

La metodologia di analisi forense di un sistema GNU/Linux segue sostanzialmente gli standard e le best practises in uso nella Digital Forensics ma, per poter applicare correttamente tali metodologie, in particolare nelle fasi di identificazione, acquisizione ed analisi, è necessario conoscere le caratteristiche, le potenzialità e le criticità dello specifico sistema.
L’argomento è molto vasto e non è possibile trattarne i vari aspetti in un articolo; quindi si tenterà un rapido excursus con lo scopo di dare le informazioni essenziali sul sistema – anche un pò di storia che non guasta mai – e le principali problematiche relative all’approccio.
Sicuramente la maggior parte dei lettori avrà dimestichezza con i sistemi Windows e sarà in grado di effettuare un’acquisizione e successiva analisi dei sistemi in cui sono installati i prodotti della famiglia Windows; verrà utilizzata quindi una linea di confronto – per quanto possibile – onde procedere alla comprensione con riferimenti già noti.
Prima di addentrarsi nel processo di analisi dei sistemi Linux dal punto di vista forense, è necessaria ripercorrere la storia di Unix e Linux. All’inizio degli anni ’70, il sistema operativo (OS) Unix – abbreviato da UNICS (UNiplexed Information and Computing Service) – evolve dalle ceneri di un progetto di AT&T Bell Labs atto a fornire all’utente l’accesso simultaneo ai servizi di computer mainframe. Unix crebbe in popolarità e dimostrò sul campo la sua alta affidabilità, iniziando a sostituire i sistemi operativi nativi su alcune comuni piattaforme mainframe. La nuova versione del sistema, riscritta nel linguaggio C, ne migliorò sensibilmente la portabilità e consentì l’emersione sul mercato di diverse versioni di Unix, – comprese quelle per i microcomputer -; nei decenni successivi alcuni derivati di Unix, denominati “Unix-like” presero forma: è il caso di ricordare Mac OS di Apple, Sun Microsystem Solaris, e BSD (Berkeley Software Distribution).
Gli sforzi per creare una versione liberamente disponibile di Unix iniziarono negli anni ’80 con il progetto GNU (“GNU’s Not Unix”) General Public License (GPL), ma non riuscirono a produrre i risultati sperati.
Questo portò il programmatore finlandese Linus Torvalds ad affrontare lo sviluppo di un nuovo kernel Unix (il modulo di controllo centrale di un sistema operativo) come progetto studentesco. Usando il sistema operativo educativo Unix-like Minix, Torvalds codificò con successo un kernel affidabile nel 1991, rendendo il codice sorgente liberamente disponibile per il download pubblico e la manipolazione sotto la GNU GPL.
Il progetto fu poi chiamato Linux (una combinazione del nome di Torvalds, “Linus”, con “Unix”). La flessibilità e l’efficienza di Linux lo hanno conseguentemente portato all’adozione diffusa – da parte di industrie, aziende e singoli utilizzatori in tutti i continenti -; oggi il sistema è presente su smartphone, orologi, auto, negli elettrodomestici, nelle installazioni militari e in svariati altri dispositivi. La maggior parte dei server attualmente presenti nella rete internet[1] (Wikipedia e la Borsa di New York, ad esempio) utilizzano Linux.
IBM lo scelse nel 2011 per realizzare Sequoia[2], il supercomputer che doveva essere il più potente mai creato.
Attualmente il 100%[3] dei supercomputer[4] attualmente esistenti usa GNU-Linux, e un motivo sicuramente ci sarà – esecuzione di carichi di lavoro ad elevata disponibilità all’interno di data center e ambienti cloud; modularità, che consente una gestione più semplice dato che ogni singolo componente del sistema operativo Linux può essere sottoposto ad audit, monitorato e protetto; dotazione di moduli e strumenti integrati, come SELinux, – per citarne uno – che aiutano a bloccare, monitorare, segnalare e rimediare in maniera più completa eventuali problematiche relative alla sicurezza; etc. –
Bene, cominceremo ad addentrarsi nei meandri del kernel, descrivendone la prima differenza con i sistemi operativi Windows: il File System. Windows utilizza File System NTFS, FAT e exFAT o FAT64 che dir si voglia, pensato per le memorie flash; ReFS, (Resilient File System) è l’ultimo sviluppo di Microsoft introdotto con Windows 8 e ora disponibile per Windows 10. L’architettura del File System differisce assolutamente dagli altri File System di Windows ed è principalmente organizzata in una forma di B + -tree.
Un cenno lo merita NTFS, il più adoperato tra i File System Windows: una sola struttura fissa, il boot sector; le altre strutture di controllo non sono predeterminabili essendo rappresentate da file. La principale struttura dati è delineata dalla MFT (Master File Table), anch’essa costituita da file – fisicamente – ma logicamente strutturata come una sequenza lineare ≤ 2^48 record di ampiezza da 1 a 4 Kbyte.[5]
Linux impiega come regola generale il mounting dei dispositivi su directory, generalmente “/mnt” e “/media”. L’organizzazione del filesystem di Linux è gerarchica: la sua struttura è ad albero con il livello più alto espresso dal simbolo “/” e denominato “directory root”.
Non esiste distinzione tra hardware e software (le periferiche hardware in Linux vengono rappresentate come dei file speciali) e qualsiasi parte del sistema è figlia della directory radice. In calce un esempio esplicativo di directory costituenti il File System Linux:
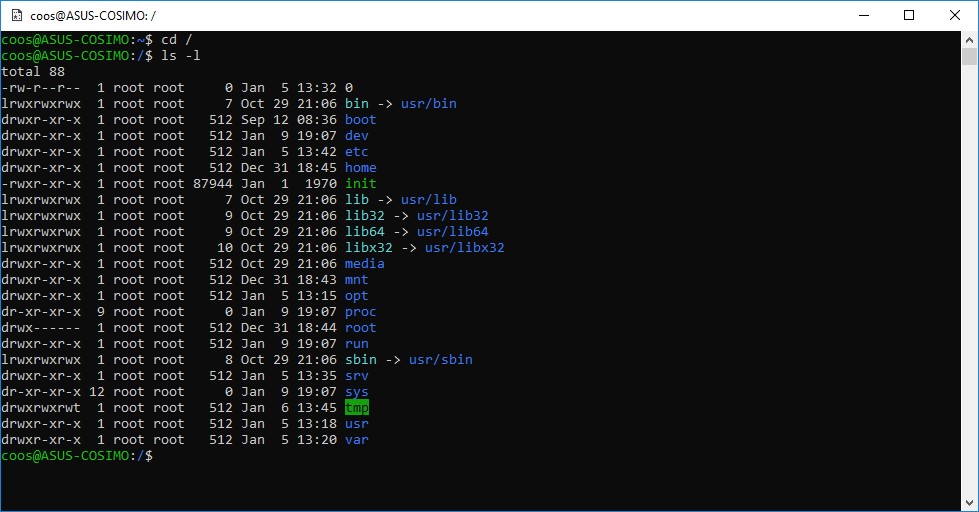
fig. 1
All’interno della directory root (/) è presente un insieme di directory comuni a tutte le distribuzioni Linux. Quello che segue è un elenco delle più comuni presenti nella root (/):
- /bin: applicazioni per la gestione del sistema;
- /boot: kernel e file di configurazione necessari al processo di boot;
- /dev: file dei device (dispositivi);
- /etc: file di configurazione, script di avvio, etc…;
- /home: directory home degli utenti locali;
- /lib: librerie di sistema;
- /media: dispositivi rimovibili (media) montati (caricati) come CD, fotocamere digitali, etc.;
- /mnt: Punto di montaggio per media esterni;
- /opt: contiene applicazioni aggiuntive ed opzionali (Oracle, OpenOffice, Libreoffice, etc.);
- /proc: contiene un File System virtuale. Non è infatti un File System vero e proprio, in quanto viene creato dal kernel dinamicamente istante per istante, in memoria e non sul disco. Al suo interno sono contenute le informazioni relative al sistema (originariamente erano contenute esclusivamente le informazioni relative ai vari processi in esecuzione, da ciò il nome proc);
- /root: home directory dell’utente root;
- /sbin: contiene programmi di sistema eseguibili solo dall’amministratore del sistema come ad esempio fdisk o fsck;
- /sys: file di sistema;
- /tmp: file temporanei;
- /usr: file e applicazioni che sono per la maggior parte disponibili a tutti gli utenti (users) e non indispensabili al sistema;
- /var: parte variabile dei programmi. Contiene log, mail, database, etc.
Tutti i file in un sistema Linux hanno permessi che abilitano o meno gli utenti alla visualizzazione, modifica o esecuzione. Il super utente “root” ha l’abilità di accedere a ogni file nel sistema. Ogni file possiede delle restrizioni di accesso, restrizioni sull’utente ed è associato con un proprietario/gruppo.
Un ausilio importante per l’analisi di un sistema Linux proviene dalla comprensione del processo di avvio. Infatti, la conoscenza dei file coinvolti in detto processo potrebbe aiutare l’esaminatore forense a determinare, ad esempio, la versione del sistema operativo in esecuzione e la data di installazione.
Inoltre, gli consentirebbe di mirare la ricerca delle evidenze in caso di modifica fraudolenta di alcuni aspetti del processo di avvio che, data la sua natura di sistema aperto, un utente dotato dei privilegi sufficienti, potrebbe aver modificato.
Una trattazione completa del processo di avvio di Linux esula la trattazione di questo articolo, ma è opportuno esporre una breve descrizione dello stesso.
Il primo passo del processo di avvio di Linux è l’esecuzione del boot loader[6], che individua e carica il kernel. Il kernel è il cuore del sistema operativo ed è generalmente presente nella directory “/boot”.
Successivamente viene montato in memoria initrd[7] (Inizial RamDisk).
Il File System temporaneo initrd contiene i driver di dispositivo, i moduli del File System, i moduli del volume logico e altri elementi richiesti per l’avvio ma non presenti nel kernel.
Terminata la cosiddetta fase di bootstrap, il kernel procede ad inizializzare l’hardware del sistema e ad avviare il processo “/sbin/init” che porterà il sistema in uno stato operativo.
Due sono le filosofie che organizzano il funzionamento di init: System V[8] e BSD[9].
Nel metodo System V, il processo init legge il file “/etc/inittab” per determinare l’impostazione predefinita del runlevel. Un runlevel è un numero che identifica il set di script che una macchina eseguirà per un dato stato. Ad esempio, sulla maggior parte delle distribuzioni Linux, runlevel 3 fornirà un pieno ambiente di console multiutente, mentre runlevel 5 produrrà un ambiente grafico. Da notare che ogni voce in una directory di runlevel è in realtà un collegamento software a uno script in “/etc/init.d/”, che verrà avviato o interrotto a seconda del nome del collegamento: il nome che inizia con “S” indica l’ordine di avvio, mentre quelli che iniziano con “K” ne indicano l’ordine di interruzione del servizio.
Nel metodo BSD, invece, a ogni runlevel corrisponde uno script (solitamente chiamato /etc/rc.d/rc.X), che ha il compito di avviare tutti i processi necessari a portare il sistema nel runlevel richiesto.
Conclusa la breve panoramica sul processo di boot, andremo ora ad esaminare le peculiarità del File System di Linux, ovvero il meccanismo con il quale i file vengono immagazzinati ed organizzati su un dispositivo di archiviazione.
Vengono utilizzati principalmente due tipologie: Ext3 e Ext4; Ext3 è retrocompatibile con il File System Ext2 da cui deriva con l’aggiunta del journaling[10] che permette di eseguire modifiche ai file adoperando il concetto di transazione[11], preservando in questo modo l’integrità dei dati.
Genericamente un file in Linux consiste in uno o più blocchi di dati contenenti qualsiasi tipo di informazioni (una directory è un particolare tipo di file). Ad ogni file è associato un inode; inoltre gli inode vengono identificati tramite un numero chiamato inumber; con un inumber è possibile identificare univocamente un file all’interno del File System.
Poiché un inode ha una dimensione limitata e ha lo spazio solo per un piccolo numero di puntatori diretti ai blocchi di dati, i blocchi successivi sono referenziati in modo indiretto.
L’accesso indiretto ai blocchi di dati è realizzato attraverso alcuni puntatori in ogni inode.
Quando la dimensione di un file richiede più blocchi di quelli che possono essere indirizzati dai puntatori diretti, viene allocato un blocco che non fa parte del file, ma viene usato per contenere puntatori diretti ai blocchi successivi del file (indirizzamento indiretto singolo).
Se il file è particolarmente grande, un blocco pieno di puntatori diretti può non bastare, in questo caso sarà necessario usare uno o due livelli di indirizzamento (indirizzamento indiretto doppio o triplo).
Un puntatore indiretto doppio di inode punta a un blocco che contiene puntatori indiretti singoli, ciascuno dei quali punta ai blocchi contenenti puntatori diretti. Così il sistema operativo può seguire una catena fino a 4 di questi puntatori per accedere ai blocchi di un file molto grande.
Vi sono grandi differenze tra File System Ext2 e Ext3; su Ext3 il recupero dei dati è decisamente arduo e, in alcuni casi, addirittura impossibile; per garantire l’integrità dei dati dopo un malfunzionamento, il sistema azzera tutti i puntatori agli inode[12], che vanno irrimediabilmente persi una volta che il file è in stato non allocato.
Il contenuto del file originale sarà ancora presente nei blocchi di dati non allocati del File System, almeno fino a quando tali blocchi non saranno riutilizzati, ma non esiste una “mappa” per ricostruire quei blocchi di dati nel file originale.
I metodi tradizionali per il recupero dei file si basano su strumenti di “file carving” quali Scalpel e Foremost. Questi strumenti, imperniandosi sull’allocazione consecutiva dei blocchi di dati che compongono un file, consentono, adoperando una “signature“[13] – che normalmente identifica un particolare tipo di file -, il recupero della maggior parte o di tutto il file, raccogliendo via via i blocchi successivi. Se il formato del file include anche una “signature” di fine file, lo strumento sarà in grado di interrompere la raccolta dei blocchi appartenenti al file in esame.
Pur tuttavia, vi sono alcuni problemi derivanti dall’utilizzo di detta tecnica durante il recupero dei dati dai sistemi Linux:
- Data l’intrinseca struttura del sistema operativo, orientato ampiamente al testo, molti artefatti Linux mancano di “signature” valide.
- Ext3, come già evidenziato, utilizza i blocchi indiretti nel mezzo del contenuto del file per memorizzare i metadati. Questi “blocchi indiretti” – che Foremost ignorerà semplicemente sia come blocco che come contenuto – vengono utilizzati per archiviare i puntatori di riferimento ai blocchi di dati quando un file diventa troppo grande e non può più essere rappresentato dal numero relativamente piccolo di puntatori di riferimento all’inode; ciò potrebbe causare il danneggiamento dei file qualora vengano estratti assieme ai blocchi di dati che lo compongono;
- Il tentativo di recuperare un file raccogliendo blocchi consecutivi si interromperà quando verrà individuata una frammentazione del file su più aree del disco.
In calce la struttura degli Inode in Ext2/Ext3: gli offset e le lunghezze sono espressi in byte.
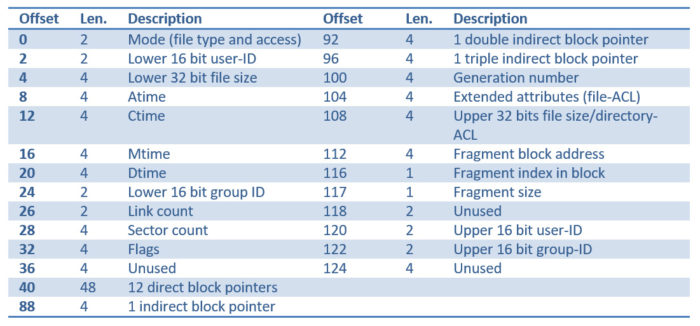
fig. 2
In generale, il layout Ext, si basa su blocchi sequenziali di 1024, 2048 o 4096 byte numerati e raggruppati, a loro volta, in gruppi.
Ogni catena di blocchi contiene metadati che documentano la sua struttura interna.
La disposizione generale di tutte le catene di blocchi è illustrata in Fig. 3.
Il superblocco contiene molti metadati essenziali del File System, come ad esempio il numero e la dimensione dei blocchi, il numero di inode e i blocchi riservati. La “group descriptor table” contiene le informazioni per ogni catena di blocchi nel File System e la “block bitmap” memorizza lo stato libero/utilizzato di ciascun blocco. Allo stesso modo, la “inode-bitmap” memorizza lo stato libero/utilizzato di ogni inode nella tabella degli inode. Il resto della catena di blocchi è costituito da dati consecutivi che vengono utilizzati per memorizzare i dati.
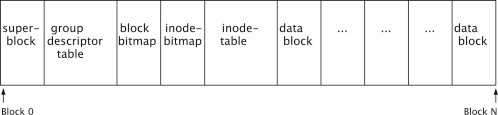
fig. 3
In tutti i File System Ext, quasi tutti i metadati di file/directory, come ad esempio timestamp, diritti di accesso, riferimenti a blocchi di dati, sono memorizzati nell’inode del file (i nomi dei file, ad esempio, non lo sono, sebbene non siano sempre considerati come metadati). Gli inode sono numerati, a partire dall’inode numero 1 e memorizzati nella tabella degli inode della rispettiva catena di blocchi.
Con la Ext3, per motivi di compatibilità con le versioni precedenti, sono state implementate solo poche modifiche alla struttura inode. Ad esempio, alcuni degli spazi precedentemente non utilizzati sono stati adoperati per introdurre nuovi attributi, come mostrato nella fig.4 (Per la struttura originale completa degli inode Ext3, si faccia riferimento alla fig.2).
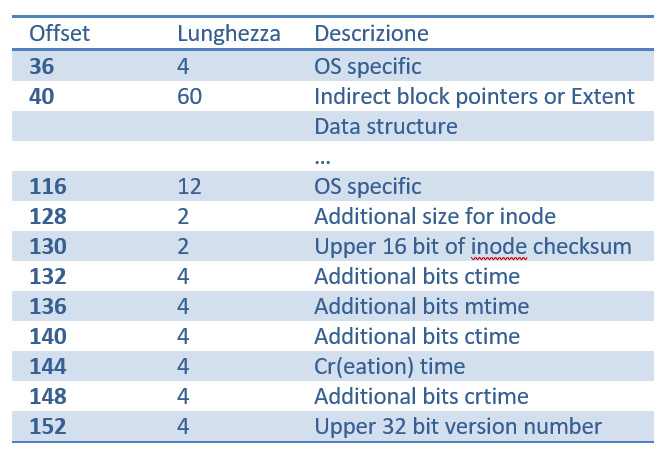
fig. 4
Il layout generale di Ext4 è molto simile a Ext3 anche se ha subito alcune modifiche.
Una caratteristica, ad esempio, introdotta in Ext4 è il concetto dei cosiddetti “Flex Group”. I Flex Group combinano più gruppi di blocchi in un unico gruppo di blocchi logici. Solo il primo gruppo di blocchi contiene le bitmap di blocco e inode, nonché le tabelle di inode di tutti i gruppi di blocchi.
E ancora:
- Spazio degli indirizzi a 48 bit;
- Utilizzo di estensioni (Extend) invece di catene di blocchi indiretti;
- Timestamp a 64 bit con precisione al nanosecondo;
- Data e ora di creazione del file.
Il recupero dei dati, anche con detta versione del File System, è particolarmente ardua.
Pur utilizzando una tecnologia diversa da Ext3 basata sugli Extent, – cioè un gruppo di blocchi contigui invece del mapping dei blocchi indiretto – non cambia la la gestione dei puntatori che vengono comunque azzerati dopo la cancellazione di un file.
Oltre a ciò vi è un’ulteriore complicazione dovuta all’organizzazione dei File System di Linux in blocchi logici tramite la tecnologia LVM (Logical Volume Manager)[14].
Quindi il sistema oggetto di analisi, non si presenta come una passeggiata, anzi!
La necessaria e propedeutica carrellata degli aspetti tecnici più salienti ci consente di riepilogare brevemente la diversità tra i sistemi Windows e Linux.
Ma cosa c’è di realmente diverso in Linux rispetto a Windows, molto più conosciuto?
- Non vi è alcun registro;
- È necessario raccogliere le informazioni da fonti diverse e sparse;
- La struttura del File System è diversa;
- Non vi sono date di creazione file alla versione del File System nota come Ext4[15];
- I metadati importanti vengano azzerati con la cancellazione dei file;
- I file/dati sono per lo più composti da semplice testo;
- Ottimo per la ricerca di stringhe e l’interpretazione dei dati;
- Accesso complesso al File System data la presenza di Encryption, RAID, LVM (Logical Volume Manager)[16];
- Molteplici partizioni – anche nascoste – da montare.
Linux usa il kernel come un singolo grande processo eseguito interamente in un unico spazio di indirizzamento, rappresentato da un singolo file binario statico. Tutti i servizi del kernel vengono eseguiti nello spazio di indirizzamento dedicato ed è il kernel stesso a richiamare direttamente le sue funzioni.
Windows utilizza invece programmi e sottosistemi in modalità utente e quindi limitati in termini di risorse di sistema a cui si ha accesso, al contrario della modalità kernel che ha, invece, accesso illimitato alla memoria di sistema e ai dispositivi esterni.
Mi si perdonerà la spiegazione forse elementare dell’operatività insita nei due sistemi ma ritengo necessario farne comprendere la differenza senza inutili tecnicismi (kernel monolitico e kernel ibrido).
Quindi, dove cercare? Cosa analizzare? Quali artefatti tenere in considerazione?
L’analisi forense di un sistema GNU/Linux può essere davvero ardua e rappresentare una vera sfida per un esperto di Digital Forensics. Da un lato il sistema fornisce una grande quantità di informazioni rispetto ad un sistema Windows, dall’altro, la sua prerogativa di sistema aperto consente all’utente con privilegi di amministratore, la compilazione del kernel includendo tutte le patch che desidera, trasformando l’analisi in un incubo.
Per meglio comprendere le analogie con Windows, si adopererà una tabella che confronta la posizione di alcuni dei file rilevanti ai fini delle indagini nei due sistemi.
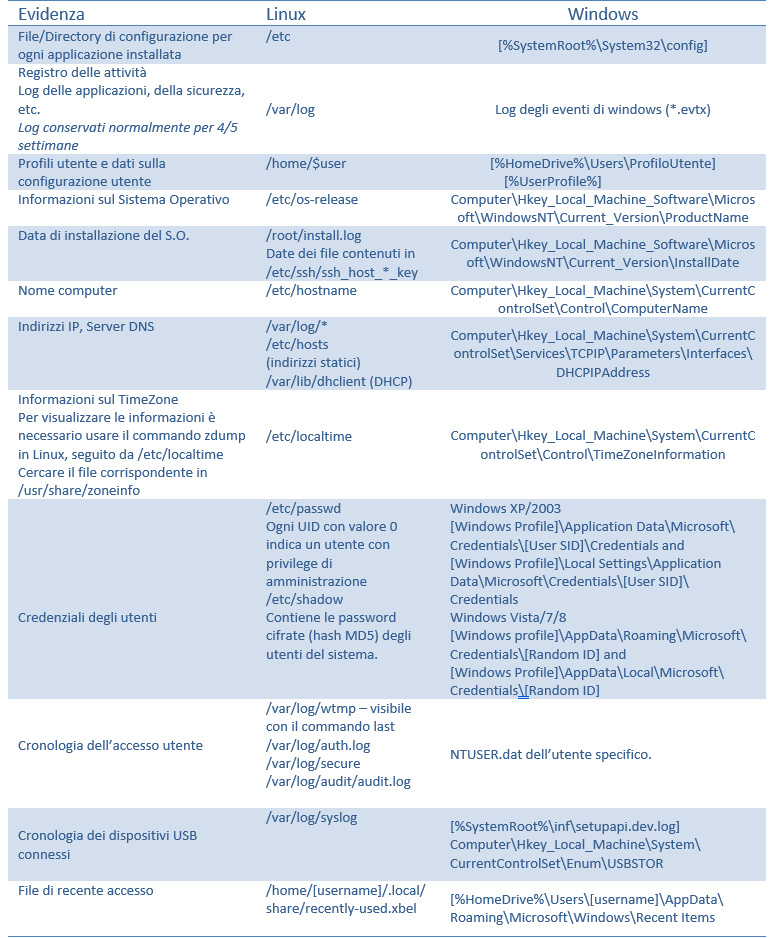
fig. 5
È consigliato quindi, prima di intraprendere l’analisi del sistema, porsi alcune semplici domande:
- Quando è stato installato il sistema operativo Linux?
- Quale distribuzione Linux è stata installata?
- L’orologio e la time zone della macchina erano corretti?
- Qual’era l’indirizzo IP della macchina al tempo dell’accadimento?
- Chi era connesso alla macchina in corrispondenza della data e ora segnalate?
- Sono stati riscontrati accessi al server Web del cliente identificati in base alla data e ora segnalate?
- Vi è una cronologia dei comandi digitati?
Va tenuto in debita considerazione che, la fase più importante dell’analisi del caso che viene affidato, è costituita proprio dai dati da acquisire e soprattutto dalla profonda conoscenza delle strutture utili al reperimento delle evidenze rilevanti.
Nel caso di dati volatili, si ha davvero una sola possibilità di acquisirli correttamente; è necessario quindi documentare attentamente tutte le operazioni sin dalla fase di acquisizione forense.
Ma come rispondere correttamente alle domande poste?[17]
Di seguito verranno fornite le risposte seguendo lo stesso ordine delle domande; a riferimento si è adoperata la distribuzione Ubuntu 14.01.1.
- La data di installazione del sistema operativo può essere estrapolata dal contenuto del file “/root/install.log” oppure dai file .key contenuti nella directory /etc/ssh;
- La versione del sistema operativo e le informazioni sulla release sono identificate dal contenuto del file “/etc/os-release”;
- Le informazioni sul fuso orario della macchina sono identificate dal contenuto del file “/etc/localtime”, adoperando l’output del comando zdump. Per ulteriore conferma è possibile ricercare il file nella directory “/usr/share/zoneinfo”;
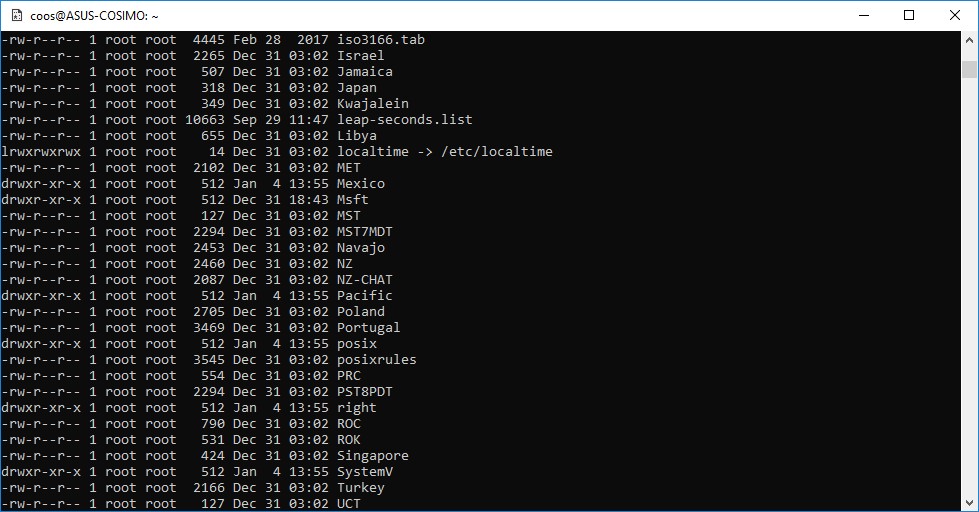
fig.6
- L’indirizzo IP della macchina è identificato dal contenuto del file “/etc/host” per gli indirizzi statici e dal contenuto dei file /etc/dhcp/dhclient.conf, /var/lib/dhclient/dhclient.leases,
/var/run/dhclient.pid, var/lib/dhclient/dhclient.leases~ per gli indirizzi dinamici (DHCP);
- I dettagli delle attività di accesso degli utenti sono identificati dal contenuto dei file “/var/log/wtmp e “/var/log/auth.log”;
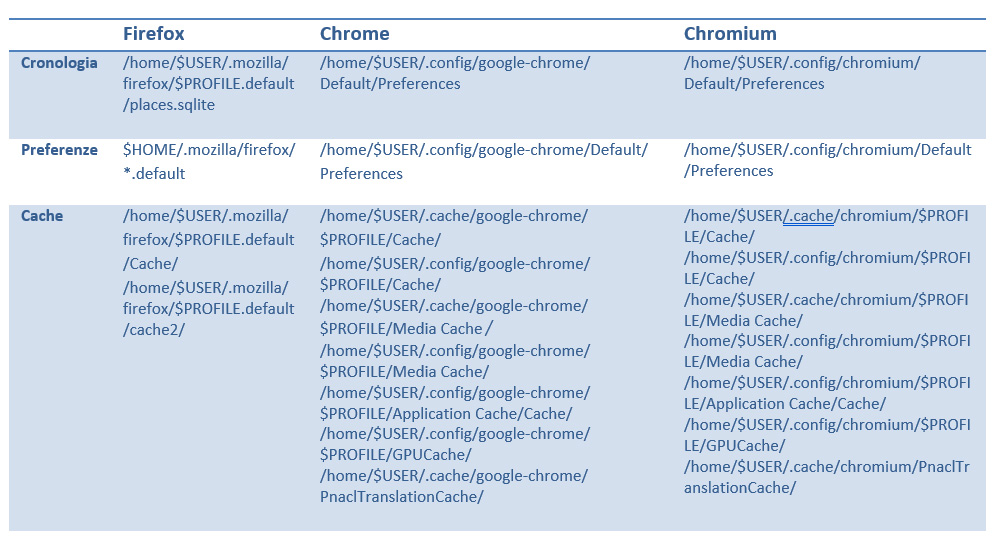
- I browser normalmente utilizzati sono Firefox e Chrome/Chromium. Gli artefatti di interesse sono identificati nel seguente modo:
- Il riepilogo dei dispositivi di archiviazione USB collegati è identificato dal contenuto del file “/var/log/syslog”. Le voci relative ai file recentemente utilizzati sono stati evidenziati dal contenuto di “/home/[username]/.local/share/recently-used.xbel”;
- La cronologia dei comandi digitati è rilevata dal contenuto del file “/home/[username]/.bash_history”. Non è possibile rilevarne i timestamp di esecuzione, dato che non è previsto di default. Va comunque tenuto in debito conto che la stessa cronologia può essere modificata o rimossa dall’utente. Nel caso di utilizzo di “sudo”, la cronologia può essere rinvenuta in “/var/log/auth.log” e “/var/log/sudo.log”.
Questi semplici quesiti consentono un iniziale approccio all’analisi forense del sistema Linux, avvalendosi successivamente dei molteplici strumenti a supporto delle indagini.La vera sfida che questi strumenti devono superare riguarda la necessità di non modificare o danneggiare, neanche minimamente o temporaneamente, nessuna delle periferiche che possono contenere dati sensibili.
Le distribuzioni forensi di Linux, quali ad esempio le italiane Caine, DeFT, la nuovissima TSURUGI o le straniere Paladin, Raptor, SIFT, Kali, Parrot e BlackBox consentono un’adeguata analisi e ricerca delle evidenze con ottimi tool automatici di ausilio.
Essi possono essere suddivisi in quattro macro-categorie:
- Tool di acquisizione: consentono l’acquisizione delle evidenze digitali da una macchina;
- Tool di analisi: consentono l’analisi delle evidenze ottenute in fase di acquisizione; a loro volta si suddividono in tool di analisi di basso livello e tool di analisi di alto livello; Fra i tool di analisi di alto livello è possibile individuare, inoltre, le seguenti categorie:
- Tool di cracking: consentono il recupero, a partire da un’evidenza cifrata, dell’evidenza originale e/o la password utilizzata per la cifratura;
- Tool integrati: supportano il consulente informatico forense nella ricerca, estrazione e stesura degli elaborati peritali, consentendogli il riporto, in modo dettagliato, delle informazioni rilevanti trovate.
Per l’analisi di ciò che è avvenuto sul sistema in esame, sono essenziali e indispensabili due strumenti: The Sleuth Kit basato su “The Coroner’s Toolkit” – https://www.sleuthkit.org – e log2timeline/Plaso – https://github.com/log2timeline/plaso/wiki/Using-log2timeline –
The Sleuth Kit e la sua estensione grafica Autopsy è ormai consolidato da anni e permette di eseguire la timeline del sistema basata sui metadati temporali del File System che, a mezzo dell’opzione “daily summary” consente anche la costruzione di un grafico (istogramma) contenente l’attività rilevata sul sistema durante ogni giorno e ad ogni ora del periodo selezionato. Autopsy ha funzione molto avanzate di gestione dei file, di analisi degli stessi – inclusi i file cancellati -, permettendo la visione degli stessi in diverse modalità, l’estrazione di immagini, l’analisi delle estensioni e del loro cambiamento.
Log2timeline con la nuova versione PLaso è uno strumento che permette l’estensione della timeline generata tramite TSK[18] aggiungendo attività ricavate da metadati o da informazioni interne ai file, quali ad esempio dati exif[19], di registro, eventi di sistema, log di antivirus, journaling NTFS, storia della navigazione internet, etc., consentendo un’agevole analisi degli accadimenti molto più precisa e puntale.
Un tool da non sottovalutare è Bulk Extractor, un software open source sviluppato da Simson L. Garfinkel, professore e ricercatore californiano, autore tra l’altro di altri utili progetti relativi alla computer forensics. Il software consente l’estrazione di mail, artefatti facebook, indirizzi e domini web, numeri di telefono, carte di credito, prefetch, indirizzi ip e molto altro ancora. Tramite accesso sequenziale a livello di settore, Bulk Extractor è in grado di estrarre da dischi, immagini forensi o directory di file, informazioni utili per gli investigatori senza la necessità di dover accedere al File System sottostante. Oltre al rilevamento delle informazioni direttamente disponibili sul disco durante il “parsing”, Bulk Extractor è in grado di rilevare, decomprimere e processare ricorsivamente i dati contenuti all’interno di archivi compressi con svariati algoritmi. Il software consente quindi accesso alle analisi dei contenuti dei vari file zip rar e via dicendo presenti nelle aree allocate e non allocate del sistema. Anche per questo aspetto, se non opportunamente configurati, diversi tool commerciali rischiano di trascurare informazioni rilevanti non parsificando gli archivi.
Il software produce delle “Feature Files”, ovvero dei file suddivisi per tipologia di dati estratti e contenenti le informazioni ritrovate. In fig. 7 è riportato un esempio di contenuto del “Feature File” denominato “domain.txt”:

Fig.7
Infine, per quanto riguarda il recupero di dati cancellati su sistemi Linux, ricordiamo Testdisk/Photorec, Scalpel e Foremost.
Testdisk permette di ricostruire partizioni danneggiate di qualsiasi tipo, indispensabile per la ricostruzione di supporti danneggiati.
Photorec consente il recupero dei file cancellati dalle aree di memoria non allocate. Il recupero utilizza la cosiddetta tecnica di carving, basata sulle firme dei file.
Foremost è il più famoso tool di carving su Linux, in grado di lavorare su file immagine (dd, Ewf, etc.) oppure direttamente sul dispositivo. Gli Header e i footer dei file da ricercare possono essere specificati nei file di configurazione o attraverso parametri della riga di comando. Una volta in esecuzione crea nella directory di output un file denominato “audit.txt” ed una serie di sub directory nominate con il tipo di file ritrovato (doc, jpg, tiff, etc.).
Scalpel è stato riscritto a partire da Foremost onde consentire un miglioramento di performance e riduzione dell’utilizzo di memoria. Nel caso di Scalpel, i file da identificare devono essere specificati nel file di configurazione “/etc/scalpel/scalpel.conf”.
Bene, per ora è tutto. Stay Tuned.
Note
Articolo a cura di Cosimo De Pinto

https://www.ictsecuritymagazine.com/articoli/analisi-forense-di-sistemi-linux/