueller is also believable in that Google would not want page titles to become terribly click-baity as a reaction to a disclosure that CTR could improve rankings.
The signal is “noisy,” not just due to potential artificial manipulation – it is also noisy because people click in and out of search results listings in varying patterns.
If a user clicks on five listings in the SERP before choosing one, what is the takeaway?
Google has determined that the signal is too blurry to be beneficial except in some specific cases.
Some will never be persuaded that CTR is not a core ranking factor in Google. It will always correlate to a large degree with rankings, which will be misconstrued as cause as much as effect.
But, all the former and current Googlers I have known have been honest and have given good advice. Why disbelieve so many of them?
Attempting to manipulate CTR to gain rankings is contraindicated. The three instances where CTR likely affects rankings are not terribly good targets for trying manipulation.
Where personalization is concerned, CTR only affects rankings for the person who clicked on the listing.
Where recency or trending topics are concerned, it is highly likely that other signals would need to be included in the mix, such as freshness of the content and social media buzz. The buzz and engagement would likely need to be continued to maintain the ranking, plus there could be a time limit for how long the effect lasts, too.
In the case of Local/Maps listing rankings, it will not be easy to game – can a bot request driving directions and geospatially follow them to the location? The clicks used are not isolated signals in a vacuum – there are ancillary activities that go along with them which may be assessed in conjunction with the click.
Will a bot access the listing through the mobile app or make a phone call? In general, cheap labor paid to click on search results may often be foreign, and Google detects foreign users, proxied IP addresses, and artificial usage patterns.
I think Google should probably change its standard messaging around CTR at this point. They ought to make an official document on the various ways it uses click-throughs in search results as its definitive guidance on the matter.
It may be that more transparent disclosure might reduce artificial influence attempts. Google could acknowledge that it affects personalized search and potentially contributes to recent/trending topics and Maps listings.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
New on Search Engine Land
About The Author

https://searchengineland.com/google-clicks-ctr-bounce-rate-ranking-388049