

Facebook began measuring the prevalence of hate speech on its platform globally in the November 2020 edition of its Community Standards Enforcement Report, pegging it at 0.10% to 0.11%, or 10 to 11 views of hate speech for every 10,000 views of content.
Vice president of integrity Guy Rosen said in a Newsroom post Thursday that Facebook’s investments in artificial intelligence have helped it to proactively detect hate speech content on its platform before it is reported by users.
Rosen said during a press call Thursday, “Think of prevalence like an air quality test to determine the percentage of pollutants.”
Facebook product manager for integrity Arcadiy Kantor went into further detail in a separate Newsroom post, explaining that the social network calculates prevalence by selecting a sample of content that was seen on Facebook and labeling how much of that content violates its hate speech policies.
In order to account for language and cultural context, these samples are sent to content reviewers across different languages and regions.
Kantor pointed out that the amount of times that content is seen is not evenly distributed, writing, “One piece of content could go viral and be seen by lots of people in a very short amount of time, whereas other content could be on the internet for a long time and only be seen by a handful of people.”
He also detailed the challenges of determining what constitutes hate speech, writing, “We define hate speech as anything that directly attacks people based on protected characteristics including race, ethnicity, national origin, religious affiliation, sexual orientation, sex, gender, gender identity or serious disability or disease,” but adding, “Language continues to evolve, and a word that was not a slur yesterday may become one tomorrow. This means content enforcement is a delicate balance between making sure we don’t miss hate speech while not removing other forms of permissible speech.”
Facebook continues to use a combination of user reports and AI to detect hate speech on Facebook and Instagram, and Kantor addressed the challenges the company faces with the human part of that equation, such as people from areas with lower digital literacy not being aware that they can report content, or people reporting content that they don’t like, but that doesn’t violate Facebook’s policies, such as TV show spoilers or posts about rival sports teams.
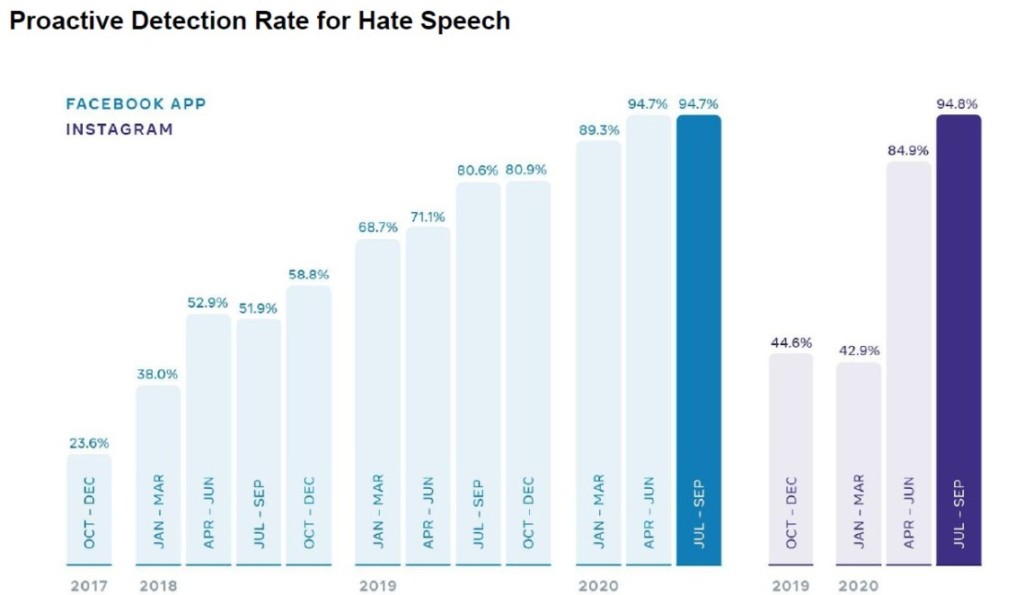
As for AI, he wrote, “When we first began reporting our metrics for hate speech, in the fourth quarter of 2017, our proactive detection rate was 23.6%. This means that of the hate speech we removed, 23.6% of it was found before a user reported it to us. The remaining majority of it was removed after a user reported it. Today, we proactively detect about 95% of hate speech content we remove. Whether content is proactively detected or reported by users, we often use AI to take action on the straightforward cases and prioritize the more nuanced cases, where context needs to be considered, for our reviewers.”
Those content moderators may beg to differ, however, as an open letter sent Wednesday by over 200 of them blasted Facebook’s AI systems, saying, “Management told moderators that we should no longer see certain varieties of toxic content coming up in the review tool from which we work—such as graphic violence or child abuse, for example. The AI wasn’t up to the job. Important speech got swept into the maw of the Facebook filter—and risky content, like self-harm, stayed up. The lesson is clear. Facebook’s algorithms are years away from achieving the necessary level of sophistication to moderate content automatically. They may never get there.”
https://www.adweek.com/digital/facebook-hate-speech-accounts-for-10-or-11-of-every-10000-pieces-of-content-viewed/