


{kind=link}
SANTA BARBARA, California—Early this autumn, a paper leaked on a NASA site indicating Google engineers had built and tested hardware that achieved what’s termed “quantum supremacy,” completing calculations that would be impossible on a traditional computer. The paper was quickly pulled offline, and Google remained silent, leaving the rest of us to speculate about their plans for this device and any follow-ons the company might be preparing.
That speculation ended today, as Google released the final version of the paper that had leaked. But perhaps more significantly, the company invited the press to its quantum computing lab, talked about its plans, and gave us time to chat with the researchers behind the work.
The supremacy result
“I’m not going to bother explaining the quantum supremacy paper—if you were invited to come here, you probably all read the leaked paper,” quipped Hartmut Neven, the head of Google’s Quantum AI lab. But he found it hard to resist the topic entirely, and the other people who talked with reporters were more than happy to expand on Neven’s discussion.
Google’s Sergio Boixo explained the experiment in detail, describing how a random source was used to configure the gates among the qubits, after which a measurement of the system’s output was made. The process was then repeated a few million times in succession. While on a normal computer the output would be the same given the same starting configuration, qubits can have values that make their measured output probabilistic, meaning that the result of any one measurement can’t be predicted. With enough measurements, however, it’s possible to get the probability distribution.
Calculating that distribution is possible on a classical computer for a small number of qubits. But as the total number of qubits goes up, it becomes impossible to do so within the lifetime of existing supercomputing hardware. In essence, Google was asking a quantum computer to tell it what a quantum computer would do in a situation that’s difficult for a traditional computer to predict.
(And doing so with a computer that has a high error rate. When asked, however, Google engineers indicated that errors would alter the probability distribution in a way they could detect when run with a moderate number of qubits).
Google staff admitted that it was a problem specifically chosen because quantum computers can produce results even if they have a high error rate. But, as researcher Julian Kelly put it, “if you can’t beat the world’s best classical computer on a contrived problem, you’re never going to beat it on something useful.” Boixo highlighted that this problem provided a useful test, showing that the error rate remained a simple linear extrapolation of the errors involved in setting and reading pairs of qubits.
This seemingly indicates that there’s no additional fragility caused by the increasing complexity of the system. While this had been shown before for smaller collections of qubits, Google’s hardware increases the limits on earlier measurements by a factor of 1013.
Google and its hardware
None of that, however, explains how Google ended up with a quantum computing research project to begin with. According to various people, the work was an outgrowth of academic research going on at nearby University of California, Santa Barbara. A number of the Google staff retain academic positions there and have grad students that work on the projects at Google. This relationship was initiated by Google, which started looking into the prospect of doing its own work on quantum computing at about the same time the academics were looking for ways to expand beyond the work that traditionally took place at universities.
Google’s interest was spurred by its AI efforts. There are a number of potential applications of quantum computing in AI, and the company had already experimented a bit on a D-Wave quantum annealer. But gate-based quantum computers hadn’t matured enough to run much more than demonstrations. So, the company decided to build its own. To do so, it turned to superconducting qubits called transmon—the same choice that others in the field, like IBM, have made.
The hardware itself is a capacitor linked to a superconducting Josephson junction, in which a bunch of electrons behaves as if it were a single quantum object. Each qubit behaves like an oscillator, with its two possible output values corresponding to still or in motion. The hardware is quite large, which makes it relatively easy to control—you can bring wires right up next to it, which is something you can’t do to individual electrons.
Google has its own fabs, and the company makes the wiring and qubits on separate chips before combining them. But the challenges don’t end there. The chip’s packaging plays a role in shielding it from the environment, and it brings the control and readout signals in from external hardware—Google’s Jimmy Chen noted that the packaging is so important that a member of that team was given the honor of being first author on the supremacy paper.
The control and readout wires consist of a superconducting niobium-titanium alloy, which constitutes one of the most expensive individual parts of the whole assembly, according to Pedram Roushan. And that connects it to external control hardware, with five wires required for every two qubits. (That wiring requirement is starting to create problems, as we’ll get to later.)
-
The external hardware needed to control the qubits is pretty substantial.John Timmer
-
This being Google, they’ve made a Web interface to control the qubits.John Timmer
-
The control software generates specific waveforms to set the hardware in the desired state.John Timmer
-
The oscilloscope shows the actual pulses generated by the hardware beneath it.John Timmer
-
From there, the signals are sent into the cooling system that contains the quantum processor.John Timmer
-
A view of what’s behind that steel drum. Most of what you see is either wiring to feed signals to the processor, or refrigeration equipment.John Timmer
-
Google has at least a half-dozen slots for its processors, though not all were currently active.John Timmer
-
A close up of the processor that has caused all the fuss.
-
A view of several generations of quantum chips of increasing size, with a pen for scale.John Timmer
-
One of the superconducting signal amplifiers.John Timmer
-
Google is also designing its own superconducting signal amplifiers.John Timmer
The external control hardware for quantum computers is rather extensive. As Google’s Evan Jeffrey described it, traditional processors contain circuitry that help control the processor’s behavior in response to external inputs that are relatively sparse. That’s not true for quantum processors—every aspect of their control has to be provided from external sources. Currently, Google’s setup loads up all the control instructions into external hardware that’s extremely low latency and then executes it multiple times. Even so, Jeffrey told Ars, as the complexity of the instructions has risen with the number of qubits, the amount of time the qubits spend idle has climbed from 1% to 5%.
Chen also described how simply putting the hardware together isn’t the end of the challenge. While the individual qubits are designed to be identical, small flaws or impurities and the local environment can all alter the behavior of individual qubits. As a result, each qubit has its own frequency and error rate, and those have to be determined before a given chip can be used. Chen is working on automating this calibration process, which currently takes a day or so.
What’s coming, hardware-wise
The processor that handled the quantum supremacy experiment is based on a hardware design called Sycamore, and it has 53 qubits (due to one non-functional device in a planned array of 54). That’s actually a step down from the company’s earlier Bristlecone design, which had 72 qubits. But Sycamore has more connections among its qubits, and that better fits with Google’s long-term design goals.
Google refers to the design goal as “surface code,” and its focus is on enabling fault-tolerant, error-correcting quantum computing. Surface code, as Google’s Marissa Giustina described it, requires nearest-neighbor coupling, and the Sycamore design lays out its qubits in a square grid. Everything but the edge qubits have connections to their four neighbors.
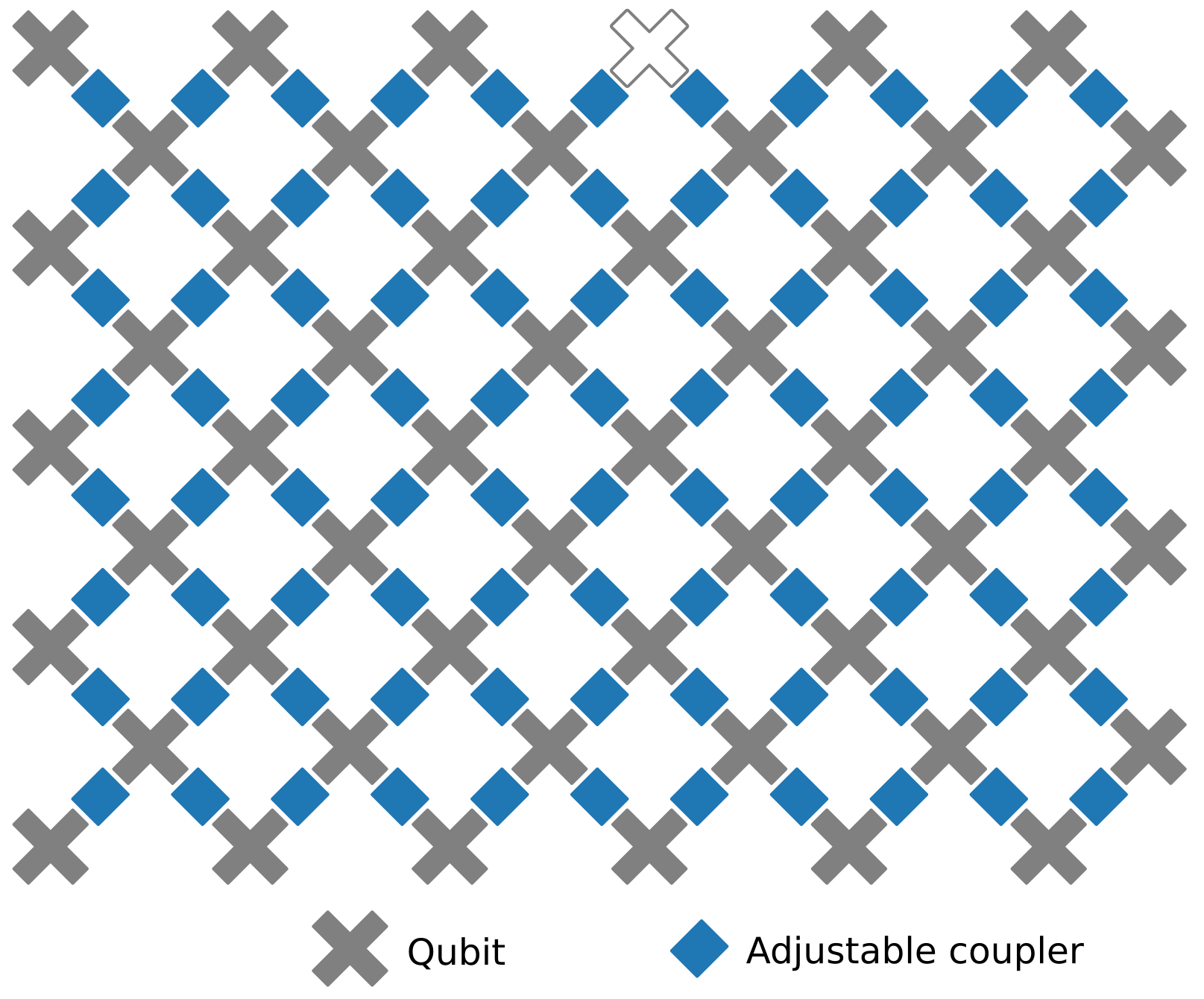
But the layout isn’t the only issue that stands between Google and error-correcting qubits. Google Hardware Lead John Martinis said that you also need two-qubit operations to have an error rate of about 0.1% before error correction is realistically possible. Right now, that figure stands at roughly 0.3%. The team is confident it can be brought down, but they’re not there yet.
Another issue is wiring. Error correction requires multiple qubits to act as a single logical qubit, which means a lot more control wires for each logical qubit in use. And, right now, that wiring is physically large compared to the chip itself. That will absolutely have to change to add significant numbers of additional qubits to the chips, and Google knows it. The wiring problem “is boring—it’s not a very exciting thing,” quipped Martinis. “But it’s so important that I’ve been working on it.”

Error correction also requires a fundamental change in the control hardware and software. At the moment, controlling the chip generally involves sending a series of operations, then reading out the results. But error corrections require more of a conversation, with constant sampling of the qubit state and corrective commands issued when needed. For this to work, Jeffrey noted, you’re going to really need to bring latency down.
Overall, the future of Google’s hardware was best summed up by Kelly, who said, “lots of things will have to change, and we’re aware of that.” Martinis said that, as they did when moving away from the Bristlecone design, they’re not afraid to scrap something that’s currently successful: “We go to conferences and pay attention, and we’re willing to pivot if we find we need to.”
Listing image by Google
https://arstechnica.com/?p=1590815