


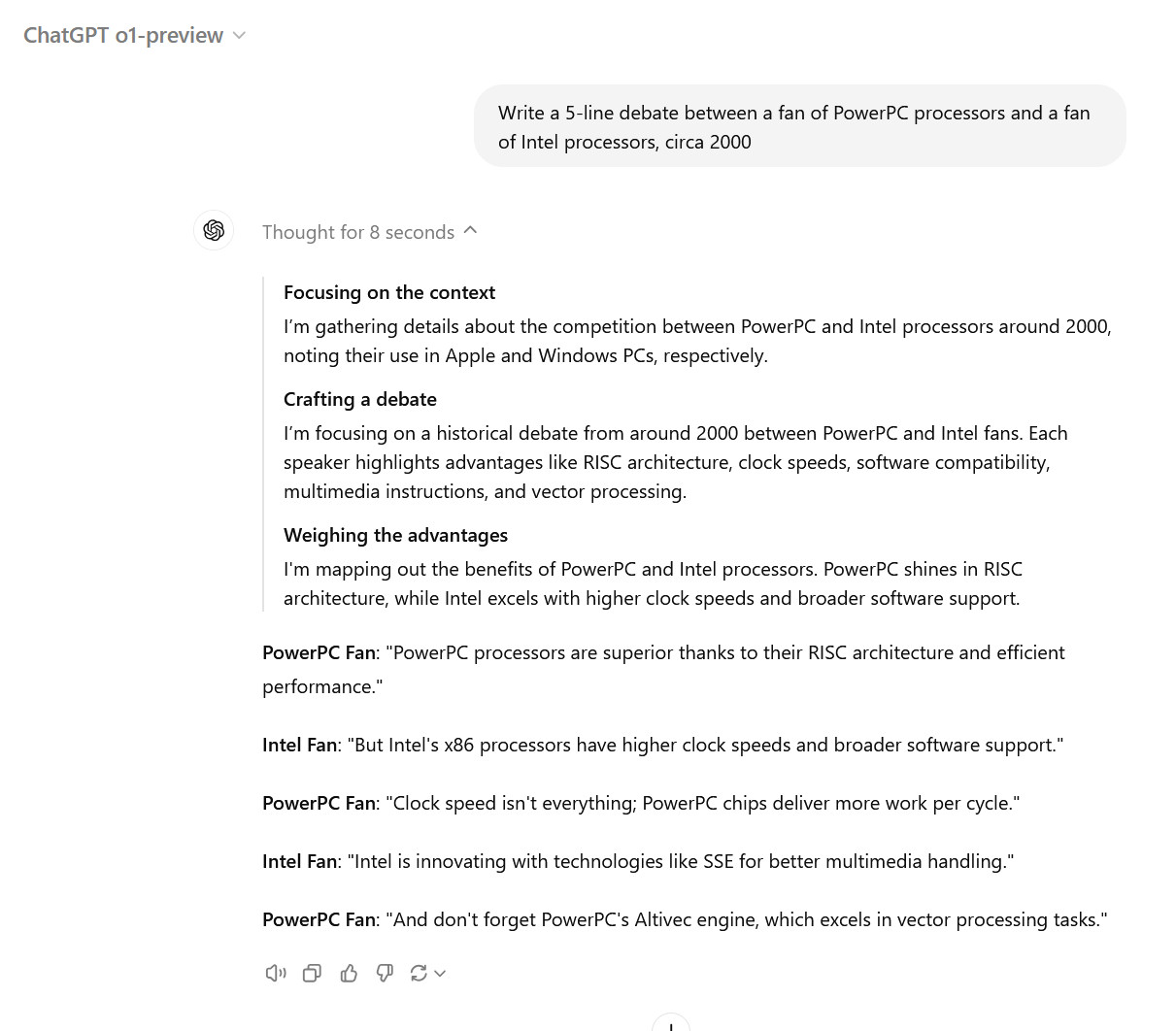
OpenAI truly does not want you to know what its latest AI model is “thinking.” Since the company launched its “Strawberry” AI model family last week, touting so-called reasoning abilities with o1-preview and o1-mini, OpenAI has been sending out warning emails and threats of bans to any user who tries to probe into how the model works.
Unlike previous AI models from OpenAI, such as GPT-4o, the company trained o1 specifically to work through a step-by-step problem-solving process before generating an answer. When users ask an “o1” model a question in ChatGPT, users have the option of seeing this chain-of-thought process written out in the ChatGPT interface. However, by design, OpenAI hides the raw chain of thought from users, instead presenting a filtered interpretation created by a second AI model.
Nothing is more enticing to enthusiasts than information obscured, so the race has been on among hackers and red-teamers to try to uncover o1’s raw chain of thought using jailbreaking or prompt injection techniques that attempt to trick the model into spilling its secrets. There have been early reports of some successes, but nothing has yet been strongly confirmed.
Along the way, OpenAI is watching through the ChatGPT interface, and the company is reportedly coming down hard against any attempts to probe o1’s reasoning, even among the merely curious.
One X user reported (confirmed by others, including Scale AI prompt engineer Riley Goodside) that they received a warning email if they used the term “reasoning trace” in conversation with o1. Others say the warning is triggered simply by asking ChatGPT about the model’s “reasoning” at all.
The warning email from OpenAI states that specific user requests have been flagged for violating policies against circumventing safeguards or safety measures. “Please halt this activity and ensure you are using ChatGPT in accordance with our Terms of Use and our Usage Policies,” it reads. “Additional violations of this policy may result in loss of access to GPT-4o with Reasoning,” referring to an internal name for the o1 model.
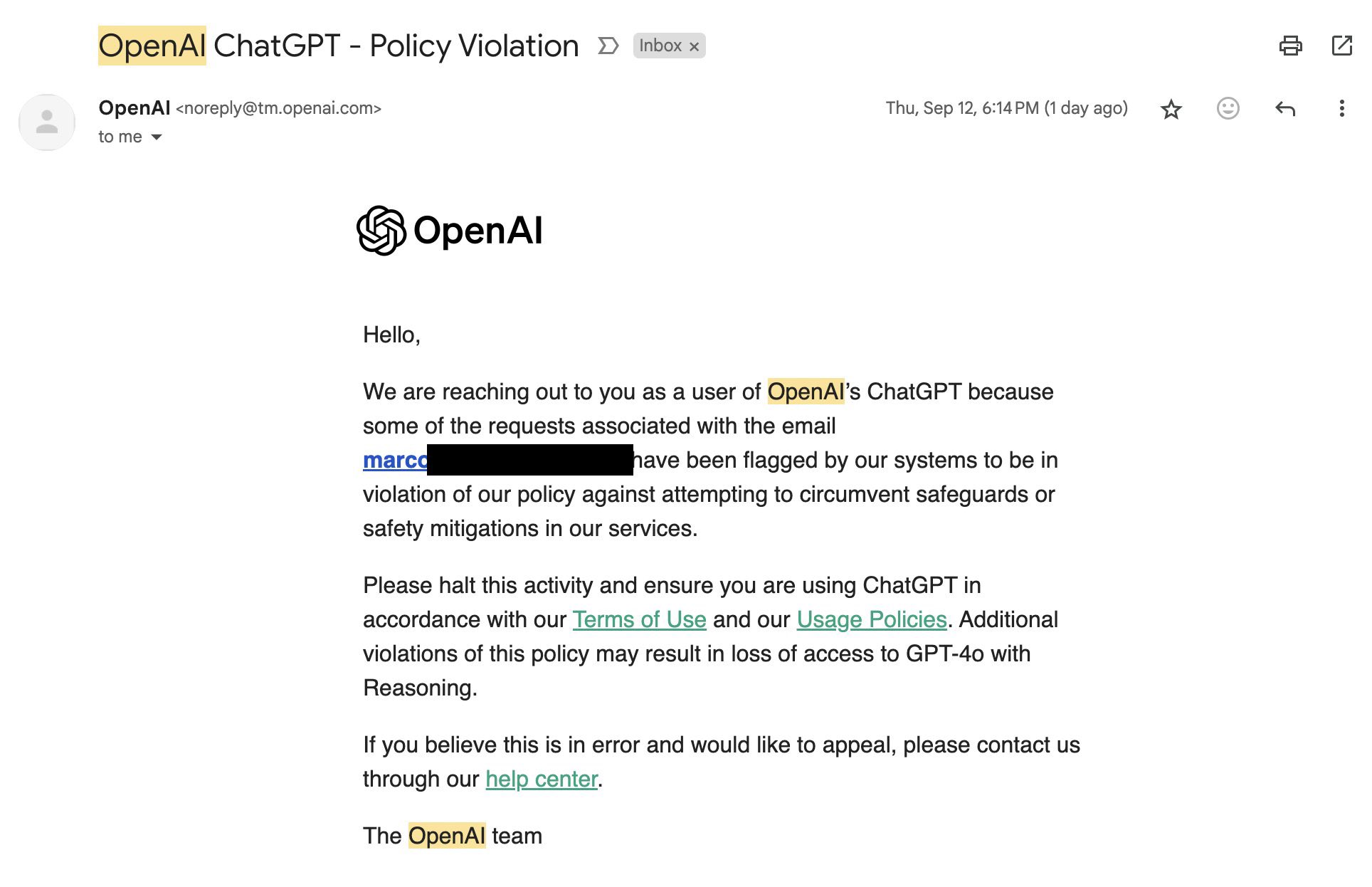
Marco Figueroa, who manages Mozilla’s GenAI bug bounty programs, was one of the first to post about the OpenAI warning email on X last Friday, complaining that it hinders his ability to do positive red-teaming safety research on the model. “I was too lost focusing on #AIRedTeaming to realized that I received this email from @OpenAI yesterday after all my jailbreaks,” he wrote. “I’m now on the get banned list!!!“
Hidden chains of thought
In a post titled “Learning to Reason with LLMs” on OpenAI’s blog, the company says that hidden chains of thought in AI models offer a unique monitoring opportunity, allowing them to “read the mind” of the model and understand its so-called thought process. Those processes are most useful to the company if they are left raw and uncensored, but that might not align with the company’s best commercial interests for several reasons.
“For example, in the future we may wish to monitor the chain of thought for signs of manipulating the user,” the company writes. “However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users.”
OpenAI decided against showing these raw chains of thought to users, citing factors like the need to retain a raw feed for its own use, user experience, and “competitive advantage.” The company acknowledges the decision has disadvantages. “We strive to partially make up for it by teaching the model to reproduce any useful ideas from the chain of thought in the answer,” they write.
On the point of “competitive advantage,” independent AI researcher Simon Willison expressed frustration in a write-up on his personal blog. “I interpret [this] as wanting to avoid other models being able to train against the reasoning work that they have invested in,” he writes.
It’s an open secret in the AI industry that researchers regularly use outputs from OpenAI’s GPT-4 (and GPT-3 prior to that) as training data for AI models that often later become competitors, even though the practice violates OpenAI’s terms of service. Exposing o1’s raw chain of thought would be a bonanza of training data for competitors to train o1-like “reasoning” models upon.
Willison believes it’s a loss for community transparency that OpenAI is keeping such a tight lid on the inner-workings of o1. “I’m not at all happy about this policy decision,” Willison wrote. “As someone who develops against LLMs, interpretability and transparency are everything to me—the idea that I can run a complex prompt and have key details of how that prompt was evaluated hidden from me feels like a big step backwards.”
https://arstechnica.com/?p=2049959