

-
Intel’s focus on AI architecture is so deep that the actual SKU table seemed like little more than an afterthought. Also notice no prices are available.
-
This is the only place you’ll see general-purpose workload performance claims—against five-year-old Intel-only systems, and ignoring Spectre/Meltdown mitigations.
-
There’s no mention of AMD on this or any other slide. Intel would actually dominate AMD on this slide if it were shown, since Epyc doesn’t offer AVX-512 optimization.
-
Ice Lake in the data center later this year should be an interesting launch—though somewhat limited by the lower socket count.
Intel today announced its third-generation Xeon Scalable (meaning Gold and Platinum) processors, along with new generations of its Optane persistent memory (read: extremely low-latency, high-endurance SSD) and Stratix AI FPGA products.
The fact that AMD is currently beating Intel on just about every conceivable performance metric except hardware-accelerated AI isn’t news at this point. It’s clearly not news to Intel, either, since the company made no claims whatsoever about Xeon Scalable’s performance versus competing Epyc Rome processors. More interestingly, Intel hardly mentioned general-purpose computing workloads at all.
Finding an explanation of the only non-AI generation-on-generation improvement shown needed jumping through multiple footnotes. With sufficient determination, we eventually discovered that the “1.9X average performance gain” mentioned on the overview slide refers to “estimated or simulated” SPECrate 2017 benchmarks comparing a four-socket Platinum 8380H system to a five-year-old, four-socket E7-8890 v3.
-
Who doesn’t like a good cat pic? These images of a kitten stored in INT8, BF16, and FP32 data types give a good overview of the accuracy levels of each.
-
These case studies demonstrate both inference and training acceleration offered by the new BF16 datatype. Note the fine print—which boils down to “we ignored Meltdown/Spectre to get big numbers.”
-
If you weren’t satisfied with a kitten pic, you can play a cheesy and theoretically BF16-releated game. It’s just as much fun as it sounds like.
To be fair, Intel does seem to have introduced some unusually impressive innovations in the AI space. “Deep Learning Boost,” which formerly was just branding for the AVX-512 instruction set, now encompasses an entirely new 16-bit floating point data type as well.
With earlier generations of Xeon Scalable, Intel pioneered and pushed heavily for using 8-bit integer—INT8—inference processing with its OpenVINO library. For inference workloads, Intel argued that the lower accuracy of INT8 was acceptable in most cases, while offering extreme acceleration of the inference pipeline. For training, however, most applications still needed the greater accuracy of FP32 32-bit floating point processing.
The new generation adds 16-bit floating point processor support, which Intel is calling bfloat16. Cutting FP32 models’ bit-width in half accelerates processing itself, but more importantly, halves the RAM needed to keep models in memory. Taking advantage of the new data type is also simpler for programmers and codebases using FP32 models than conversion to integer would be.
Intel also thoughtfully provided a game revolving around the BF16 data type’s efficiency. We cannot recommend it either as a game or as an educational tool.
Optane storage acceleration
-
Performance results “may not reflect all publicly available security updates” sounds like weasel-wording for “Meltdown/Spectre mitigations not applied.”
-
The big draws to Optane storage are dramatically lower latency and higher write endurance than NAND SSDs can offer.
Intel also announced a new, 25 percent-faster generation of its Optane “persistent memory” SSDs, which can be used to greatly accelerate AI and other storage pipelines. Optane SSDs operate on 3D Xpoint technology rather than the NAND flash typical SSDs do. 3D Xpoint has tremendously higher write endurance and lower latency than NAND does. The lower latency and greater write endurance makes it particularly attractive as a fast caching technology, which can even accelerate all solid-state arrays.
The big takeaway here is that Optane’s extremely low latency allows acceleration of AI pipelines—which frequently bottleneck on storage—by offering very rapid access to models too large to keep entirely in RAM. For pipelines which involve rapid, heavy writes, an Optane cache layer can also significantly increase the life expectancy of the NAND primary storage beneath it, by reducing the total number of writes which must actually be committed to it.
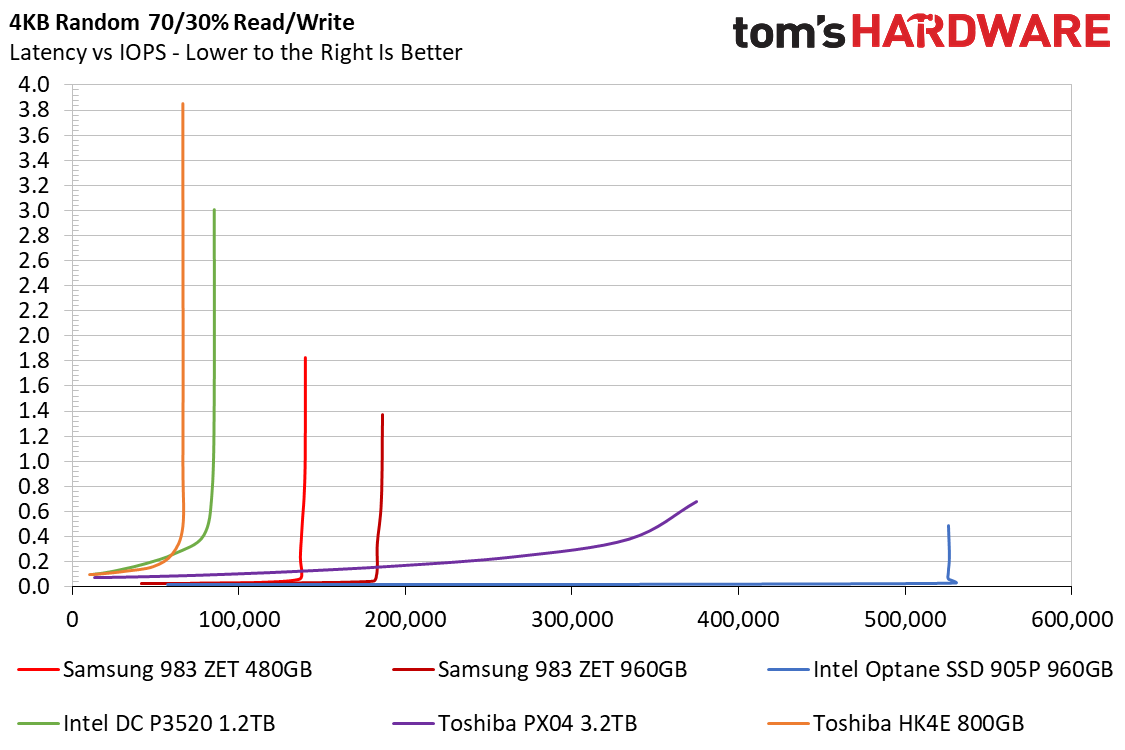
For example, a 256GB Optane has a 360PB write-endurance spec, whereas a Samsung 850 Pro 256GB SSD is only specced for 150TB endurance—greater than a 1,000:1 advantage to Optane.
Meanwhile, this excellent Tom’s Hardware review from 2019 demonstrates just how far in the dust Optane leaves traditional data center-grade SSDs in terms of latency.
Stratix 10 NX FPGAs
-
A curve that doubles almost once per quarter puts Moore’s Law to shame.
-
This block model overview of Stratix claims enormous generation-on-generation INT8 inference improvements at data center scale.
-
When you need higher densities and better efficiency than a general-purpose CPU can provide, you build an ASIC. Stratix is Intel’s answer to AI-targeted ASICs.
Finally, Intel announced a new version of its Stratix FPGA. Field Gate Programmable Arrays can be used as hardware acceleration for some workloads, allowing more of the general-purpose CPU cores to tackle tasks that the FPGAs can’t.
Listing image by Intel
https://arstechnica.com/?p=1684956