

Posted by alexis-sanders
SEO is about understanding how search bots and users react to an online experience. As search professionals, we’re required to bridge gaps between online experiences, search engine bots, and users. We need to know where to insert ourselves (or our teams) to ensure the best experience for both users and bots. In other words, we strive for experiences that resonate with humans and make sense to search engine bots.
This article seeks to answer the following questions:
- How do we drive sustainable growth for our clients?
- What are the building blocks of an organic search strategy?
What is the SEO cyborg?
A cyborg (or cybernetic organism) is defined as “a being with both organic and
biomechatronic body parts, whose physical abilities are extended beyond normal human limitations by mechanical elements.”
With the ability to relate between humans, search bots, and our site experiences, the SEO cyborg is an SEO (or team) that is able to work seamlessly between both technical and content initiatives (whose skills are extended beyond normal human limitations) to support driving of organic search performance. An SEO cyborg is able to strategically pinpoint where to place organic search efforts to maximize performance.
So, how do we do this?
The SEO model
Like so many classic triads (think: primary colors, the Three Musketeers, Destiny’s Child [the canonical version, of course]) the traditional SEO model, known as the crawl-index-rank method, packages SEO into three distinct steps. At the same time, however, this model fails to capture the breadth of work that we SEOs are expected to do on a daily basis, and not having a functioning model can be limiting. We need to expand this model without reinventing the wheel.

The enhanced model involves adding in a rendering, signaling, and connection phase.
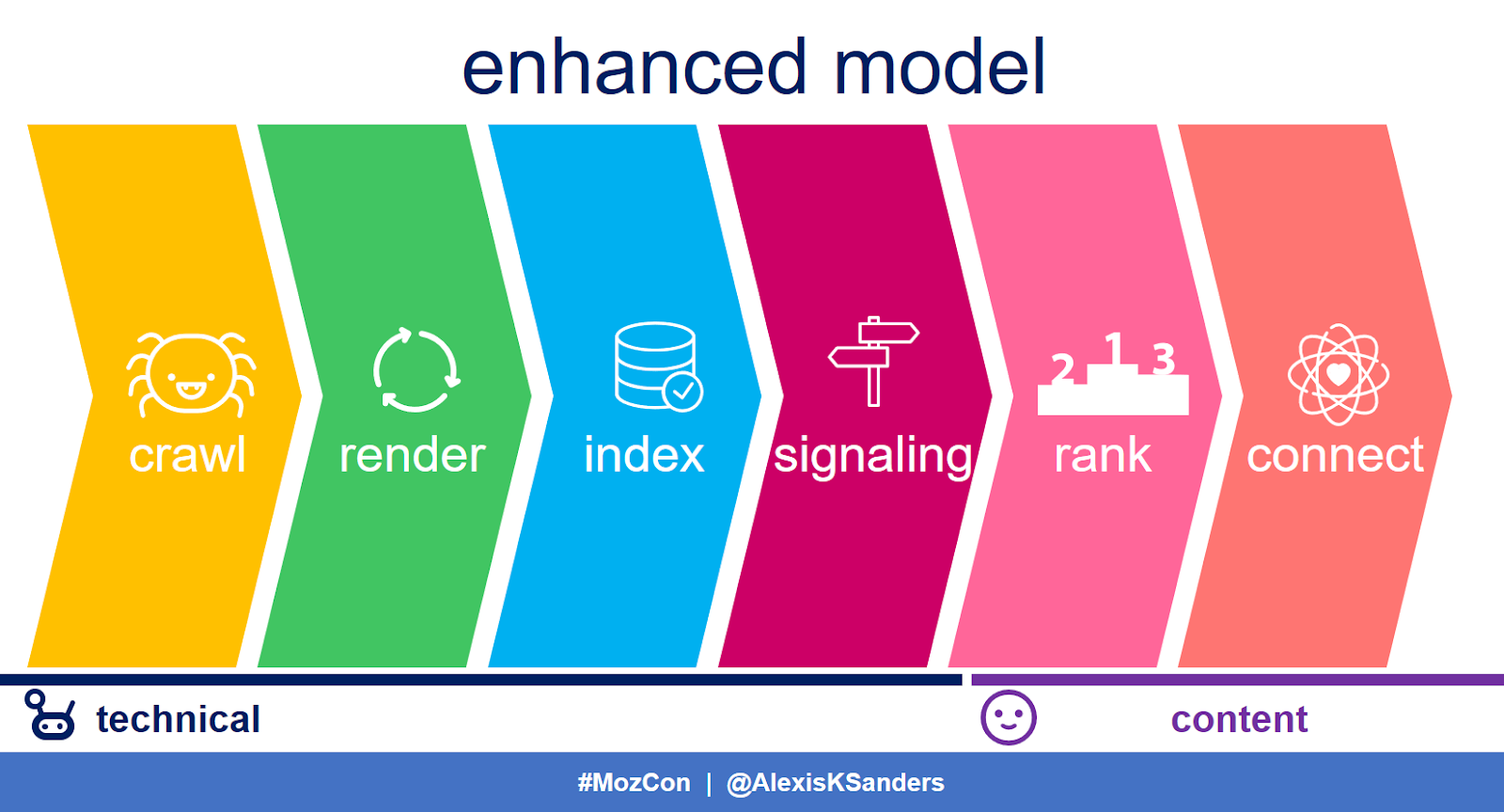
You might be wondering, why do we need these?:
- Rendering: There is increased prevalence of JavaScript, CSS, imagery, and personalization.
- Signaling: HTML <link> tags, status codes, and even GSC signals are powerful indicators that tell search engines how to process and understand the page, determine its intent, and ultimately rank it. In the previous model, it didn’t feel as if these powerful elements really had a place.
- Connecting: People are a critical component of search. The ultimate goal of search engines is to identify and rank content that resonates with people. In the previous model, “rank” felt cold, hierarchical, and indifferent towards the end user.
All of this brings us to the question: how do we find success in each stage of this model?
Note: When using this piece, I recommend skimming ahead and leveraging those sections of the enhanced model that are most applicable to your business’ current search program.
The enhanced SEO model
Crawling
Technical SEO starts with the search engine’s ability to find a site’s webpages (hopefully efficiently).
Finding pages
Initially finding pages can happen a few ways, via:
- Links (internal or external)
- Redirected pages
- Sitemaps (XML, RSS 2.0, Atom 1.0, or .txt)
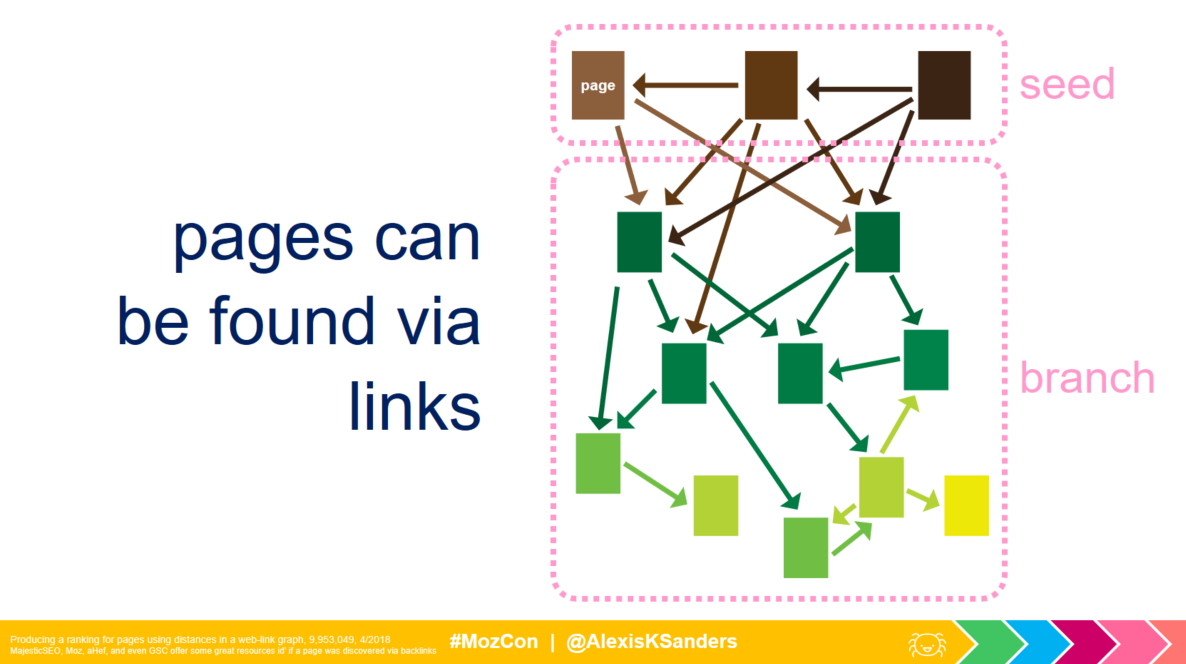
Side note: This information (although at first pretty straightforward) can be really useful. For example, if you’re seeing weird pages popping up in site crawls or performing in search, try checking:
- Backlink reports
- Internal links to URL
- Redirected into URL
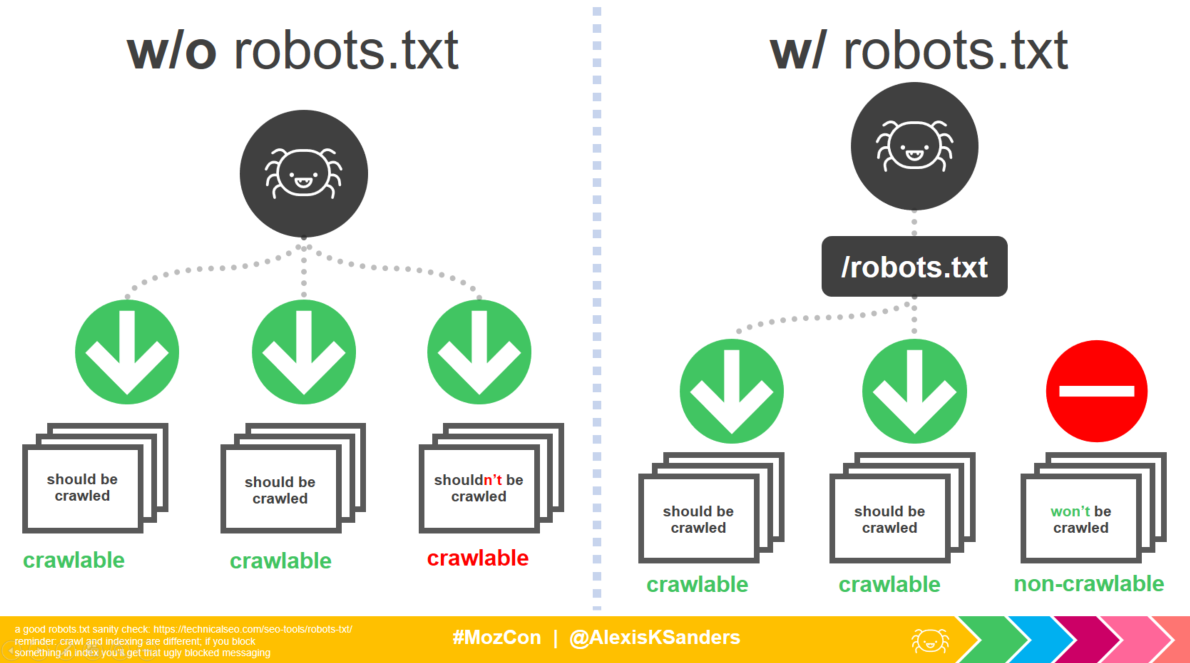
Obtaining resources
The second component of crawling relates to the ability to obtain resources (which later becomes critical for rendering a page’s experience).
This typically relates to two elements:
- Appropriate robots.txt declarations
- Proper HTTP status code (namely 200 HTTP status codes)
Crawl efficiency
Finally, there’s the idea of how efficiently a search engine bot can traverse your site’s most critical experiences.
Action items:
- Is site’s main navigation simple, clear, and useful?
- Are there relevant on-page links?
- Is internal linking clear and crawlable (i.e., <a href=”/”>)?
- Is an HTML sitemap available?
- Side note: Make sure to check the HTML sitemap’s next page flow (or behavior flow reports) to find where those users are going. This may help to inform the main navigation.
- Do footer links contain tertiary content?
- Are important pages close to root?
- Are there no crawl traps?
- Are there no orphan pages?
- Are pages consolidated?
- Do all pages have purpose?
- Has duplicate content been resolved?
- Have redirects been consolidated?
- Are canonical tags on point?
- Are parameters well defined?
Information architecture
The organization of information extends past the bots, requiring an in-depth understanding of how users engage with a site.
Some seed questions to begin research include:
- What trends appear in search volume (by location, device)? What are common questions users have?
- Which pages get the most traffic?
- What are common user journeys?
- What are users’ traffic behaviors and flow?
- How do users leverage site features (e.g., internal site search)?
Rendering
Rendering a page relates to search engines’ ability to capture the page’s desired essence.
JavaScript
The big kahuna in the rendering section is JavaScript. For Google, rendering of JavaScript occurs during a second wave of indexing and the content is queued and rendered as resources become available.
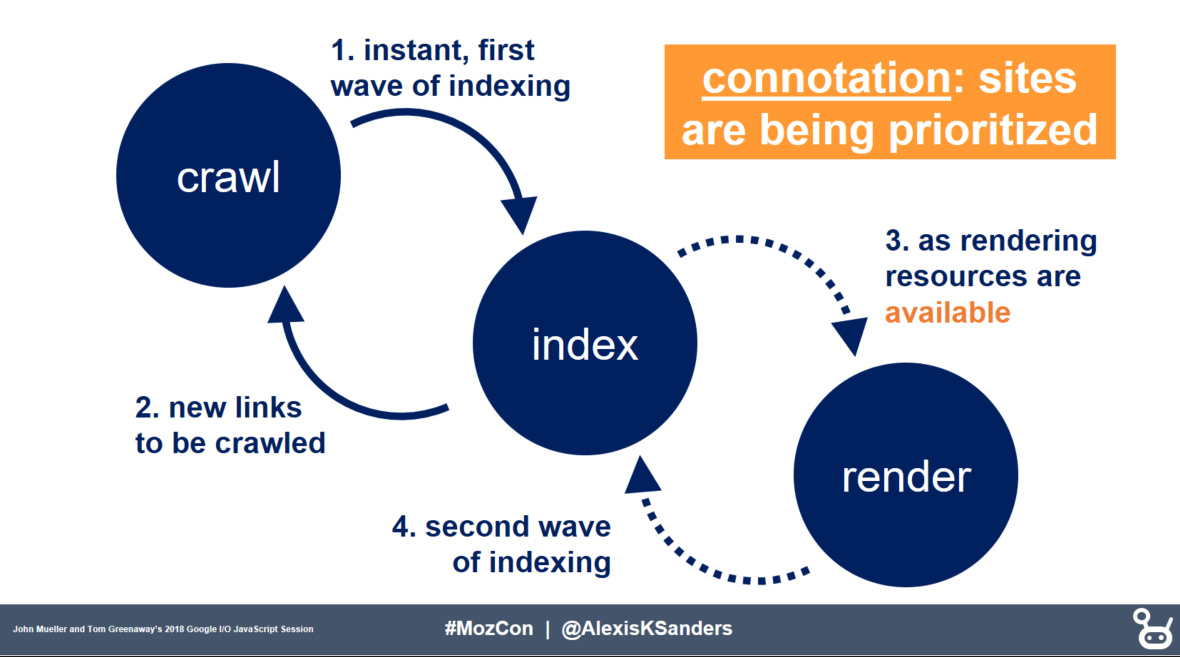
Image based off of Google I/O ’18 presentation by Tom Greenway and John Mueller, Deliver search-friendly JavaScript-powered websites
As an SEO, it’s critical that we be able to answer the question — are search engines rendering my content?
Action items:
- Are direct “quotes” from content indexed?
- Is the site using <a href=”/”> links (not onclick();)?
- Is the same content being served to search engine bots (user-agent)?
- Is the content present within the DOM?
- What does Google’s Mobile-Friendly Testing Tool’s JavaScript console (click “view details”) say?
Infinite scroll and lazy loading
Another hot topic relating to JavaScript is infinite scroll (and lazy load for imagery). Since search engine bots are lazy users, they won’t scroll to attain content.
Action items:
Ask ourselves – should all of the content really be indexed? Is it content that provides value to users?
- Infinite scroll: a user experience (and occasionally a performance optimizing) tactic to load content when the user hits a certain point in the UI; typically the content is exhaustive.
Solution one (updating AJAX):
1. Break out content into separate sections
- Note: The breakout of pages can be /page-1, /page-2, etc.; however, it would be best to delineate meaningful divides (e.g., /voltron, /optimus-prime, etc.)
2. Implement History API (pushState(), replaceState()) to update URLs as a user scrolls (i.e., push/update the URL into the URL bar)
3. Add the <link> tag’s rel=”next” and rel=”prev” on relevant page
Solution two (create a view-all page)
Note: This is not recommended for large amounts of content.
1. If it’s possible (i.e., there’s not a ton of content within the infinite scroll), create one page encompassing all content
2. Site latency/page load should be considered
- Lazy load imagery is a web performance optimization tactic, in which images loads upon a user scrolling (the idea is to save time, downloading images only when they’re needed)
- Add <img> tags in <noscript> tags
- Use JSON-LD structured data
- Schema.org “image” attributes nested in appropriate item types
- Schema.org ImageObject item type
CSS
I only have a few elements relating to the rendering of CSS.
Action items:
- CSS background images not picked up in image search, so don’t count on for important imagery
- CSS animations not interpreted, so make sure to add surrounding textual content
- Layouts for page are important (use responsive mobile layouts; avoid excessive ads)
Personalization
Although a trend in the broader digital exists to create 1:1, people-based marketing, Google doesn’t save cookies across sessions and thus will not interpret personalization based on cookies, meaning there must be an average, base-user, default experience. The data from other digital channels can be exceptionally useful when building out audience segments and gaining a deeper understanding of the base-user.
Action item:
- Ensure there is a base-user, unauthenticated, default experience

Technology
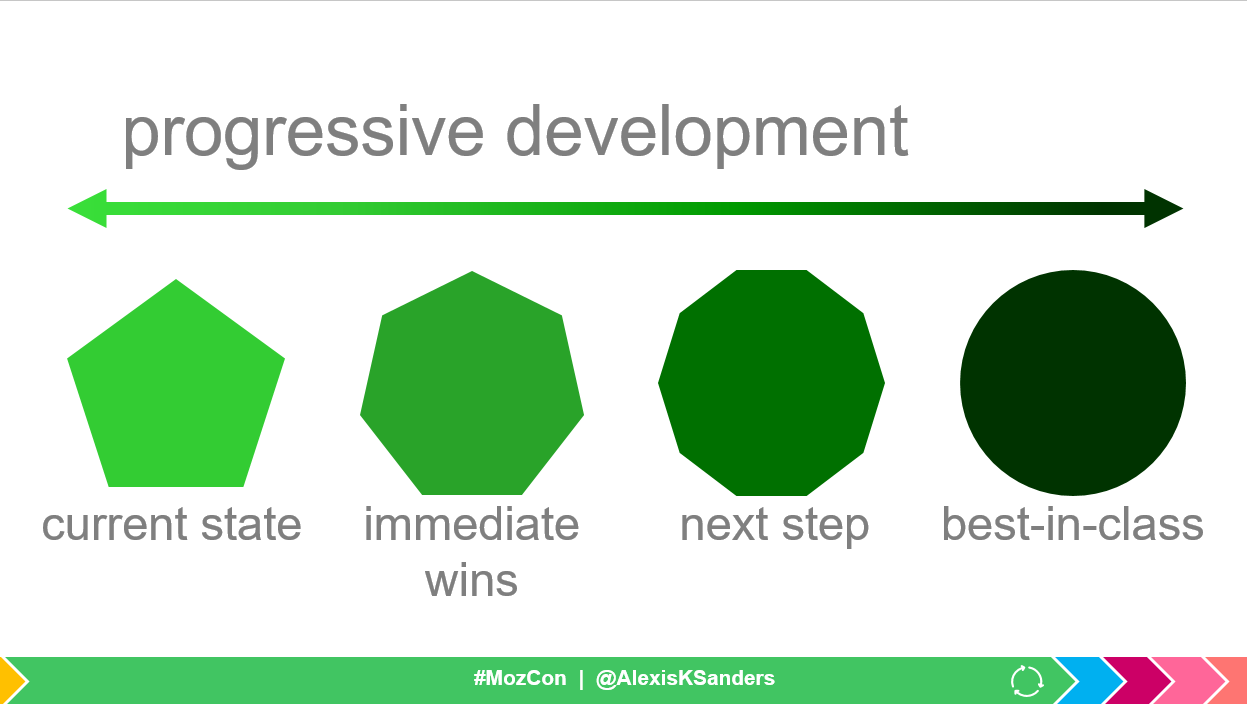
Google’s rendering engine is leveraging Chrome 41. Canary (Chrome’s testing browser) is currently operating on Chrome 69. Using CanIUse.com, we can infer that this affects Google’s abilities relating to HTTP/2, service workers (think: PWAs), certain JavaScript, specific advanced image formats, resource hints, and new encoding methods. That said, this does not mean we shouldn’t progress our sites and experiences for users — we just must ensure that we use progressive development (i.e., there’s a fallback for less advanced browsers [and Google too ☺]).
Action items:
- Ensure there’s a fallback for less advanced browsers

Indexing
Getting pages into Google’s databases is what indexing is all about. From what I’ve experienced, this process is straightforward for most sites.
Action items:
- Ensure URLs are able to be crawled and rendered
- Ensure nothing is preventing indexing (e.g., robots meta tag)
- Submit sitemap in Google Search Console
- Fetch as Google in Google Search Console
Signaling
A site should strive to send clear signals to search engines. Unnecessarily confusing search engines can significantly impact a site’s performance. Signaling relates to suggesting best representation and status of a page. All this means is that we’re ensuring the following elements are sending appropriate signals.
Action items:
- <link> tag: This represents the relationship between documents in HTML.
- Rel=”canonical”: This represents appreciably similar content.
- Are canonicals a secondary solution to 301-redirecting experiences?
- Are canonicals pointing to end-state URLs?
- Is the content appreciably similar?
- Since Google maintains prerogative over determining end-state URL, it’s important that the canonical tags represent duplicates (and/or duplicate content).
- Are all canonicals in HTML?
- Presumably Google prefers canonical tags in the HTML. Although there have been some studies that show that Google can pick up JavaScript canonical tags, from my personal studies it takes significantly longer and is spottier.
- Is there safeguarding against incorrect canonical tags?
- Rel=”next” and rel=”prev”: These represent a collective series and are not considered duplicate content, which means that all URLs can be indexed. That said, typically the first page in the chain is the most authoritative, so usually it will be the one to rank.
- Rel=”alternate”
- media: typically used for separate mobile experiences.
- hreflang: indicate appropriate language/country
- The hreflang is quite unforgiving and it’s very easy to make errors.
- Ensure the documentation is followed closely.
- Check GSC International Target reports to ensure tags are populating.
- Rel=”canonical”: This represents appreciably similar content.
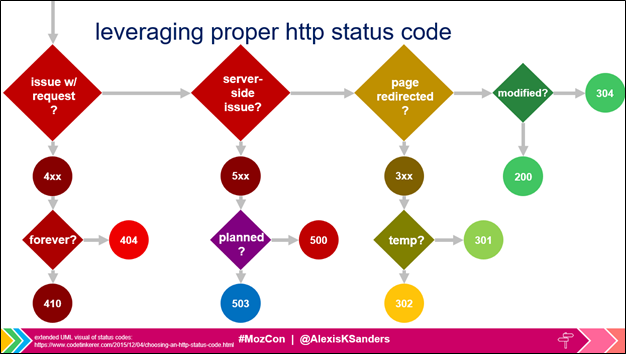
- HTTP status codes can also be signals, particularly the 304, 404, 410, and 503 status codes.
- 304 – a valid page that simply hasn’t been modified
- 404 – file not found
- 410 – file not found (and it is gone, forever and always)
- 503 – server maintenance
- Google Search Console settings: Make sure the following reports are all sending clear signals. Occasionally Google decides to honor these signals.
- International Targeting
- URL Parameters
- Data Highlighter
- Remove URLs
- Sitemaps
Rank
Rank relates to how search engines arrange web experiences, stacking them against each other to see who ends up on top for each individual query (taking into account numerous data points surrounding the query).
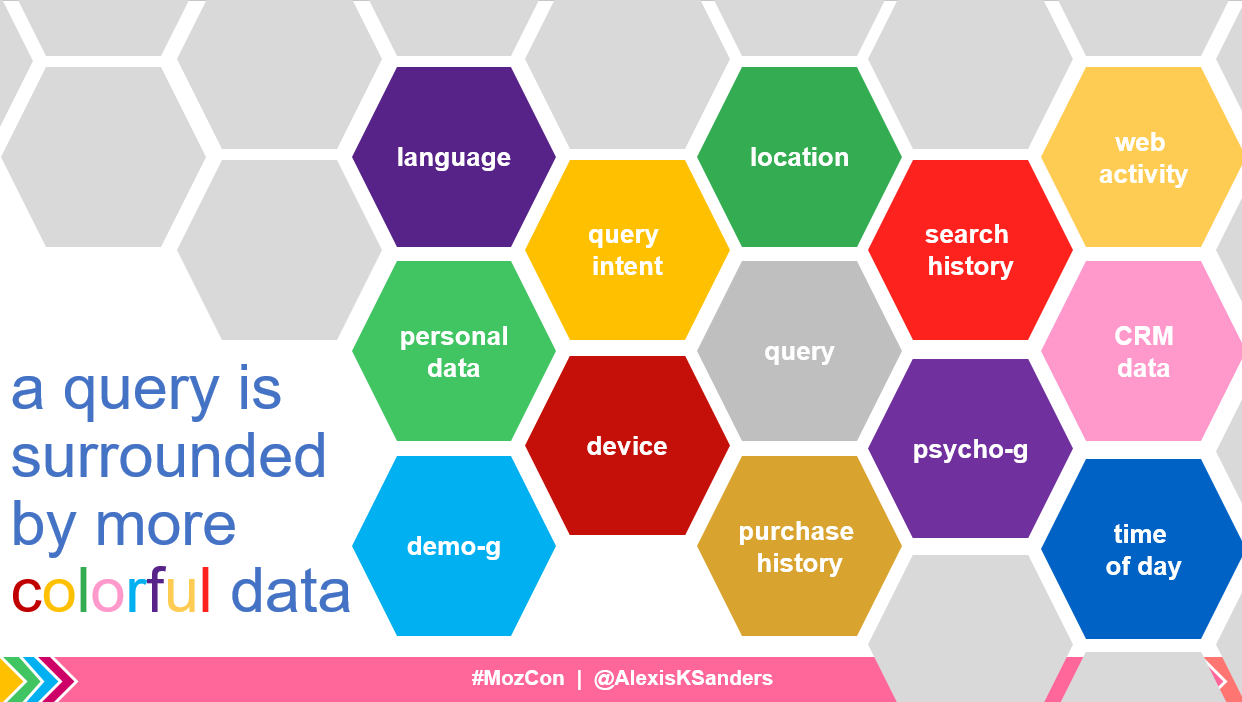
Two critical questions recur often when understanding ranking pages:
- Does or could your page have the best response?
- Are you or could you become semantically known (on the Internet and in the minds of users) for the topics? (i.e., are you worthy of receiving links and people traversing the web to land on your experience?)

On-page optimizations
These are the elements webmasters control. Off-page is a critical component to achieving success in search; however, in an idyllic world, we shouldn’t have to worry about links and/or mentions – they should come naturally.
Action items:
- Textual content:
- Make content both people and bots can understand
- Answer questions directly
- Write short, logical, simple sentences
- Ensure subjects are clear (not to be inferred)
- Create scannable content (i.e., make sure <h#> tags are an outline, use bullets/lists, use tables, charts, and visuals to delineate content, etc.)
- Define any uncommon vocabulary or link to a glossary
- Multimedia (images, videos, engaging elements):
- Use imagery, videos, engaging content where applicable
- Ensure that image optimization best practices are followed
- If you’re looking for a comprehensive resource check out https://images.guide
- Meta elements (<title> tags, meta descriptions, OGP, Twitter cards, etc.)
- Structured data
- Schema.org (check out Google’s supported markup and TechnicalSEO.com’s markup helper tool)
- Use Accessible Rich Internet Applications (ARIA)
- Use semantic HTML (especially hierarchically organized, relevant <h#> tags and unordered and ordered lists (<ul>, <ol>))
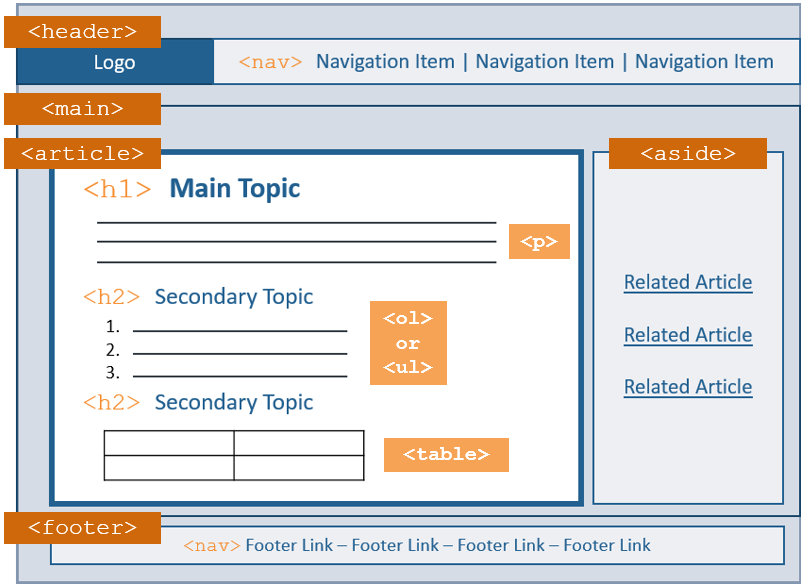
Image courtesy of @abbynhamilton
- Is content accessible?
- Is there keyboard functionality?
- Are there text alternatives for non-text media? Example:
- Transcripts for audio
- Images with alt text
- In-text descriptions of visuals
- Is there adequate color contrast?
- Is text resizable?
Finding interesting content
Researching and identifying useful content happens in three formats:
- Keyword and search landscape research
- On-site analytic deep dives
- User research

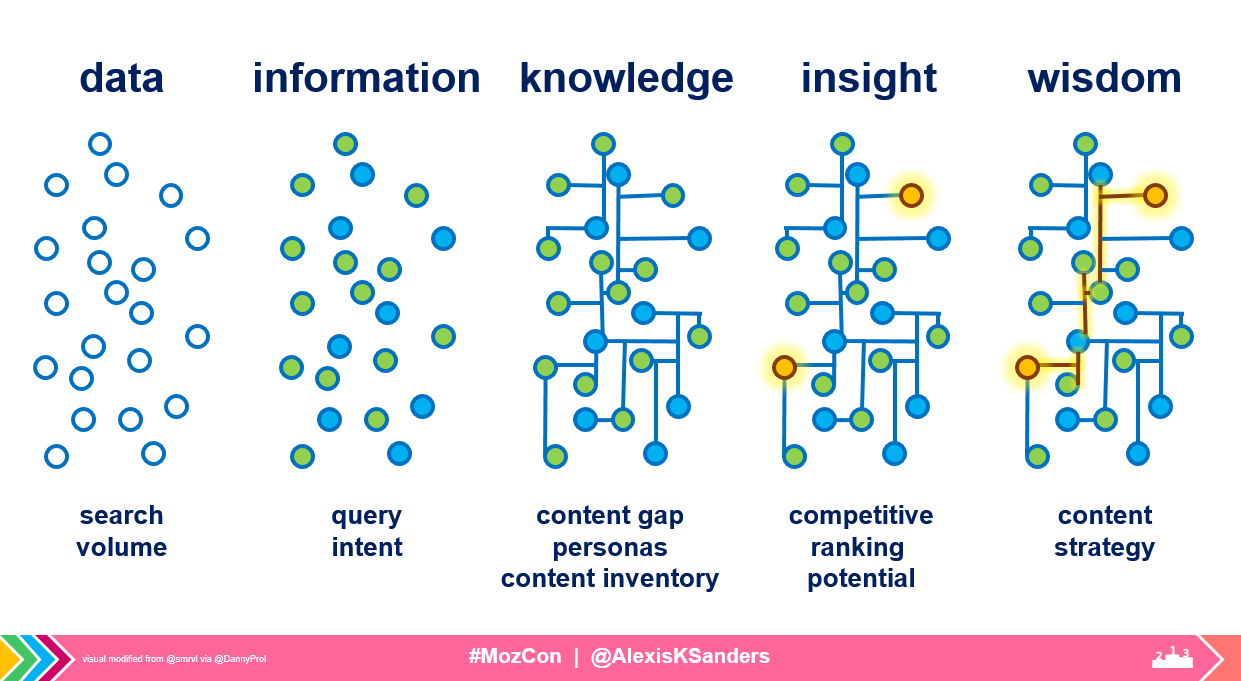
Visual modified from @smrvl via @DannyProl
Audience research
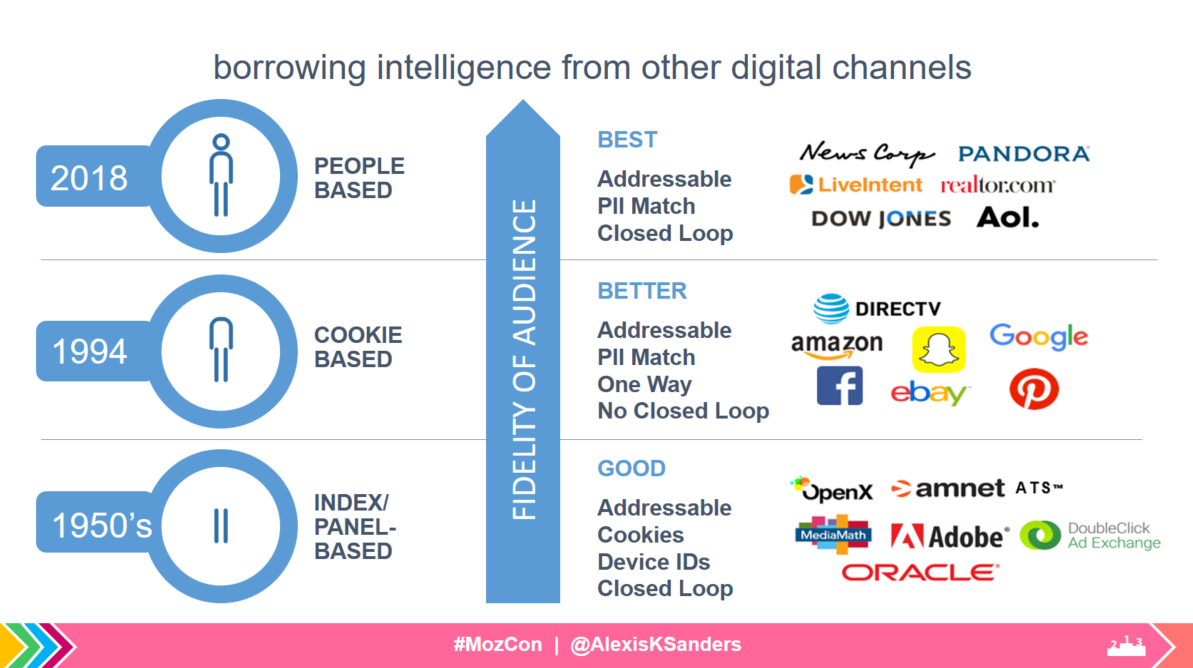
When looking for audiences, we need to concentrate high percentages (super high index rates are great, but not required). Push channels (particularly ones with strong targeting capabilities) do better with high index rates. This makes sense, we need to know that 80% of our customers have certain leanings (because we’re looking for base-case), not that five users over-index on a niche topic (these five niche-topic lovers are perfect for targeted ads).
Some seed research questions:
- Who are users?
- Where are they?
- Why do they buy?
- How do they buy?
- What do they want?
- Are they new or existing users?
- What do they value?
- What are their motivators?
- What is their relationship w/ tech?
- What do they do online?
- Are users engaging with other brands?
- Is there an opportunity for synergy?
- What can we borrow from other channels?
- Digital presents a wealth of data, in which 1:1, closed-loop, people-based marketing exists. Leverage any data you can get and find useful.
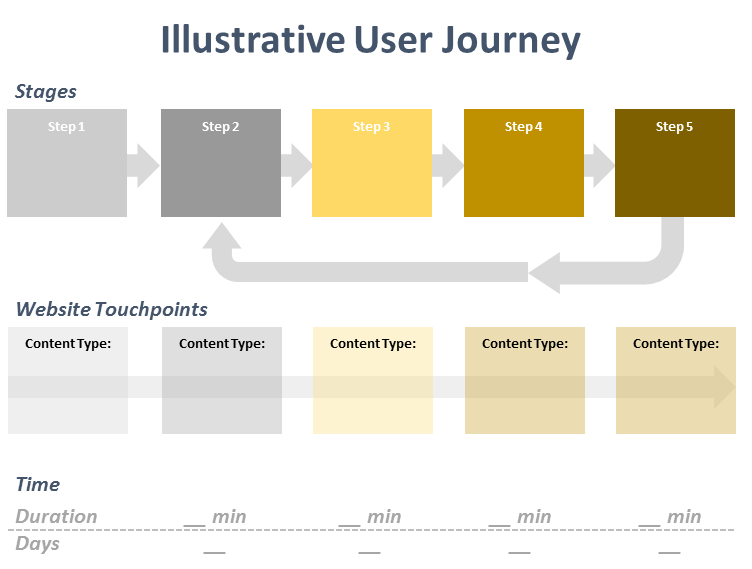
Content journey maps
All of this data can then go into creating a map of the user journey and overlaying relevant content. Below are a few types of mappings that are useful.
Illustrative user journey map
Sometimes when trying to process complex problems, it’s easier to break it down into smaller pieces. Illustrative user journeys can help with this problem! Take a single user’s journey and map it out, aligning relevant content experiences.
Funnel content mapping
This chart is deceptively simple; however, working through this graph can help sites to understand how each stage in the funnel affects users (note: the stages can be modified). This matrix can help with mapping who writers are talking to, their needs, and how to push them to the next stage in the funnel.

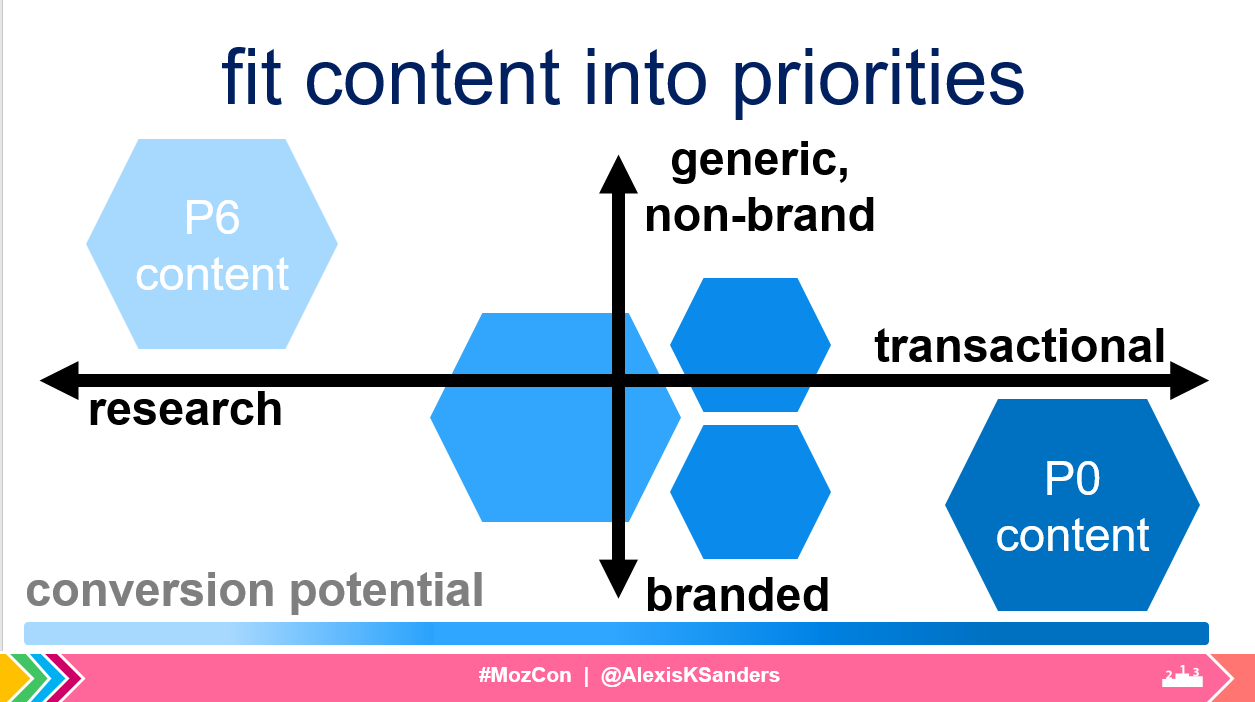
Content matrix
Mapping out content by intent and branding helps to visualize conversion potential. I find these extremely useful for prioritizing top-converting content initiatives (i.e., start with ensuring branded, transactional content is delivering the best experience, then move towards more generic, higher-funnel terms).
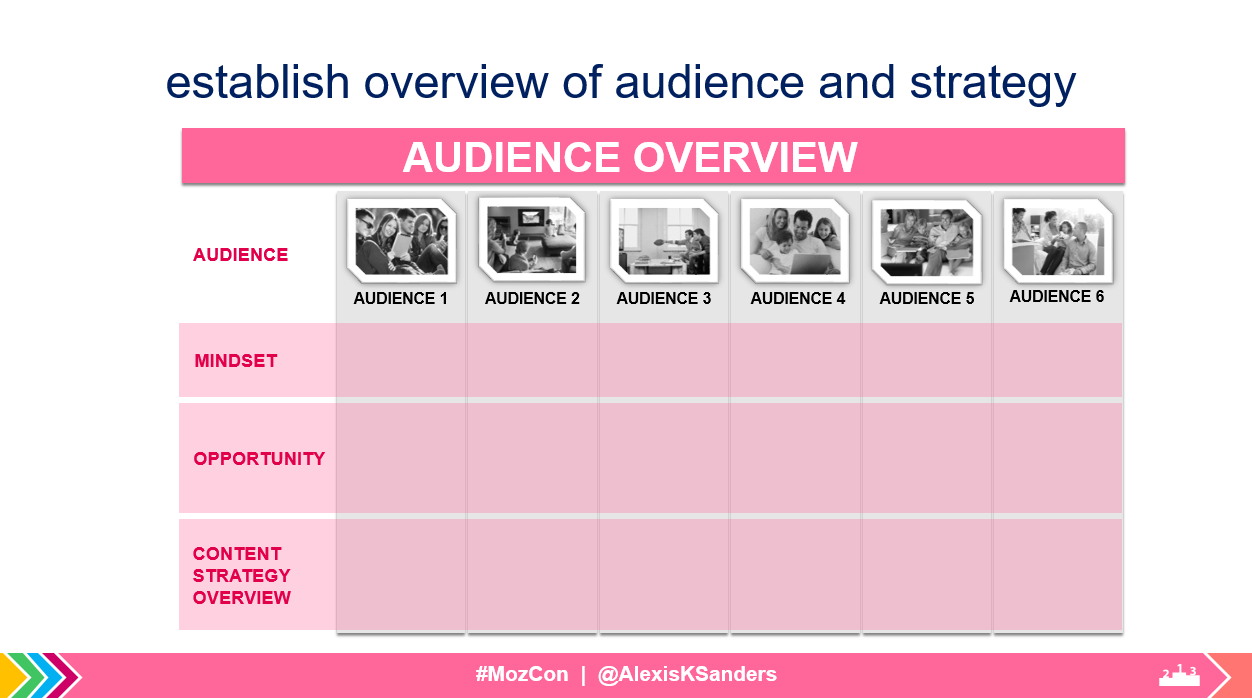
Overviews
Regardless of how the data is broken down, it’s vital to have a high-level view on the audience’s core attributes, opportunities to improve content, and strategy for closing the gap.
Connecting
Connecting is all about resonating with humans. Connecting is about understanding that customers are human (and we have certain constraints). Our mind is constantly filtering, managing, multitasking, processing, coordinating, organizing, and storing information. It is literally in our mind’s best interest to not remember 99% of the information and sensations that surround us (think of the lights, sounds, tangible objects, people surrounding you, and you’re still able to focus on reading the words on your screen — pretty incredible!).
To become psychologically sticky, we must:
- Get past the mind’s natural filter. A positive aspect of being a pull marketing channel is that individuals are already seeking out information, making it possible to intersect their user journey in a micro-moment.
- From there we must be memorable. The brain tends to hold onto what’s relevant, useful, or interesting. Luckily, the searcher’s interest is already piqued (even if they aren’t consciously aware of why they searched for a particular topic).
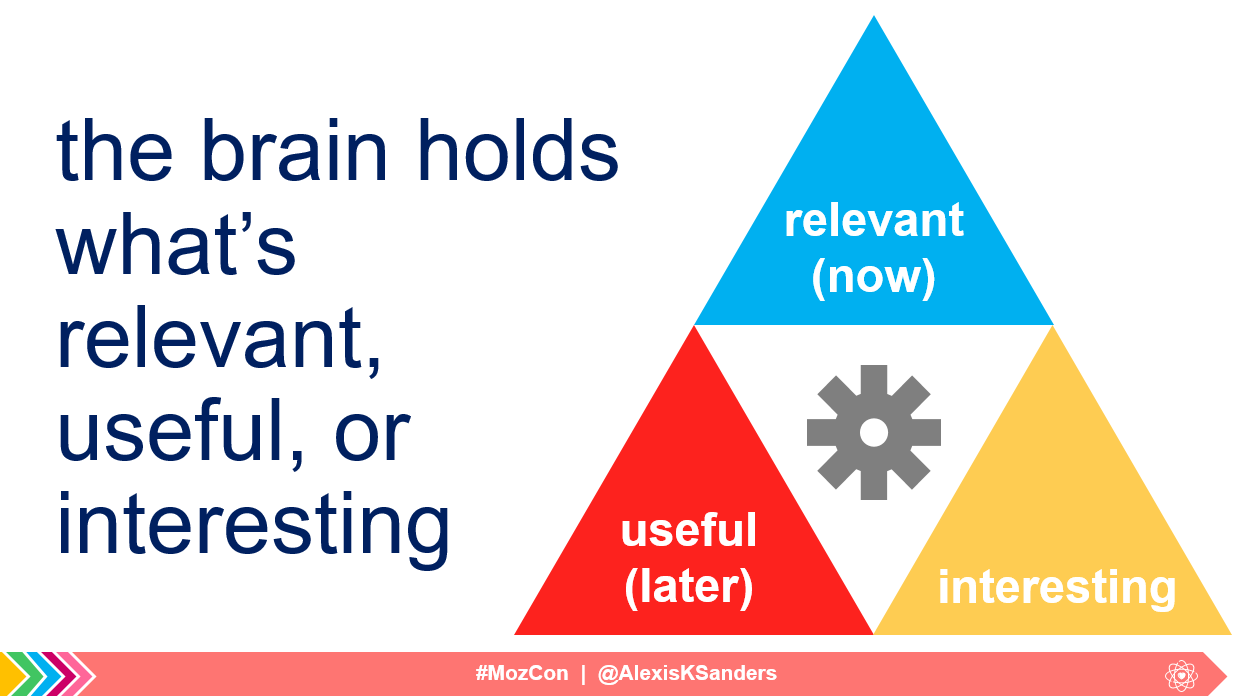
This means we have a unique opportunity to “be there” for people. This leads to a very simple, abstract philosophy: a great brand is like a great friend.
We have similar relationship stages, we interweave throughout each other’s lives, and we have the ability to impact happiness. This comes down to the question: Do your online customers use adjectives they would use for a friend to describe your brand?
Action items:
- Is all content either relevant, useful, or interesting?
- Does the content honor your user’s questions?
- Does your brand have a personality that aligns with reality?
- Are you treating users as you would a friend?
- Do your users use friend-like adjectives to describe your brand and/or site?
- Do the brand’s actions align with overarching goals?
- Is your experience trust-inspiring?
- https://?
- Using Limited ads in layout?
- Does the site have proof of claims?
- Does the site use relevant reviews and testimonials?
- Is contact information available and easily findable?
- Is relevant information intuitively available to users?
- Is it as easy to buy/subscribe as it is to return/cancel?
- Is integrity visible throughout the entire conversion process and experience?
- Does site have credible reputation across the web?
Ultimately, being able to strategically, seamlessly create compelling user experiences which make sense to bots is what the SEO cyborg is all about. ☺

tl;dr
- Ensure site = crawlable, renderable, and indexable
- Ensure all signals = clear, aligned
- Answering related, semantically salient questions
- Research keywords, the search landscape, site performance, and develop audience segments
- Use audience segments to map content and prioritize initiatives
- Ensure content is relevant, useful, or interesting
- Treat users as friend, be worthy of their trust
This article is based off of my MozCon talk (with a few slides from the Appendix pulled forward). The full deck is available on Slideshare, and the official videos can be purchased here. Please feel free to reach out with any questions in the comments below or via Twitter @AlexisKSanders.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]() http://tracking.feedpress.it/link/9375/10520986?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+mozblog
http://tracking.feedpress.it/link/9375/10520986?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+mozblog