

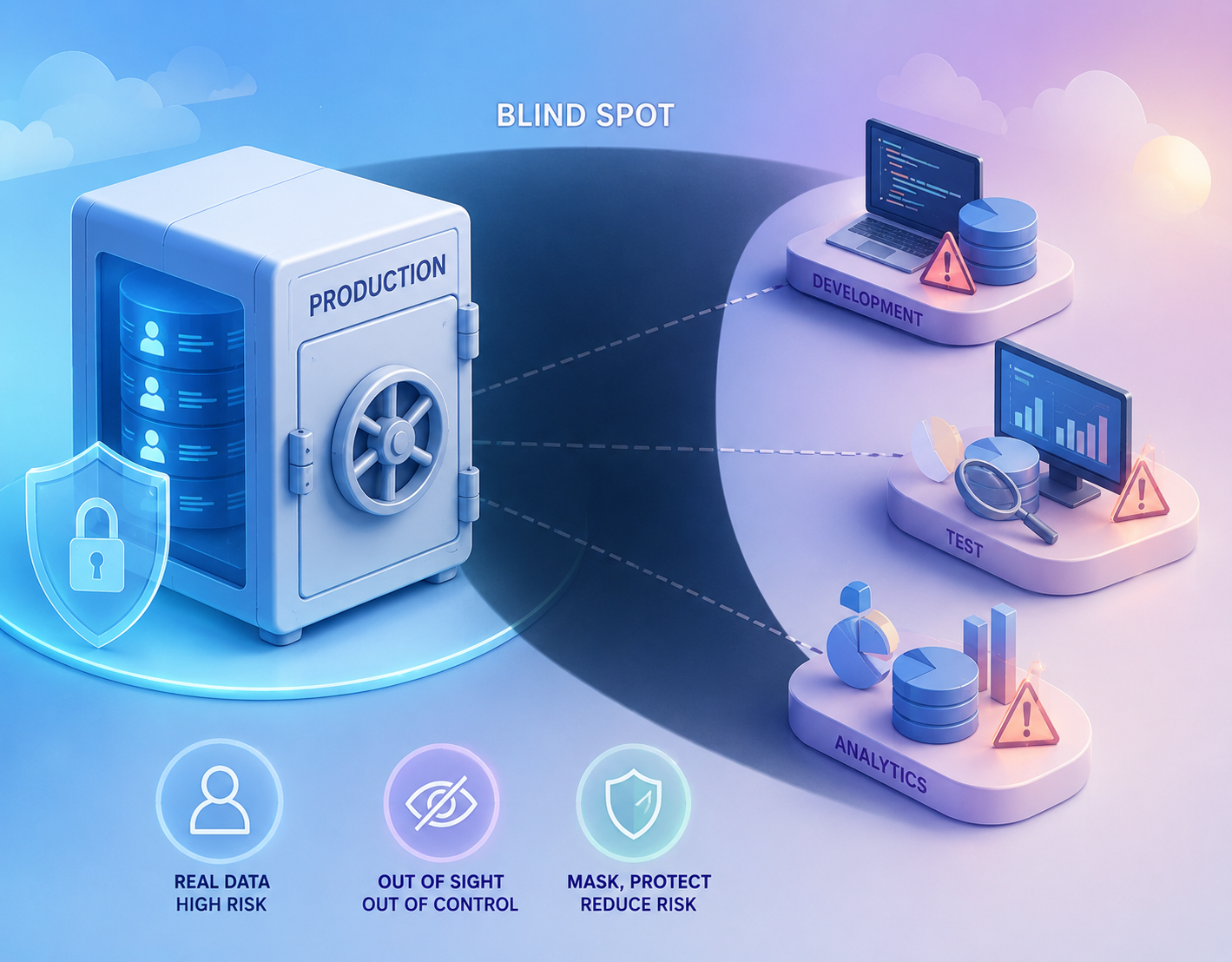
Data masking è la tecnica che affronta un rischio nascosto in piena vista: le organizzazioni proteggono con cura i dati nei sistemi di produzione, e poi ne fanno copie su copie in ambienti di sviluppo, test, formazione e analisi che nessuno sorveglia allo stesso modo. In quelle copie ci sono gli stessi dati sensibili, gli stessi nomi, gli stessi numeri di carta, gli stessi codici fiscali, ma con accessi più larghi, controlli più deboli e una vita più lunga. È un punto cieco strutturale, perché si dà per scontato che il dato sia a rischio solo dove vive in produzione, mentre ogni sua copia mal protetta è la stessa esposizione, privata però delle difese.
Il data masking interrompe questa moltiplicazione silenziosa del rischio sostituendo i valori sensibili con valori falsi ma realistici. Lo scopo è permettere a chi sviluppa, collauda o analizza di lavorare con dati credibili, che si comportano come quelli veri, senza maneggiare un solo dato reale. La differenza, per la sicurezza, è enorme: una violazione di un ambiente di test mascherato non porta via informazioni utili, perché lì dentro non c’è nulla di autentico da rubare.
Il pericolo che si copia da solo
Vale la pena soffermarsi su quanto sia sottovalutato questo fronte. Un database di produzione è di solito presidiato: accessi ristretti, monitoraggio, cifratura, audit. Ma quello stesso database viene clonato di continuo per dare ai team materiale su cui lavorare, e ogni clone eredita i dati sensibili senza ereditare le protezioni. Gli ambienti non di produzione si moltiplicano, restano attivi a lungo, sono accessibili a più persone, e quasi mai ricevono la stessa attenzione di sicurezza della produzione. Sono, in pratica, lo stesso forziere con le porte spalancate.
Il problema non è teorico, anche se l’esempio più citato va preso per quello che è. Uno scenario descritto dalla letteratura di settore, costruito a fini illustrativi, racconta una piattaforma di commercio elettronico europea con sette ambienti non di produzione, tra sviluppo, collaudo, staging e formazione, ciascuno con una copia completa del database; un audit di conformità vi individua dati personali non mascherati in tutti, per circa 4,2 milioni di record cliente. Costruito o reale, è lo schema tipico: nessuno aveva deciso di esporre quei dati, semplicemente erano stati copiati per comodità operativa e dimenticati. Per questo il data masking si lega tanto alle pratiche di protezione del dato quanto al modo in cui le pipeline DevSecOps costruiscono e alimentano gli ambienti di lavoro.
Sostituire con il falso realistico
Il cuore della tecnica è la sostituzione: ogni valore sensibile viene rimpiazzato con uno fittizio che ne conserva le caratteristiche utili. Un nome diventa un altro nome plausibile, una data di nascita un’altra data coerente, un codice una sequenza valida nel formato ma priva di corrispondenza reale. Le modalità sono diverse, dalla sostituzione con valori da dizionari, al rimescolamento dei valori esistenti tra i record, alla variazione controllata di numeri e date. L’obiettivo comune è che il dato resti realistico e strutturalmente corretto, perché un test o un’analisi su dati assurdi non servono a nulla, ma che non contenga più nulla di vero.
La proprietà decisiva, almeno nella forma destinata agli ambienti non di produzione, è l’irreversibilità. Un dato mascherato bene non si può riportare all’originale: non c’è una chiave come nella cifratura, non c’è un archivio di corrispondenze come nella tokenizzazione. È proprio questa assenza di una via di ritorno a far sì che, agli occhi delle norme sulla protezione dei dati, un’informazione mascherata correttamente sia trattata come anonima, e quindi esca dal perimetro della maggior parte degli obblighi. Qui sta la differenza con la cifratura e la tokenizzazione, entrambe reversibili per chi ha la chiave o il vault: per i dati di test, non poter tornare indietro non è un limite, è il punto. Va riconosciuto che alcune tassonomie elencano la cifratura tra le tecniche di mascheramento; in questo articolo la si tiene distinta proprio in base alla reversibilità, che è la proprietà rilevante quando si parla di ambienti non di produzione.
Data masking statico e dinamico: due scopi diversi
Sotto lo stesso nome convivono due approcci che rispondono a problemi diversi. Il mascheramento statico produce una copia permanentemente mascherata dei dati, da usare al posto dell’originale negli ambienti non di produzione: è la risposta al rischio dei cloni di sviluppo e test, perché quei cloni, da quel momento, non contengono dati reali. Il mascheramento dinamico, invece, non altera i dati memorizzati, ma li nasconde al volo nel momento dell’accesso, in base a chi sta guardando: un operatore dell’assistenza vede solo le ultime cifre di una carta, mentre il dato completo resta intatto sotto, accessibile solo a chi ne ha diritto.
Sono due strumenti per due esigenze. Lo statico serve a fare in modo che il dato reale non finisca dove non deve stare, cioè nei tanti ambienti secondari. Il dinamico serve a limitare ciò che gli utenti vedono in produzione, come una forma di controllo degli accessi applicata al singolo campo. Confonderli, o pensare che uno copra il bisogno dell’altro, porta a lasciare scoperto proprio il fronte che si credeva protetto.
L’insidia tecnica: l’integrità referenziale
C’è un dettaglio che separa un mascheramento utile da uno che rende i dati inservibili, ed è l’integrità referenziale. Lo stesso dato mascherato deve restare coerente in tutte le tabelle e i sistemi che vi fanno riferimento: se un identificativo cliente viene sostituito con un certo valore, quel valore deve essere lo stesso negli ordini, nei pagamenti, nelle spedizioni. Se il mascheramento procede campo per campo senza questa coerenza, le relazioni tra i dati si spezzano, le interrogazioni che le attraversano falliscono, e il database mascherato smette di comportarsi come quello vero, vanificando lo scopo per cui lo si è creato. È la parte difficile della disciplina, quella che distingue uno strumento serio da una semplice cancellatura, e che richiede di mascherare i dati in modo consistente, non isolato.
Mascherare bene, non solo mascherare
Resta un’ultima avvertenza, perché il data masking dà sicurezza solo se fatto con rigore. Un mascheramento debole può essere annullato: se restano abbastanza elementi originali o abbastanza regolarità, i dati si possono re-identificare, ricollegando i valori finti alle persone reali. La distinzione che le norme sulla privacy tracciano tra anonimizzazione, irreversibile e fuori perimetro, e pseudonimizzazione, che resta dato personale perché in qualche modo riconducibile, passa esattamente di qui. Un mascheramento che lascia una porta sul retro offre una falsa tranquillità, e lo stesso riconoscimento del mascheramento come misura di sicurezza in standard come la ISO 27001 presuppone che sia robusto, non cosmetico. La verifica della non re-identificabilità è parte del lavoro, non un dettaglio.
In definitiva, il data masking risponde a una verità che la sicurezza tende a rimuovere: il dato non è a rischio solo dove lo si custodisce con attenzione, ma in ogni copia che se ne lascia in giro. E le copie, negli ambienti di sviluppo, test e analisi, sono quasi sempre molte più di quante si pensi. Mascherare significa permettere a tutta l’organizzazione di lavorare con dati realistici senza detenere nulla di reale fuori dal luogo che davvero lo protegge. È la stessa logica della tokenizzazione, non perdere ciò che non si possiede, applicata però alla proliferazione invisibile dei dati fuori produzione, ed è uno dei modi più concreti, e più trascurati, per ridurre la superficie di un’eventuale violazione.
https://www.ictsecuritymagazine.com/cyber-security/data-masking-dati-produzione/
