

Posted by Dr-Pete
In June of 2017, Moz launched our entirely rebuilt Site Crawl, helping you dive deep into crawl issues and technical SEO problems, fix those issues in your Moz Pro Campaigns (tracked websites), and monitor weekly for new issues. Many times, though, you need quick insights outside of a Campaign context, whether you’re analyzing a prospect site before a sales call or trying to assess the competition.
For years, Moz had a lab tool called Crawl Test. The bad news is that Crawl Test never made it to prime-time and suffered from some neglect. The good news is that I’m happy to announce the full launch (as of August 2018) of On-Demand Crawl, an entirely new crawl tool built on the engine that powers Site Crawl, but with a UI designed around quick insights for prospecting and competitive analysis.
While you don’t need a Campaign to run a crawl, you do need to be logged into your Moz Pro subscription. If you don’t have a subscription, you can sign-up for a free trial and give it a whirl.

How can you put On-Demand Crawl to work? Let’s walk through a short example together.
All you need is a domain
Getting started is easy. From the “Moz Pro” menu, find “On-Demand Crawl” under “Research Tools”:
Just enter a root domain or subdomain in the box at the top and click the blue button to kick off a crawl. While I don’t want to pick on anyone, I’ve decided to use a real site. Our recent analysis of the August 1st Google update identified some sites that were hit hard, and I’ve picked one (lilluna.com) from that list.
Please note that Moz is not affiliated with Lil’ Luna in any way. For the most part, it seems to be a decent site with reasonably good content. Let’s pretend, just for this post, that you’re looking to help this site out and determine if they’d be a good fit for your SEO services. You’ve got a call scheduled and need to spot-check for any major problems so that you can go into that call as informed as possible.
On-Demand Crawls aren’t instantaneous (crawling is a big job), but they’ll generally finish between a few minutes and an hour. We know these are time-sensitive situations. You’ll soon receive an email that looks like this:
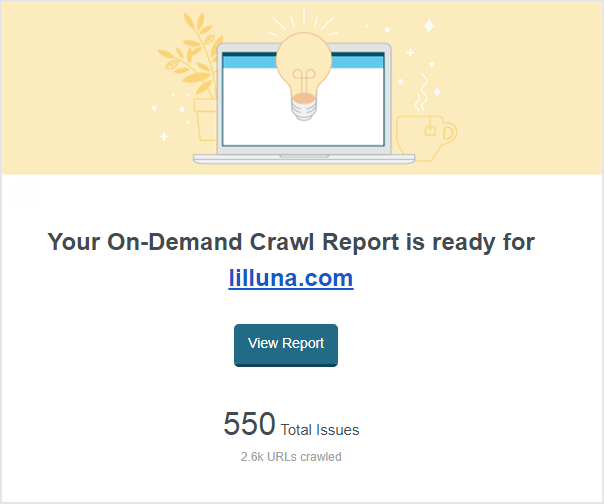
The email includes the number of URLs crawled (On-Demand will currently crawl up to 3,000 URLs), the total issues found, and a summary table of crawl issues by category. Click on the [View Report] link to dive into the full crawl data.
Assess critical issues quickly
We’ve designed On-Demand Crawl to assist your own human intelligence. You’ll see some basic stats at the top, but then immediately move into a graph of your top issues by count. The graph only displays issues that occur at least once on your site – you can click “See More” to show all of the issues that On-Demand Crawl tracks (the top two bars have been truncated)…
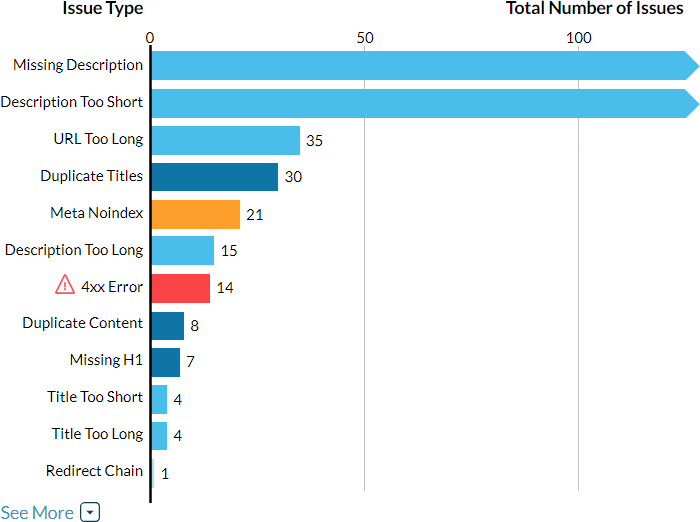
Issues are also color-coded by category. Some items are warnings, and whether they matter depends a lot on context. Other issues, like “Critcal Errors” (in red) almost always demand attention. So, let’s check out those 404 errors. Scroll down and you’ll see a list of “Pages Crawled” with filters. You’re going to select “4xx” in the “Status Codes” dropdown…
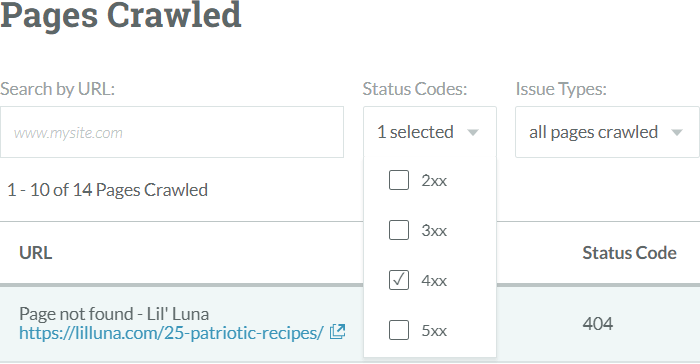
You can then pretty easily spot-check these URLs and find out that they do, in fact, seem to be returning 404 errors. Some appear to be legitimate content that has either internal or external links (or both). So, within a few minutes, you’ve already found something useful.
Let’s look at those yellow “Meta Noindex” errors next. This is a tricky one, because you can’t easily determine intent. An intentional Meta Noindex may be fine. An unintentional one (or hundreds of unintentional ones) could be blocking crawlers and causing serious harm. Here, you’ll filter by issue type…
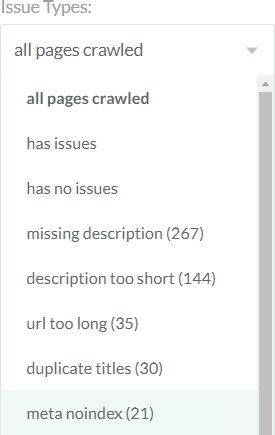
Like the top graph, issues appear in order of prevalence. You can also filter by all pages that have issues (any issues) or pages that have no issues. Here’s a sample of what you get back (the full table also includes status code, issue count, and an option to view all issues)…
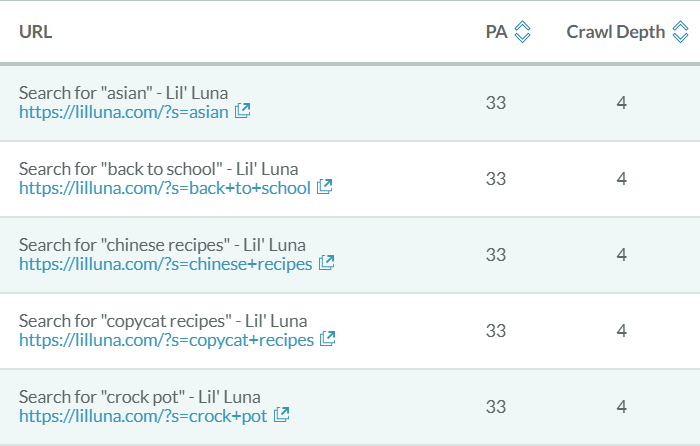
Notice the “?s=” common to all of these URLs. Clicking on a few, you can see that these are internal search pages. These URLs have no particular SEO value, and the Meta Noindex is likely intentional. Good technical SEO is also about avoiding false alarms because you lack internal knowledge of a site. On-Demand Crawl helps you semi-automate and summarize insights to put your human intelligence to work quickly.
Dive deeper with exports
Let’s go back to those 404s. Ideally, you’d like to know where those URLs are showing up. We can’t fit everything into one screen, but if you scroll up to the “All Issues” graph you’ll see an “Export CSV” option…

The export will honor any filters set in the page list, so let’s re-apply that “4xx” filter and pull the data. Your export should download almost immediately. The full export contains a wealth of information, but I’ve zeroed in on just what’s critical for this particular case…
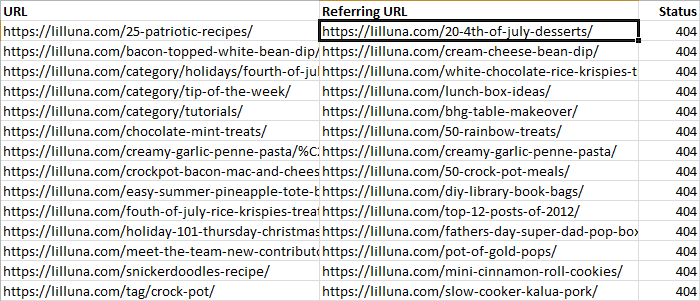
Now, you know not only what pages are missing, but exactly where they link from internally, and can easily pass along suggested fixes to the customer or prospect. Some of these turn out to be link-heavy pages that could probably benefit from some clean-up or updating (if newer recipes are a good fit).
Let’s try another one. You’ve got 8 duplicate content errors. Potentially thin content could fit theories about the August 1st update, so this is worth digging into. If you filter by “Duplicate Content” issues, you’ll see the following message…

The 8 duplicate issues actually represent 18 pages, and the table returns all 18 affected pages. In some cases, the duplicates will be obvious from the title and/or URL, but in this case there’s a bit of mystery, so let’s pull that export file. In this case, there’s a column called “Duplicate Content Group,” and sorting by it reveals something like the following (there’s a lot more data in the original export file)…
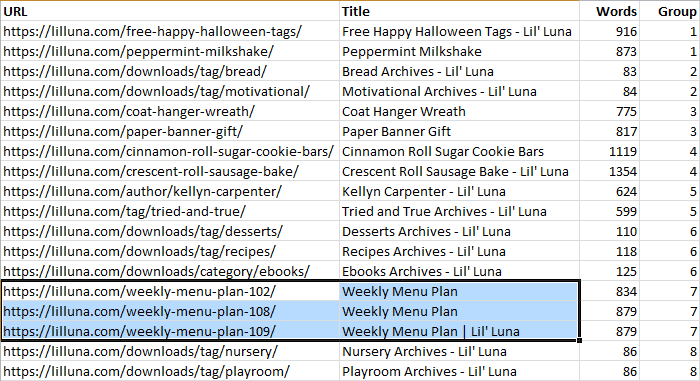
I’ve renamed “Duplicate Content Group” to just “Group” and included the word count (“Words”), which could be useful for verifying true duplicates. Look at group #7 – it turns out that these “Weekly Menu Plan” pages are very image heavy and have a common block of text before any unique text. While not 100% duplicated, these otherwise valuable pages could easily look like thin content to Google and represent a broader problem.
Real insights in real-time
Not counting the time spent writing the blog post, running this crawl and diving in took less than an hour, and even that small amount of time spent uncovered more potential issues than what I could cover in this post. In less than an hour, you can walk into a client meeting or sales call with in-depth knowledge of any domain.
Keep in mind that many of these features also exist in our Site Crawl tool. If you’re looking for long-term, campaign insights, use Site Crawl (if you just need to update your data, use our “Recrawl” feature). If you’re looking for quick, one-time insights, check out On-Demand Crawl. Standard Pro users currently get 5 On-Demand Crawls per month (with limits increasing at higher tiers).
Your On-Demand Crawls are currently stored for 90 days. When you re-enter the feature, you’ll see a table of all of your recent crawls (the image below has been truncated):
Click on any row to go back to see the crawl data for that domain. If you get the sale and decide to move forward, congratulations! You can port that domain directly into a Moz campaign.
We hope you’ll try On-Demand Crawl out and let us know what you think. We’d love to hear your case studies, whether it’s sales, competitive analysis, or just trying to solve the mysteries of a Google update.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]() http://tracking.feedpress.it/link/9375/10086767?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+mozblog
http://tracking.feedpress.it/link/9375/10086767?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+mozblog