

In questo articolo analizzeremo cosa significhi proteggere la nostra privacy, prendendo in considerazione alcuni possibili comportamenti perpetrati da soggetti definiti, qui, semplicemente “attaccanti.” Cercheremo di capire quali dati possano costituire un rischio e come fare per non divulgarli. Inoltre guarderemo la questione “lato attaccante”, per capire cosa farà dei nostri dati e perché potrebbe essere nocivo. Le basi tecniche cui faremo riferimento sono il world wide web – ipertesto consultabile attraverso un browser – e il fatto che certe pagine web non siano accessibili a chiunque ma richiedano un’autenticazione (spesso: username e password).
QUALI DATI PRIVATI È POSSIBILE REPERIRE IN RETE?
Di ogni tipo: per rendercene conto, basta inserire in un moderno motore di ricerca (Google, Bing, ecc.) alcune semplici parole chiave come “carta d’identità”, “documento”, “passaporto” o “denuncia”, selezionando i risultati di tipo “immagine”. Oltre a immagini di volti, possiamo facilmente reperire nomi, indirizzi, numeri di telefono, codici fiscali… il che, in un mondo onesto, non costituirebbe un problema. Ma il mondo pullula di disonesti.
Si potrà dire: i proprietari li hanno messi in rete e nella maggioranza dei casi sapevano quello che facevano. Non sono del tutto d’accordo, soprattutto relativamente alle conseguenze indirette, di cui discuteremo.
Inoltre, la pubblicazione sul web non è l’unica sorgente di dati personali; questi possono essere condivisi in molti modi, per esempio usando una rete sociale (Instagram, Facebook, TikTok ecc.) che a sua volta si poggia sul web, con una differenza che deriva da quella esistente fra surface web e deep web.
Appartengono al surface web tutti i siti che possono essere consultati da un motore di ricerca; appartengono al deep web (da non confondere con il dark web) i siti che non possono essere raggiunti da un motore di ricerca per vari motivi, uno dei quali è la necessità di sapersi autenticare. Per completezza, aggiungiamo che appartengono al dark web tutti i siti che offrono pagine web attraverso una “overlay network” (rete sovrapposta) come la rete Tor e che possono essere consultati esclusivamente tramite il Tor browser; non essendo questi raggiungibili da un normale motore di ricerca, tecnicamente appartengono al deep web (che naturalmente non si esaurisce nel dark web).
Precisata la differenza, c’è da dire che un enorme quantitativo di dati personali è affidato al deep web e, almeno in linea di principio, non disponibile alla visione di chiunque. Si tratta spesso di foto e video che appartengono alla sfera più privata, incluso il fatto che spesso includono volti di minori (cosa che in teoria dovrebbe essere soggetta ad autorizzazione). Dati protetti, dunque? La risposta, purtroppo, è no. Anche assumendo che i server che realizzano la rete sociale – chiamiamola S – non siano e non saranno compromessi, rimane il fatto che gli “amici” ottenuti attraverso la rete sociale possono spesso visualizzare tali informazioni.
Facciamo chiarezza. Assumiamo che S, attenta alla privacy e moderna, divida il pubblico, rispetto a un utente X, in più fasce:
A. quella con cui si condividono contenuti soggetti a selezione;
B. quella degli amici stretti con cui si condivide tutto, con qualche possibile eccezione;
C. quella degli utenti di S (inclusi i non amici di X), con si può scegliere di condividere qualcosa;
D. il resto del mondo (che include i non iscritti a S), con cui si condivide ciò che si reputa pubblico.
Anche supponendo che un utente possa configurare e caratterizzare completamente le fasce A, B, C e D, quanti saranno disposti a farlo? In molti casi prevarranno le impostazioni di default scelte dall’applicazione. Anche se i comportamenti di default saranno privacy preserving (non sempre è così!) è comunque compito di X definire le eccezioni, sia in positivo che in negativo, e non è scontato che X lo faccia. Ci sono poi reti sociali in cui la privacy è, a causa dello scopo della rete, poco attuata dagli utenti (es. LinkedIn, app di dating).
Inoltre, poche reti sociali consentono a X di definire i permessi di visione agli “amici degli amici”. Il che si traduce nel fatto che, per quanto attenti possiamo essere nel concedere gli accessi, dipenderemo spesso dai comportamenti dei nostri contatti. Ad esempio, supponiamo di voler tenere privato il numero di cellulare, per cui lo diamo solo a pochi contatti stretti: cosa ci garantisce rispetto alla richiesta automatica di WhatsApp, Signal o Line di accedere alla rubrica? Può darsi che gli amici stretti consegneranno a queste app la loro rubrica, per non parlare del fatto che potrebbero decidere di dare il nostro numero a qualcuno senza consultarci in proposito.
Dal lato dell’attaccante, è possibile reperire dati sia attraverso un motore di ricerca, sia diventando utente di una rete sociale e ottenendone dati che diventano così accessibili: questo può essere fatto sia di persona, sia usando una specifica applicazione. Una delle tecniche più antiche, ma ancora attuali, è prendere contatto con un uomo attraverso un profilo social che mostra la foto di una donna avvenente: pochi sapranno resistere alla tentazione di accogliere una nuova amica attraente.
COME SONO CEDUTI I DATI?
In realtà ciò è stato discusso nella Sez. 1. Tuttavia, non abbiamo ancora menzionato un fatto centrale e ricorrente. Siamo tutti utenti del web, a prescindere dalle reti sociali: e i siti web vorrebbero sapere alcune informazioni di base sugli utenti, per migliorare gli avvisi pubblicitari da mostrare (ad esempio, appare un po’ goffo mostrare a un uomo avvisi destinati a un pubblico femminile). Ecco che nascono alcune domande di base, quali sesso, fascia di età, malattie croniche, vizi, bisogno di credito/mutui, composizione del nucleo familiare ecc. Tutto – o quasi – è considerato lecito al fine di acquisire queste informazioni, che nella maggior parte dei casi saranno trattate in maniera automatica.
Un meccanismo di base che spicca fra gli altri è quello dei cookies. Come noto, il protocollo per l’acquisizione dei file che caratterizzano il contenuto di un sito è http, un protocollo stateless (senza memoria). Per ovviare a tale limite (talvolta tecnicamente rilevante) è stato introdotto il meccanismo dei cookies:
- un server web, nel trasmettere informazioni a un browser, può decidere autonomamente di inviare dei frammenti di informazione (spesso dei numeri) chiamati appunto cookies. Ovviamente il server conterrà una tabella che associa a ciascun numero varie informazioni;
- il browser riceve i cookies e, se non espressamente istruito a fare diversamente, li conserva fino a una data di scadenza (spesso più lontana della data media di dismissione del dispositivo). Il cookie spesso descrive la pagina di attuale visualizzazione;
- il browser, nel mandare una richiesta qualunque a un server web, controlla se conservi cookies non scaduti provenienti da quel server e, se sì, li invia al server assieme alla richiesta;
- lo scambio di cookies fra server e browser avviene di norma silenziosamente, senza che l’utente ne abbia percezione. Il numero di cookies ricevuto da un browser in un giorno di navigazione può facilmente raggiungere diverse migliaia;
- ogni browser possiede un “contenitore” in cui depositare e da cui attingere cookies;
- tale contenitore è diverso da browser a browser e da utente ad utente (anche se condividono lo stesso dispositivo).
Inoltre occorre tenere presente che, se si visita il sito W, questo offrirà presumibilmente contenuti provenienti da altri siti, diciamo Y e Z. Per tale ragione W si chiama “first party” (prima parte) e Y e Z si chiamano “third parties” (terze parti). Non è difficile comprendere che i cookies ricevuti da siti di terze parti servono principalmente a queste ultime per ricostruire informazioni sull’attività di navigazione di un utente e, in particolare, sui contenuti consultati. Invece i cookies di prima parte hanno spesso una valenza tecnica, conservando informazioni su un’avvenuta autenticazione e su una preferenza di navigazione. In definitiva, è consigliabile l’approccio basato sul configurare il browser in modo che rifiuti automaticamente i cookies di terze parti (è possibile, anche se talvolta va cercato). Il meccanismo che contempla pagine composte da contenuti provenienti da diversi siti fa sì che nascano relazioni fra siti, che possono portare alla condivisione di informazioni. La Figura 1 mostra le relazioni fra siti visitati in quasi un anno da parte dell’autore; in Figura 2 ne è mostrato un frammento.
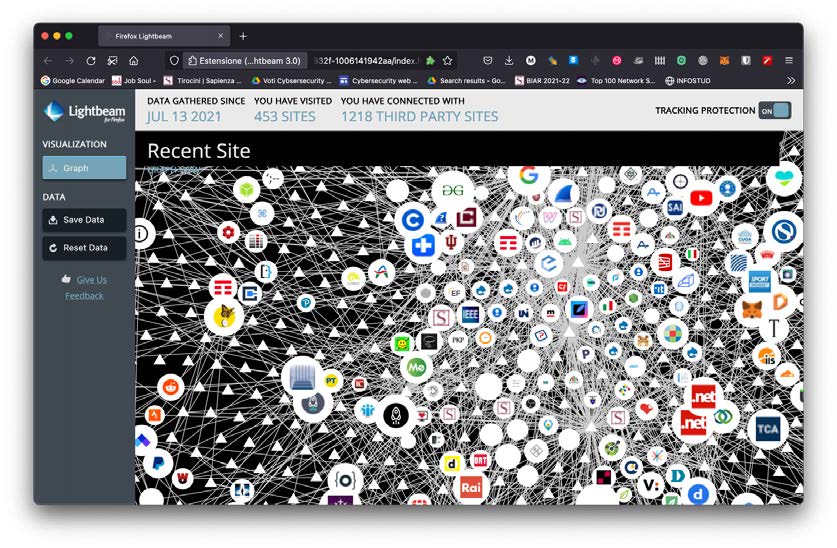
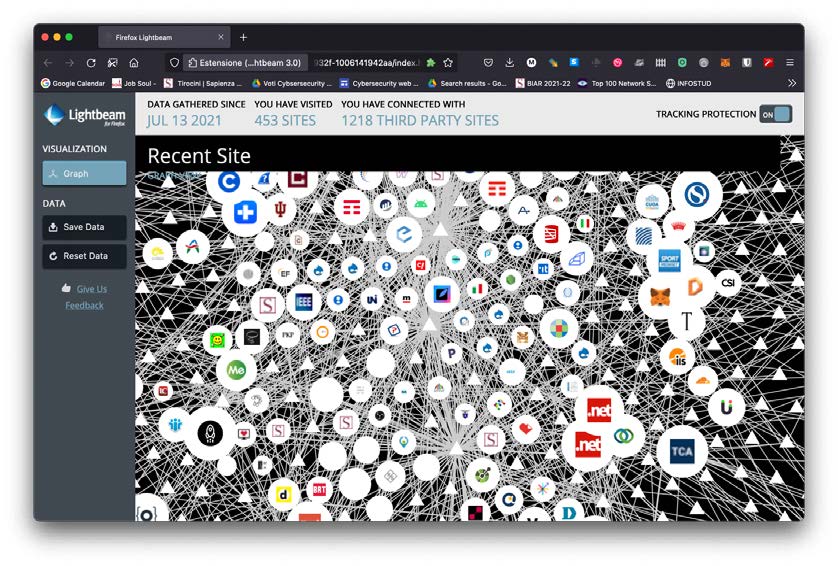
Oggi sono molti gli add-on (componenti aggiuntivi) disponibili per dotare un browser di una migliore capacità di controllo dei cookies; non approfondiremo questo dettaglio, privilegiando i concetti di base. Inoltre ci sono molti browser, ciascuno con una sensibilità diversa rispetto alla tutela della riservatezza dei dati degli utenti. Fra questi prevale, ai fini del controllo della privacy, quello prodotto da Mozilla e noto con il nome di Firefox. I web server usano anche altri meccanismi di tracciamento, talvolta molto più tecnici, che giustificano il ricorso alla modalità di navigazione chiamata privata o anonima.
Si tratta di una modalità nata nel passato per obiettivi differenti, che oggi offre ancora alcuni aspetti interessanti. La modalità privata non lo è davvero (il server web riceve ugualmente il nostro IP), tuttavia in questa modalità i browser allestiscono un nuovo contenitore per i cookies (e per altre informazioni) che nasce vuoto e durante la navigazione riceve tutti i cookies somministrati, anche fornendoli, ma che viene distrutto alla chiusura del browser, perdendo automaticamente tutti i dati collezionati. In questo modo renderà vana la somministrazione di cookies di qualunque tipo, inclusi quelli “buoni” (es., autenticazione avvenuta).
QUALE CESSIONE DATI È DA CONSIDERARSI RISCHIOSA E PERCHÉ?
Dalle riflessioni precedenti capiamo facilmente la molteplicità dei meccanismi che consentono all’attaccante di collezionare i nostri dati. A questi vanno aggiunti quelli di esfiltrazione, che attaccano un server per estrarne i dati contenuti: in particolare, le password. In effetti il riuso delle password, pratica prediletta da molti utenti, favorisce fortemente il furto d’identità, in cui l’attaccante può impersonare la vittima e agire passivamente o attivamente in sua vece. Esistono varie tipologie di furto di identità; ed è abbastanza pacifico che sebbene i meccanismi lesivi della privacy discussi in Sez. 2 possano essere fastidiosi, condizionando la pubblicità ricevuta, di norma non conducono a furti di identità. Tuttavia, ci sono stati casi emblematici in cui giganti del web sono incorsi in famosi scandali unendo tecniche disparate: ad esempio il caso Facebook-Cambridge Analytica, ove i dati di 87 milioni di utenti FB furono usati con scopi di propaganda politica.
In effetti sembrerebbe naturale domandarsi se i meccanismi illustrati in Sez. 2 non potrebbero essere sfruttati dalle forze dell’ordine a fini investigativi, o trovare addirittura applicazioni forensi. Se da un lato appare scontato che la disponibilità dei dati presso i siti che effettuano tracciamento costituisca un patrimonio di indubbio interesse che potrebbe facilitare analisi, profilazione psicologica, valutazioni ecc., dall’altro dobbiamo prendere atto che il concetto di confine nazionale, per quanto riguarda la rete, ha perso ogni significato. Così assistiamo ad aziende od organizzazioni che si trovano in uno Stato, ma che conservano i dati su qualche server localizzato in altro Stato. Ne deriva la difficoltà, per le forze dell’ordine, di ottenere tali dati, rendendosi in genere necessarie rogatorie internazionali dai tempi lunghi (poco compatibili con quelli dell’investigazione) e dagli esiti incerti. Questo perché manca una legislazione comune di valenza internazionale, anche se la UE ha recentemente fatto significativi passi avanti in tal senso. Eppure, la magistratura dello Stato ove risiedano i dati potrebbe ordinarne sequestro ed esportazione, chiarendo che in caso di cifratura c’è l’obbligo di fornirne le chiavi.
Più significativa per i nostri scopi è invece la valenza degli atti descritti in Sez. 1, nonché dell’esfiltrazione della password.
Va premesso che in generale esistono due tipi di attacco informatico: “a pioggia” e “mirato”. Nei primi si è attaccati per il semplice fatto di essere utenti di Internet; nei secondi invece l’attacco è legato al nostro ruolo, status o funzione e integra un’azione espressamente studiata per noi. Va detto che il rapporto fra questi è dell’ordine di 100 a 1: ne consegue che la somma dei danni provocati dagli attacchi a pioggia diventa considerevole sul piano quantitativo mentre, nel caso degli attacchi mirati, questi possono produrre danni ingenti in ragione della loro maggiore “qualità”.
In aggiunta, gli attacchi mirati sono molto onerosi – non molti possono permettersi i costi necessari alla progettazione – e pertanto sono solitamente imputabili a gruppi motivati e ben organizzati, talvolta anche a governi nazionali. Qui ci concentreremo solamente sugli attacchi a pioggia poiché, nella situazione evocata dal titolo, le vittime sono persone “qualsiasi” che ritengono di non aver nulla da nascondere.
Mettiamoci nei panni di un attaccante che dedica tempo e sforzi per realizzare attacchi a pioggia (usando i meccanismi descritti in Sez. 1), eventualmente resi più efficaci da password o dati esfiltrati in seguito a qualche attacco a server. L’attaccante colleziona dunque dati ottenuti con questi meccanismi, correlando le varie informazioni relative allo stesso soggetto: in Figura 3, l’esito di una semplice ricerca su un celebre social. Nel tempo, i dati correlati attribuiti a uno stesso soggetto diventano corposi: quello è il momento maturo per venderli e, a tale scopo, cosa c’è di meglio di un mercato nero raggiungibile nel dark web?
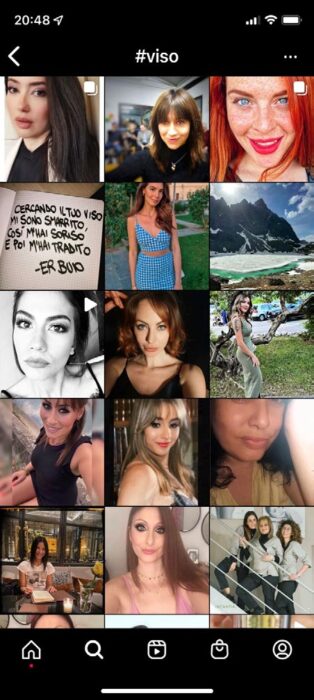
su Instagram.
Dunque assistiamo alla messa in vendita di nomi, indirizzi, foto, e-mail ecc. relativi a uno stesso soggetto; e questo viene fatto per moltissimi soggetti.
Esaminiamo, a seguire, i due principali tipi di abusi che i legittimi proprietari dei dati possono subire: il furto d’identità e la presenza in raccolte estranee di dati.
Nel primo caso, l’acquirente è spesso una persona che vuole intentare una truffa ai danni di altri individui o di istituti finanziari (bancari, assicurativi ecc.). Per organizzare tale frode, il truffatore ha bisogno di usare identità “normali” – molto meglio avere dati reali che creare identità fittizie con il pericolo di qualche dimenticanza – così rendendo la sua opera più robusta e a prova di numerose verifiche. Il risultato è che risulterà molto più credibile ed efficace nel portare la truffa a compimento. Naturalmente le forze dell’ordine conoscono bene il fenomeno; tuttavia le vittime di furti d’identità potranno rimanere all’interno di liste di potenziali sospetti, consultate ogni volta che si verifichi una frode in rete.
Il secondo caso fa riferimento al ben noto fenomeno della pedopornografia in rete. È piuttosto frequente il caso in cui il criminale si sia procurato una collezione di materiali pornografici relativi a minori, concentrati su dettagli anatomici e mancanti di volti specifici o figura del corpo. È pratica comune ricorrere a fotomontaggi o, semplicemente, all’arricchimento della collezione mediante immagini prese da chi “non ha nulla da nascondere”, per suggerire il volto o la figura del minore o di un suo parente stretto. Basta una qualche compatibilità nel colore della pelle. Anche in questo caso, ammesso il successo nel dimostrare l’estraneità, si rischia l’inclusione in liste di possibili sospetti.
ALTRE MINACCE
Finora ci siamo focalizzati sugli attacchi a pioggia. Nel caso di attacchi mirati, diversamente, non c’è limite alle conseguenze ottenibili; basti citare i deepfake, consistenti nell’uso di tecniche di machine learning (considerata parte dell’intelligenza artificiale) che mediante l’uso di autoencoders o reti generative avversarie (GAN) riescono, a partire da alcune immagini date, ad “addestrare” reti generative neurali all’alterazione delle immagini stesse. Il fenomeno ha acquisito notorietà nel 2017, quando queste tecniche furono usate per associare volti di attrici famose ai corpi nudi di modelle compiacenti. Tra i più celebri s’includono anche un video di Putin che annuncia la resa dell’Ucraina e uno di Obama, dove l’ex Presidente USA afferma che “stiamo entrando in un’era in cui i nostri nemici possono far dire a chiunque qualunque cosa in ogni momento”.
I deepfake accrescono fortemente la difficoltà di distinguere immagini genuine da quelle alterate: esistono anche numerose app che mettono a disposizione questa possibilità, alimentando però diversi dubbi sull’opportunità di depositare dati (come immagini di volti reali) all’interno di database il cui uso è per lo meno opaco.
Articolo a cura di Fabrizio D’Amore

Docente presso l’Università degli Studi di Roma “La Sapienza”, membro del Cyber Intelligence and Information Security Center
https://www.ictsecuritymagazine.com/articoli/il-furto-di-identita-e-come-non-facilitarlo-il-luogo-comune-non-ho-nulla-da-nascondere/