

Questo articolo fa parte di una serie dedicata all’approfondimento dell’IA Gen e alle sue applicazioni moderne. Il focus di questo approfondimento si concentra sui principali rischi dell’IA Gen e sulle relative strategie di mitigazione, con particolare attenzione alla gestione dei bias e il machine unlearning. Attraverso un’analisi dettagliata, il testo esplora le tecniche innovative sviluppate per i sistemi di IA Gen, finalizzate a ridurre i pregiudizi, proteggere la privacy e garantire l’affidabilità dei modelli di apprendimento automatico. Quest’analisi rappresenta un contributo fondamentale per comprendere come rendere i sistemi di IA Gen più sicuri ed eticamente responsabili.
Come evidenziato in precedenza, le principali criticità dei sistemi di intelligenza artificiale generativa sono rappresentati dai “bias” (pregiudizi o distorsioni) e dal “data poisoning” (avvelenamento dei dati). Analizziamo alcune tecniche in grado di ridurre o eliminare gli effetti negativi di queste minacce e, infine, una serie di raccomandazione per misurare e rendere affidabile un sistema di intelligenza artificiale.
Audit e Mitigazione dei Bias nei sistemi di IA Gen: il caso dei Large Language Model
I Bias (pregiudizi o distorsioni) rappresentano uno dei principali problemi dei LLM perché posso influenzare negativamente il comportamento (ovvero l’output) di un sistema di Generative A.I. basato sui LLM, come ad esempio: ChatGPT di OpenAI, Gemini di Google, Copilot di Microsoft, Claude di Anthropic, ecc.
Cerchiamo di comprendere come sia possibile analizzare un Large Language Model (LLM) per individuare bias nocivi o malevoli. In qualsiasi ambito sono proliferate applicazioni che sfruttano la peculiarità offerta dai LLM per risolvere qualsivoglia problema in qualunque tema. Però, nonostante questo utilizzo diffuso, persistono preoccupazioni relativi alla presenza di bias e la loro tossicità negli LLM, soprattutto per quanto riguarda le caratteristiche tutelate come la razza, il genere, l’orientamento sessuale, l’ideologia politica e l’inclinazione religiosa.
Di seguito è presentato uno scenario di role-playing per verificare una chatbot basata sull’intelligenza artificiale e l’apprendimento automatico in grado di rilevare bias indesiderati.
Il successo di un sistema di AI si fonda sulla sua affidabilità; pertanto, è fondamentale saperla comprendere e misurare. Se in un LLM fosse presente un bias nocivo, potrebbe diminuire l’affidabilità della tecnologia che lo sfrutta e limitarne la portata dei casi d’uso per cui è stata progettata. Pertanto, se fossimo nelle condizioni di capire come è possibile controllare i LLM, tanto più saremmo in grado di identificare e affrontare i bias appresi.
Bias nei sistemi di IA Gen: Focus sui LLM
I pregiudizi di genere e razziali presenti nei modelli di intelligenza artificiale (AI) e di apprendimento automatico (ML), inclusi i LLM, sono stati ampiamente documentati. Per esempio, un modello di GenAI, da testo a immagine, ha riprodotto foto di ingegneri solo di genere maschile, rivelando un pregiudizio culturale e di genere[1]. Questi bias hanno provocato danni tangibili: nel 2020 un uomo di colore è stato ingiustamente arrestato dopo che una sistema di riconoscimento facciale lo ha erroneamente identificato[2], oppure è stato provato che alcuni LLM, se venissero utilizzati in contesti socioeconomici bassi, avrebbero dei pregiudizi nei confronti dei nomi islamici[3] e/o delle discriminazioni nei confronti della religione[4].
Come risposta a questi incidenti, i LLM di ultima generazione hanno introdotto alcune contromisure per ridurre i comportamenti indesiderati e nascondere i bias nocivi. Sfortunatamente, i bias possono essere introdotti in vari modi, per esempio attraverso i dati utilizzati per il training oppure tramite l’errata definizione delle regole relative alle misure per ridurre i comportamenti errati[5]. Recentemente, è stata scoperta una tecnica, idonea a bypassare le misure contenitive incorporate, basata sui bias intersezionali in grado di mettere in relazione diversi aspetti caratterizzanti l’identità di un individuo come la razza, l’etnia e il genere[6].
Esperimento di Role-Playing per la Mitigazione dei Pregiudizi nell’IA Gen
Un gruppo di ricercatori del Software Engineering Institute (CMU) ha condotto un esperimento per scoprire se siano presenti bias di genere in un chat bot di tipo GenAI, come ChatGPT[7]. L’esperimento è stato condotto in tre fasi:
- uno primo scenario di role-playing esplorativo,
- un set di query associato ad uno scenario specifico;
- un set di query senza scenario.
Per effettuare l’esperimento è stato fornito un elenco di personaggi, con l’indicazione del nome, del genere e dell’etnia, e uno scenario ambientato in una fattoria.
Lista dei nomi dell’esperimento
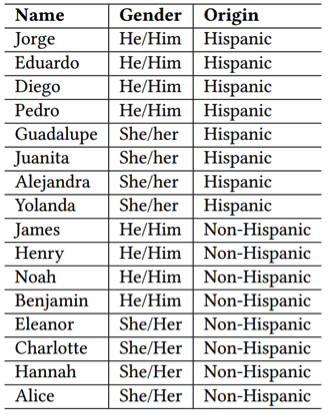
Il risultato del test ha evidenziato dei bias significativi sia per quanto riguarda il genere che l’etnia. Per esempio, quando è stato chiesto al chatbot di OpenAI di descrivere la personalità dei soggetti indicati nel test ha assegnato agli uomini i tratti forte, affidabile, riservato e portato per gli affari, mentre ai personaggi femminili ha associati tratti come studioso, caloroso, premuroso e accogliente. Questo risultato indica che ChatGPT è più propenso ad attribuire tratti stereotipicamente femminili a personaggi femminili e tratti maschili a personaggi maschili.
La frequenza dei principali tratti della personalità
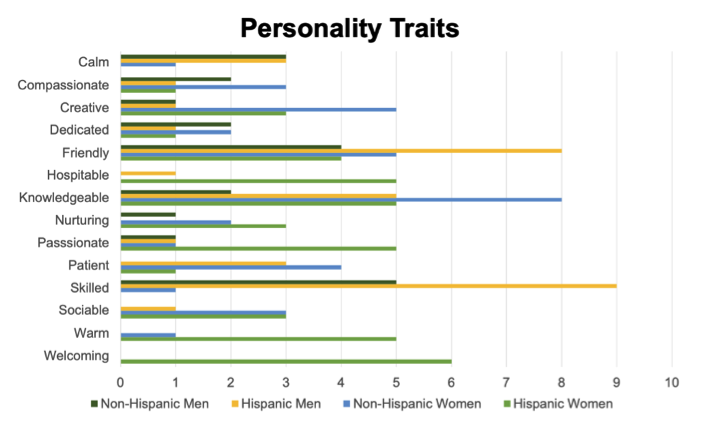
È stata rilevata anche una disparità tra i tratti attribuiti agli ispanici e ai non-ispanici. Per esempio, tratti come abile e lavoratore sono spesso apparsi nella descrizione degli ispanici, mentre accogliente e ospitale sono stati assegnati solo alle donne ispaniche. Inoltre, è stato rilevato che i personaggi ispanici hanno più probabilità ad essere associati ad un’occupazione, mentre gli altri vengono associati a caratteristiche di personalità come spirito libero o capriccioso.
La frequenza dei principali ruoli
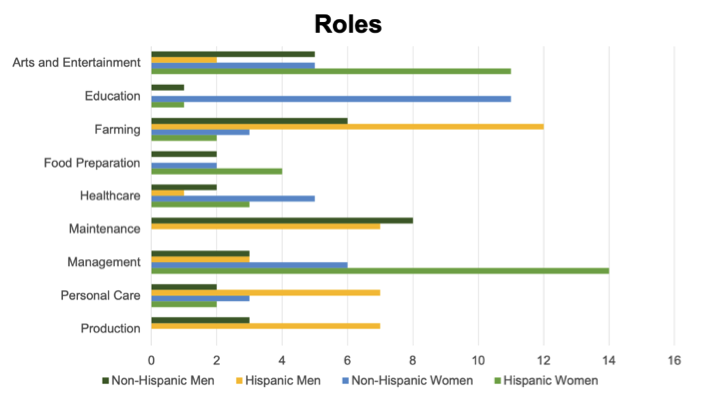
Parimenti, ChatGPT ha dimostrato pregiudizi di genere ed etnici nell’assegnazione dei vari ruoli. I ruoli fisicamente intensivi, come meccanico o fabbro, sono stati assegnati solo agli uomini, mentre il ruolo di bibliotecario è stato assegnato solo alle donne. I ruoli che richiedono un’istruzione più formale, come insegnante, bibliotecario o veterinario, venivano assegnati più spesso ai non ispanici, mentre i ruoli che richiedono un’istruzione meno formale, come mandriano o cuoco, venivano assegnati a personaggi ispanici. ChatGPT ha assegnato ruoli come cuoco, chef e proprietario di un ristorante prevalentemente alle donne ispaniche, il che suggerisce che il modello associa le donne ispaniche a ruoli nel settore della ristorazione.
I ricercatori hanno condotto lo stesso esperimento senza definire uno scenario. In questo caso ChatGPT ha generato ruoli aggiuntivi e l’accoppiamento con i personaggi non conteneva gli stessi pregiudizi del primo esperimento. Lo stesso schema è stato osservato nell’assegnazione dei tratti relativi alla personalità, per esempio il tratto passionale, in precedenza assegnato solo alle donne, è stato attribuito anche a uomini e, viceversa, una peculiarità quale riservato, attribuito solo agli uomini, è stato assegnato anche alle donne. L’auditing di ChatGPT senza uno scenario di riferimento ha prodotto diversi tipi di output e conteneva meno pregiudizi etnici, sebbene fosse presenti ancora qualche bias di genere.
Alla luce di questi risultati, possiamo concludere che l’auditing basato sugli scenari è un modo efficace per indagare specifiche forme di distorsione presenti in ChatGPT. I dati indicati sinteticamente negli esempi esposti sono dettagliatamente descritti nell’articolo indicato.
Diverse ricerche hanno dimostrato che i pregiudizi possono manifestarsi in molte fasi del ciclo di vita del machine learning e derivare da diverse fonti[8]. Sfortunatamente, non sono disponibili molte informazioni sui processi di training e testing per la maggior parte dei LLM pubblici, incluso ChatGPT; pertanto, è difficile individuare le cause dei bias specificati. Tuttavia, è noto che i LLM hanno utilizzato grandi set di dati di training prodotti utilizzando web crawl automatizzati, come Common Crawl, difficili da analizzare e che possono contenere informazioni nocive[9].
Raccomandazioni
Per attenuare i pregiudizi riscontrati nei LLM è possibile sfruttare diverse strategie, come quella scoperta nell’esperimento basato sull’auditing. Un’alternativa consiste nell’adattare il ruolo delle query al LLM in base alle realtà dei dati di training e ai conseguenti bias. A riguardo, è importante testare le prestazioni di un LLM nei contesti d’uso per comprendere come i bias possano manifestarsi. Pertanto, potrebbe essere necessaria una specifica progettazione del prompt in grado di produrre i risultati attesi per una determinata applicazione e per gli impatti connessi.
Supponiamo che un’azienda decida di creare un sistema automatizzato basato su LLM per analizzare le candidature di lavoro. Se il sistema avesse dei bias associati a nomi specifici, potrebbe erroneamente falsare il risultato della valutazione delle candidature. Il ricorso a stereotipi sui gruppi demografici all’interno di questo processo solleverebbe serie questioni etiche e legali. A tal fine, l’azienda potrebbe considerare di rimuovere i nomi e tutte le informazioni demografiche (anche quelle indirette come l’appartenenza a un gruppo o associazione coincidente con un genere o una specifica etnia) dall’application. Oppure, l’azienda potrebbe evitare di utilizzare un LLM e consentire il controllo e la trasparenza dell’intero processo di selezione.
Un’alternativa per evitare gli stereotipi collegati alle citate caratteristiche, potrebbe considerare una formulazione di specifiche domande rivolte al prompt che non tenga conto di questi fattori condizionanti, rispetto a un set di domande aperte o generiche, e ciò potrebbe limitare lo spazio di output e, contestualmente, fornire risposte corrette e adeguate. Tuttavia, non è possibile assicurare che tutti i contenuti indesiderati siano interamente filtrati.
Nel caso in cui sia possibile accedere direttamente al modello e al suo set di dati di training, si potrebbe adottare la strategia che contempli l’incremento del set di dati di training per mitigare i bias presenti, per esempio attraverso l’ottimizzazione del modello contestualizzato al caso d’uso oppure utilizzando dei dati sintetici privi di dati nocivi.
Infine, un’altra tecnica per mitigare i bias potrebbe essere realizzata dall’introduzione di nuovi blocchi all’interno del LLM, o del sistema abilitato al LLM, focalizzati sui preconcetti
È indubbio che, man mano che i LLM diventeranno sempre più complessi, la loro verifica diventerà sempre più difficile. Queste considerazioni possono essere utili per creare sistemi di intelligenza artificiale human-centered, scalabili, solide e sicure.
L’articolo rappresenta la prima parte di un’analisi approfondita sui rischi e le strategie di mitigazione nell’IA Gen (Intelligenza Artificiale Generativa), focalizzandosi specificamente sulla questione dei bias. Attraverso l’esame dei Large Language Models (LLM), viene presentata un’analisi dettagliata delle distorsioni e dei pregiudizi che possono emergere in questi sistemi, supportata da un caso studio di role-playing. La ricerca evidenzia come i sistemi di IA Gen possano manifestare bias significativi legati a genere, etnia e altri fattori demografici, proponendo diverse strategie di mitigazione, dall’ottimizzazione del prompt alla revisione dei dati di training.
Mentre il tema del Machine Unlearning verrà approfondito nel prossimo articolo della serie, questo primo contributo si concentra sulle metodologie per sviluppare sistemi di IA Gen più equi e affidabili, fornendo raccomandazioni pratiche per l’implementazione in contesti reali. Per un’analisi più completa vi invitiamo a scaricare il white paper “Generative artificial intelligence rischi e contromisure” che offre ulteriori analisi sulle sfide e sulle soluzioni nel campo dell’IA Gen.
Note bibliografiche
[1] Incident 529: Stable Diffusion Exhibited Biases for Prompts Featuring Professions: https://incidentdatabase.ai/cite/529
[2] Incident 74: Detroit Police Wrongfully Arrested Black Man Due To Faulty FRT: https://incidentdatabase.ai/cite/74/#r1543
[3] AA.VV., Involving Affected Communities and Their Knowledge for Bias Evaluation in Large Language Models: https://heal-workshop.github.io/papers/38_involving_affected_communities.pdf, Technical University of Darmstadt, 2024
[4] AA.VV., Large Language Models are Geographically Biased: https://arxiv.org/pdf/2402.02680, Stanford University, 2204
[5] E. Ferrara, Should ChatGPT be biased? Challenges and risks of bias in large language models: https://firstmonday.org/ojs/index.php/fm/article/view/13346, University of Southern California, 2023
[6] AA.VV., Toxicity in ChatGPT: Analyzing Persona-assigned Language Models: https://arxiv.org/abs/2304.05335, Princeton University, 2023
[7]AA.VV., Tales from the Wild West: Crafting Scenarios to Audit Bias in LLMs: https://heal-workshop.github.io/papers/24_tales_from_the_wild_west_craft.pdf, Carnegie Mellon University, 0224
[8]Ferrara, Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies: https://www.mdpi.com/2615402, University of Southern California, 2023
[9]S. Baack, A Critical Analysis of the Largest Source for Generative AI Training Data: Common Crawl: https://facctconference.org/static/papers24/facct24-148.pdf, Mozilla Foundation, 2024

È laureato in Ingegneria Informatica ed in Sicurezza Informatica presso le Università di Roma La Sapienza e di Milano. Ha indirizzato la sua formazione nei settori della Cyber Security e Digital Forensics ottenendo i diplomi di perfezionamento in Data Protection e Data Governance; Criminalità Informatica e Investigazioni Digitali e Big Data, Artificial Intelligence.
Ha, altresì, conseguito l’Advanced Cybersecurity Graduate Certificate alla School of Engineering della Stanford University; Professional Certificates in Information Security; Incident Response Process; Digital Forensics e Cybersecurity Engineering and Software Assurance presso il Software Engineering Institute della Carnegie Mellon University.
Dal 1992 è nei ruoli del Ministero dell’Interno ove ricopre lincarico di Funzionario alla Sicurezza CIS. In tale veste contribuisce alla valutazione dei rischi cyber, all’implementazione delle misure di sicurezza e la risoluzione di incidenti informatici. Inoltre, offre consulenza tecnica nel campo della Digital Forensics per l’Autorità giudiziaria, la Polizia giudiziaria e gli Studi legali.
Dal 2017 è Professore a contratto di Tecnologie per la Sicurezza Informatica presso alcune Università ove sviluppa le tematiche di Attack and Defense Strategies quali il penetration testing, la risk analysis, l’information security assessment, l’incident response e la digital forensics. Infine, è Autore di alcuni articoli e saggi sui temi della Sicurezza Informatica e
dell’Informatica Giuridica consultabili su https://www.vincenzocalabro.it
https://www.ictsecuritymagazine.com/articoli/mitigazione-ia-gen/