


On Thursday, the research publisher Science announced that all of its journals will begin using commercial software that automates the process of detecting improperly manipulated images. The move comes many years into our awareness that the transition to digital data and publishing has made it comically easy to commit research fraud by altering images.
While the move is a significant first step, it’s important to recognize the software’s limitations. While it will catch some of the most egregious cases of image manipulation, enterprising fraudsters can easily avoid being caught if they know how the software operates. Which, unfortunately, we feel compelled to describe (and, to be fair, the company that has developed the software does so on its website).
Fantastic fraud and how to catch it
Much of the image-based fraud we’ve seen arises from a dilemma faced by many scientists: It’s not a problem to run experiments, but the data they generate often isn’t the data you want. Maybe only the controls work, or maybe the experiments produce data that is indistinguishable from controls. For the unethical, this doesn’t pose a problem since nobody other than you knows what images come from which samples. It’s relatively simple to present images of real data as something they’re not.
To make this concrete, we can look at data from a procedure called a western blot, which uses antibodies to identify specific proteins from a complex mixture that has been separated according to protein size. Typical western blot data looks like the image at right, with the darkness of the bands representing proteins that are present at different levels in different conditions.
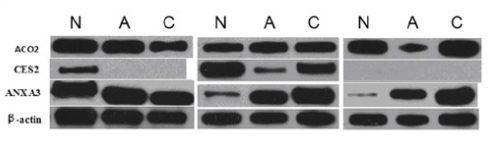
Note that the bands are relatively featureless and are cropped out of larger images of the raw data, divorcing them from their original context. It’s possible to take bands from one experiment and splice them into an image of a different experiment entirely, fraudulently generating “evidence” where none exists. Similar things can be done with graphs, photographs of cells, and so on.
Since data is hard to come by and fraudsters are often lazy, in many cases, the original and fraudulent images are both derived from data used for the same paper. To hide their tracks, unethical researchers will often rotate, magnify, crop, or change the brightness/contrast of images and use them more than once in the same paper.
Not everyone is quite that lazy. But this image recycling is remarkably common and perhaps the most frustrating form of research fraud. All the evidence is in the paper, and it is usually easy to see once it’s pointed out. But it can be remarkably difficult to spot in the first place.
That “spot in the first place” challenge is why Science is turning to a service called Proofig to make it easier to spot problems.
https://arstechnica.com/?p=1993687