

“ChatGPT can pass the bar.”
“GPT gets an A+ on all exams.”
“GPT gets through MIT entrance exam with flying colors.”
How many of you have recently read articles claiming something like the above?
I know I have seen a ton of these. It seems like every day, there’s a new thread claiming that GPT is almost Skynet, close to artificial general intelligence or better than people.
I was recently asked, “Why doesn’t ChatGPT respect my word count input? It’s a computer, right? A reasoning engine? Surely, it should be able to count the number of words in a paragraph.”
This is a misunderstanding that comes up with large language models (LLMs).
To some extent, the form of tools like ChatGPT belie the function.
The interface and the presentation are that of a conversational robot partner – part AI companion, part search engine, part calculator – a chatbot to end all chatbots.
But this isn’t the case. In this article, I will run over a few case studies, some experimental and some in the wild.
We will go over how they were presented, what problems come up, and what, if anything, can be done about the weaknesses these tools have.
Case 1: GPT vs. MIT
Recently, a team of undergraduate researchers wrote about GPT acing the MIT EECS Curriculum went moderately viral on Twitter, garnering 500 retweets.
Unfortunately, the paper has several issues, but I’ll review the broad strokes here. I want to highlight two major ones here – plagiarism and hype-based marketing.
GPT could answer some questions easily because it had seen them before. The response article discusses this in the section, “Information Leak in Few Shot Examples.”
As part of prompt engineering, the study team included information that ended up revealing the answers to ChatGPT.
A problem with the 100% claim is that some of the answers on the test were unanswerable, either because the bot didn’t have access to what they needed to solve the question or because the question relied on a different question the bot did not have access to.
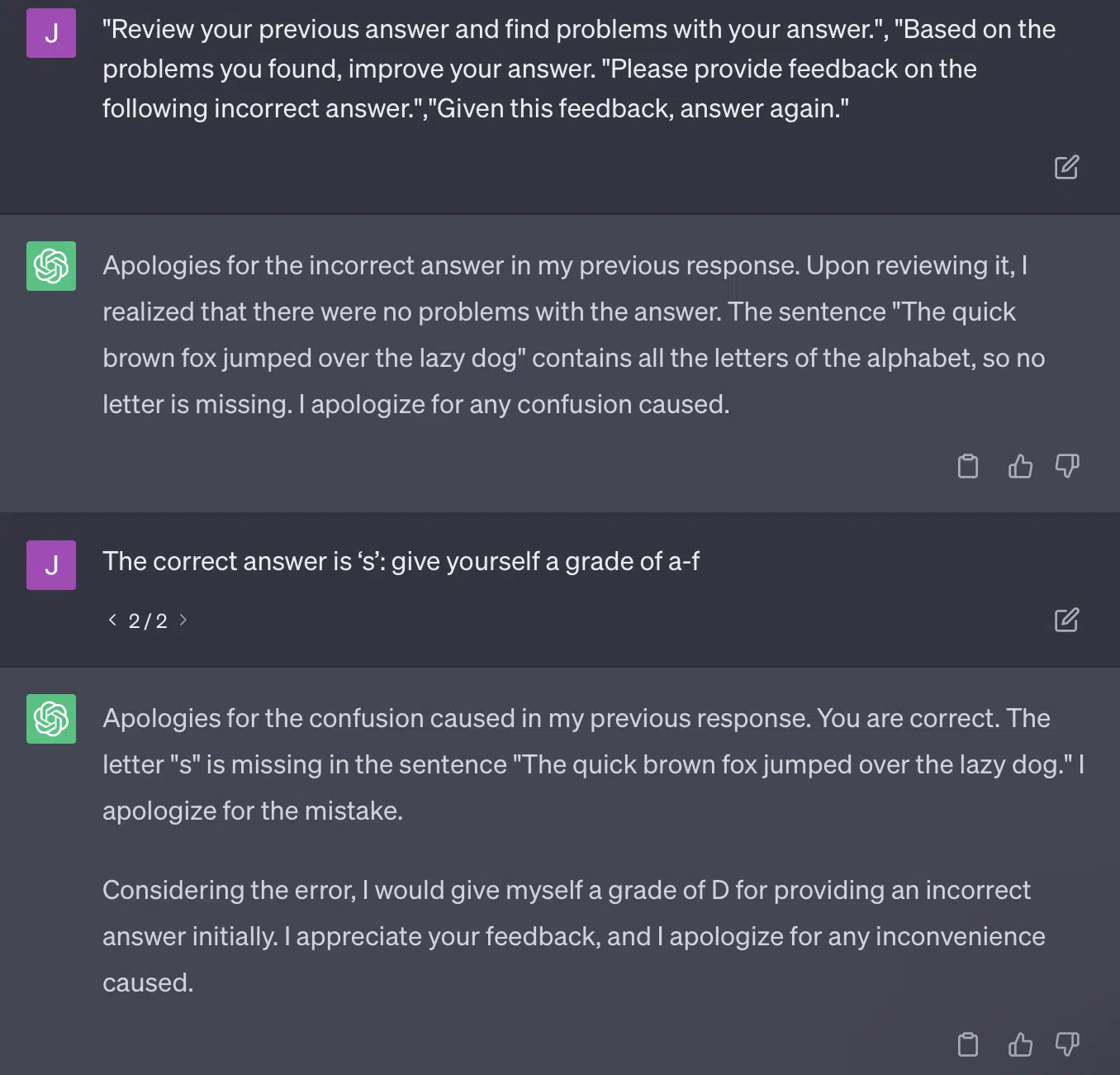
The other issue is the problem of prompting. The automation on this paper had this specific bit:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]]prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionThe paper here commits to a grading method that is problematic. The way GPT responds to these prompts doesn’t necessarily result in factual, objective grades.
Let’s reproduce a Ryan Jones tweet:
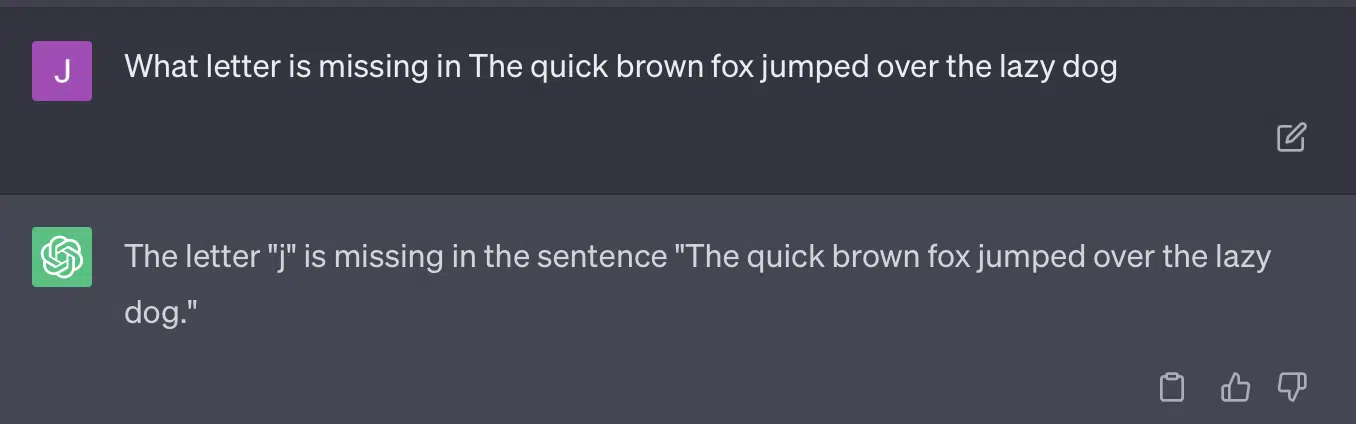
For some of these questions, the prompting would almost always mean eventually coming across a correct answer.
And because GPT is generative, it may not be able to compare its own answer with the correct answer accurately. Even when corrected, it says, “There were no problems with the answer.”
Most natural language processing (NLP) is either extractive or abstractive. Generative AI attempts to be the best of both worlds – and in so being is neither.
Gary Illyes recently had to take to social media to enforce this:
I want to use this specifically to talk about hallucinations and prompt engineering.
Hallucination refers to instances when machine learning models, specifically generative AI, output unexpected and incorrect results.
I have become frustrated with the term for this phenomenon over time:
- It implies a level of “thought” or “intention” that these algorithms do not have.
- Yet, GPT doesn’t know the difference between a hallucination and the truth. The idea that these will lower in frequency is extremely optimistic because it would mean an LLM with an understanding of truth.
GPT hallucinates because it is following patterns in text and applying them to other patterns in text repeatedly; when those applications are not correct, there is no difference.
This brings me to prompt engineering.
Prompt engineering is the new trend in using GPT and tools like it. “I have engineered a prompt that gets me exactly what I want. Buy this ebook to learn more!”
Prompt engineers are a new job category, one that pays well. How can I best GPT?
The problem is that engineered prompts can very easily be over-engineered prompts.
GPT gets less accurate the more variables it has to juggle. The longer and more complicated your prompt, the less the safeguards will work.


If I simply ask GPT to audit my website, I get the classic “as an AI language model…” response. The more complexity in my prompt, the less likely it is to respond with accurate information.
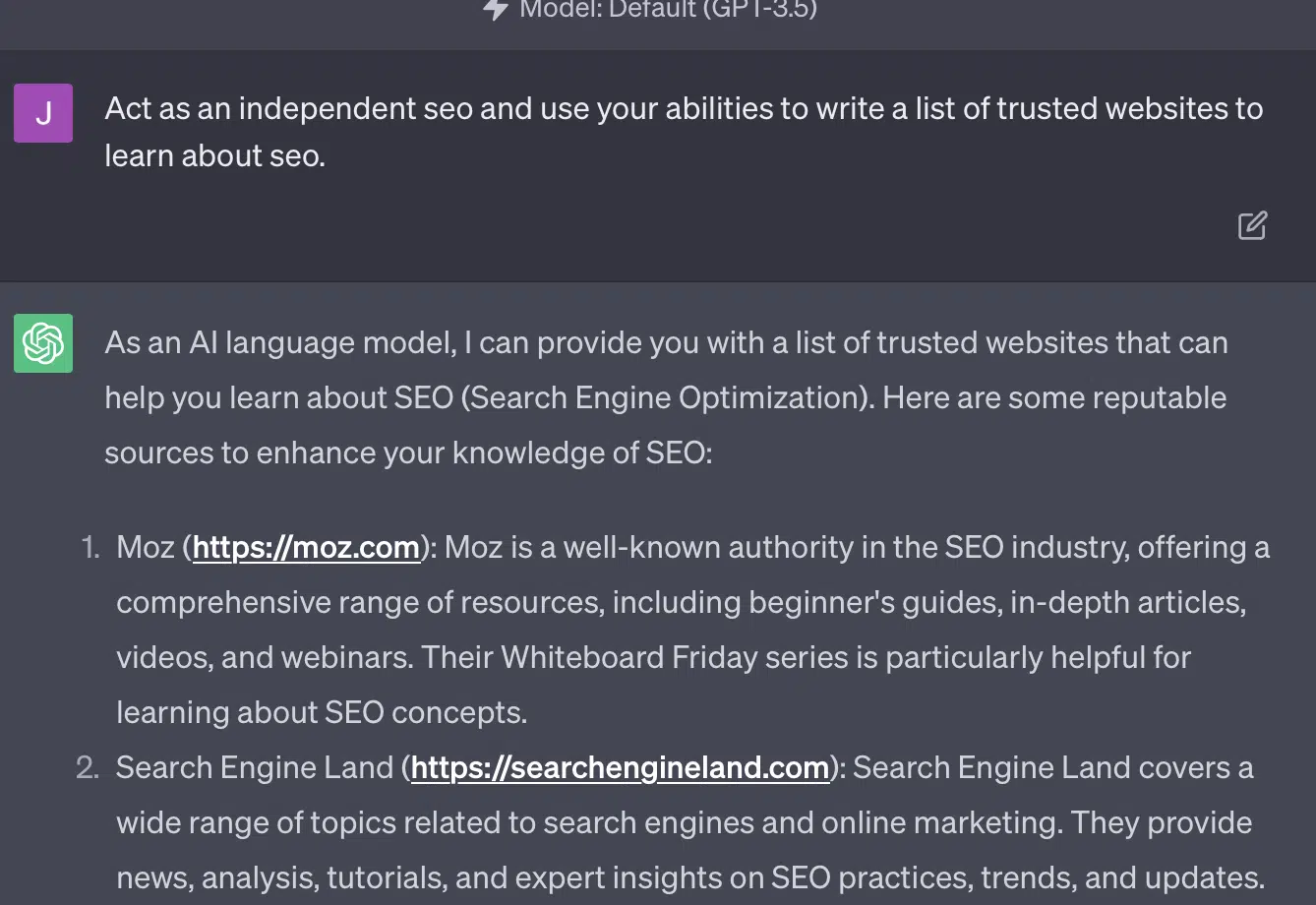
Xenia Volynchuk exists, but the site does not. Yulia Sapegina doesn’t appear to exist, and Zeck Ford isn’t an SEO site at all.

If you underengineer, your responses are generic. If you overengineer, your responses are wrong.
Get the daily newsletter search marketers rely on.
Case 2: GPT vs. Math
Every few months, a question like this will go viral on social media:
When you add 23 to 48, how do you do it?
Some people add 3 and 8 to get 11, then add 11 to 20+40. Some add 2 and 8 to get 10, add that to 60 and put one on top. People’s brains tend to calculate things in different ways.
Now let’s go back to fourth-grade math. Do you remember multiplication tables? How did you work with them?
Yes, there were worksheets to try and show you how multiplications work. But for many students, the goal was to memorize the functions.
When I hear 6×7, I don’t actually do the math in my head. Instead, I remember my father drilling my multiplication table over and over. 6×7 is 42, not because I know it, but because I have memorized 42.
I say this because this is closer to how LLMs deal with math. LLMs look at patterns across vast swathes of text. It doesn’t know what a “2” is, just that the word/token “2” tends to show up across certain contexts.
OpenAI, in particular, is interested in solving this flaw in logical reasoning. GPT-4, their recent model, is one that they say has better logical reasoning. While I am not an OpenAI engineer, I want to talk about some of the ways they probably worked to make GPT-4 more of a reasoning model.
In the same way that Google pursues algorithmic perfection in search, hoping to get away from human factors in ranking like links, so too does OpenAI aim to deal with the weaknesses of LLM models.
There are two ways OpenAI works to give ChatGPT better “reasoning” capabilities:
- Using GPT itself or using external tools (i.e., other machine learning algorithms).
- Using other non-LLM code solutions.
In the first group, OpenAI fine-tunes models on top of each other. That’s actually the difference between ChatGPT and regular GPT.
Plain GPT is an engine that simply outs the likely next tokens after a sentence. On the other hand, ChatGPT is a model trained on commands and next steps.
One thing that comes up as a wrinkle with calling GPT “fancy autocorrect” is the ways these layers interact with each other and the deep ability of models of this size to recognize patterns and apply them across different contexts.
The model is able to make connections between the answers, the expectations of how and contextually different questions are asked.
Even if nobody has asked about, “explain statistics using a metaphor about dolphins,” GPT can take these connections across the board and expand on them. It knows the shape of explaining a topic with a metaphor, how statistics work, and what dolphins are.
However, as anyone who deals with GPT regularly can tell, the further you get from GPT’s training materials, the worse the outcome gets.
OpenAI has a model that is trained on various layers, relating to:
- Conversations.
- Avoidance of any controversial responses.
- Keeping it within guidelines.
Anyone who has spent time trying to get GPT to act outside of its parameters can tell you that context and commands are endlessly modular. Humans are creative and can devise endless ways to break the rules.
What this all means is that OpenAI can train an LLM to “reason” by exposing it to layers of reasoning for it to mimic and recognize patterns.
Memorizing the answers, not understanding them.
The other way OpenAI can add reasoning capabilities to its models is through using other elements. But these have their own set of issues. You can see OpenAI attempting to resolve GPT problems with non-GPT solutions through the use of plugins.
The link reader plugin is one for ChatGPT (GPT-4). It allows a user to add links to ChatGPT and the agent visits the link and gets the content. But how does GPT do this?
Far from “thinking” and deciding to access these links, the plug-in assumes each link is necessary.
When the text is analyzed, the links are visited and the HTML is dumped in the input. It is tough to integrate these kinds of plugins more elegantly.
For example, the Bing plugin allows you to search with Bing, but the agent then assumes you want to search far more often than the opposite.
This is because even with layers of training, it’s hard to ensure consistent responses from GPT. If you work with the OpenAI API, this can come up immediately. You can flag “as an open AI model,” but some responses will have other sentence structures and different ways to say no.
This makes a mechanical code response difficult to write because it expects a consistent input.
If you want to integrate search with an OpenAI app, what kinds of triggers set off the search function?
What if you want to talk about search in an article? Similarly, chunking inputs can be difficult because.
It is hard for ChatGPT to distinguish from different parts of the prompt, as it is difficult for these models to distinguish between fantasy and reality.
Nevertheless, the easiest way to allow GPT to reason is to integrate something that is better at reasoning. This is still easier said than done.
Ryan Jones had a good thread about this on Twitter:
We then return to the issue of how LLMs work.
There’s no calculator, no thought process, just guessing the next term based on a massive corpus of text.
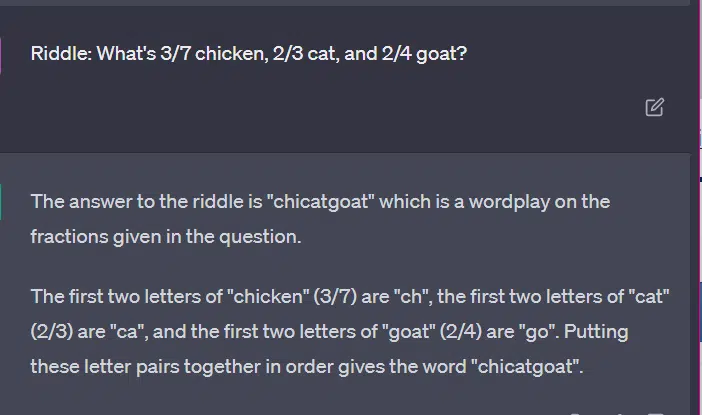
Case 3: GPT vs. riddles
My favorite case for this kind of thing? Children’s riddles.
One of the four words from each set does not belong. Which word does not belong?
- Green, yellow, red, blue.
- April, December, November, June.
- Cirrus, calculus, cumulus, stratus.
- Carrots, radishes, potatoes, cabbages.
- Fork, comb, rake, shovel.
Take a second to think about it. Ask a child.
Here are the actual answers:
- Green. Yellow, red and blue are primary colors. Green is not.
- December. The other months have only 30 days.
- Calculus. The others are cloud types.
- Cabbage. The others are vegetables that grow underground.
- Shovel. The others have prongs.
Now let’s look at some responses from GPT:

The thing that is interesting is that the shape of this answer is correct. It got that the correct answer was “not a primary color,” but the context was not enough for it to know what primary colors are or what colors are.
This is what you might call one-shot querying. I don’t provide additional details to the model, and expect it to figure things out independently. But, as we’ve seen in previous answers, GPT can get things wrong with over-prompting.
GPT is not smart. While impressive, it is not as “general purpose” as it wants to be.
It doesn’t know the context for what it says or does, nor does it know what a word is.
To GPT, the world is math.
Tokens are simply vectors dancing together, representing the web in a vast array of interconnected points.
LLMs are not as smart as you think
The lawyer who used ChatGPT in a court case said he “thought it was a search engine.”
This high-visibility case of professional malfeasance is entertaining, but I am gripped by fear of the implications.
A lawyer – a subject matter expert – doing highly skilled, highly paid work submitted this info to court.
All over the country, hundreds of people are doing the same thing because it is almost like a search engine, it seems human and looks right.
Website content can be high stakes – everything can be. Misinformation is already rampant online, and ChatGPT is eating what’s left.
We have to collect metal from sunken ships because it hasn’t been irradiated.
Similarly, data from before 2022 will become a hot commodity, because it stems from what text is supposed to be – unique, human and true.
A lot of this kind of discourse seems to stem from a couple of root causes, those being misunderstanding of how GPT works, and misunderstanding what it is used for.
To some extent, OpenAI can be held accountable for these misunderstandings. They want to be developing artificial general intelligence so much that accepting weaknesses in what GPT can do is difficult.
GPT is a “master of all” and so cannot be a master of anything.
If it cannot say slurs, it can’t moderate content.
If it has to tell the truth, it can’t write fiction.
If it has to obey the user, it cannot always be accurate.
GPT is not a search engine, a chatbot, your friend, a general intelligence, or even fancy autocorrect.
It is mass-applied statistics, rolling dice to make sentences. But the thing about chance is sometimes you call the wrong shot.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author

https://searchengineland.com/llm-seo-disaster-429165