

“Adversarial Machine Learning”, “Adversarial Attacks”, “Adversarial Examples” e “Adversarial Robustness” sono termini che appaiono sempre più spesso quando si considerano aspetti di sicurezza dei modelli di Machine Learning (ML).
Bug Hunting e Adversarial Examples
Come pratica ormai consolidata nella sicurezza informatica, una nuova applicazione, sistema o servizio va prima o poi soggetto a delle verifiche di “sicurezza”, intesa anche in senso lato, da parte di esperti che cercano di trovare errori, comportamenti anomali o vere e proprie vulnerabilità. Questo accade anche per i modelli di Intelligenza Artificiale e in particolare di Machine Learning.
Sin dalle prime applicazioni pratiche dei modelli ML, nei primi anni 2000, i ricercatori si impegnarono a verificare il loro comportamento: ad esempio trovando modalità di evadere i filtri anti-SPAM basati su modelli ML e aggirare le applicazioni di ML per il riconoscimento di immagini (inizialmente questi erano chiamati genericamente Evasion Attacks, mentre il termine maggiormente usato oggi è Adversarial Examples).
Queste attività possono essere considerate l’equivalente di eseguire un Penetration Test su un’applicazione Web, o di trovare il modo di aggirare o ingannare un sensore biometrico con funzioni di controllo degli accessi. Riportiamo qui solo due esempi provenienti dalla ormai enorme letteratura a riguardo [Rif. 1] e relativi ad applicazioni ML per il riconoscimento di immagini.

La Fig. 1 presenta un ben riconoscibile cartello stradale di Stop ma, a causa dello sticker giallo apposto sotto la scritta, il modello ML sotto attacco interpreta il segnale con il 94,7% di probabilità come un limite di velocità (tipicamente 40Kmh o 25Mph). Una ipotetica vettura a guida autonoma che utilizzasse questo modello ML per riconoscere la segnaletica stradale, quindi, non si fermerebbe allo Stop ma proseguirebbe a velocità inferiore al limite, con ben immaginabili possibili conseguenze.
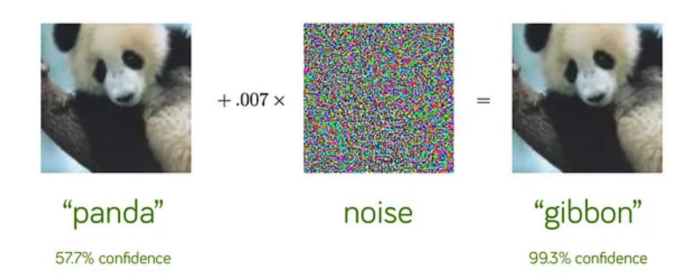
La Fig. 2 presenta un’immagine di un panda (a sinistra) in cui al 7 per mille dei pixel viene aggiunto del “rumore bianco”. Il risultato è che, per l’occhio umano, l’immagine non è cambiata; mentre per il modello ML ora rappresenta una scimmia gibbone con il 99,3% di probabilità.
Lo studio di queste vulnerabilità ha portato a comprendere – si veda ad esempio [Rif. 4] – che non si tratta di errori dovuti ad una particolare implementazione errata o disattenzione dei programmatori, ma di un problema più generale e profondo dei modelli ML.
Per semplicità e chiarezza di esposizione, conviene distinguere due significati simili ma non precisamente identici del termine “Adversarial Machine Learning”:
- Adversarial ML – Aspetti Scientifici: studio della “Robustezza” dei modelli tramite la possibilità di costruire Adversarial Examples con tecniche sperimentali e matematiche – si vedano i due esempi precedenti;
- Adversarial ML – Aspetti Operativi: Studio dei possibili attacchi ai modelli ML utilizzati in ambiente Business.
I due ambiti hanno ovviamente ampie aree di sovrapposizione ma i principali obiettivi, pur essendo allineati, sono diversi.
Adversarial Machine Learning – Aspetti Scientifici
In ambito scientifico lo scopo della ricerca è comprendere quali sono le ragioni dell’esistenza degli Adversarial Examples e, di conseguenza, come migliorare i modelli ML in modo da non averne. I modelli ML senza Adversarial Examples sono chiamati Robusti: questo non vuol dire che non possono fare errori o confondersi, ma che non hanno deviazioni sistematiche con grandi errori dal comportamento atteso.
Nel primo esempio sopra riportato, in un modello ML Robusto l’applicazione di sticker o altri camuffamenti e scritte che all’occhio umano non nascondono il cartello stradale di Stop, possono al più ridurre la confidenza dell’identificazione del cartello da parte del modello ML ad una percentuale del 70% o 60%, ma non identificare il cartello come un altro segnale con quasi assoluta certezza. Nel secondo esempio, due immagini che appaiono uguali all’occhio umano devono essere classificate similmente da un modello ML Robusto, al più con diverso livello di confidenza; e non possono essere identificate come raffiguranti due animali diversi, quello errato con quasi assoluta certezza.
È possibile quindi paragonare il processo di creazione di un modello ML Robusto al processo di sviluppo sicuro del software: ormai è ben noto come sviluppare software adottando pratiche che permettono di ridurre il più possibile la probabilità di Bugs e vulnerabilità di sicurezza, anche se rimane molto difficile se non impossibile (anche teoricamente) scrivere del software complesso con garanzia assoluta di assenza di vulnerabilità.
Ma i modelli ML che sono oggi disponibili sono ancora molto giovani. Benché i primi sviluppi di modelli di Intelligenza Artificiale risalgano agli anni ’50, lo sviluppo dei modelli ML odierni è iniziato decisamente negli anni ’90. Anche se l’architettura di base di molti modelli ML è a prima vista semplice, gli algoritmi matematici che li supportano possono essere molto complessi e ancora non ben compresi/risolti dai ricercatori, ad esempio quelli dei modelli di Deep Learning che recentemente hanno fatto tanto clamore giornalistico.
Siamo quindi nel periodo in cui si è identificato un problema (l’esistenza di Adversarial Examples in modelli ML) e lo si sta studiando; ma non si è ancora trovata la soluzione generale (come costruire modelli ML Robusti) né l’approccio operativo per risolverlo.
L’esistenza di Adversarial Examples è legata al processo di apprendimento di un modello ML. Una tra le principali caratteristiche dei modelli ML è avere moltissimi, anche centinaia di miliardi di parametri numerici configurabili. Inizialmente questi parametri hanno valori casuali e il processo di apprendimento consiste appunto nel configurare il miglior valore di ogni parametro in modo che ogni dato di addestramento in ingresso venga elaborato dal modello, producendo in uscita il risultato atteso. Semplificando molto il funzionamento di questi modelli, quando un nuovo dato viene elaborato dal modello ML, i valori dei parametri configurati permettono di identificare somiglianze con i dati di addestramento e fornire un risultato probabilisticamente vicino a quello corretto od ottimale. Ovviamente il set di dati di addestramento non è esaustivo di tutti i possibili dati esistenti: nei due esempi precedenti non comprende tutte le possibili immagini di cartelli stradali o di panda, anche perché sarebbe una quantità infinita di dati. I set di dati di addestramento sono però rappresentativi dei dati esistenti ma a priori (e in pratica) non è detto che siano sufficienti a configurare tutti i parametri del modello ML in maniera ottimale. C’è quindi la possibilità che una particolare combinazione di dati in ingresso corrisponda ad uno speciale set di parametri che non è stato configurato ottimamente per quei dati (o per nulla) e che quindi generi un risultato errato.
Una ovvia prima soluzione all’esistenza degli Adversarial Examples è addestrare nuovamente il modello ML includendo tra i dati di addestramento gli Adversarial Examples. Il primo problema di questo approccio è che bisogna innanzitutto essere capaci di identificare tutti gli Adversarial Examples; e questo è proprio uno dei principali problemi ancora aperti. Inoltre alcuni modelli ML hanno mostrato di essere soggetti a vulnerabilità o debolezze quali la “sotto-specifica” (Underspecification, ovvero il fatto che una minima modifica ai dati di addestramento produce grandi modifiche nel modello) e la “smemoratezza” (Forgetfulness, ovvero un aggiornamento del modello con nuovi dati porta il modello a dimenticare parte di quello che aveva già appreso). Vi è quindi il rischio che un ulteriore addestramento di un modello ML, aggiungendo anche gli Adversarial Examples tra i dati di addestramento, possa introdurre nuovi Adversarial Examples, senza quindi risolvere il problema. Queste e simili fragilità attuali del processo di apprendimento dei modelli ML rendono oggi difficile – se non impossibile – identificare ed eliminare completamente gli Adversarial Examples dai modelli ML.
Riferimenti Bibliografici
Rif. 1: N. Carlini, “A Complete List of All (arXiv) Adversarial Example Papers”, https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html, nel solo anno 2022 risultano pubblicati quasi 3.000 articoli scientifici relativi a “Adversarial Machine Learning”
Rif. 2: T. Gu, B. Dolan-Gavitt, S. Garg, “BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain”, 2017, arXiv:1708.06733
Rif. 3: I.J. Goodfellow, J. Shlens, C. Szegedy, “Explaining and Harnessing Adversarial Examples”, 2014, arXiv:1412.6572
Rif. 4: B. Biggio, B. Nelson, P. Laskov, “Poisoning Attacks against Support Vector Machines”, 2013-03-25, ArXiv:1206.6389; Biggio, I. Corona, D. Maiorca, B. Nelson, N. Srndic, P. Laskov, G. Giacinto, F. Roli, Fabio, “Evasion attacks against machine learning at test time” , 2013, ECML PKDD. Lecture Notes in Computer Science. Vol. 7908. Springer. pp. 387–402, arXiv:1708.0613; Biggio, F. Roli, Fabio, “Wild patterns: Ten years after the rise of adversarial machine learning” , dicembre 2018, Pattern Recognition. 84: 317–331, arXiv:1712.03141intell
Continua a leggere: scarica il white paper gratuito “Adversarial Attacks a Modelli di Machine Learning“
Articolo a cura di Andrea Pasquinucci

PhD CISA CISSP
Consulente freelance in sicurezza informatica: si occupa prevalentemente di consulenza al top management in Cyber Security e di progetti, governance, risk management, compliance, audit e formazione in sicurezza IT.
https://www.ictsecuritymagazine.com/articoli/adversarial-attacks-a-modelli-di-machine-learning/